






创建数据库
#character set指定字符集默认utf-8,collate指定字符集校对规则(utf8_bin区分大小写,utf8_general_ci不区分大小写)
create database [if not exists] db_name [character set] [collate]显示数据库
show databases显示数据库创建语句
show create database db_name数据库删除语句
drop database [if exists] db_name创建表
create table name
(
field1 datatype,
field1 datatype,
field1 datatype
)character set 字符集 collate 校对规则(默认与数据库为准) engine 引擎Mysql列类型
整形 tinyint[1字节] smallint[2字节] mediumint[3字节] int[4字节] bigint[8字节]
小数类型 float[单精度4字节] double[双精度8字节] decimal[M,D][大小不确定M=10,D=0]M是小数位数(精度)的总数,D是小数点后面的位数
字符串类型 char(固定长度字符串) 0-255(字符) varchar(可变长度字符串,字符) 会预留1~3字节记录存放长度 0-65535{0~2^16-1](字节) text 0~2^16-1(字节) longtext 0~ 2^32-1(字节)(gbk中文2个字节,英文1个字节;utf-8中文3个字节,英文1个字节)
二进制数据 blob[0~2^16-1] longblob 0~2^32-1
日期类型 date 日期 年月日 time 时间 时分秒 datetime 年月日时分秒 YYYY-MM-DD hh:mm:ss
timestamp 时间戳
CREATE TABLE `table`
(
birthday DATE,
job_time DATETIME,
login_time TIMESTAMP
not null DEFAULT CURRENT_TIMESTAMP on UPDATE CURRENT_TIMESTAMP
) CHARACTER SET utf8; #自动更新时间戳
INSERT INTO `TABLE`(birthday,job_time) VALUE("2024-3-24","2024-3-24 10:10:10");
year 年
位类型 bit 1-64 二进制显示修改表
添加列 alter table tablename add (column datatype) after 列
修改列 alter table tablename modify (column datatype)
删除列 alter table tablename drop (column)
查看表的结构 desc 表名 --查看表所有列
修改表名 rename table 表名 to 新表名
修改表字符集 alter table 表名 character set 字符集
修改列名 alter table tablename 列名 新列名 datatypeInsert
insert into tablename [(column)] values [(value)]
update
update tablename set colname = expr1[colnames] [where where_definition] 
delete
delete from tablename [where where_definition]
select
select [distinct] *|[column1,column2] from tablename
distinct表示是否去掉重复数据(每一行相同)使用表达式对查询的列进行运算
select *|{column1 | expression1 ,column2 | expression2,...} from tablename
select name , (chinese+english+math) as total_score from student在select语句中可使用as语句
select column as 别名 from tablename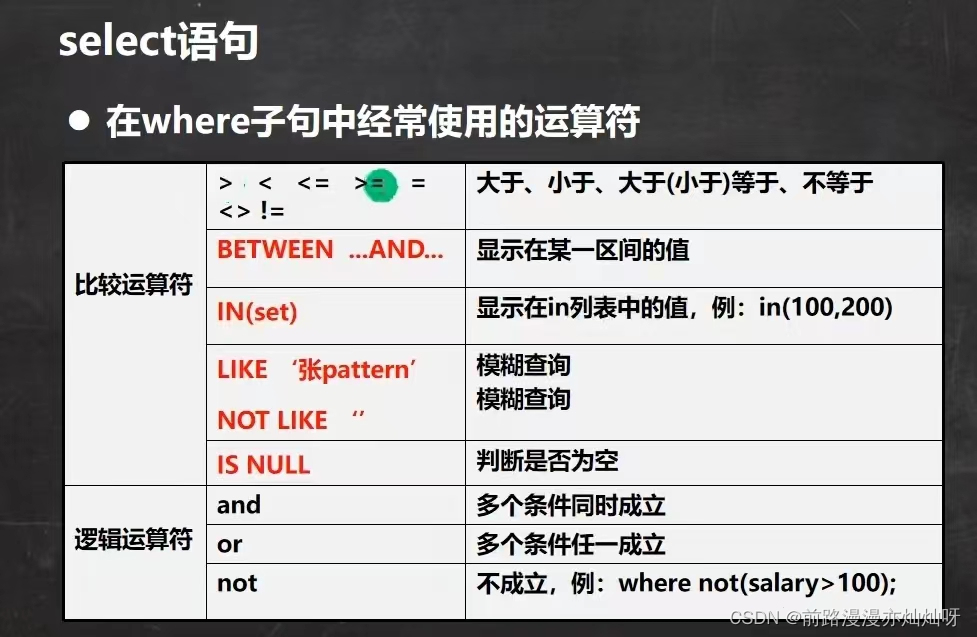
使用order by 子句排序查询结果
select column1,column2,column3,... from tablename order by column asc|desc,...
#按照部门号升序而雇员的薪资降序排列
select * from emp order by deptno asc ,sal desc
合计/统计函数
count 返回行的总数
select count(*)|count(列名) from tablename [where where_definition]
count(*) 返回满足条件的记录的数量
count(列) 统计满足条件的某列有多少个,但是会排除为nullsum返回满足条件的行的和,仅对数值起作用,否则会报错
select sum(列名) ,sum(列名),... from tablename [where where_definition]
#统计一个班数学总成绩
select sum(math) from studentavg函数返回满足where条件的一列的平均值
select avg(列名),avg(列名) from tablename [where where_definition]max/min返回满足where条件的一列的最大值/最小值
select max(列名) from tablebname [where where_definition]使用group by 子句对列进行分组
select column1,column2... from table group by column
#显示每种岗位的雇员总数,平均工资
select count(*),avg(sal),job from emp group by job
#显示雇员数,以及获得补助的雇员数
select count(*),count(comm) from emp
#显示雇员数,以及没有获得补助的雇员数
select count(*),count(if comm is null,100,null) from emp
使用having子句对分组后的结果进行过滤
select column1,column2,column3,... from table group by column having 表达式字符串相关函数
concat将多个列拼接成一列
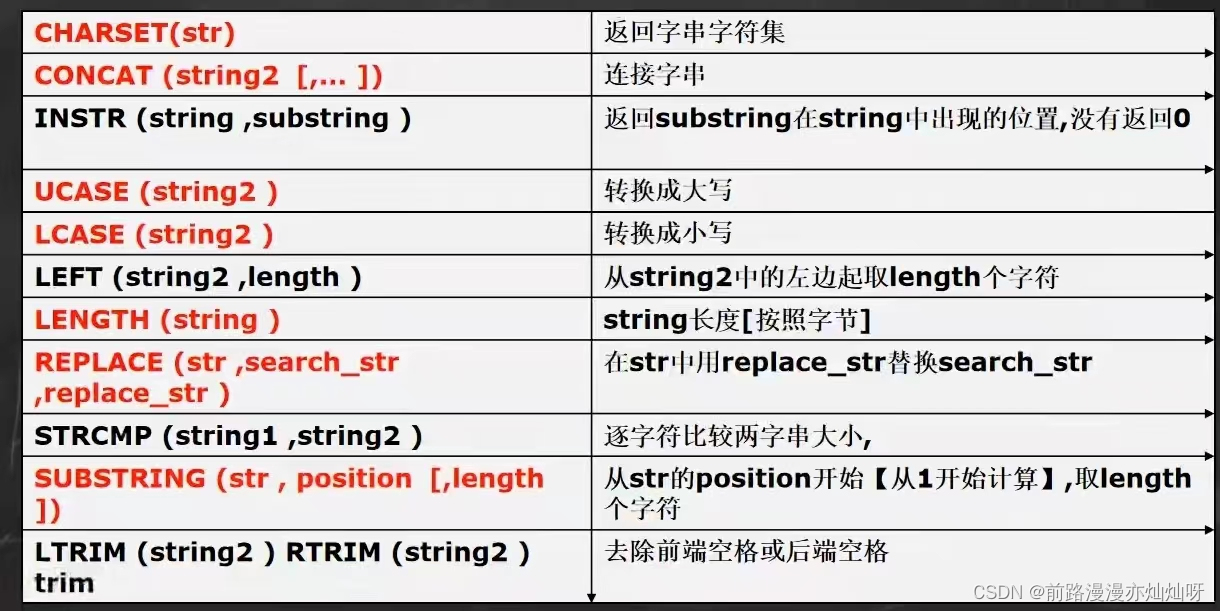
#以首字母小写的方式显示所有员工姓名
select concat(lcase(substring(ename,1,1)),substring(ename,e)) as new_name from emp数学相关函数

时间日期相关函数

#查询10分钟以内发布的新闻
select * from mes where date_add(send_time,interval 10 minute) >= now()#显示所有新闻,发布日期只显示日期,不显示时间
select id,content,date(send_time) from mes#求出2011-11-11和1990-1-1相差多少天
select datediff('2011-11-11','1990-1-1') from dual#如果你能活80岁,求出你还能活多少天
select DateDiff(date_add("2000-11-11",interval 80 year),now()) from dualunix_timestamp() 返回1970-1-1到现在的秒数
from_unixtime() 可以把一个unix_timestamp秒数,转成指定格式的日期
select FROM_UNIXTIME(UNIX_TIMESTAMP(),'%Y-%m-%d %H:%i:%s') from dual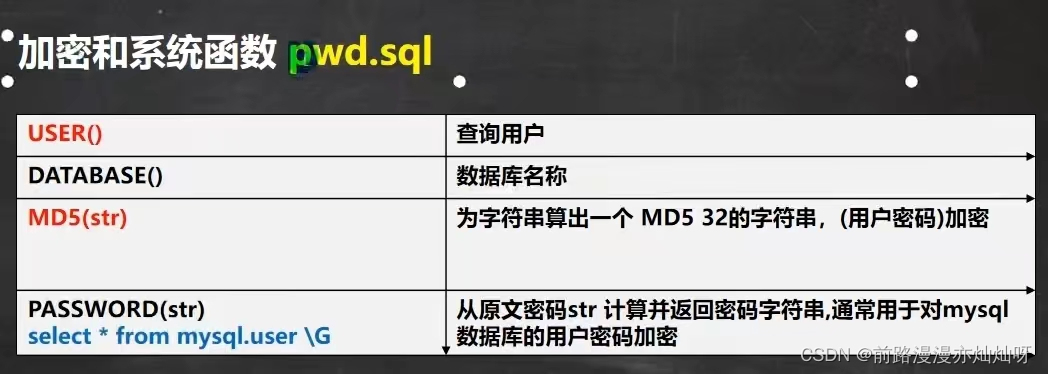
select user() from dual
select database() from dual
select database() from dual
insert into user values(100,'xu',md5('xiang'))#插入
select * from user where md5('xiang')#查询流程控制函数
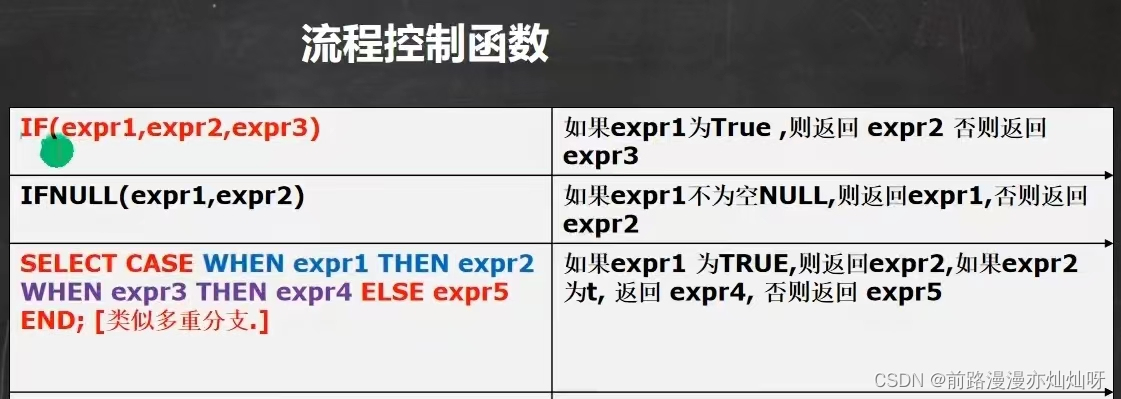
select ename,if(comm is null,0.0,comm) from emp
select ename,(select case when job = 'CLERK' then '职员' when job = 'manager' then '经理' when job = 'saleman' then '销售人员') from emp模糊查询
like操作符
%:表示0到多个任意字符
_:表示单个任意字符
判断某一列的值是否为空使用is null 而非 =
#查询以S开头的所有员工
select ename,sal from emp where ename like "S%"
#查询没有上级的员工
select * from emp where mgr is null分页查询
如果select同时包含有group by,having,limit,order by那么他们的顺序是group by,having,order by,limit,顺序错误报语法错
多表查询
笛卡尔积:当两个表查询时,从第一张表中取出一行和第二张表的每一行进行组合,返回结果【含两张表的所有列】
#显示雇员名,雇员工资以及所在部门的名字,并按部门降序排序
select ename,sal,dname,emp.deptno from emp,dept where emp.deptno=dept.deptno
#显示各个员工的姓名,工资,及其工资级别
select ename,sal,grade from emp,salgrade where sal between losal ans hisal自连接:在同一张表的连接查询【将同一张表看作是两张表 需要取别名】,
#显示公司员工和他的上级的名字(每一个员工都有一个编号(mgr),一行中显示的是他的编号)
select worker.ename , boss.ename from emp worker,emp boss where worker.mgr = boss.empno子查询:嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:只返回一行数据的子查询语句
多行子查询:返回多行数据的子查询,使用关键字in
将子查询结果当作一张临时表
在多行子查询中使用all操作符
在多行子查询中使用any操作符
多列子查询:返回多个列数据的子查询语句
#显示与SMITH同一个部门的所有员工
1、先查询到SMITH的部门号
2、把上面的select语句当作一个子查询来使用
select * from emp where deptno = (
select deptno from emp where ename = 'SMITH'
)#查询和部门10的工作相同的员工但是不含部门10自己的员工
select ename,job,sal,deptno from emp where job in (
select distinct job
from emp
where deptno = 10
) and deptno <> 10
#查询ecs_goods中各个类别中,价格最高的商品
select goods_id,temp.cat_id,goods_name,shop_price from (
select cat_id,max(shop_price)
from ecs_goods
group by cat_id
) temp,ecs_goods
where temp.cat_id = ecs_goods.cat_id and temp.max(shop_price) = ecs.goods.shop_price#显示工资比所有30的所有员工的工资高的员工姓名、工资、部门号
select ename,sal,deptno from emp where sal > all(
select sal from emp where deptno = 30
)
#显示工资比部门30的其中一个员工的工资高的员工姓名、工资、部门号
select ename,sal,deptno from emp where sal > any(
select sal from emp where deptno = 30
)
#查询与Smith的部门和岗位完全相同的所有雇员不包含Smith本人
select * from emp where (deptno,job) = (
select deptno,job from emp where ename='smith'
) and ename <> 'smith'
多表子查询练习
#查找每个部门工资高于该部门平均工资的人的资料
select * from emp,(
select dempno,avg(sal) from emp group by deptno
) temp where temp.deptno = emp.deptno and emp.sal > temp.sal表复制
自我复制数据(蠕虫复制):有时为了对某个sql语句进行效率测试,我们需要海量数据时,可以用此法为表创建海量数据
create table my_table(
id int,
name varchar(32),
sal double,
job varchar(32),
deptno int
);
insert into my_table (id,name,sal,job,deptno)
select empno,ename,sal,job,deptno from emp
#自我复制
insert into my_table
select * from my_table
#删除一张表中的重复记录
create table my_table2 like emp 复制结构
insert into my_table2
select distinct * from emp合并查询
为了合并多个select语句的结果,可以使用union(去重),union all(不去重)
mysql外连接

#使用左外连接显示所有人的成绩,如果没有成绩,也要显示改人的姓名和id号,成绩显示为空
select stu.id,name,grade
from stu left join exam
on stu.id = exam.id
#使用右外连接,显示所有成绩,如果没有名字匹配,就显示空
select stu.id,name,grade
from stu right join exam
on stu.id = exam.idmysql约束:用于确保数据库满足特定的商业规则
not null,unique(唯一,如果没有指定not null,unique字段还是可以有多个null,一张表可以有多个unique),primary key(不可重复且不为空),foreign key,check(用于强制数据必须满足的条件)
#复合主键
create table mytable(
id int,
name varchar(32),
email varchar(32),
primary key(id,name)
); 
自增长
字段名 整形 primary key auto_incrementcreate table mytable(
id int primary key auto_increment,
name varchar(32) CHECK(name in ('man','woman')),
email varchar(32)
)
INSERT into mytable value(null,'man','12345')
索引
#empno_index 索引名称 on emp(empno) 表示在emp表的empno列创建索引 索引占用磁盘空间
#只对创建了索引的列有效
create index empno_index on emp(empno)索引的原理
没有索引时,会进行全表扫描
索引代价 1、磁盘占用 2、对DML(update delete insert)语句的效率影响

#查询表是否有索引
show indexes from tablename
show keys from tablename
#如果某列的值是不会重复的,则优先使用unique索引,否则使用普通索引
#添加唯一索引
create unique index in_index on tablename(列)
#添加索引
create index in_index on tablename(列)
alter table tablename add index id_index (列)
#添加主键索引
alter table tablename add primary key (列)
#删除索引
drop index in_index on tablename
#删除主键索引
alter table tablename drop primary key
#修改索引 先删除再添加

mysql事务
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功,要么全部失败
当执行事务操作时,mysql会在表上加锁,防止其他用户改表的数据,这对用户来讲是非常重要的
#mysql数据库控制台事务的几个重要操作
start transaction --开始一个事务
savepoint 保存点名 --设置保存点
rollback to 保存点名 --回退事务
rollback --回退全部事务
commit --提交事务,所有的操作生效,不能回退create table t27(
id int,
name varchar(32)
)
start TRANSACTION
SAVEPOINT A
INSERT INTO t27 values(100,'tom')
select * from t27
SAVEPOINT B
insert into t27 values(200,'jack')
ROLLBACK to b
select * from t27


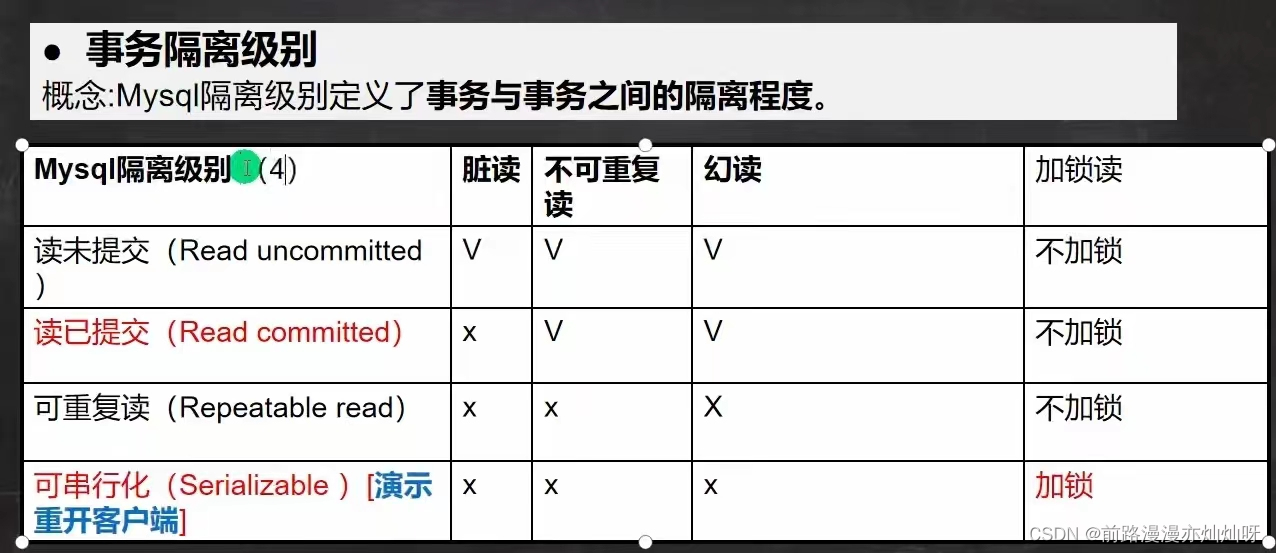
#查看当前会话隔离级别
select @@transaction_isolation
#查看系统当前隔离级别
select @@global.transaction_isolation
#设置当前会话隔离级别
set session transaction isolation level read uncommitted
#设置系统隔离级别
set global transaction isolation level read uncommitted

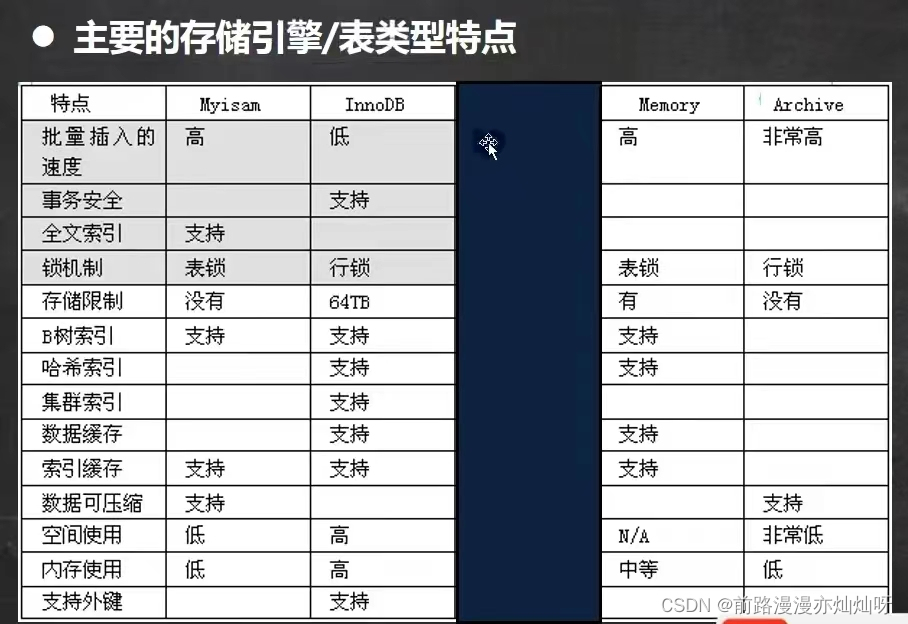


#修改存储引擎
alter table tablename engine = innodb视图是一个虚拟表,其内容由查询定义,同真实表一样,视图包含列,其数据来自于对应的真实表,只有结构文件,没有数据文件,是映射关系,数据修改都会影响对方,视图中可以再使用视图,还是映射基表

create view emp_view
as select empno,ename,job,dempno from emp
select * from emp_view
#查看创建视图的指令
show create view emp_view
#针对emp,dept和salgrade这三张表,创建一个视图emp_view,显示雇员编号,雇员名,雇员部门名称和薪水级别【使用三张表构建一个视图】
create view as emp_view as
select empno,ename,dname,grade from emp,dept,salgrade
where emp.dempno = demp.deptno and (sal between losal and hisal)mysql用户
mysql用户,都存储在系统数据库MySQL中user表中
user表字段的说明
host:允许登录的位置,localhost表示该用户只允许本机登录,也可以指定IP地址
user:用户名
authentication_string:密码,是通过MySQL的password()函数加密后的密码
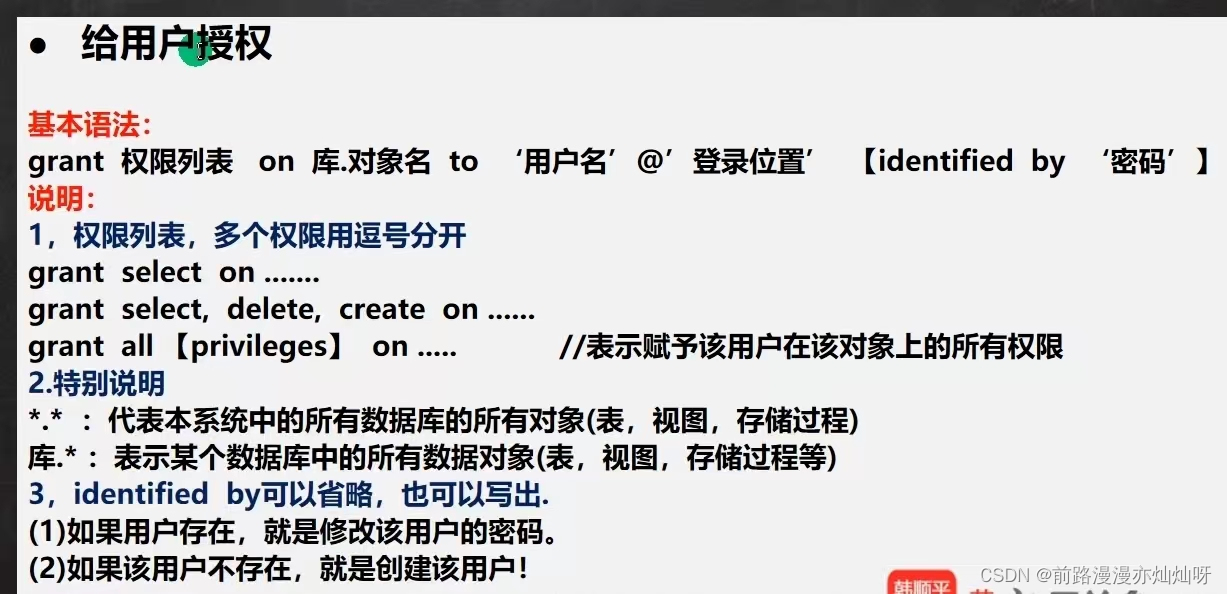
#创建用户
create user 用户名@允许登录的位置 identified by 密码
create user 'tom'@'localhost' identified by '12345'
#删除用户
drop user 'tom'@'localhost'
#修改自己的密码
set password = password('12345')
#修改其他用户的密码,需要权限
set password for 'root@localhost' = password('12345')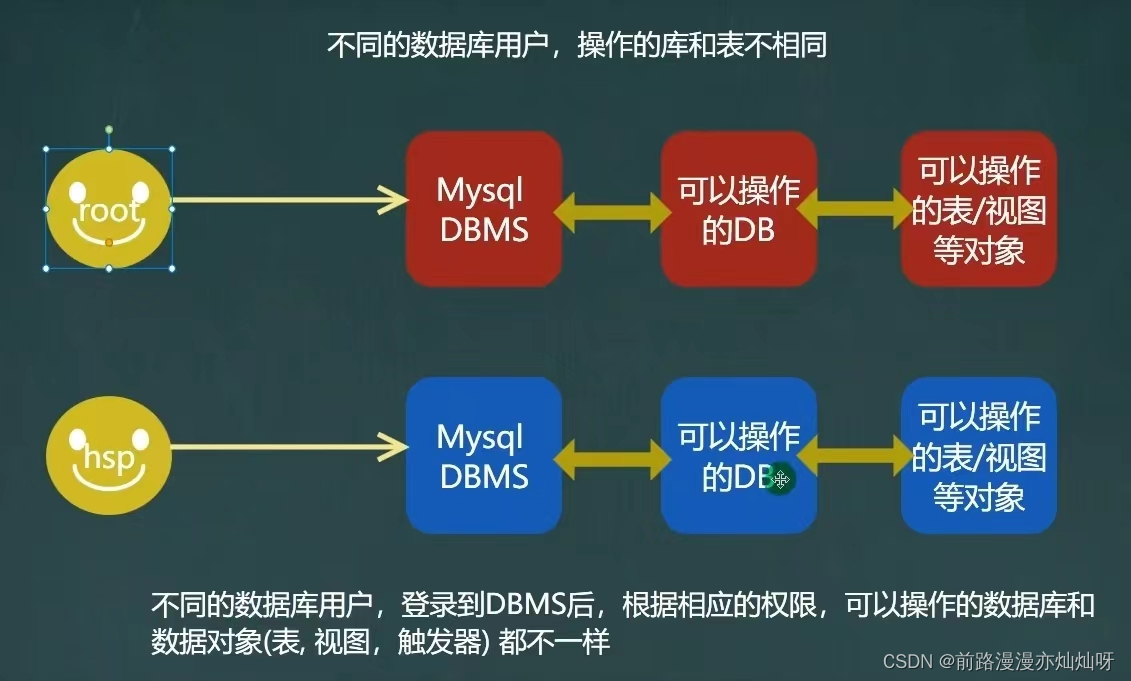

#创建用户xiang,密码12345,从本地登录
create user 'xiang@localhost' identified by '123'
#创建数据库和表
create database testdb
create table news(
id int,
content varchar(32)
)
#给用户分配查看news表和添加数据的权限
grant select,insert on testdb.news to 'tom'@'localhost'
#回收权限
revoke select,insert on testdb.news from 'tom'@'localhost'
#删除用户
drop user 'tom'@'localhost'
drop user 'jack' 默认 drop user 'jack'@'%'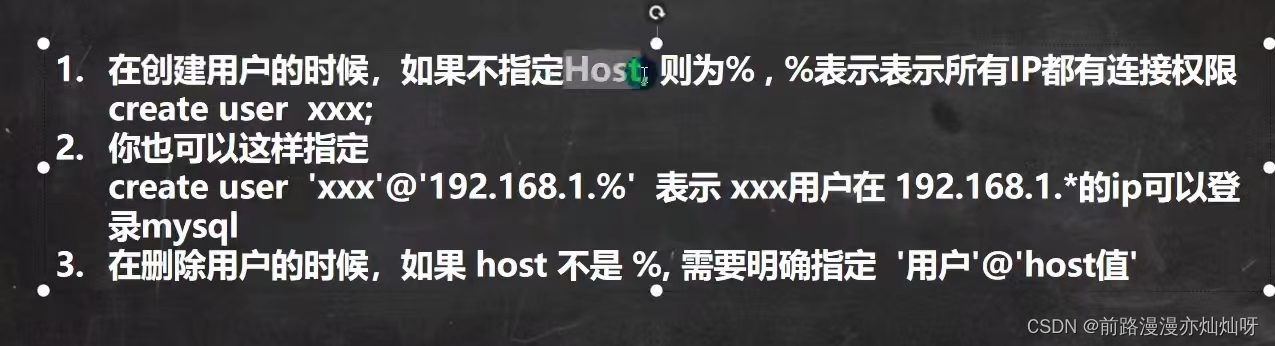















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









