







目录介绍
数据结构之——动态数组(顺序表)
1.动态数组和静态数组
静态数组:静态数组在内存中位于栈区,是在编译时就已经在栈上分配了固定大小,程序结束由系统释放。在运行时不能改变数组大小。
//静态数组
int N = 10;
int a[N]; /*定义一个数组大小为10的数组,因为静态数组在编译阶段就会确定数组大小,所以这里的N必须是一个确定的值
如果在这里没有给出N值的大小,会导致编译失败*/
动态数组:动态数组是malloc(在c语言中使用malloc函数)或者new(在c++中使用new操作符)出来的,位于内存的堆区,它的大小是在程序运行时给定的,可以动态的改变数组的大小,以及动态的增,删,查,改数组中的元素。
//动态数组
struct Array
{
int* a; //这里只需要定义一个指针,在程序运行起来之后如果在堆区开辟了一块数组空间,就让这个指针指向数组的首地址即可
int size; //size用于记录当前数组储存了多少个元素
int acpcaity; //acpcaity用于记录当前数组的容量大小(该数组最多能存储多少个元素)
}
2.如何维护一个动态数组
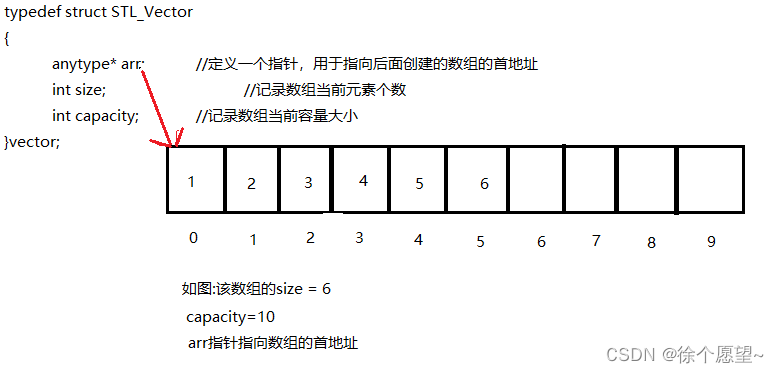
根据上图将维护一个数组分为以下三点:
1.当数组未创建时只需要让arr指针指向NULL,size,acpcaity都初始化为零,当成功在堆区创建了一个数组之后我们只需要把arr指针指向该数组的首地址即可。
2.每次对数组进行添加元素或者删除元素时,都要对应的对size进行相应的加减操作,size必须准确的记录数组中的元素个数
3.每次对数组扩容时都要实时更新当前数组大小给acpcaity,以便于更准确的控制数组大小如果acpcaity大于数组真实容量,可能导致程序崩溃。
列: 如果当前acpcaity=5;而当前数组实际容量为4,这时通过arr[4]插入第5个元素时,就会因为非法访问内存而导致程序崩溃
如果acpcaity小于数组真实容量,会导致数组频繁扩容,造成资源浪费。
以下是一个动态数组的小案列,用C语言实现c++中的vector容器(没有学过的c++的家人们完全可以忽略这句话,因为这就是一个简单动态数组的实现,vector容器的底层也是用动态数组实现的)
//头文件(vector.h)
#pragma once
#include<stdio.h>
//如果想储存其他数据类型只需将这里的int换成你想要储存的数据类型即可
typedef int anytype; //储存int类型的数据
//typedef double anytype; //储存double类型的数据
typedef struct STL_Vector
{
anytype* arr; //定义一个指针,用于指向后面创建的数组的首地址
int size; //记录数组当前元素个数
int capacity; //记录数组当前容量大小
}vector;
//接口函数
void VectorInit(vector * v); //初始化结构体
void Add_Capacity(vector* v); //当数组容量不够时扩容
void push_back(vector* v, anytype x); //尾部插入元素
void push_front(vector* v, anytype x); //头部插入元素
void My_print(vector v); //遍历数组
void pop_back(vector* v); //删除最后一个元素
int find(vector v, anytype x); //查找指定元素的位置,返回元素位置
void pop_front(vector* v); //删除第一个元素下标
int pos_insert(vector* v,int pos, anytype x);//指定下标位置插入元素
int pos_delect(vector* v, int pos); //指定下标位置删除元素
以下是接口函数的实现
//.c文件(vector.c)
#include"vector.h"
//初始化结构体
void VectorInit(vector* v){
v->arr = NULL;
v->capacity = v->size = 0;
}
//创建数组或对已经满的数组进行扩容
void Add_Capacity(vector* v){
if (v->size == v->capacity){ //当size=capacity时,说明数组可能还未创建,或数组已经满了
int newspace = v->capacity == 0 ? 4 : v->capacity * 2; /*如果数组容量为零就先给4个整形的大小,否则就在原来的
基础上乘以2,每次扩容2倍*/
anytype* tem = (anytype*)realloc(v->arr, newspace * sizeof(anytype));
/*1.扩容成功,返回新空间的地址
2.扩容失败,返回NULL*/
if (tem == NULL){
printf("扩容失败!");
exit(-1); //扩容失败直接退出程序
}
v->arr = tem;
v->capacity = newspace;
}
}
//尾插数据
void push_back(vector* v, anytype x){
Add_Capacity(v); //首先要确定数组是否创建,容量是否大于零,如果数据未创建,先创建数组,如果已创建但是容量已满,就扩容
if (v->arr != NULL){
v->arr[v->size] = x;
v->size++;
}
}
//头插数据
void push_front(vector* v, anytype x){
Add_Capacity(v);
int ret = v->size;
for (ret; ret>=0; ret--){
v->arr[ret] = v->arr[ret-1];
}
if (v->arr != NULL){
v->arr[0] = x;
v->size++;
}
}
//尾删数据
void pop_back(vector* v){
if (v->size > 0){ //首先判断数组中是否有数据,有数据才删除,以下同理
v->size--;
}
}
//头删数据
void pop_front(vector* v){
if (v->size > 0){
int ret = v->size;
for (int i= 0; i<ret; i++){
v->arr[i] = v->arr[i+1];
}
v->size--;
}
}
//查找数据,成功返回数据下标,失败返回-1
int find(vector v, anytype x){
if (v.size > 0){
for (int i = 0; i < v.size; i++){
if (v.arr[i] == x){
return i;
}
}
}
return -1;
}
//指定下标添加数据
int pos_insert(vector* v, int pos, anytype x){
Add_Capacity(v);
if (pos >= 0 && pos <= v->size){
int i = v->size;
for (i - 1; pos <= i; i--){
v->arr[i] = v->arr[i-1];
}
v->arr[pos] = x;
v->size++;
return 0;
}
return -1;
}
//指定下标删除数据
int pos_delect(vector* v, int pos){
Add_Capacity(v);
if (pos >= 0 && pos < v->size){
int i = v->size;
for (pos; pos < i; pos++){
v->arr[pos] = v->arr[pos+1];
}
v->size--;
return 0;
}
return -1;
}
//遍历数组
void My_print(vector v){
if (v.arr == NULL){
printf("数组未创建!\n");
return;
}
else if (v.size == 0){
printf("数组为空!\n");
return;
}
for (int i=0; i < v.size; i++){
printf("%d ",v.arr[i]);
}
printf("\n");
}
3.动态数组和静态数组的优缺点
静态数组:
优点:
(1).容量大小固定,下标固定,查找数据快,效率高
缺点:
(1).如果数组满了,就不能继续插入数据了
(2). 很难确定数组的容量大小,给大了浪费,给大小不够放
(3).同一个数组只能储存一种数据类型
动态数组:
优点:
(1).可以根据数据量的大小动态扩容和缩小容量
(2).可以通过下标快速查找数据
缺点:
(1).头插数据,中间插入数据时,需要挪动数据,速度慢效率低
(2).同一个数组只能储存一种数据类型
面试常见考点
1.请你说说delete和free的区别
(1). delete是操作符,free是库函数
(2). delete用于在c++中释放new创建的空间,free用于释放c语言中malloc创建的空间
(3). 调用free之前需要检查要释放的指针是否为空,而delete则不需要
2.请你说说malloc和new的区别
(1).new/delete是C++操作符,需要编译器支持,而malloc/free是库函数,需要引入头文件。
(2).使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要指定要开辟空间的大小。
(3). new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
(4).new内存分配失败时,会抛出bac_alloc异常。malloc分配内存失败时返回NULL。
(5). new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。
(6). C++允许重载new/delete操作符,特别的,布局new的就不需要为对象分配内存,而是指定了一个地址作为内存起始区域,new在这段内存上为对象调用构造函数完成初始化工作,并返回此地址。而malloc不允许重载。
(7).new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。
转载自
总结
顺序表应该是数据结构中最简单的一个了,接下来的时间我也会更加努力的学习,提升自己的同时给家人们带来更优质的文章,最后希望该篇文章能帮助到大家,作者本人水平有限,如果文章中错误或者不足的地方欢迎大家指出。















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











