






目录
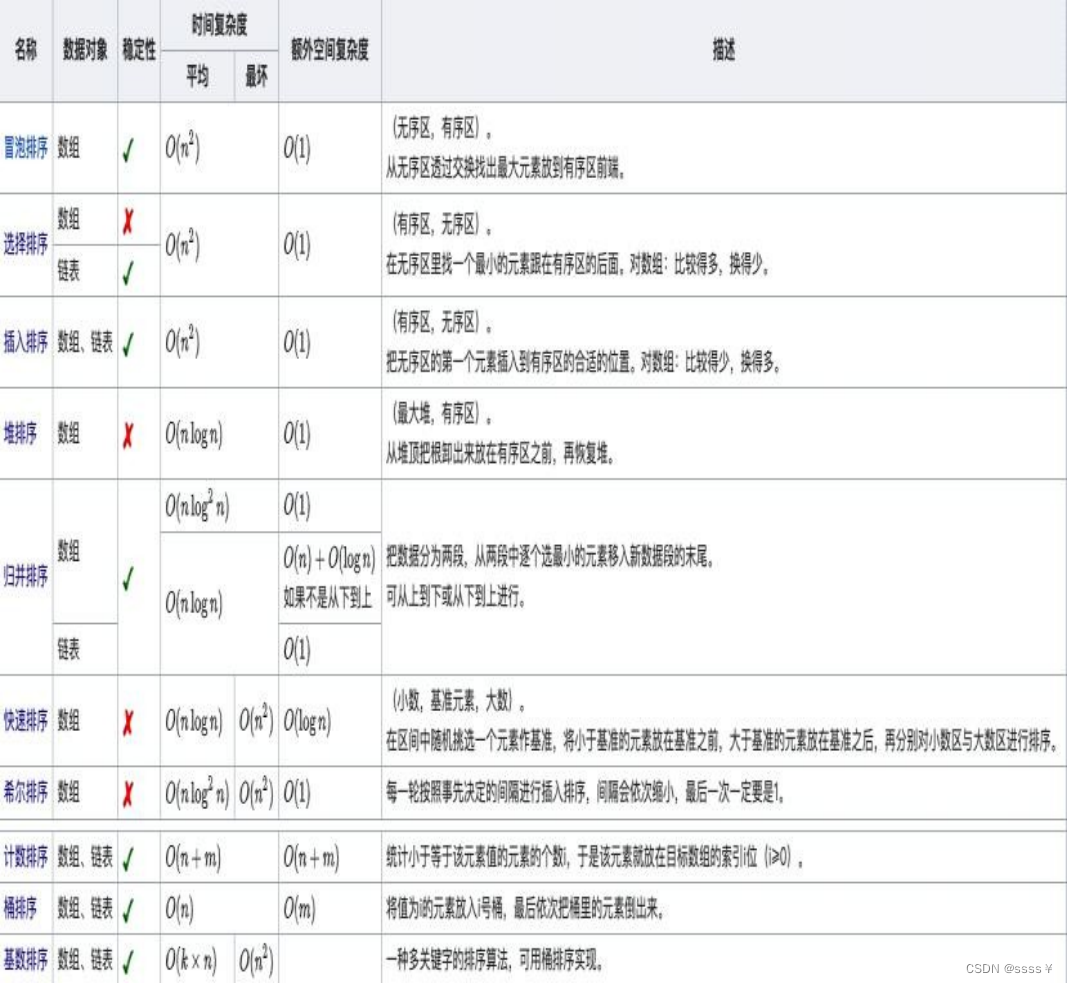
| 最好情况 | 平均情况 | 最坏情况 | 空间复杂 度 | 稳定性 | 内外排序 | 数据对象 | 常考点 | |
| 直接插入排序 | O(n) | O( | O( | O(1) | 稳定 | 内排序 | 数组,链表 |
|
| 希尔排序 | O(nlog2n) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | 内排序 | 数组 |
|
| 冒泡排序 | O(n) | O( | O( | O(1) | 稳定 | 内排序 | 数组 |  |
| 快速排序 | O(nlogn) | O(nlogn) | O( | O(logn)
| 不稳定 | 内排序 | 数组 |
|
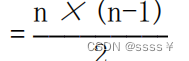
| 简单选择排序 | O(
| O( | O( | O(1) | 不稳定 | 内排序 | 数 组, 链表 |
|
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | 内排序 | 数组 |  |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 | 外排序 | 数组,链表 |
|
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O(r) | 稳定 | 外排序 | 数组,链表 |
|
第一类:插入排序
| 1.直接插入排序【 】 | 2.希尔排序【 】 | 3.折半插入排序 | |
| 原理 | 某节点前是排好序的,节点后是未排序的 未排序数据从后向前一一比较大小并交换数据边比较边移动元素 | 先 整个待排序的记录序列按增量分割成若干序列,每个序列分别直接插入排序然后不断减小增量的大小,直到序列有序 | 先折半查找出元素的待插入位置 然后统一地移动待插入位置后的所有元素 |
| 平均复杂度 | 0( | O(nlogn) | 0( |
| 稳定 性 | 稳定 | 不稳定 | 稳定 |
| 常考点 |
|
|
|
第二类:交换排序:(排序趟数与原始状态有关)
| 1.冒泡排序【 】 | 2.快速排序【 】 | |
| 原理 |
|
|
| 平均复杂 度 | 0( | 0(nlogn) |
| 稳定性 | 稳定 | 不稳定 |
| 常考点 |
代码: #include <stdio.h> void bubble_sort(int arr[], int len) { int i, j, temp; for (i = 0; i < len - 1; i++) for (j = 0; j < len - 1 - i; j++) if (arr[j] > arr[j+ 1]){ temp = arr[j]; arr[j] = arr[j+ 1]; arr[j + 1] =temp;} } int main() { int arr[] = {22, 34, 3,32, 82, 55, 89, 50, 37, 5, 64,35, 9, 70}; int len = (int)sizeof(arr) / sizeof(*arr); bubble_sort(arr, len); int i; for (i = 0; i < len; i++) printf("%d ", arr[i]); return 0; } |
|


第三类:选择排序
| 1.简 单选择排序【 】 | 2.堆排序【 】 | |
| 原理 |
|
|
| 平均复杂度 | 0( | 0(nlogn) |
| 稳定性 | 不稳定 | 不稳定 |
| 常考点 |
|  |
| 例图 |
|

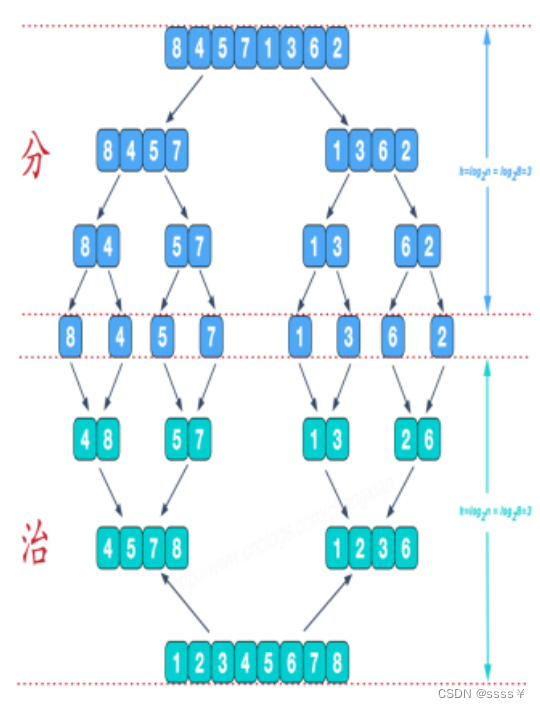
第四类:归并排序与基数排序
| 1. 并排序【 】 | 2.基数排序【 】 | |
| 原理 |
|
|
| 平均复杂度 | 0(nlogn) | O(n*k) |
| 稳定 性 | 稳定 | 稳定,外部排序 |
| 常考点 |
|
|
| 例图 |
|  |
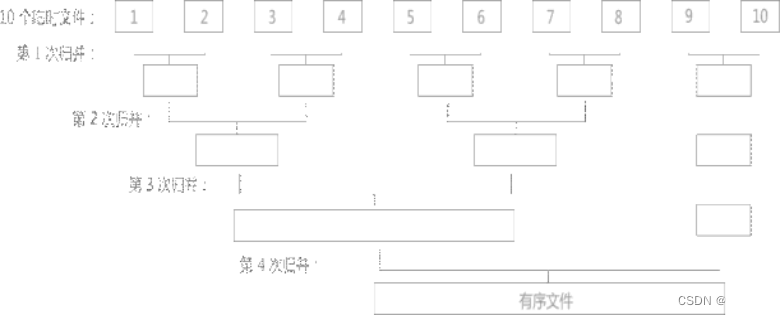
第五类:外部排序
| 概念 |
|
| 外部排序的阶段 |  |
| 举例 | 有一个含有 10000 个记录的文件,但是内存的可使用容量仅为1000 个记录,需要使用外部排序算法,具体步骤如下:
|

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









