







前言:
在计算机科学中,链表是一种常见的数据结构,用于存储和组织数据。相比于顺序表,链表具有更高的灵活性和动态性。
在本博客中,我们将深入讨论链表的概念、分类以及实现方法。我们将从链表的基本概念开始,了解链表是如何组织数据的,并分析链表的优势和劣势。
接下来,我们将探讨链表的分类。链表可以根据结构和特性分为多种类型,例如单链表、双链表、循环链表等。我们将详细介绍每种类型的链表,并讨论它们的特点和适用场景。
然后,我们将重点关注单链表的实现。单链表是最简单的链表形式,我们将学习如何使用指针来构建单链表,并实现基本的操作,如插入、删除和查找。
进一步,我们将学习带头双向循环链表的实现。带头双向循环链表是一种更复杂的链表形式,它具有双向遍历的能力,并且首尾相连形成一个循环。我们将详细讲解如何构建带头双向循环链表,并实现相关的操作。
最后,我们将比较链表和顺序表之间的区别。顺序表是另一种常见的数据结构,它使用连续的内存块来存储数据。我们将对比链表和顺序表的特点,分析它们在不同场景中的优劣势,以便更好地选择合适的数据结构。
通过学习本博客,您将对链表有一个全面的了解,并能够使用链表解决实际问题。希望本博客能够帮助您深入掌握链表的概念和实现,提升您的数据结构和算法能力。接下来,我们开始探索链表的奥秘吧!
个人主页:Oldinjuly的个人主页
收录专栏:数据结构
欢迎各位点赞👍收藏⭐关注❤️

目录
🌹1.链表的概念
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
和顺序表不同的是:
顺序表的空间是malloc出的一整块,是一块连续的空间;
而链表是一个一个结点组成,每一个结点都是单独malloc出的,并且结点结构体类型设置结构体的自引用,通过malloc返回的结点指针让这些结点连接起来。所以链表的存储空间非连续,在内存中是离散分布的。
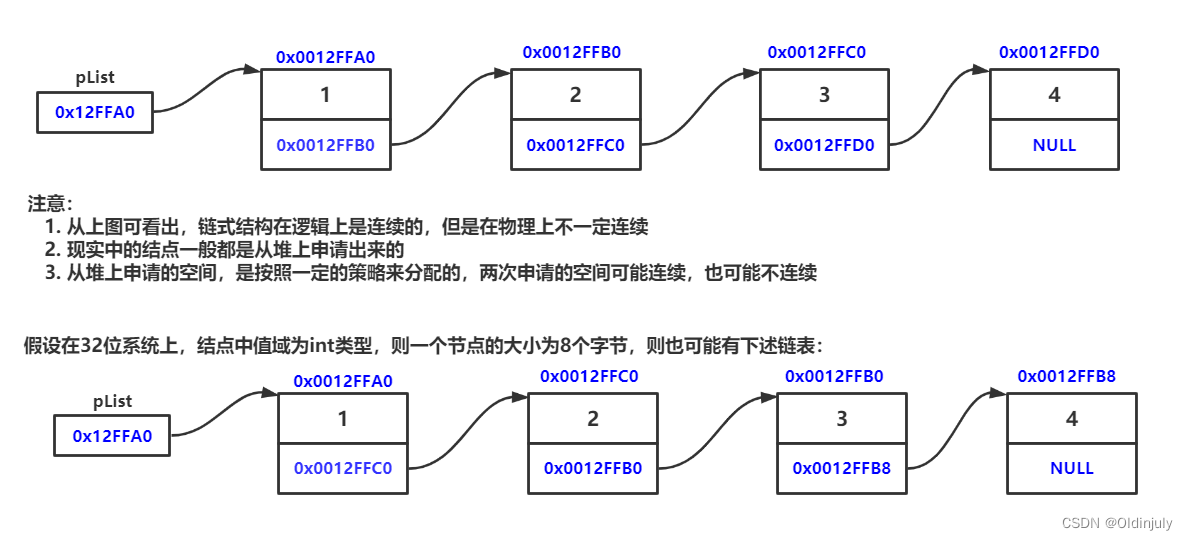

链表结点一定是在堆上创建的,不可能在栈上,原因如下:
- 生命周期:栈上的内存是由编译器自动分配和回收的,它的生命周期与函数的调用和返回相关联。一旦函数返回,栈上的内存就会被释放,其中的数据也就不再有效。而链表的结点需要在整个程序的执行过程中一直存在,它们之间通过指针进行连接。因此,需要在堆上创建结点,使其具有长时间的生命周期。
- 动态分配:链表的结点数量是动态变化的,当需要添加或删除结点时,需要动态地分配和释放内存空间。堆上的内存分配和释放由程序员手动控制,可以根据需要动态分配结点内存,并在不再需要时释放。而栈上的内存是由编译器自动管理的,无法手动控制内存的动态分配和释放。
- 灵活性:链表的结点大小可能不同,而且结点的数量也可能非常大。在堆上创建结点可以灵活地分配不同大小的内存空间,以满足具体的需求。而栈上的内存通常有限,并且大小是固定的,在创建结点时可能无法满足链表的需求。
综上所述,链表的结点需要在堆上创建,以确保其生命周期的长久性、动态分配的灵活性和内存空间的可控性。
🌹2.链表的分类
链表有以下三中分类方式:
1.带头或者不带头
带头就是带头结点,头结点不存数据,作为链表的哨兵位。
2.单向或者双向
双向:不仅有next指针,还有prev指针。
3.循环或者非循环
循环链表即尾结点的next指针指向头结点。
而我们实际常用的只有:
- 无头单向非循环链表
- 带头双向循环链表
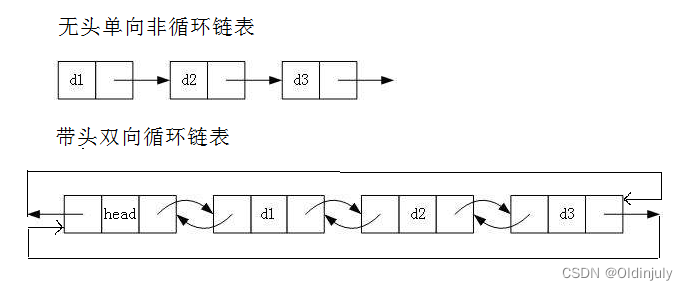
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。OJ题也基本都是这种结构。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
🌹3.单链表的实现
💐3.1 单链表打印
SList.c
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
phead是链表头指针,也就是链表第一个结点的指针。
cur是结点指针变量,通过cur=cur->next进行迭代来打印结点数据。
💐3.2 创建结点
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
BuySListNode函数创建结点,返回创建的结点指针。
💐3.3 单链表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySListNode(x);
//第一次插入时单独考虑
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
思考:
1.尾插是要找最后一个结点的(SLTNode* tail),那能不能这样找tail然后插入newnode?
//代码二 SLTNode* tail = *pphead; while (tail != NULL) { tail = tail->next; } tail = newnode;答:不可以,这种方式找尾结点时,碰到NULL退出循环,然后newnode给NULL,会发现newnode和尾结点没有连接上,并且会出现内存泄漏。没有连接上可以理解,但为什么会出现内存泄漏呢?这里我们要先知道:tail、newnode都是局部的指针变量,指针变量也是变量,那么局部变量的生命周期只在SLTPushBack()函数内部,出了作用域销毁,我们是无法获取函数内部的newnode和tail指针变量的,那么最新malloc出的堆区空间我们就无法收回导致泄露。
两种代码的区别:
代码一:
代码二:

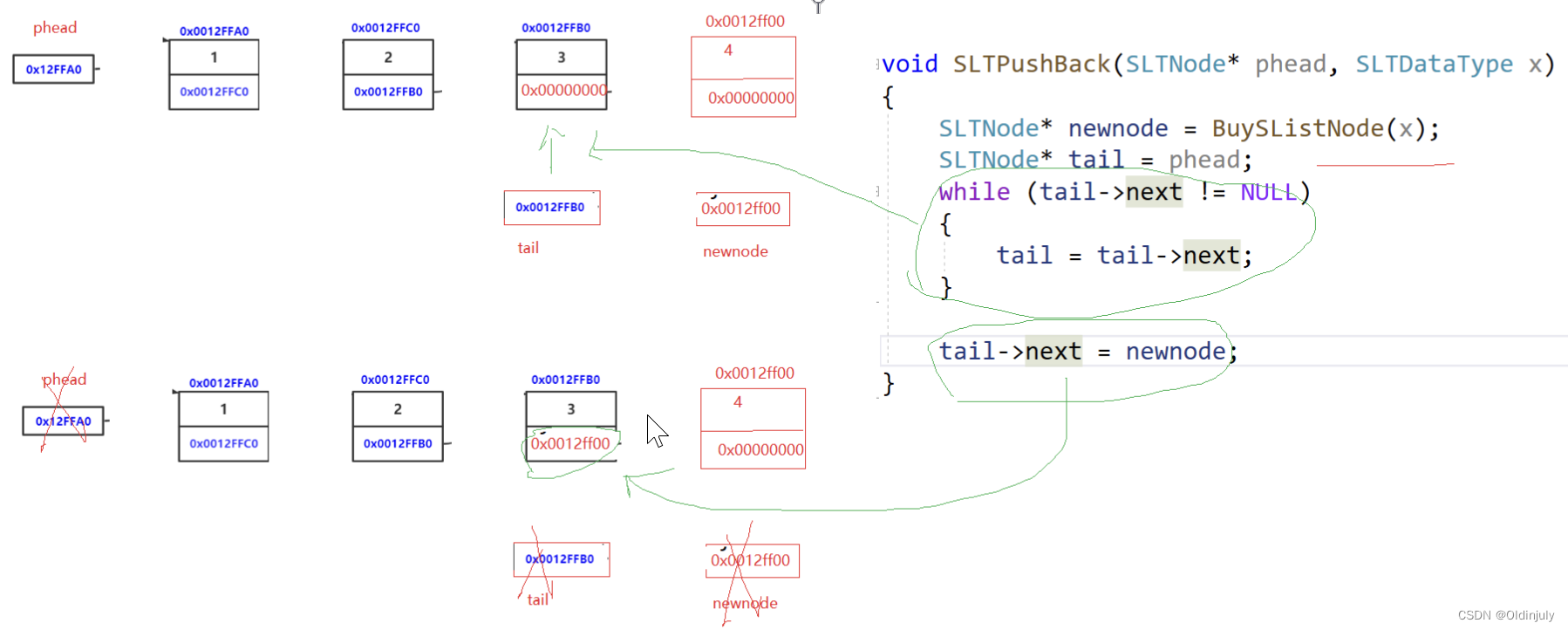
2.第一次插入时不存在什么尾结点,所以第一次插入要单独处理,直接赋值:phead=newnode。
3.头指针一定要传二级指针!!!
//SList.c void SLTPushBack(SLTNode* phead, SLTDataType x) { SLTNode* newnode = BuySListNode(x); //第一次插入时单独考虑 if (phead == NULL) { phead = newnode; } else { SLTNode* tail = phead; while (tail->next != NULL) { tail = tail->next; } tail->next = newnode; } } //test.c void TestSlist() { SLTNode* plist = NULL; SLTPushBack(plist,1); }这里形参是phead,实参是plist,形参是实参的一份拷贝,plist和phead是两个结构体指针变量,形参的改变并不会影响实参,也就是说第一次插入的时候修改phead,并不会修改函数外的plist,所以要传递plist的指针(也就是二级指针)。
void SLTPushBack(SLTNode** pphead, SLTDataType x) { assert(pphead); SLTNode* newnode = BuySListNode(x); //第一次插入时单独考虑 if (*pphead == NULL) { *pphead = newnode; } else { SLTNode* tail = *pphead; while (tail->next != NULL) { tail = tail->next; } tail->next = newnode; } } //test.c void TestSlist() { SLTNode* plist = NULL; SLTPushBack(&plist,1); }但是来说,修改谁,就传递谁的指针。我们要修改结构体指针plist,就传递结构体指针的指针&plist;我们要修改结构体,就传递结构体的指针,比如tail是结构体指针,可以直接修改结构体。
还有就是,SListPrint()函数不需要传递二级指针,因为只是打印,不做修改,拷贝的头指针变量也可以遍历。
💐3.4 单链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
注意:
- 头插的第一次插入不需要单独处理。
- 要改变头指针plist,传递二级指针。
💐3.5 单链表尾删
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);
//1.空
assert(*pphead);
//2.一个结点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//3.一个以上结点
else
{
SLTNode* tailPrev = NULL;
SLTNode* tail = *pphead;
while (tail->next)
{
tailPrev = tail;
tail = tail->next;
}
free(tail);
//tail = NULL;
tailPrev->next = NULL;
//另一种方法
/*SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;*/
}
}
注意:
- 能不能直接找到tail然后free掉?
答:不可以,否则tail的前驱结点tailPrev的next指针为野指针,没有置空。
- 需要传递二级指针吗?
答:需要!删除最后一个结点时要把plist置空成NULL,要改变头指针,所以传递二级指针。
- 一个结点删除时不需要找tailPrev,单独处理。
- 链表为空时,即*pphead==NULL时,不能删除,需要断言。
- free(tail)之后,tail需不需要置空?
答:tail没有必要置空tail=NULL,因为tail是函数内局部变量,置空后出了作用域要销毁,没有必要。
💐3.6 单链表头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);
//1.空
assert(*pphead);
//2.非空
SLTNode* newhead = (*pphead)->next;
free(*pphead);
*pphead = newhead;
}
- 和尾删不同,删最后一个结点不需要单独处理。
- 要改变头指针plist,传递二级指针。
- 空时不能删,需要断言。
💐3.7 单链表查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while(cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
- 只是查找,不需要传递二级指针。
- 函数返回结点结构体的指针SLTNode*
- 查找配合后面的Insert和Erase使用,返回的指针作为Insert和Erase函数的pos参数。
💐3.8 单链表插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else
{
SLTNode* prev = *pphead;;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySListNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
- 对pos断言,保证能找到插入的位置。
- 设置prev指针变量,便于结点的链接关系。
- 头插时没有prev指针一说,单独处理,直接复用头插函数。
//pos后面插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
InsertAfter不能头插。
在pos位置后面插入,参数不需要头指针pphead。
因为不需要prev指针变量,也就不需要头指针来找,而且不能头插也不会改变头指针。
💐3.9 单链表删除
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
- 对pos断言,保证找到删除的位置。
- 设置prev指针变量,并且单独处理头删。
- free(pos)后函数参数pos没有必要置空pos=NULL,实参的pos依然是野指针。
//pos后面删除
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
//pos不能删除尾结点后面的位置
assert(pos->next);
SLTNode* posNext = pos->next;
pos->next = posNext->next;
free(posNext);
}
EraseAfter不能头删,尾删时也没有意义。
参数只有pos,不需要头指针pphead,
因为不需要prev指针变量,也就不需要头指针来找,而且不能头删也不会改变头指针。
💐3.10 单链表销毁
void SLTDestory(SLTNode** pphead)//要把plist置空,传二级
{
assert(pphead);
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
🌹4.带头双向循环链表的实现
前面所说的单链表,其实是一个很挫的链表。因为尾插尾删需要找尾,时间复杂度是O(N),失去了链表插入删除的优势。所以单链表并不适合用来存储数据,那么就需要一个完美链表结构:带头双向循环链表。
带头双向循环链表相对单链表,虽然结构复杂了,但是实现却变的非常简单。具体如下:
- 二级指针问题:带头双向循环链表由于带有头结点,插入删除并不会修改头指针plist,只会修改结构体的next域,所以只需要传一级指针即可。
- 尾部插入删除的单独讨论问题:由于头节点的存在,带头双向循环链表的所有插入删除都不需要单独讨论。
- 尾部插入删除找尾节点的问题:由于带头双向循环链表是个循环链表,head->prev == tail,不需要从头结点开始找。
- Insert和Erase的头插头删单独讨论问题:头结点的存在,不需要单独讨论。
- Insert和Erase找posPrev的问题:posPrev == pos->prev,不需要从头结点开始找。
typedef struct LTNode
{
int data;
struct LTNode* next;
struct LTNode* prev;
}LTNode;
💐4.1 头结点初始化
void LTInit(LTNode* phead)
{
phead = (LTNode*)malloc(sizeof(LTNode));
if (phead == NULL)
{
perror("LTInit:");
exit(-1);
}
phead->data = -1;
phead->next = phead;
phead->prev = phead;
}
这是一种典型的错误,形参phead是外部的实参plist的拷贝,phead的修改不会影响plist。
所以这里要传二级指针,但是传二级和后面的插入删除又显得格格不入,所以我们设置返回值来解决这个问题。
LTNode* LTInit()
{
LTNode* phead = (LTNode*)malloc(sizeof(LTNode));
if (phead == NULL)
{
perror("LTInit:");
exit(-1);
}
phead->data = -1;
phead->next = phead;
phead->prev = phead;
return phead;
}
💐4.2 尾插
创建结点:
LTNode* BuyNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("BuyNode:");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
尾插:
void LTPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = BuyNode(x);
LTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}
💐4.3 尾删
void LTPopBack(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
LTNode* tail = phead->prev;
LTNode* tailPrev = phead->prev->prev;
free(tail);
tailPrev->next = phead;
phead->prev = tailPrev;
}
💐4.4 头插
void LTPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = BuyNode(x);
LTNode* next = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next = next;
next->prev = newnode;
}
💐4.5 头删
void LTPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
LTNode* first = phead->next;
LTNode* second = first->next;
free(first);
phead->next = second;
second->prev = phead;
}
从头删和头插中可以看出,多设置几个指针变量,可以让代码更加简洁,指针链接更加方便。
💐4.6 查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
有一个非常重要的一点:带头结点的双向循环链表,第一个节点是phead->next。千万不然让cur从phead开始走,因为循环结束条件是cur == phead,这样循环一开始就结束。
💐4.7 插入
void LTInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* posPrev = pos->prev;
LTNode* newnode = BuyNode(x);
posPrev->next = newnode;
newnode->prev = posPrev;
newnode->next = pos;
pos->prev = newnode;
}
💐4.8 删除
void LTErase(LTNode* pos)
{
assert(pos);
LTNode* posPrev = pos->prev;
LTNode* posNext = pos->next;
free(pos);
posPrev->next = posNext;
posNext->prev = posPrev;
}
💐4.9 结点个数
int LTSize(LTNode* phead)
{
assert(phead);
int size = 0;
LTNode* cur = phead->next;
while (cur != phead)
{
++size;
cur = cur->next;
}
return size;
}
💐4.10 销毁
void LTDestory(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
}
🌹5.顺序表和链表的区别
















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









