






一、项目介绍
1.1 赛题背景
赛题以计算机视觉为背景,要求选手使用给定的航拍图像训练模型并完成地表建筑物识别任务,具体包括语义分割的模型和具体的应用案例。
1.2 赛题描述及数据说明
遥感技术已成为获取地表覆盖信息最为行之有效的手段,遥感技术已经成功应用于地表覆盖检测、植被面积检测和建筑物检测任务。本赛题使用航拍数据,需要参赛选手完成地表建筑物识别,将地表航拍图像素划分为有建筑物和无建筑物两类。
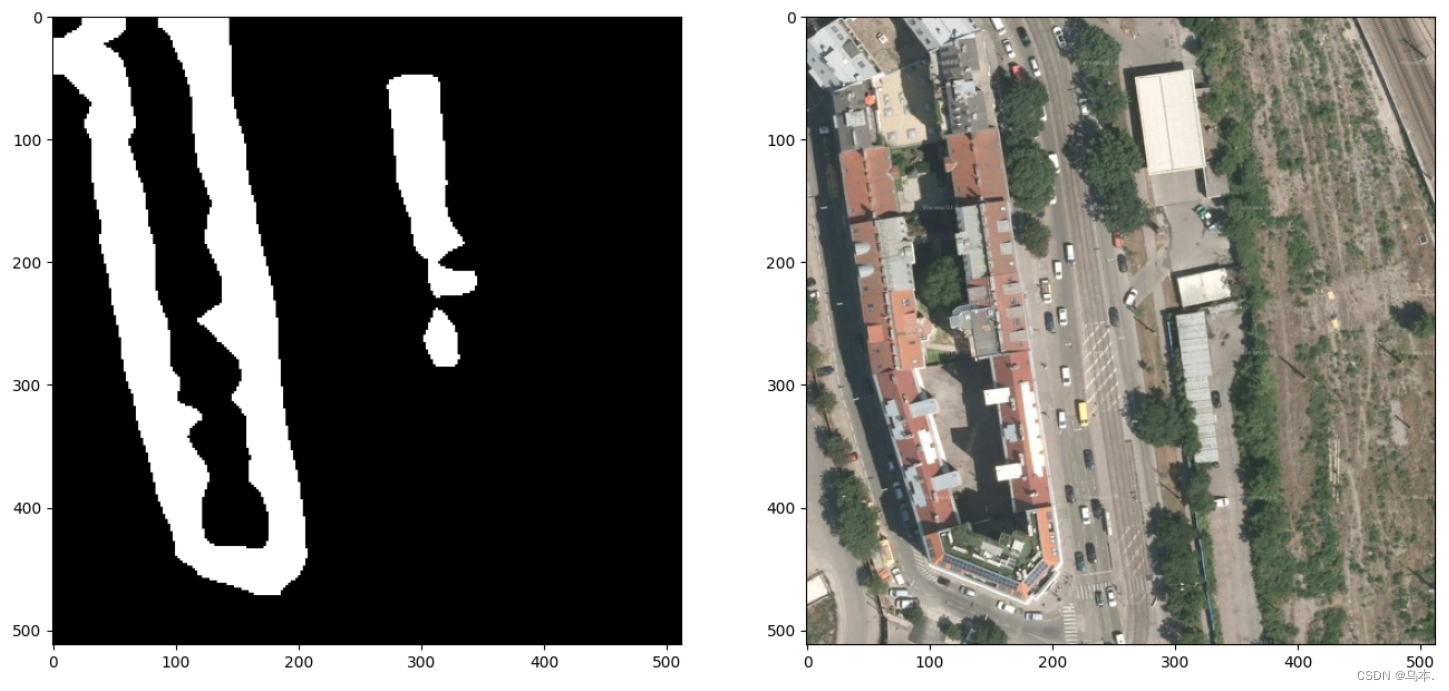
如下图,左边为原始航拍图,右边为对应的建筑物标注。

二、数据准备和预处理
在赛题数据中像素属于2类(无建筑物和有建筑物),因此标签为有建筑物的像素。赛题原始图片为jpg格式,标签为RLE编码的字符串。
2.1 获取数据
1、下载数据集文档

2、通过天池实验室下载数据集或直接复制链接下载数据集
!wget md文件中的数据集链接
3、通过天池实验室解压数据集或本地解压
在天池实验室新建Terminnal并输入指令。
unzip 压缩包名2.2 数据预处理
数据扩增作为一种有效的正则化方法,可以防止模型过拟合,目的是增加数据集中样本的数据量,同时也可以有效增加样本的语义空间。
常见的数据增广方法包含:OpenCV数据扩增、albumentations数据扩增、Pytorch数据读取等。
# 创建一个图像增强和预处理的操作序列
trfm = A.Compose([
A.Resize(IMAGE_SIZE, IMAGE_SIZE),
A.HorizontalFlip(p=0.5), # 0.5概率的水平翻转
A.VerticalFlip(p=0.5), # 0.5的概率垂直翻转
A.RandomRotate90(), # 随机对图像进行90°旋转
])在本次任务中,对于预处理过的数据进行数据增强处理,使用albumentations库中的Compose函数构建了一个图像增强和预处理的操作序列trfm,通过定义这些图像增强和预处理操作,可以在训练过程中增加数据的多样性,提高模型的泛化能力和训练效果。
三、模型选择与训练
3.1 模型选择
FCN-ResNet-50 是一种神经网络模型,结合了 Fully Convolutional Network (FCN) 和 Residual Network (ResNet) 的特性。
具体来说,FCN-ResNet-50 结合了 FCN 的图像分割能力和 ResNet 的深度特征学习能力,使得它在图像分割任务中具有较好的性能。ResNet-50 作为 ResNet 中的一个变种,它具有 50 层深度的网络结构,同时包含多个残差块,以提取更丰富的特征信息。将 FCN 与 ResNet-50 结合在一起,可以在图像分割任务中获得更高的准确性和鲁棒性。
# 创建并返回一个FCN-ResNet-50模型
def get_model():
model = torchvision.models.segmentation.fcn_resnet50(True)
model.classifier[4] = nn.Conv2d(512, 1, kernel_size=(1, 1), stride=(1, 1))
return model
@torch.no_grad()
def validation(model, loader, loss_fn):
losses = []
model.eval()
for image, target in loader:
image, target = image.to(DEVICE), target.float().to(DEVICE)
output = model(image)['out']
loss = loss_fn(output, target)
losses.append(loss.item())
return np.array(losses).mean()3.2 模型训练
1、读取数据集图像数据。
# 从名为train_mask.csv的文件中读取数据,使用制表符(\t)作为分隔符,指定列名为name和mask,
# 并将读取的数据存储在DataFrametrain_mask中
train_mask = pd.read_csv('./train_mask.csv', sep='\t', names=['name', 'mask'])
train_mask['name'] = train_mask['name'].apply(lambda x: './train/' + x)
img = cv2.imread(train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
print(rle_encode(mask) == train_mask['mask'].iloc[0])2、参数传递。
# 创建的dataset实例将用于训练数据集的加载和处理
dataset = TianChiDataset(
train_mask['name'].values,
train_mask['mask'].fillna('').values,
# trfm:前面定义的数据增强操作trfm,用于对图像和mask进行增强操作
# False:设置为训练模式
trfm, False
)四、模型评估与优化
4.1 评价参数
赛题使用Dice coefficient来衡量选手结果与真实标签的差异性,Dice coefficient可以按像素差异性来比较结果的差异性。
Dice系数(Dice coefficient)是常见的评价分割效果的方法之一,同样也可以改写成损失函数用来度量prediction和target之间的距离。同时Dice系数与分类评价指标中的F1 score很相似,通过公式可以观察出Dice系数不仅在直观上体现了target与prediction的相似程度,同时其本质上还隐含了精确率和召回率两个重要指标。
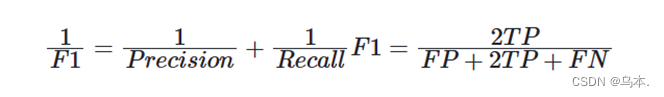
4.2 模型优化
1、通过优化器对模型进行梯度下降等操作
EPOCHES = 5
best_loss = 10
for epoch in range(1, EPOCHES+1):
losses = []
start_time = time.time()
model.train()
for image, target in tqdm_notebook(loader):
image, target = image.to(DEVICE), target.float().to(DEVICE)
# 对优化器进行梯度归零、模型向前传播、计算损失、反向传播和参数更新
optimizer.zero_grad()
output = model(image)['out']
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
# print(loss.item())
vloss = validation(model, vloader, loss_fn)
print(raw_line.format(epoch, np.array(losses).mean(), vloss,
(time.time()-start_time)/60**1))
losses = []
if vloss < best_loss:
best_loss = vloss
torch.save(model.state_dict(), 'model_best.pth')2、自定义损失计算
class SoftDiceLoss(nn.Module):
def __init__(self, smooth=1., dims=(-2,-1)):
super(SoftDiceLoss, self).__init__()
self.smooth = smooth
self.dims = dims
def forward(self, x, y):
tp = (x * y).sum(self.dims)
fp = (x * (1 - y)).sum(self.dims)
fn = ((1 - x) * y).sum(self.dims)
dc = (2 * tp + self.smooth) / (2 * tp + fp + fn + self.smooth)
dc = dc.mean()
return 1 - dc
3、二分类交叉熵损失计算
# 定义二分类交叉熵损失函数
bce_fn = nn.BCEWithLogitsLoss()
dice_fn = SoftDiceLoss()
def loss_fn(y_pred, y_true):
bce = bce_fn(y_pred, y_true)
dice = dice_fn(y_pred.sigmoid(), y_true)
return 0.8*bce+ 0.2*dice4、输出效果测试

4.3 完整代码
import numpy as np
import pandas as pd
import pathlib, sys, os, random, time
import numba, cv2, gc
from tqdm import tqdm_notebook
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from tqdm.notebook import tqdm
import albumentations as A
import rasterio
from rasterio.windows import Window
def rle_encode(im):
'''
im: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels = im.flatten(order = 'F')
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)
def rle_decode(mask_rle, shape=(512, 512)):
'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape, order='F')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as D
import torchvision
from torchvision import transforms as TEPOCHES = 5
BATCH_SIZE = 8
IMAGE_SIZE = 256
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
trfm = A.Compose([
A.Resize(IMAGE_SIZE, IMAGE_SIZE),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(),
])
class TianChiDataset(D.Dataset):
def __init__(self, paths, rles, transform, test_mode=False):
self.paths = paths
self.rles = rles
self.transform = transform
self.test_mode = test_mode
self.len = len(paths)
self.as_tensor = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
def __getitem__(self, index):
img = cv2.imread(self.paths[index])
if not self.test_mode:
mask = rle_decode(self.rles[index])
augments = self.transform(image=img, mask=mask)
return self.as_tensor(augments['image']), augments['mask'][None]
else:
return self.as_tensor(img), ''
def __len__(self):
"""
Total number of samples in the dataset
"""
return self.lentrain_mask = pd.read_csv('./train_mask.csv', sep='\t', names=['name', 'mask'])
train_mask['name'] = train_mask['name'].apply(lambda x: './train/' + x)
img = cv2.imread(train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
print(rle_encode(mask) == train_mask['mask'].iloc[0])# 创建的dataset实例将用于训练数据集的加载和处理
dataset = TianChiDataset(
train_mask['name'].values,
train_mask['mask'].fillna('').values,
trfm, False
)image, mask = dataset[0]
plt.figure(figsize=(16,8))
plt.subplot(121)
plt.imshow(mask[0], cmap='gray')
plt.subplot(122)
plt.imshow(image[0]);

valid_idx, train_idx = [], []
for i in range(len(dataset)):
if i % 7 == 0:
valid_idx.append(i)
# else:
elif i % 7 == 1:
train_idx.append(i)
train_ds = D.Subset(dataset, train_idx)
valid_ds = D.Subset(dataset, valid_idx)
# define training and validation data loaders
loader = D.DataLoader(
train_ds, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
vloader = D.DataLoader(
valid_ds, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)# 创建并返回一个FCN-ResNet-50模型
def get_model():
model = torchvision.models.segmentation.fcn_resnet50(True)
model.classifier[4] = nn.Conv2d(512, 1, kernel_size=(1, 1), stride=(1, 1))
return model
@torch.no_grad()
def validation(model, loader, loss_fn):
losses = []
model.eval()
for image, target in loader:
image, target = image.to(DEVICE), target.float().to(DEVICE)
output = model(image)['out']
loss = loss_fn(output, target)
losses.append(loss.item())
return np.array(losses).mean()model = get_model()
model.to(DEVICE);
# 使用AdamW优化器初始化模型参数,设置学习率为1e-4,权重衰减为1e-3
optimizer = torch.optim.AdamW(model.parameters(),
lr=1e-4, weight_decay=1e-3)
class SoftDiceLoss(nn.Module):
def __init__(self, smooth=1., dims=(-2,-1)):
super(SoftDiceLoss, self).__init__()
self.smooth = smooth
self.dims = dims
def forward(self, x, y):
tp = (x * y).sum(self.dims)
fp = (x * (1 - y)).sum(self.dims)
fn = ((1 - x) * y).sum(self.dims)
dc = (2 * tp + self.smooth) / (2 * tp + fp + fn + self.smooth)
dc = dc.mean()
return 1 - dc
bce_fn = nn.BCEWithLogitsLoss()
dice_fn = SoftDiceLoss()
def loss_fn(y_pred, y_true):
bce = bce_fn(y_pred, y_true)
dice = dice_fn(y_pred.sigmoid(), y_true)
return 0.8*bce+ 0.2*dice# 定义了输出表格的表头,包括Epoch、Train Loss、Valid Loss和Time等列的标题
header = r'''
Train | Valid
Epoch | Loss | Loss | Time, m
'''
# Epoch metrics time
# 定义了每一行数据的输出格式,包括Epoch数、训练损失、验证损失和训练时间等数据的展示
raw_line = '{:6d}' + '\u2502{:7.3f}'*2 + '\u2502{:6.2f}'
print(header)
EPOCHES = 5
best_loss = 10
for epoch in range(1, EPOCHES+1):
losses = []
start_time = time.time()
model.train()
for image, target in tqdm_notebook(loader):
image, target = image.to(DEVICE), target.float().to(DEVICE)
optimizer.zero_grad()
output = model(image)['out']
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
# print(loss.item())
vloss = validation(model, vloader, loss_fn)
print(raw_line.format(epoch, np.array(losses).mean(), vloss,
(time.time()-start_time)/60**1))
losses = []
if vloss < best_loss:
best_loss = vloss
torch.save(model.state_dict(), 'model_best.pth')
trfm = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
subm = []
model.load_state_dict(torch.load("./model_best.pth"))
model.eval()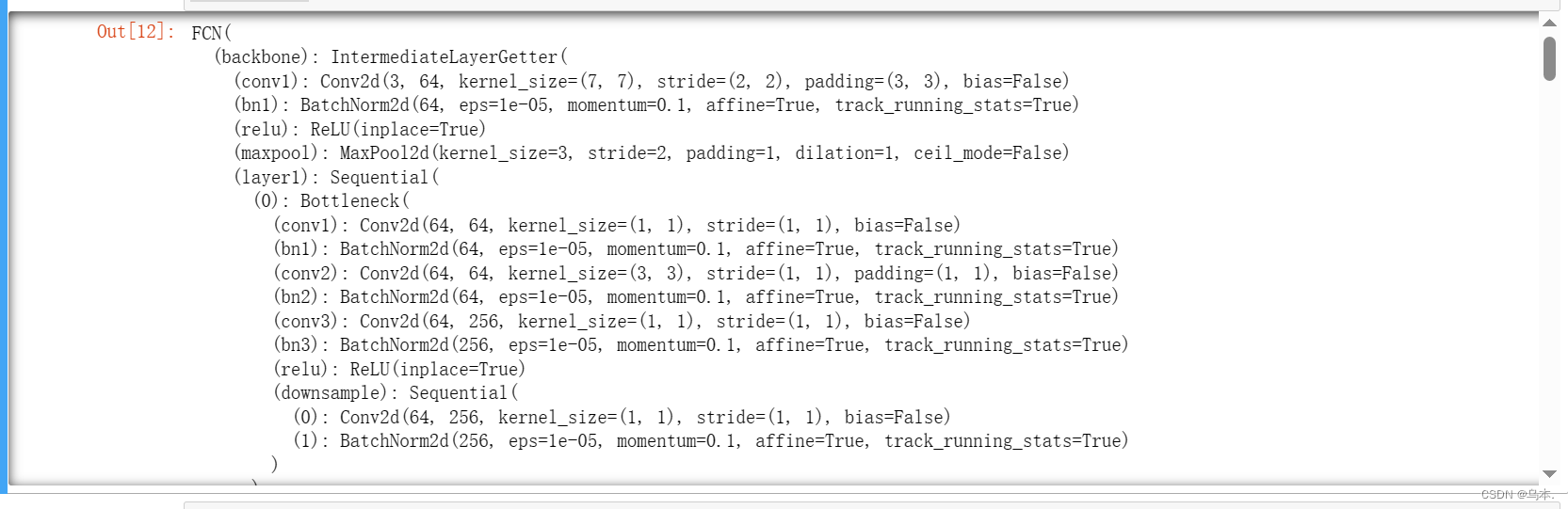
test_mask = pd.read_csv('./test_a_samplesubmit.csv', sep='\t', names=['name', 'mask'])
test_mask['name'] = test_mask['name'].apply(lambda x: './test_a/' + x)
for idx, name in enumerate(tqdm_notebook(test_mask['name'].iloc[:])):
image = cv2.imread(name)
image = trfm(image)
with torch.no_grad():
image = image.to(DEVICE)[None]
score = model(image)['out'][0][0]
score_sigmoid = score.sigmoid().cpu().numpy()
score_sigmoid = (score_sigmoid > 0.5).astype(np.uint8)
score_sigmoid = cv2.resize(score_sigmoid, (512, 512))
# break
subm.append([name.split('/')[-1], rle_encode(score_sigmoid)])subm = pd.DataFrame(subm)
subm.to_csv('./tmp.csv', index=None, header=None, sep='\t')
plt.figure(figsize=(16,8))
plt.subplot(121)
plt.imshow(rle_decode(subm[1].fillna('').iloc[0]), cmap='gray')
plt.subplot(122)
plt.imshow(cv2.imread('./test_a/' + subm[0].iloc[0]));

















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









