







基本操作
show databases;
用于查看数据库内容。
create databases (数据库名字);
用于创建数据库。
use (数据库名字);
选中数据库并使用。
drop database (数据库名字);
用于删除数据库。
表操作:
create tablie (表名) (列名 类型, 列名 类型...);
创建表,主义列名在前类型在后,不同于其他的编译器。
show tables;
再选中库后查看当前库存在的表。
desc (表名);
查看指定表的结构。
drop table (表名);
用于删除表。
show warnings;
查看警告。CRUD方面(新增,查找,修改,删除):
insert into (表名) (表的列名) values (想要插入的内容);
针对表内某一行的具体列进行插入,列名需要存在于表内。
insert into (表名) values (想要插入的内容,想要插入的内容), (想要插入的内容,想要插入的内容);
用于多行数据插入,更为效率。
select * from (表名);
全列查找,查询出当前表的所有行和所有的列。不适合用于公司的生产环境,会较大的消耗性能等。其中*为通配符,表示所有的列。
select (列名) from (表名);
用于查询指定列的数据,列名可以增加,中间使用,分隔开即可。
select (列名),(列名+/某数字或者某列数值) from (表名);
查询字段为表达式,一边查找一边计算。+只是一个例子可以有很多不同的计算表达式。注意的是查询计算后生成的表为临时表,并不影响原来的表格,使所以不会受到原来表格的数值范围限制。
select 表达式 as 别名 from 表名;
给查询结果的列起别名。
select distinct 列名 from 表名;
使用distinct关键字来进行去重,会合并重复的数据。
select * from 表名 order by 列名;
按照哪一列来进行升序排序。
默认的其实是
select * from 表名 order by 列名 asc;
asc是升序的意思。如果要改成降序就改成:
select * from 表名 order by 列名 desc;
select 列名 from 表名 where 条件;
使用指定条件来进行查询,用where来写栓选条件。
主义where的条件有优先级顺序,在同级下and的优先级比or高,可以使用括号来降低层级。
select 列名 from 表名 limit A offset B;
或者 select 列名 from 表名 limit B, A;
从第A条记录开始,查询接下来的B条数据。
update 表名 set 列名 = 值,列名 = 值... where 条件;\
针对那些表的哪些行的哪些列改成哪些数值。
updata是对当前的表进行修改,并不是临时表。
delete from 表名 where 条件;
删除满足条件的选项,没有写条件则全部删除,相比drop的话只剩了个空表。
数据库约束
NOTNULL
某列不能储存NULL值。
UNIQUE
保证某列的每一个必须有一个唯一的值。
DEFAULT
规定没有给列赋值时的默认值。
PRIMARY KEY
是NOTNULL和UNIQUE的结合,是每一条数据的身份标识,具有唯一性且不能重复。
一个表内只能有一个,但是UNIQUE可以有多个
FOREIGN KEY
把两张表关联起来
CHECK
auto_increment
自增主键 primary key的实例:
这个时候如果我们插入为空的id或者重复的id就会显示:


foerign key 案例

foreign key((当前表的那一列)) references (另一个表)((另一个表的一列));这个时候,当前表就成为了子表,另一个表就成为了父表。注意另一个表的另一列引用必须是primary key或者unique
当我们新增和修改子表内的数据是失败的,因为classid需要存在于班级表中所以需要给父表先插入数据才可以对子表进行数据的更改。父表对子表的约束作用。

并且在外键的约束下,插入数据会自动查询。会在子表中寻找该列的数据是否存在,依次来决定是否插入成功。
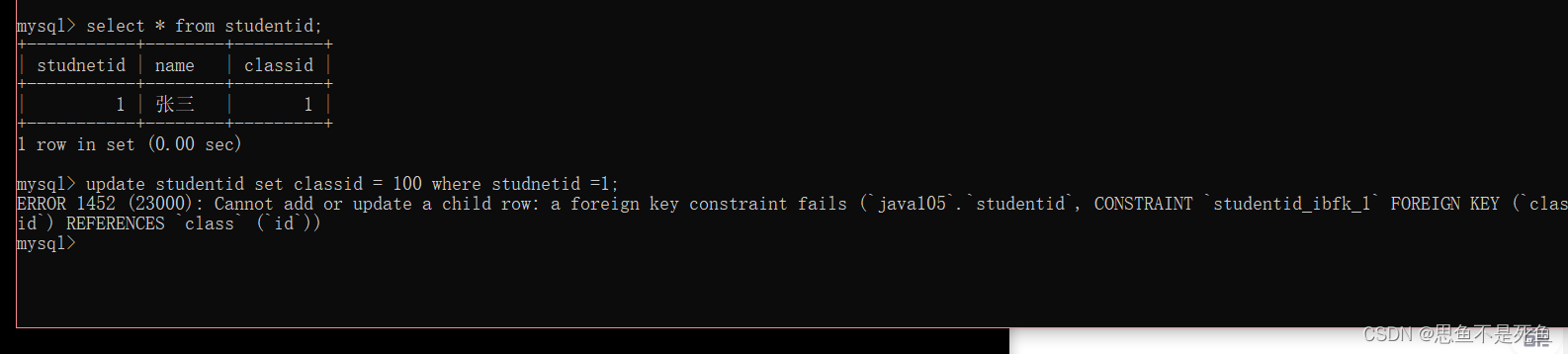
同时,子表对父表也产生了约束。如果在子表引用了数据的情况下存在的情况下直接删除父表就会出问题。 修改和删除都是如此。

没有被引用的数据就可以进行修改。
补:拷贝表数据
insert into (新表) select * from (拷贝表) where...;需要注意的是查询结果的列要和插入表的列相匹配(列的个数和类型匹配)。

同时可以往后面用where加条件。
或者使用下列来指定列插入。
insert into (新表)(列名) select (列名) from (旧表);补:自增主键案例:
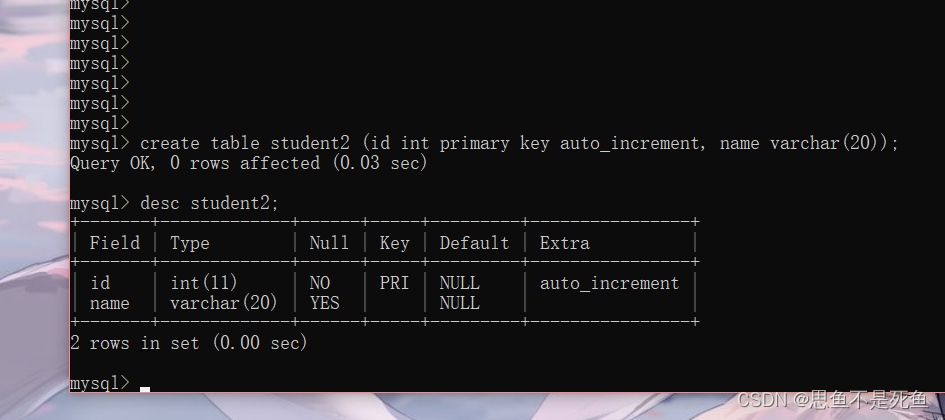
当我们往里面插入id为null的个例的时候,id会递增如下。

当我们手动插入一个id有具体数字的数据时,数据库会自动帮我们分配id例如:

比较运算符
特殊的有
=在比较null的时候是不安全的,比如null = null 的结果是null,也就是faluse。
<=>在比较null的时候是安全的,比如null <=> null的结果是true(1)。
between a and b
用于范围匹配,范围为[a,b],如果在范围内,返回true(1)。
in(option...)
如果是option中的任意一个,返回true(1);
is null
是null
is not null
不是null
like
模糊匹配,其中%能表示多个(包括0个)任意字符;_表示任意一个字符。
例如where name like '李__'
运算符
and
多个都符合才返回true
or
任意一个条件为true即可
not
相当于取反
常用数据类型有
BIT[(M)]
M为定指数,默认为1。整个数据类型为二进制数字,M的范围为从1到64,存值范围为2^M-1。
TINYINT
大小为一字节。对应JAVA的Byte类型。
SMALLINT
大小为两字节。对应JAVA的Short类型。
INT
大小为四字节。对应JAVA的integer类型。
BIGINT
大小为八字节。对应JAVA的Long类型。
FLOAT(M,D)
大小为四字节。为单精度,其中M指定长度,D制定小数位数,存在精度丢失的情况。对应JAVA的float类型。
DOUBLE(M,D)
大小为八字节。对应JAVA的double类型。
DECIMAL(M,D)
大小为(M/D)的最大值+2。为双精度,其中M指定长度,D制定小数位数,对应JAVA的BigDecimal类型。
NUMERIC(M,D)
大小为(M/D)的最大值+2。为双精度,其中M指定长度,D制定小数位数,对应JAVA的BigDecimal类型。
VARCHAR(SIZE)
为字符串类型,其中SIZE为最大的长度,意思是字符串最多能包含几个字符(注意不是字节),对应JAVA的string类型。
DATETIME
大小为八字节,范围为从1000到9999年,不会进行时区的检索和转换。对应JAVA的java.util.Date类型或者java.sql.Timestramp类型。
MYSQL
提供的函数
COUNT([DISTINCT]expr)
用于计算行数,count(*)会记录空值,count(列名)就不会记录空值。
SUM([DISTINCT]expr)
计算加和,只能计算数字,不能计算字符串。
AVG([DISTINCT]expr)
计算平均值
MAX([DISTINCT]expr)
最大值
MIN([DISTINCT]expr)
最小值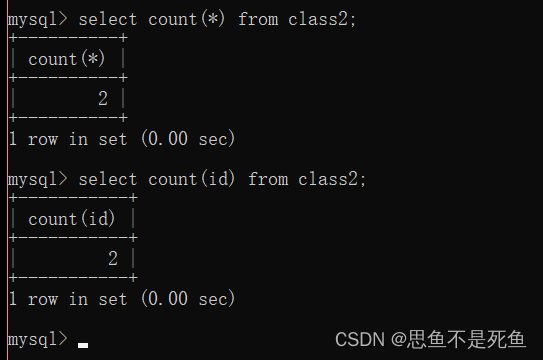















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









