






缓存穿透
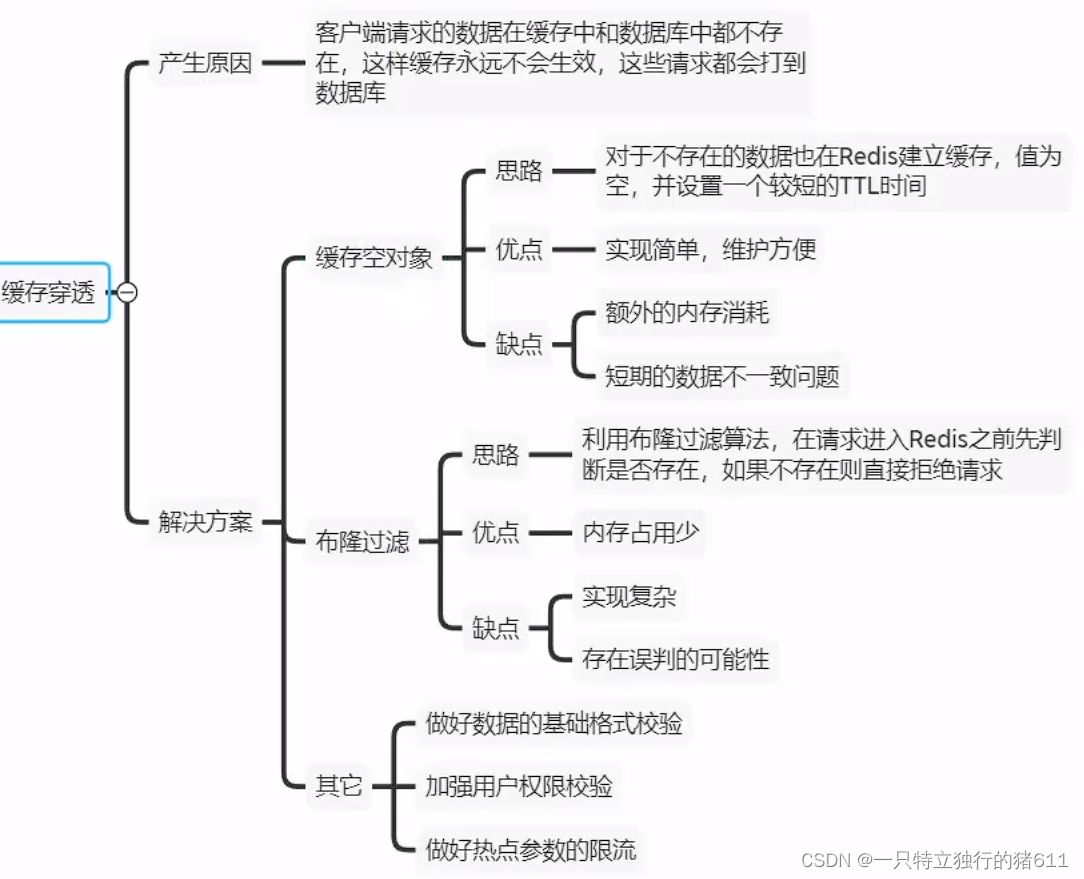
缓存穿透问题:
一般请求来到后端,都是先从缓存中查找数据,如果缓存中找不到,才会去数据库中查询数据。
而缓存穿透就是基于这一点,不断发送请求查询不存在的数据,从而使数据库压力过大,导致数据库崩溃!
解决这一问题,一般有两种解决方案:
一、缓存空数据:
把查询不到结果的请求,缓存值设置为空,这样该请求下次过来,缓存中就有空数据返回了。

缺点:
1.缓存了大量没用的空数据,浪费内存。
2.导致数据不一致性,比如说:一开始一个id为1的请求过来,我确实查询不到,缓存一个空数据。然后要添加了一条id为1的数据。但这个时候用户再来查询,得到的还是缓存中的空数据,要等到改空数据过期以后,才能去数据库中更新最新的数据,导致了数据的不一致性。
二、布隆过滤器:
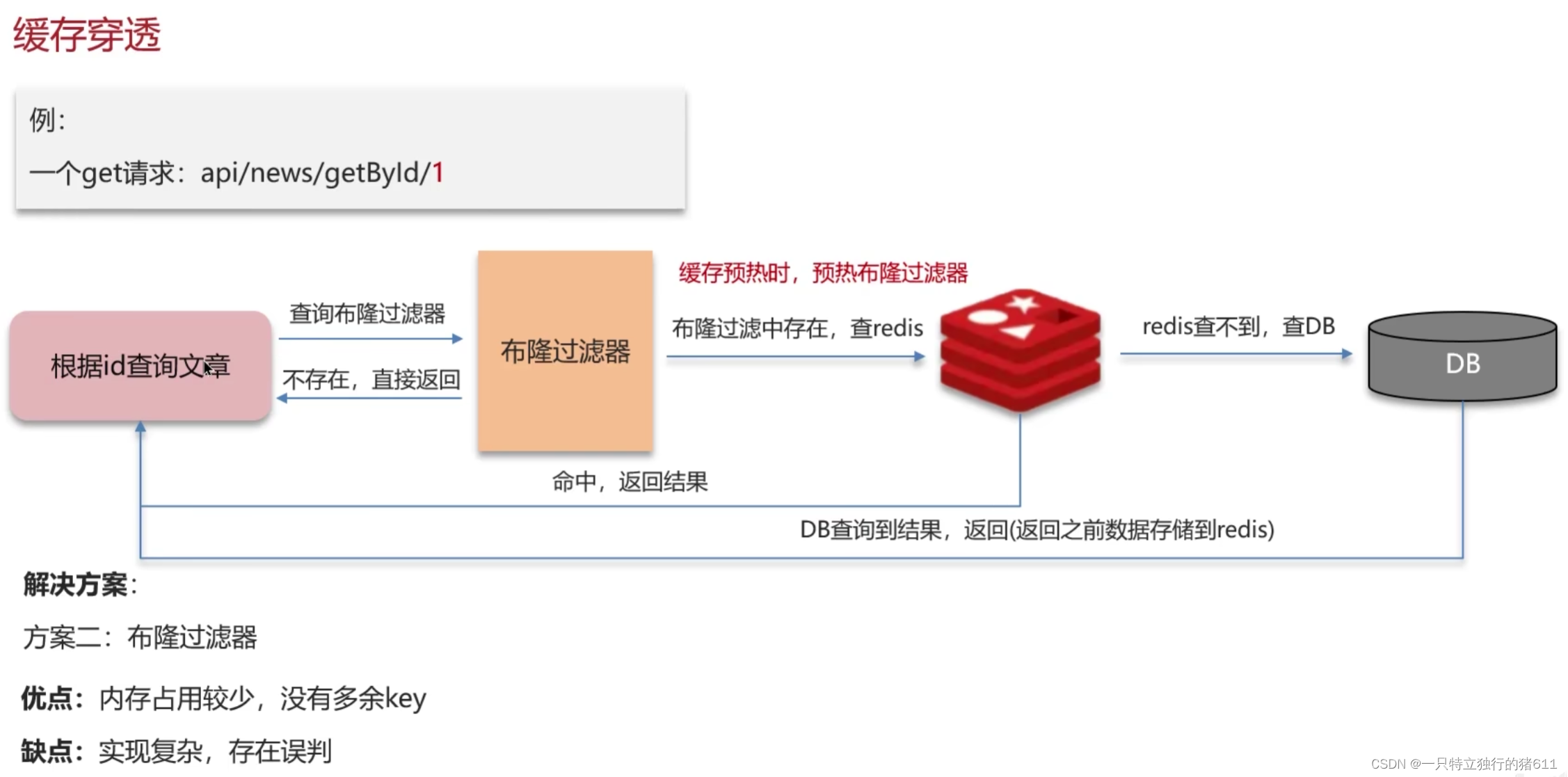
布隆过滤器判断元素是否存在的原理:

布隆过滤器的误判情况:
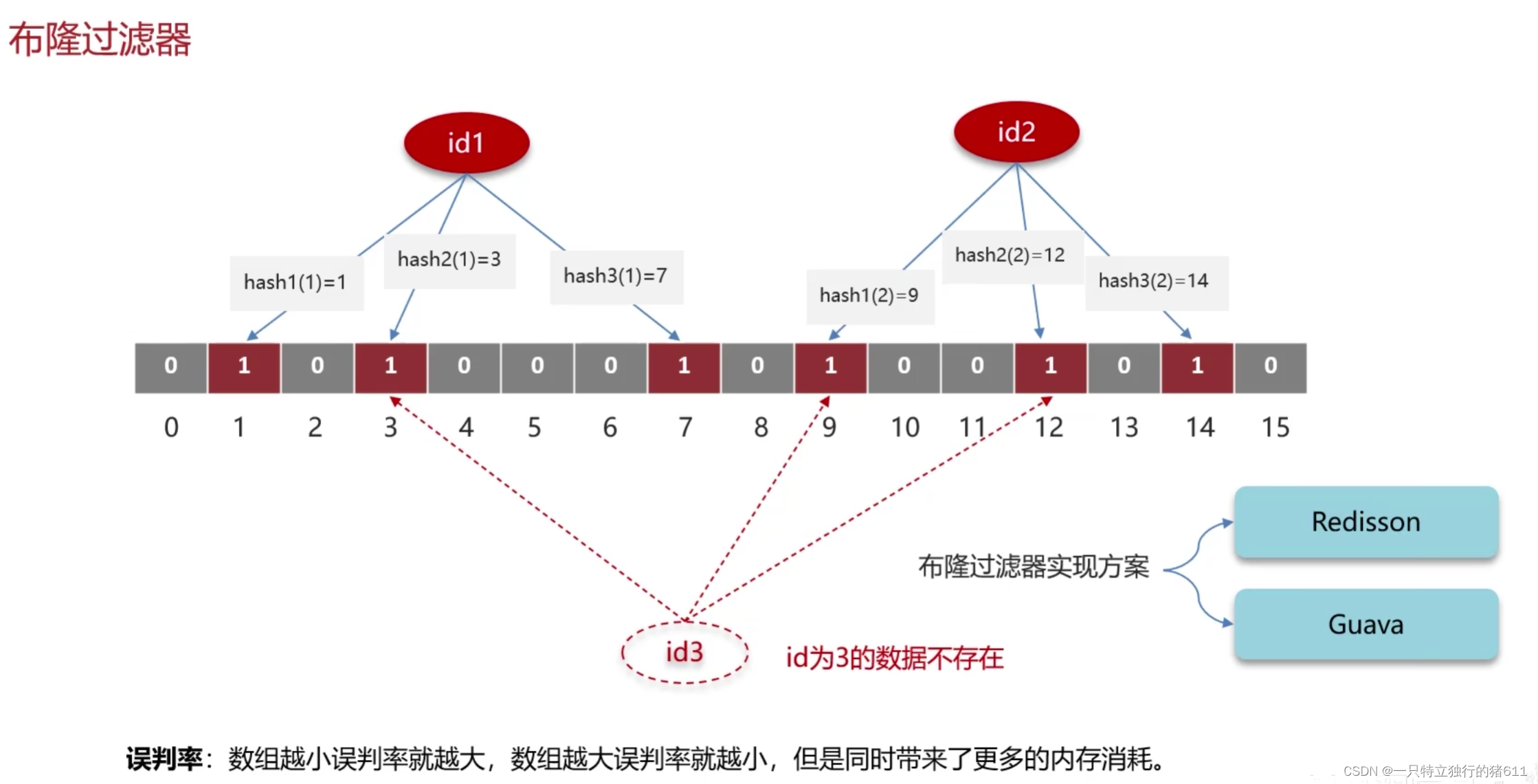
布隆过滤器使用情况:1.确定模型是一个集合结构,且没有删除行为 (类似于黑名单查询)。2.能接受一定的失误率。

总结:
1.缓存穿透
缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致DB 挂掉。这种情况大概率是遭到了攻击。
2.布隆过滤器
它的底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。当然是有缺点的,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,其实已经算是很划分了,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









