







目录
树的相关概念和结构
概念
树是一种非线性的结构,根朝上,而叶朝下,是一棵倒挂的树。
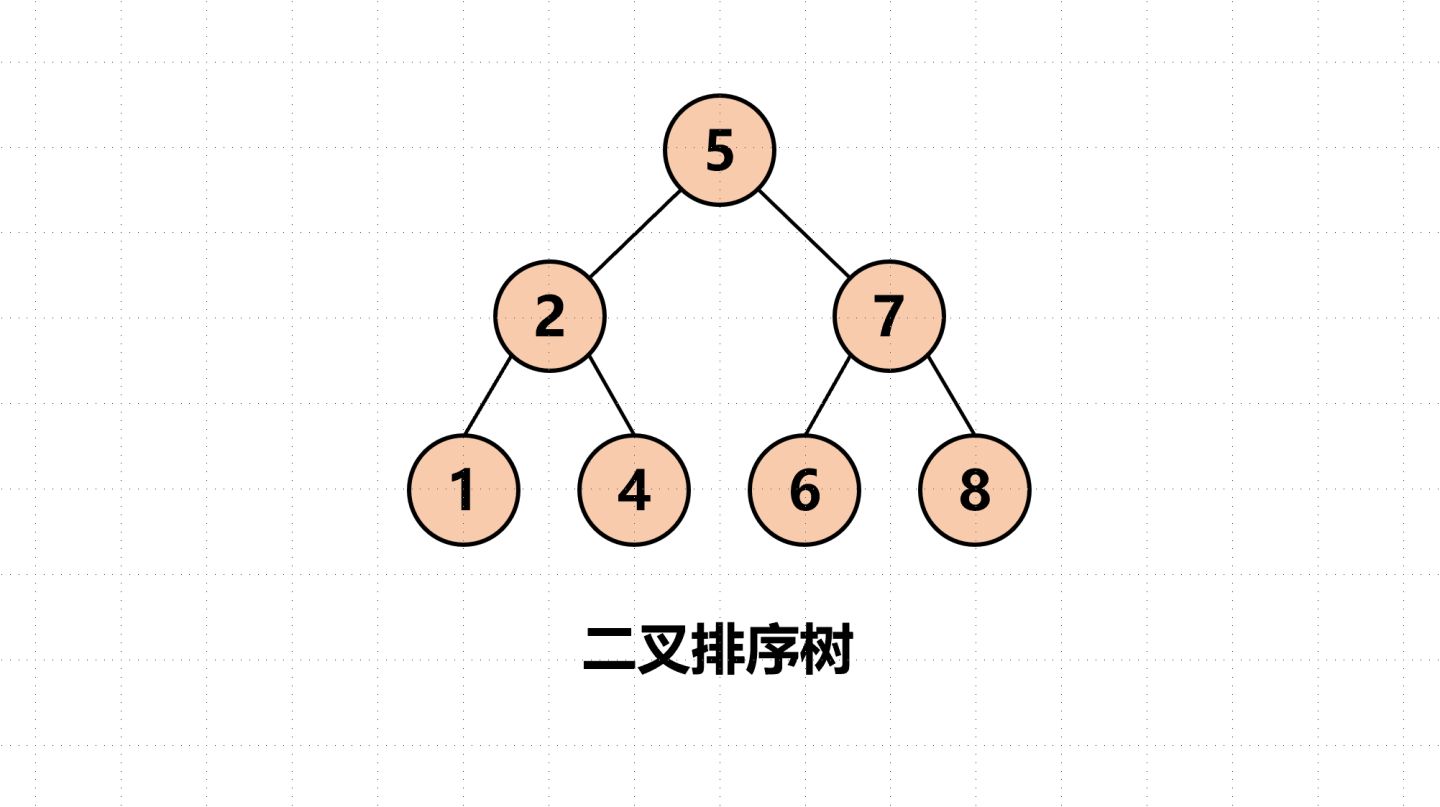
来认识些简单的概念
节点的度:一个节点含有的子树的个数。(通俗的讲就是有多少个子节点)。 例如5号的度为2
树的度:最大的节点的度才是树的度。
叶节点/终端节点:度为0的节点。1,4,6,8都是叶节点。
双亲节点/父节点:若这个节点含有子节点,则这个节点为其子节点的父节点。
子节点/孩子节点:例如,5是2,7的父节点,2是5的子节点。
兄弟节点:具备相同父节点的才是兄弟节点。例如2,7就是兄弟节点,但1,6就不是,因为其不具备相同父节点。
节点的层次:从根开始,根为1开始(有些资料认为是从0开始,但不建议,因为这样的话空树的高度就是-1)
树的高度或深度:树中节点的最大层次。例如上图为3
节点的祖先:从根到该节点所经分支的所有节点。5是所有节点的祖先。
子孙:以某节点为根的子树中任一节点都称为改节点子孙。所有节点都是5的子孙。
森林:由多棵互不相交的树的集合称为森林。
树如何去表示?
不管怎样还是会用到结构体的,但是有一个很明显的问题,你怎么知道他有多少个孩子呢?定义多了有些节点用不上,定义少了不够用。
在c++里可以采取类似于这样的方法去实现。
vector<struct treenode*>childs亦或者“左孩子右兄弟”的表示方法。
不管一个节点多少孩子,都只存两个指针,一个叫左孩子,一个叫右兄弟。
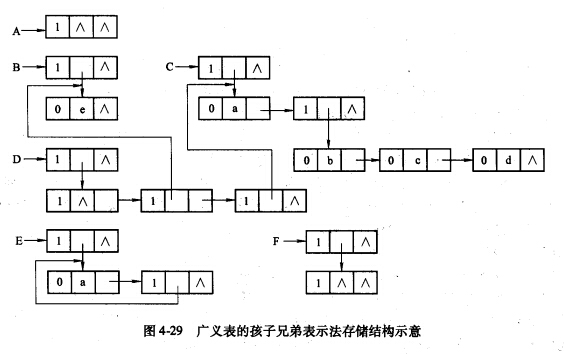
(图源百度百科)
总之就是只指向左边第一个孩子,再用孩子的兄弟指针去指向右边的兄弟。
还有双亲表示法等等。都仅作了解。
树与非树
树的子树是不相交的。
除了根节点,每个节点只有一个父节点。
一棵n个节点的树有n-1条边。
二叉树
概念
不存在超过度大于2的节点。
二叉树的子树具备左右的分别,且子树的次序是不可颠倒的。
特殊的二叉树
满二叉树:每一层的节点都达到最大值。也就是这个而二叉树的层数为k,则节点总数为(2^k)-1,可以用数学知识去进行推导。
上图就是一个满二叉树。
完全二叉树:满二叉树是一种特殊的完全二叉树。完全二叉树是一种效率很高的数据结构,当且仅当每一个节点都与满二叉树中编号1-n的节点一一对应。
若树高度为h,那么前h-1层必须是满的,且最后一层可以不满但从左到右必须连续(也就是h-1的子节点有右子树就有左子树)。
二叉树性质
性质
规定根节点层数为1,则非空二叉树第i层最多2^(i-1)个节点。
规定根节点层数为1,则深度为h的二叉树最大节点数为2^h-1 。
分析:假设深度为h,则总节点个数为2^0+2^1+2^3·······2^(h-1)=N
那么2^h-1=N
对于任意一棵二叉树,如果度为0的叶节点个数为n0,度为2的有n2,则n0=n2+1
若规定根节点层数为1,具有n个节点的满二叉树的深度,h=log2n(2为底)+1
例题
题1.某二叉树399个节点,有199个度为2的节点,求叶子节点的个数。
199+1=200,则度为0的节点有200个。
题2.在具有2n个节点的完全二叉树中,求叶子节点个数。
设度为0有a0个,度1有a1个,度2有a2个。
则a0+a1+a2=2n,a0=a2+1
即得到2a0+a1=2n-1,又因为是完全二叉树,所以度为1的点最多只有一个。
即2a0+1(或者0)-1=2n,但为0的话会得到小数,所以度为1的点有1个。
题3.一棵完全二叉树节点位数为531个,求树的高度。
设高度为h,且最后一层缺x个,则有2^h-1-x=531,又因为是完全二叉树,则x范围为[0,2^(h-1)-1]
(至少要剩一个,或者全缺),然后就只有拿值去套了。所以对2的各种次方一定要敏感。
可以得到h=10即可。
(用到遍历知识)
题4.某二叉树按层次输出(同一层从左到右)序列为abcdefgh,求该完全二叉树的前序序列。
因为是完全二叉树,则a在第一层,bc在第二层,defg在第三层,h在第四层第一个的位置。
所以把图画出来就可以得到abdhecfg是前序排列。
题5.二叉树先序为efhigjk 中序为hfiejkg,求后序。
因为前序先走根,所以可以得到e为根节点。但f就不确定是左还是右了。
但这里还给出了后序,因为e为根节点,所以可以确定hfi是左子树,jkg是右子树。
再结合前序,可以得到f是左子树的根了。依次类推得到
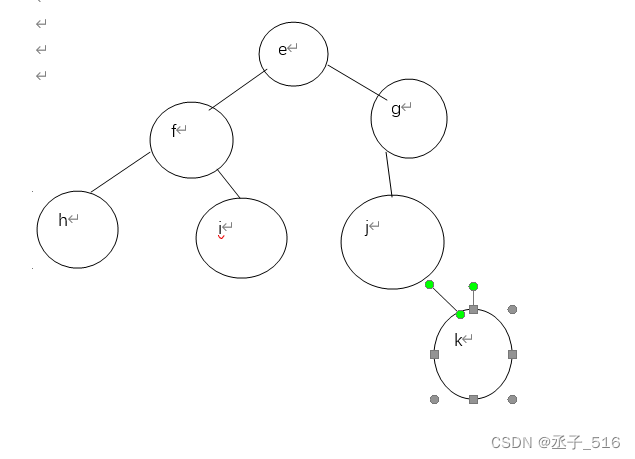
且这种题必须要有中序,只有中序可以确定左右子树有哪些。
二叉树存储形式
顺序存储
使用数组来存储,一般来讲呢,数组只适合于表示完全二叉树。因为在现实中只有在使用堆时才会用到数组来存储,所以在这里就不再过多的展开了。
链式存储
常采用定义两个指针,分别指向左子树和右子树。
也有三个指针的写法。还有一个parent指针。
typedef struct treenode
{
struct treenode* left;
struct treenode* right;
char data;
}tn;
链式遍历
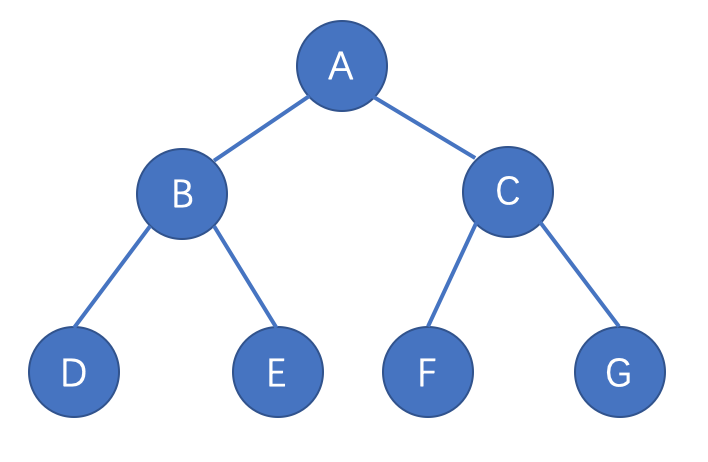
当研究一棵二叉树时,都应该有意识地认为他是由三个部分去构成的。
分别是左子树,右子树还有根节点。
例如上图,根节点为a时,那么bde构成左子树,cfg构成右子树。
当看b时,d为左子树,e为右子树,c也是同理。
那么为何要这样去分的这么细呢?因为等会会用到分治算法。
分治算法的思想是:分而治之,将大问题分成类似的子问题,子问题再接着往下分。直到子问题不可分割。
去求深度高度啥的会用到遍历。而且遍历我们分成三种。
前序遍历(先根遍历)
如其名,先访问根,再访问左子树,再访问右子树。
还是如上图,先访问a,a的左子树为b,右子树为c,先访问左子树,所以先访问b,再去访问b的左子树d,d仍然可以接着往下访问,但为空,则d的左右子树都为NULL,接着是b的右子树,e。
e如d其子树为空。
此时b访问完成,接着可以访问a的右子树。
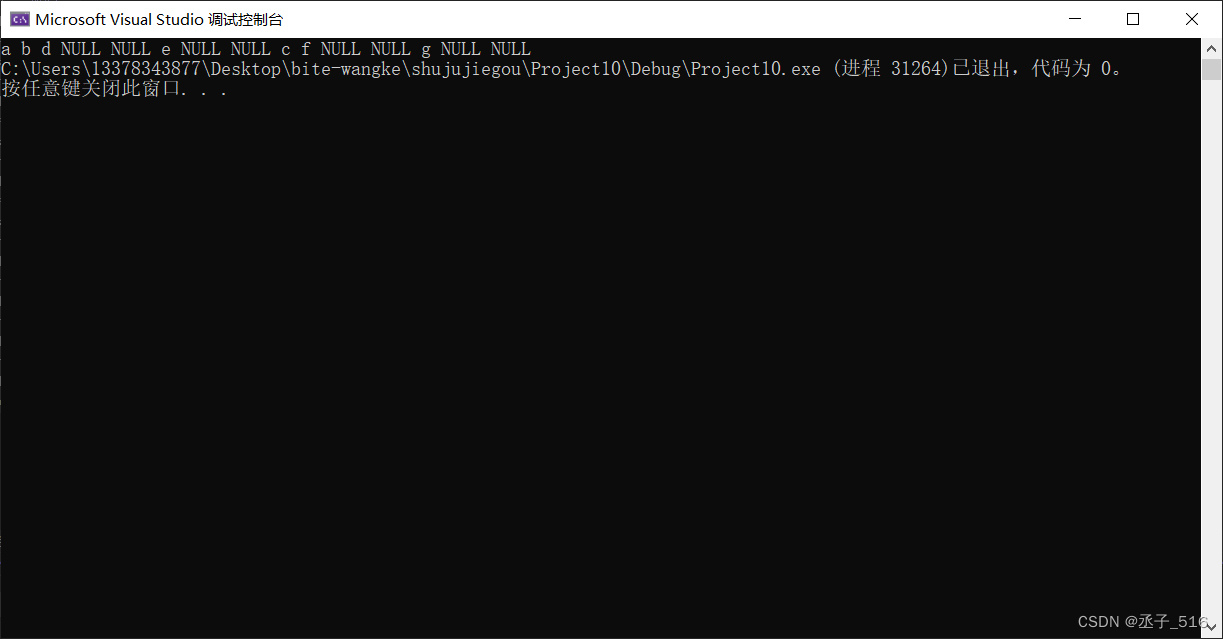
所以大概这一圈走下来就是a b d null null e null null c f null null g null null
用代码来测试一下。
结构体定义左右节点和data。遍历我们采取递归的形式。
typedef struct treenode
{
struct treenode* left;
struct treenode* right;
char data;
}tn;
//前序
void prevorder(tn* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%c ", root->data);
prevorder(root->left);
prevorder(root->right);
}
int main()
{
tn* a = (tn*)malloc(sizeof(tn));
a->data = 'a';
a->left = NULL;
a->right = NULL;
tn* b = (tn*)malloc(sizeof(tn));
b->data = 'b';
b->left = NULL;
b->right = NULL;
tn* c = (tn*)malloc(sizeof(tn));
c->data = 'c';
c->left = NULL;
c->right = NULL;
tn* d = (tn*)malloc(sizeof(tn));
d->data = 'd';
d->left = NULL;
d->right = NULL;
tn* e = (tn*)malloc(sizeof(tn));
e->data = 'e';
e->left = NULL;
e->right = NULL;
tn* f = (tn*)malloc(sizeof(tn));
f->data = 'f';
f->left = NULL;
f->right = NULL;
tn* g = (tn*)malloc(sizeof(tn));
g->data = 'g';
g->left = NULL;
g->right = NULL;
a->left = b;
a->right = c;
b->left = d;
b->right = e;
c->left = f;
c->right = g;
prevorder(a);
}结果
中序遍历(中根遍历)
先左子树,再是根,再是右子树。
null d null b null e null a null f null c null g null
代码如下,和前序如出一辙
//中序
void inorder(tn* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
inorder(root->left);
printf("%c ", root->data);
inorder(root->right);
}后序遍历
先左子树,再右子树,最后根。
null null d null null e b null null f null null g c a
void postorder(tn* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
postorder(root->left);
postorder(root->right);
printf("%c ", root->data);
}求节点数和各种变形
做法1:仍然采取递归的做法。但是请定义一个全局的size变量。否则size无法进行计数。
//求节点个数
int size = 0;
int treesize(tn* root)
{
if (root == NULL)
return ;
size++;
treesize(root->left);
treesize(root->right);
return size;
}但使用全局变量会出现问题。当你第二次使用此函数时,size未清零。所以注意在每次调用前需要置为0即可。
但我仍旧不推荐这样去写,比如在多线程中进行处理,就极易出现问题。
那怎么处理这个问题比较好呢?可以考虑传参。
但不能传值,因为在不断的调用中调用的都是拷贝。所以可以传址,也就是指针。
//求节点个数
int size = 0;
void treesize(tn* root,int*psize)
{
if (root == NULL)
{
return;
}
++(*psize);
treesize(root->left,psize);
treesize(root->right,psize);
}但还有其他的思考,比如分治思想。
从根开始往下走,不断的进行分治。这样的代码就非常的简洁了。
int treesize2(tn* root)
{
return root == NULL ? 0 : treesize2(root->left) + treesize2(root->right) + 1;
}那么参照分治算法,试着写一下如何去求叶子节点的个数吧。
如果此节点为空,则返回0,是叶子节点,就返回1,不是空又不是叶子节点,那就代表可以接着向下进行遍历。
//求叶子节点个数
int treeleafsize(tn* root)
{
if (root == NULL)
return 0;
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return treeleafsize(root->left) + treeleafsize(root->right);
}二叉树oj题练习
几道经典的力扣题目,可以更好的去理解在二叉树中递归的使用。
题1 二叉树前序遍历
链接:https://leetcode.cn/problems/binary-tree-preorder-traversal
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,2,3]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
示例 4:
输入:root = [1,2]
输出:[1,2]
示例 5:
输入:root = [1,null,2]
输出:[1,2]
提示:
树中节点数目在范围 [0, 100] 内
-100 <= Node.val <= 100
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* preorderTraversal(struct TreeNode* root, int* returnSize){
}由题可知,返回类型是数组,所以需要malloc一个数组。和前面讲的差不多,只需要将打印换成将值放到数组里去即可。
同时,不知道数组要放多少个,所以直接用求节点的方法返回一个size即可。
int treesize(struct TreeNode* root)
{
return root==NULL?0:treesize(root->left)+treesize(root->right)+1;
}
void prevorder(struct TreeNode* root,int*a ,int *p)
{
if(root==NULL)
return ;
a[*p]=root->val;
(*p)++;
prevorder(root->left,a,p);
prevorder(root->right,a,p);
}
int* preorderTraversal(struct TreeNode* root, int* returnSize){
int size=treesize(root);
int*a =(int*)malloc(size*sizeof(int));
int i=0;
int* p=&i;
prevorder(root,a,p);
*returnSize=size;
return a;
}记得传进来的数组a和i传参传的是地址哦。否则只是一层拷贝,在调用中切记不要犯这种错误。
不要乱用全局变量来简单处理,可能会导致越界。更何况在多线程的处理中会出现问题,之前也提到过。
题2.二叉树的深度
输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
提示:
节点总数 <= 10000
分析:采用分治的思想。分为左右子树分别求,取大的深度进行返回。
最简单容易想到的就是如下代码
int maxDepth(struct TreeNode* root){
if(root==NULL)
return 0;
return maxDepth(root->left)>maxDepth(root->right)?maxDepth(root->left)+1:maxDepth(root->right)+1;
}但是在力扣中会给出一个非常巨大的树,导致超出时间限制。
可以将计算的值进行一个存储,减少计算时间。
int maxDepth(struct TreeNode* root){
if(root==NULL)
return 0;
int leftdepth=maxDepth(root->left);
int rightdepth=maxDepth(root->right);
return leftdepth>rightdepth?leftdepth+1:rightdepth+1;
}
题3.平衡二叉树
链接:https://leetcode.cn/problems/ping-heng-er-cha-shu-lcof
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7
返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1
/ \
2 2
/ \
3 3
/ \
4 4
返回 false 。
限制:
0 <= 树的结点个数 <= 10000
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
bool isBalanced(struct TreeNode* root){
}分析:和上面那道题思路是类似的。去检查每棵树是否满足。只有满足了才去检查其左树和右树。
直到不可分割的子问题。
int maxDepth(struct TreeNode* root){
if(root==NULL)
return 0;
int leftdepth=maxDepth(root->left);
int rightdepth=maxDepth(root->right);
return leftdepth>rightdepth?leftdepth+1:rightdepth+1;
}
bool isBalanced(struct TreeNode* root){
if(root==NULL)
return true;
int leftdepth=maxDepth(root->left);
int rightdepth=maxDepth(root->right);
return abs(leftdepth-rightdepth)<2&&isBalanced(root->left)&&isBalanced(root->right);
}
大概应付学校的期末考试如上就差不多了。就算超过也一般不会超过太多。
祝期末考试顺利。














 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









