






文章目录
有关 Github \text{Github} Github仓库欢迎来 Star \text{Star} Star, 期末考题
0. \textbf{0. } 0. 写在前面
1️⃣本课程总体结构

- 这门课由于由两位老师授课,个人感觉结构比较混乱
- 由于时间紧任务重经费无,所以笔记还是按 PPT \text{PPT} PPT内容和以上结构展开,即使有很多不合理的地方
2️⃣考试有关事项
1. NLU \textbf{1. NLU} 1. NLU的概念与背景
1️⃣ NLU \text{NLU} NLU与 NLP \text{NLP} NLP
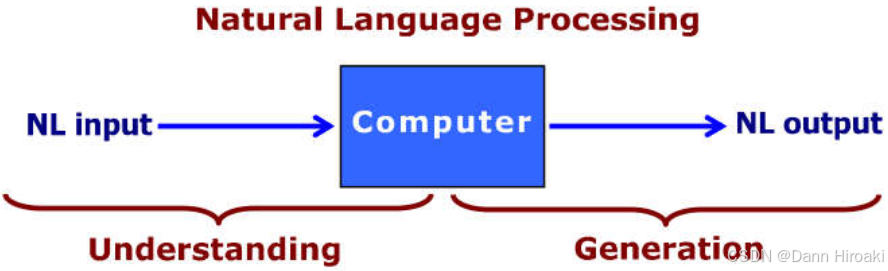
- 自然语言理解:
- 含义:让计算机理解人类语言的结构 + + +语义
- 应用:信息检索 / / /情感识别 / / /机器翻译 / / /拼写检查 / / /知识图谱构建
- 自然语言处理:对自然语言的分析 / / /理解 / / /生成,即 NLU+NLG(Generation) \text{NLU+NLG(Generation)} NLU+NLG(Generation)
2️⃣ AI-Hard \text{AI-Hard} AI-Hard问题
- 含义:问题等同于 AI \text{AI} AI核心的问题,即如何让计算机具有人类智能
- 典型: NLU/NLP \text{NLU/NLP} NLU/NLP, CV \text{CV} CV
3️⃣ NLU \text{NLU} NLU面临的挑战
- 计算机的特性:善于处理明确 / / /结构化 / / /无歧义的语言(如编程语言)
- 自然语言特性:具有复杂的上下文以及歧义性( Ambiguity \text{Ambiguity} Ambiguity)
歧义类型 含义 示例 词汇歧义 词汇具有不同含义 Fuck \text{Fuck} Fuck可以是动词 / / /语气词 句法歧义 一个句子被解析成不同的结构 南京市长江大桥 语义歧义 句中包含了不明确的词 John kissed his wife, and so did Sam \text{John kissed his wife, and so did Sam} John kissed his wife, and so did Sam 回指歧义 之前提到的词,在后面句子含义不同 小李告诉小王他生了 语用歧义 短语 / / /句子不同语境下含义不同 可以站起来吗 (询问能力 or \text{or} or请求)
2. NLU \textbf{2. NLU} 2. NLU的语法任务
2.1. \textbf{2.1. } 2.1. 词汇层面的任务
1️⃣词干抽取( Stemming \text{Stemming} Stemming)
- 含义:抽取词的词干( Stem \text{Stem} Stem)与词根( root \text{root} root),比如 Niubilitiness → { 词干: Niubility 词根: Niubi \text{Niubilitiness}\to\begin{cases}\text{词干: Niubility}\\\\词根\text{: Niubi}\end{cases} Niubilitiness→⎩ ⎨ ⎧词干: Niubility词根: Niubi
- 处理方法:
方法 含义 限制 利用形态规则 机械地去处所有后缀,如 -ing/-tion \text{-ing/-tion} -ing/-tion 不规则变形词不适用 基于词典 按照词典中的映射还原词性 受限于词典规模 高级方法 n-gram \text{n-gram} n-gram法 / / /隐马可夫 / / /机器学习 受限于语料库大小 2️⃣词形还原( Lemmatization \text{Lemmatization} Lemmatization)
- 含义:将不同形式词汇还原为词目( Lemma \text{Lemma} Lemma),如 am, is, are, was, were→be \text{am, is, are, was, were→be} am, is, are, was, were→be
- 对比:词干抽取完全不考虑上下文,词形还原考虑一定的上下文
- 示例: We are meeting in the zoom meeting → 词形还原 词干抽取 { 词干抽取: meet 词形还原: meet+meeting \text{We are meeting in the zoom meeting}\xrightarrow[词形还原]{词干抽取}\begin{cases}\text{词干抽取: meet}\\\\\text{词形还原: meet+meeting}\text{}\end{cases} We are meeting in the zoom meeting词干抽取词形还原⎩ ⎨ ⎧词干抽取: meet词形还原: meet+meeting
- 处理方法:
- 基于规则:人工给予的语言学规则,或者机器学习训练出来的规则
- 基于词典:受限于词典,只适用于简单语言
💡词形还原 / / /词干抽取并非 100% \text{100\%} 100%必要,比如细颗粒度情感分析就需要高精度文本(时态 / / /复数等)3️⃣词性标注( Part-of-speech tagging \text{Part-of-speech tagging} Part-of-speech tagging)
- 含义:为文本中每个词标记词性(名词 / / /动词 / / /形容词)
- 方法:基于规则(人工),基于隐马可夫模型( HMM \text{HMM} HMM),基于机器学习( SVM / \text{SVM}/ SVM/神经网络)
- 挑战:分词 & \text{\&} &词义多义性
4️⃣术语抽取( Terminology extraction \text{Terminology extraction} Terminology extraction)
- 含义:信息抽取的子任务,识别文本中特定领域的专门术语
- 方法:机器学习,统计( TF/IDF \text{TF/IDF} TF/IDF),外部知识库
- 挑战:新术语/跨领域术语
2.2. \textbf{2.2. } 2.2. 句法层面的任务
1️⃣句法分析( Parsing \text{Parsing} Parsing)
- 含义:分析文本中单词/短语之间的句法关系
- 方法:统计学(概率上下文无关文法 / / /最大化信息熵的原则),机器学习方法( RNN \text{RNN} RNN)
2️⃣断句( Sentence breaking \text{Sentence breaking} Sentence breaking)
- 含义:句子边界消歧(例如 . \text{ . } . 可表示短句 / / /缩写 / / /小数点等) + + +句子分割
- 方法:基于最大熵,神经网络
3️⃣分词( Word segmentation \text{Word segmentation} Word segmentation)
- 含义:仅对词汇间没有明显边界的语言(中文)而言,将连续字符分割为有意义单词
- 方法:基于字典(正逆向匹配),基于统计( HMM/SVM \text{HMM/SVM} HMM/SVM)
- 难处:未登录词 / / /切分歧义

3. NLU \textbf{3. NLU} 3. NLU的语义任务
3.1. \textbf{3.1. } 3.1. 文本生成/转换
1️⃣机器翻译
- 含义:将文本 / / /语音从一种语言翻译到另一种语言
- 方法:基于规则(源 / / /目标语言形态语法等),基于统计(用大型语料库构建概率模型),神经网络
- 难题:词句歧义 / / /对语料库大小强依赖 / / /低频词句 / / /长句子
2️⃣问答与对话
- 含义:实现自然语言形式的人机交互
- 分类:
- 5W1H \text{5W1H} 5W1H类问题:即 Who/What/When/Where/Why & How \text{Who/What/When/Where/Why \& How} Who/What/When/Where/Why & How
- Open/Closed-domain \text{Open/Closed-domain} Open/Closed-domain类:回答可以没有限制 or \text{or} or 专注于某一领域
- 方法:检索法(从库中抽取语料回答),生成法(检索 + + +推理), Pipeline \text{Pipeline} Pipeline, Seq2Seq \text{Seq2Seq} Seq2Seq
- 难题:多知识约束 / / /多轮对话 / / /多模态 / / /可解释性…
3️⃣自动文摘
- 含义:为文档生成一段包含原文档要点的压缩文档,例如搜索引擎结果
- 方法:对要点进行不修改的抽取,对要点概括(修改/复述)
- 难题:难以评估,可理解性问题,需要背景知识
3.2. \textbf{3.2. } 3.2. 文本信息提取
1️⃣命名实体识别( NER, Named entity recognition \text{NER, Named entity recognition} NER, Named entity recognition)
- 命名实体:现实世界中的某个对象,如 Obama is the president of the United States \text{\textcolor{red}{Obama} is the \textcolor{red}{president} of \textcolor{red}{the United States}} Obama is the president of the United States
- NER \text{NER} NER:信息提取的子任务,识别文本中所有实体 + + +分配到特定类别(名字 / / /时间 / / /数量)
- 方法:语法规则(效果好但需要大量人工规则),统计方法(需要标注大量数据)
- 难题:领域依赖性(如医学实体 / / /术语),实体类型多样
2️⃣关系抽取
- 含义:检测文本中实体的语义关系,并将各种关系分类
- 方法:结合了领域知识的机器学习
- 难点:训练集难以构建,自然语言的歧义
3.3. \textbf{3.3. } 3.3. 文本内容分析
1️⃣文本分类
- 含义:自动将文本划分到预定类中,比如垃圾邮件过滤/情感识别/黄色内容识别
- 方法:特征提取 → \to →训练分类器(朴素贝叶斯 / KNN/SVM /\text{KNN/}\text{SVM} /KNN/SVM)
- 难题:特征难提取(需要大量标注),数据非平衡问题
2️⃣情感分析
- 含义:识别文本中的情感状态,主观评价等
- 方法:情感词库( Happy/Fucking \text{Happy/Fucking} Happy/Fucking),统计方法( SVM/ \text{SVM/} SVM/潜在语义分析)
- 难题:修辞的多样(反语 / / /讽刺),分面观点(即将复杂事物分解为不同方面)
3️⃣主题分割
- 含义:将单个长文本分为多个较短的,主题一致的片段
- 方法:
- 基于内容变化:同一主题内容有高度相似性 → \to →通过聚类
- 基于边界特性:主题切换时会有边界(如过渡性 / / /总结性文本)
- 难点:任务目标模糊(主题多样),无关信息干扰,歧义性
3.4. \textbf{3.4. } 3.4. 文本歧义消解
1️⃣词义消歧
- 含义:确定一词多义词的含义
- 方法:基于词典(叙词表 / / /词汇知识库),基于机器学习(小语料库的半监督学习 / / /标注后的监督学习)
- 难题:词义的离散型(一个词的不同含义可能完全不搭边),需要常识
2️⃣共指消解
- 含义:识别文本中表示同一个事物的不同代称
- 示例:甲队打败了乙队,他们更强 → 消解后 \xrightarrow{消解后} 消解后虽然甲队打败了乙队,但他们更强
- 方法:
- 启发式:如最接近语法兼容词,即在代词前寻找最近的 + + +语法匹配的词
- 基于 ML \text{ML} ML:如 Mention-Pair Models/Mention-Ranking Models \text{Mention-Pair Models/Mention-Ranking Models} Mention-Pair Models/Mention-Ranking Models
- 难题:如何应用背景知识,歧义(哪哪都有它,考试的万金油解答嘿嘿)

4. \textbf{4. } 4. 关于大模型的概述
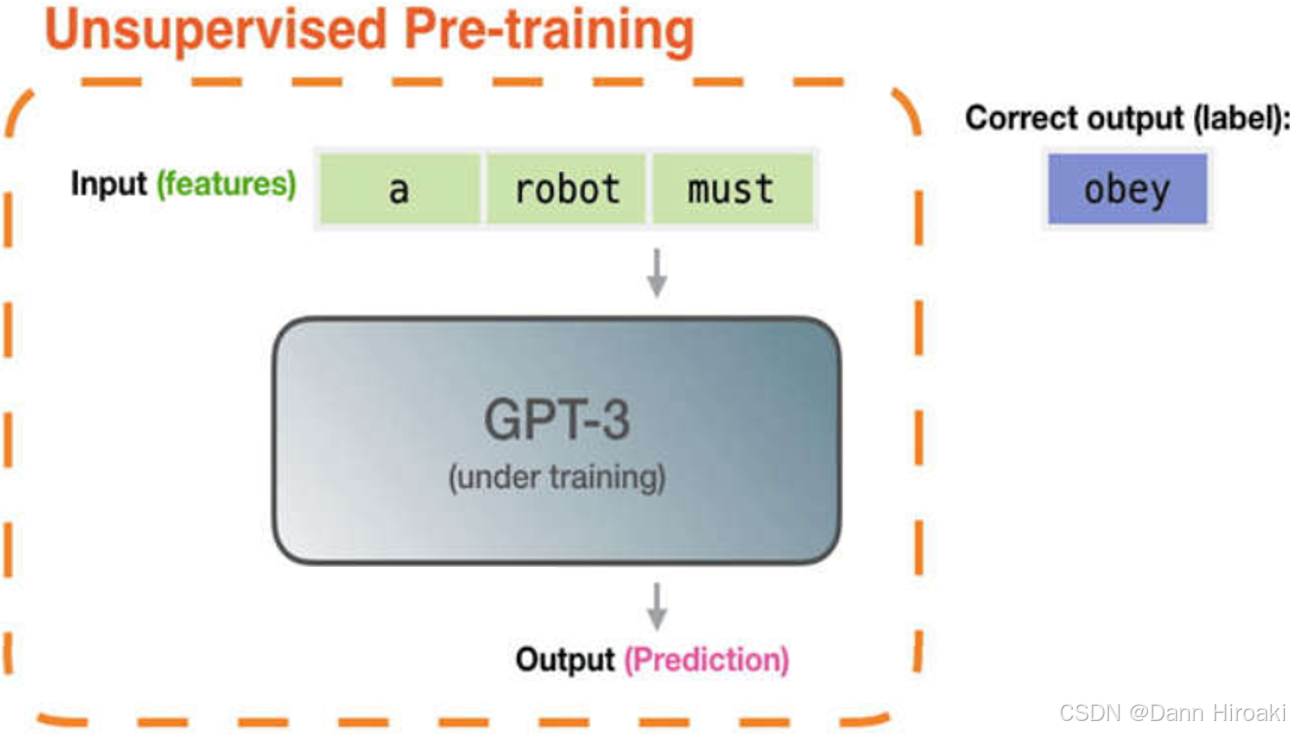
1️⃣大规模预训练模型
- 含义:用自监督方式在大规模数据集上训练的深度学习模型 → \to →后续可通过微调来适应特定任务
- 原理:以 GPT-3 \text{GPT-3} GPT-3为例
- 训练阶段:以“完形填空”形式训练一个序列预测器
- 预测阶段:当前文本序列 → 逐个预测每个Token \xrightarrow{逐个预测每个\text{Token}} 逐个预测每个Token生成最有可能的文本序列
2️⃣大模型的特点
特性 描述 备注 大模型 模型参数达到万亿级 模型性能 ∝ \propto ∝参数量 α ^{\alpha} α (即标度律) 大数据 模型参数越多 → \to →训练所需数据也更多 模型性能 ∝ \propto ∝数据量 α ^{\alpha} α 大算力 训练对算力要求高,预测时所有参数都被激活 算力需求 ∝ 2 参数规模 \propto{}2^{参数规模} ∝2参数规模 (即指数级) 3️⃣大模型的局限
局限 含义 大模型幻觉 生成错误 / / /不存在的信息,比如说埃菲尔铁塔在德国(其实也没错) 生成 404 \text{404} 404内容 TG \text{TG} TG不太喜欢的,你懂 理解不了多模态 例如很多时候同时输入文本 + \text{+} +图片, GPT \text{GPT} GPT往往会忽略图片内容 推理能力差 无法进行逻辑 / / /尝试 / / /数值推理,但是好像 GPT-o1 \textit{GPT-o1} GPT-o1解决了这一问题 难以个性化 对特定场景 / / /需求 / / /认知水平的处理欠佳,或许可以通过参数调控( ? \text{?} ?)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









