







1. \textbf{1. } 1. 导论与背景
1.1. \textbf{1.1. } 1.1. 研究背景
1️⃣两种文本相似性检索模型
类型 嵌入方式 相似度计算 单向量 (SV) \text{(SV)} (SV) 对整个句子生成唯一的嵌入 MIPS \text{MIPS} MIPS算法,从一堆向量找出与 q q q有最大内积的 多向量 (MV) \text{(MV)} (MV) 对每个 Token \text{Token} Token都生成一个嵌入 Chamfer \text{Chamfer} Chamfer相似度,也就是所谓的 MaxSim \text{MaxSim} MaxSim之和 2️⃣多向量模型的问题:检索成本还是高过单向量
- 空间占用上: Token \text{Token} Token数量过多,需要大量的存储
- 计算成本上:缺乏对于 Chamfer \text{Chamfer} Chamfer的优化,大多的优化只针对于 MIPS \text{MIPS} MIPS而无法用在 Chamfer \text{Chamfer} Chamfer上
3️⃣改进的尝试:将 MV \text{MV} MV改为基于 SV \text{SV} SV的 MIPS \text{MIPS} MIPS流水(单向量启发式方法)
- SV \text{SV} SV阶段:每个查询 Token → MIPS \text{Token}\xrightarrow{\text{MIPS}} TokenMIPS最相似的文档 Token \text{Token} Token
- MV \text{MV} MV阶段:收集所有的最相似文档 Token \text{Token} Token,再用原始 Chamfer \text{Chamfer} Chamfer相似度得到最终评分
1.2. \textbf{1.2. } 1.2. 本文工作 : Muvera \textbf{: Muvera} : Muvera概述
1️⃣ Chamfer \text{Chamfer} Chamfer相似度
- 相似度的定义:对查询 Q / Q/ Q/段落 P P P的每个 Token ( q / p ) \text{Token}(q/p) Token(q/p),相似度为 Chamfer ( Q , P ) = ∑ q ∈ Q max p ∈ P ⟨ q , p ⟩ \displaystyle{}\text{Chamfer}(Q,P)\text{=}\sum_{q \text{∈} Q} \max _{p \text{∈} P}\langle q, p\rangle Chamfer(Q,P)=q∈Q∑p∈Pmax⟨q,p⟩
- 扩展到最邻近:在 P = { P ( 1 ) , P ( 2 ) , … , P ( N ) } \mathscr{P}\text{=}\left\{P^{(1)},P^{(2)},\ldots,P^{(N)}\right\} P={P(1),P(2),…,P(N)}中找到与 Q Q Q之间 Chamfer \text{Chamfer} Chamfer相似度最高的文档 P ∗ ∈ D P^{*} \text{∈} D P∗∈D
2️⃣ Muvera \text{Muvera} Muvera概述
- 核心思想:将所向量压缩为单向量,原有的 Chamfer \text{Chamfer} Chamfer搜索也变成 MIPS \text{MIPS} MIPS搜索
- 维度压缩:特殊的映射函数 { F q u e : 2 R d → R d F D E F doc : 2 R d → R d F D E → \begin{cases}\mathbf{F}_{\mathrm{que}}: 2^{\mathbb{R}^{d}} \rightarrow \mathbb{R}^{d_{\mathrm{FDE}}}\\\\\mathbf{F}_{\text{doc}}: 2^{\mathbb{R}^{d}} \rightarrow \mathbb{R}^{d_{\mathrm{FDE}}}\end{cases}\text{→} ⎩ ⎨ ⎧Fque:2Rd→RdFDEFdoc:2Rd→RdFDE→将多向量压缩为固定 d FDE d_{\text{FDE}} dFDE维单向量编码
- 相似度计算:用内积 ⟨ F q u e ( Q ) , F doc ( P ) ⟩ \left\langle\mathbf{F}_{\mathrm{que}}(Q), \mathbf{F}_{\text{doc}}(P)\right\rangle ⟨Fque(Q),Fdoc(P)⟩作为原有 Chamfer ( Q , P ) = ∑ q ∈ Q max p ∈ P ⟨ q , p ⟩ \displaystyle{}\text{Chamfer}(Q,P)\text{=}\sum_{q \text{∈} Q} \max _{p \text{∈} P}\langle q, p\rangle Chamfer(Q,P)=q∈Q∑p∈Pmax⟨q,p⟩的替代
- 工作流程:
- 预处理:对所有文档进行 F doc \mathbf{F}_{\text{doc}} Fdoc映射得到 F doc ( P i ) \mathbf{F}_{\text{doc}}(P_i) Fdoc(Pi)的固定维度编码( FDEs \text{FDEs} FDEs)
- 查询初排:对查询 Q Q Q进行 F que \mathbf{F}_{\text{que}} Fque映射得到 F que ( Q ) \mathbf{F}_{\text{que}}(Q) Fque(Q),计算 ⟨ F q u e ( Q ) , F doc ( P i ) ⟩ \left\langle\mathbf{F}_{\mathrm{que}}(Q), \mathbf{F}_{\text{doc}}(P_i)\right\rangle ⟨Fque(Q),Fdoc(Pi)⟩得到 Top- k \text{Top-}k Top-k文档
- 查询重排:再用完整的 ∑ q ∈ Q max p ∈ P ⟨ q , p ⟩ \displaystyle{}\sum_{q \in Q} \max _{p \in P}\langle q, p\rangle q∈Q∑p∈Pmax⟨q,p⟩相似度,对 Top- k \text{Top-}k Top-k个文档进行重排
- 备注的点:
- F doc / F que \mathbf{F}_{\text{doc}}/\mathbf{F}_{\text{que}} Fdoc/Fque是与数据分布无关,由此对不同分布的处理都有鲁棒性
- ⟨ F q u e ( Q ) , F doc ( P i ) ⟩ \left\langle\mathbf{F}_{\mathrm{que}}(Q), \mathbf{F}_{\text{doc}}(P_i)\right\rangle ⟨Fque(Q),Fdoc(Pi)⟩求解过程在高度优化的 MIPS \text{MIPS} MIPS求解器中完成
2. \textbf{2. } 2. 固定维度嵌入( FDEs \textbf{FDEs} FDEs)
2.1. FDE \textbf{2.1. FDE} 2.1. FDE的生成过程

1️⃣文本嵌入:对查询文本和段落文本分别应用嵌入器(如 ColBERTv2 \text{ColBERTv2} ColBERTv2),得到各自的多向量嵌入
- 查询嵌入 Q Q Q: { q 1 , q 2 , . . . , q m } \{q_1,q_2,...,q_m\} {q1,q2,...,qm},其中 q i ⊆ R d q_i\text{⊆}\mathbb{R}^{d} qi⊆Rd即为固定 d d d维
- 段落嵌入 P P P: { p 1 , p 2 , . . . , p n } \{p_1,p_2,...,p_n\} {p1,p2,...,pn},其中 p i ⊆ R d p_i\text{⊆}\mathbb{R}^{d} pi⊆Rd即为固定 d d d维
2️⃣向量分桶:用 SimHash \text{SimHash} SimHash将原有空间分为 2 k sim 2^{k_{\text{sim}}} 2ksim个桶,每个桶用长为 k sim k_{\text{sim}} ksim的定长二进制向量编码
- 法向抽取:从高斯分布中抽取 k sim ≥ 1 k_{\text{sim}}\text{≥}1 ksim≥1个向量 g 1 , … , g k sim ∈ R d g_{1},\ldots,g_{k_{\text{sim}}}\text{∈}\mathbb{R}^{d} g1,…,gksim∈Rd,作为 k sim k_{\text{sim}} ksim个超平面的法向量
- 空间划分: φ ( x ) = ( 1 ( ⟨ g 1 , x ⟩ > 0 ) , … , 1 ( ⟨ g k sim , x ⟩ > 0 ) ) \varphi(x)\text{=}\left(\mathbf{1}\left(\left\langle{}g_{1},x\right\rangle{}\text{>}0\right),\ldots,\mathbf{1}\left(\left\langle{}g_{k_{\text{sim}}},x\right\rangle{}\text{>}0\right)\right) φ(x)=(1(⟨g1,x⟩>0),…,1(⟨gksim,x⟩>0))
- 1 ( ⟨ g i , x ⟩ > 0 ) \mathbf{1}\left(\left\langle{}g_{i},x\right\rangle{}\text{>}0\right) 1(⟨gi,x⟩>0):当 ⟨ g i , x ⟩ > 0 \langle{}g_{i},x\rangle{}\text{>}0 ⟨gi,x⟩>0成立(即 x x x投影在超平面 g i g_i gi的正侧)时,将该位设为 1 1 1
- 向量分桶:让所有的 m + n m\text{+}n m+n个嵌入通过 φ ( ⋅ ) \varphi(\cdot) φ(⋅)得到长 k sim k_{\text{sim}} ksim的二进制编码,相同编码者(即桶编码)放入同一桶
3️⃣向量生成:按照如下三种情况,为每个桶 k k k都生成一个子向量 q ⃗ ( k ) , p ⃗ ( k ) ⊆ R d \vec{q}_{(k)},\vec{p}_{(k)}\text{⊆}\mathbb{R}^{d} q(k),p(k)⊆Rd
Case \textbf{Case} Case 桶 k \boldsymbol{k} k的情况 桶 k \boldsymbol{k} k子向量 q ⃗ ( k ) \boldsymbol{\vec{q}_{(k)}} q(k) 桶 k \boldsymbol{k} k子向量 p ⃗ ( k ) \boldsymbol{\vec{p}_{(k)}} p(k) Case-0 \text{Case-0} Case-0 无 p i → { q 1 , q 2 , . . . ∣ } p_i\text{→}\{q_1,q_2,...\mid{}\} pi→{q1,q2,...∣} q ⃗ ( k ) = ∑ q i \displaystyle{}\vec{q}_{(k)}=\sum{}q_i q(k)=∑qi p ⃗ ( k ) = \displaystyle{}\vec{p}_{(k)}= p(k)=与该桶海明距离最近的 p p p Case-1 \text{Case-1} Case-1 单 p i → { q 1 , q 2 , . . . ∣ p } p_i\text{→}\{q_1,q_2,...\mid{}p\} pi→{q1,q2,...∣p} q ⃗ ( k ) = ∑ q i \displaystyle{}\vec{q}_{(k)}=\sum{}q_i q(k)=∑qi p ⃗ ( k ) = p \displaystyle{}\vec{p}_{(k)}=p p(k)=p Case-n \text{Case-n} Case-n 多 p i → { q 1 , q 2 , . . . ∣ p 1 , p 2 , . . . } p_i\text{→}\{q_1,q_2,...\mid{}p_1,p_2,...\} pi→{q1,q2,...∣p1,p2,...} q ⃗ ( k ) = ∑ q i \displaystyle{}\vec{q}_{(k)}=\sum{}q_i q(k)=∑qi p ⃗ ( k ) = 1 # p ∑ p j \displaystyle{}\vec{p}_{(k)}=\cfrac{1}{\#p}\sum{}p_j p(k)=#p1∑pj( p p p的质心) 4️⃣向量压缩:对每个 q ⃗ ( k ) , p ⃗ ( k ) ⊆ R d \vec{q}_{(k)},\vec{p}_{(k)}\text{⊆}\mathbb{R}^{d} q(k),p(k)⊆Rd应用随机线性投影 ψ : R d → R d proj ( d proj ≤ d ) \psi\text{:}\mathbb{R}^{d}\text{→}\mathbb{R}^{d_{\text{proj}}}(d_{\text{proj}}\text{≤}d) ψ:Rd→Rdproj(dproj≤d)
- 投影函数: ψ ( x ) = ( 1 d proj ) S x \boldsymbol{\psi}(x)\text{=}\left(\cfrac{1}{\sqrt{d_{\text{proj}}}}\right)\mathbf{S}x ψ(x)=(dproj1)Sx,其中 S ∈ R d proj × d \mathbf{S}\text{∈}\mathbb{R}^{d_{\text{proj}}\text{×}d} S∈Rdproj×d为随机矩阵
- 当 d proj = d d_{\text{proj}}\text{=}d dproj=d时 S \mathbf{S} S的每个元素 s i j = 1 s_{ij}\text{=}1 sij=1,即 ψ ( x ) = x \boldsymbol{\psi}(x)\text{=}x ψ(x)=x
- 当 d proj < d d_{\text{proj}}\text{<}d dproj<d时 S \mathbf{S} S的每个元素 s i j s_{ij} sij满足离散均匀分布 P r [ s i j = 1 ] = P r [ s i j =– 1 ] = 1 2 \mathbb{Pr}\left[s_{ij}\text{=}1\right]\text{=}\mathbb{Pr}\left[s_{ij}\text{=}–1\right]\text{=}\cfrac{1}{2} Pr[sij=1]=Pr[sij=–1]=21
- 投影操作: { q ⃗ ( k ) , ψ ⊆ R d proj ← ψ ( q ⃗ ( k ) ) q ⃗ ( k ) ⊆ R d p ⃗ ( k ) , ψ ⊆ R d proj ← ψ ( p ⃗ ( k ) ) p ⃗ ( k ) ⊆ R d \begin{cases}\vec{q}_{(k),\psi}\text{⊆}\mathbb{R}^{d_{\text{proj}}}\xleftarrow{\psi\left(\vec{q}_{(k)}\right)}\vec{q}_{(k)}\text{⊆}\mathbb{R}^{d}\\\\\vec{p}_{(k),\psi}\text{⊆}\mathbb{R}^{d_{\text{proj}}}\xleftarrow{\psi\left(\vec{p}_{(k)}\right)}\vec{p}_{(k)}\text{⊆}\mathbb{R}^{d}\end{cases} ⎩ ⎨ ⎧q(k),ψ⊆Rdprojψ(q(k))q(k)⊆Rdp(k),ψ⊆Rdprojψ(p(k))p(k)⊆Rd
- 合并操作:将每个桶的压缩向量依次从左到右合并 → { q ⃗ ψ = ( q ⃗ ( 1 ) , ψ , … , q ⃗ ( B ) , ψ ) ⊆ R d proj 2 k s i m p ⃗ ψ = ( p ⃗ ( 1 ) , ψ , … , p ⃗ ( B ) , ψ ) ⊆ R d proj 2 k s i m \text{→}\begin{cases}\vec{q}_{\psi}\text{=}\left(\vec{q}_{(1),\psi},\ldots,\vec{q}_{(B),\psi}\right)\text{⊆}\mathbb{R}^{d_{\text{proj}}2^{k_{sim}}}\\\\\vec{p}_{\psi}\text{=}\left(\vec{p}_{(1),\psi},\ldots,\vec{p}_{(B),\psi}\right)\text{⊆}\mathbb{R}^{d_{\text{proj}}2^{k_{sim}}}\end{cases} →⎩ ⎨ ⎧qψ=(q(1),ψ,…,q(B),ψ)⊆Rdproj2ksimpψ=(p(1),ψ,…,p(B),ψ)⊆Rdproj2ksim
5️⃣重复生成:重复2️⃣ → \text{→} →4️⃣过程 R reps R_{\text{reps}} Rreps次,每次重复完成后生成 q ⃗ i , ψ , p ⃗ i , ψ \vec{q}_{i,\psi},\vec{p}_{i,\psi} qi,ψ,pi,ψ,拼接所有 q ⃗ i , ψ , p ⃗ i , ψ \vec{q}_{i,\psi},\vec{p}_{i,\psi} qi,ψ,pi,ψ
- Q Q Q最终生成的单向量: F q u e ( Q ) = ( q ⃗ 1 , ψ , … , q ⃗ R reps , ψ ) ⊆ R d proj 2 k s i m R reps \mathbf{F}_{\mathrm{que}}(Q)\text{=}\left(\vec{q}_{1,\psi},\ldots,\vec{q}_{R_{\text{reps}},\psi}\right)\text{⊆}\mathbb{R}^{d_{\text{proj}}2^{k_{sim}}R_{\text{reps}}} Fque(Q)=(q1,ψ,…,qRreps,ψ)⊆Rdproj2ksimRreps
- P P P最终生成的单向量: F d o c ( P ) = ( p ⃗ 1 , ψ , … , p ⃗ R reps , ψ ) ⊆ R d proj 2 k s i m R reps \mathbf{F}_{\mathrm{doc}}(P)\text{=}\left(\vec{p}_{1,\psi},\ldots,\vec{p}_{R_{\text{reps}},\psi}\right)\text{⊆}\mathbb{R}^{d_{\text{proj}}2^{k_{sim}}R_{\text{reps}}} Fdoc(P)=(p1,ψ,…,pRreps,ψ)⊆Rdproj2ksimRreps
6️⃣相似度:和但向量模型一样,就是二者的内积 ⟨ F q u e ( Q ) , F d o c ( P ) ⟩ \left\langle{\mathbf{F}_{\mathrm{que}}(Q),\mathbf{F}_{\mathrm{doc}}(P)}\right\rangle ⟨Fque(Q),Fdoc(P)⟩
2.Muvera \textbf{2.Muvera} 2.Muvera的理论保证
0️⃣一些前提
- 归一化的 Chamfer \text{Chamfer} Chamfer相似度: NChamfer ( Q , P ) = 1 ∣ Q ∣ Chamfer ( Q , P ) ∈ [ − 1 , 1 ] \text{NChamfer}(Q,P)\text{=}\cfrac{1}{|Q|}\text{Chamfer}(Q,P)\text{∈}[-1,1] NChamfer(Q,P)=∣Q∣1Chamfer(Q,P)∈[−1,1],即 MaxSim \text{MaxSim} MaxSim平均值-
- 默认所有的嵌入都归一化: { ∥ q ∥ 2 = q 1 2 + q 2 2 + ⋯ + q n 2 = 1 ∥ p ∥ 2 = p 1 2 + p 2 2 + ⋯ + p n 2 = 1 \begin{cases}\|q\|_{2}\text{=}\sqrt{q_1^2\text{+}q_2^2\text{+}\cdots\text{+}q_n^2}\text{=}1\\\\\|p\|_{2}\text{=}\sqrt{p_1^2\text{+}p_2^2\text{+}\cdots\text{+}p_n^2}\text{=}1\end{cases} ⎩ ⎨ ⎧∥q∥2=q12+q22+⋯+qn2=1∥p∥2=p12+p22+⋯+pn2=1
1️⃣定理 2-1 \text{2-1} 2-1: FDE \text{FDE} FDE对 Chamfer \text{Chamfer} Chamfer相似度的近似程度,可以达到 ε - ε\text{-} ε-加相似性
- 给定条件:对于 ∀ ε , δ > 0 \forall\varepsilon,\delta\text{>}0 ∀ε,δ>0,设定 m = ∣ Q ∣ + ∣ P ∣ m\text{=}|Q|\text{+}|P| m=∣Q∣+∣P∣
- 设定参数: { k sim = O ( log ( m δ − 1 ) ε ) d proj = O ( 1 ε 2 log ( m ε δ ) ) R reps = 1 ⇒ d FDE = ( m δ ) O ( 1 ε ) \begin{cases}k_{\text{sim}}\text{=}O\left(\cfrac{\log{}\left(m\delta^{-1}\right)}{\varepsilon}\right)\\\\d_{\text{proj}}\text{=}O\left(\cfrac{1}{\varepsilon^{2}}\log{}\left(\cfrac{m}{\varepsilon\delta}\right)\right)\\\\R_{\text{reps}}\text{=}1\end{cases}\xRightarrow{\quad}d_{\text{FDE}}\text{=}\left(\cfrac{m}{\delta}\right)^{O\left(\frac{1}{\varepsilon}\right)} ⎩ ⎨ ⎧ksim=O(εlog(mδ−1))dproj=O(ε21log(εδm))Rreps=1dFDE=(δm)O(ε1)
- 结论: 1 ∣ Q ∣ ⟨ F que ( Q ) , F doc ( P ) ⟩ ∈ [ NChamfer ( Q , P ) – ε , NChamfer ( Q , P ) + ε ] \cfrac{1}{|Q|}\left\langle{}\mathbf{F}_{\text{que}}(Q),\mathbf{F}_{\text{doc}}(P)\right\rangle{}\text{∈}[\text{NChamfer}(Q,P)\text{–}\varepsilon,\text{NChamfer}(Q,P)\text{+}\varepsilon] ∣Q∣1⟨Fque(Q),Fdoc(P)⟩∈[NChamfer(Q,P)–ε,NChamfer(Q,P)+ε]以 P ≥ 1 – δ P\text{≥}1–\delta P≥1–δ概率成立
2️⃣定理 2-2 \text{2-2} 2-2:将原有的 P P P便变成 P i P_i Pi,即一个查询对多个段落
- 给定条件:对于 ∀ ε > 0 \forall\varepsilon\text{>}0 ∀ε>0,设定 m = ∣ Q ∣ + ∣ P i ∣ max m\text{=}|Q|\text{+}|P_i|_{\text{max}} m=∣Q∣+∣Pi∣max
- 设定参数: { k sim = O ( log m ε ) d proj = O ( 1 ε 2 log ( m ε ) ) R reps = O ( 1 ε 2 log n ) ⇒ d FDE = m O ( 1 ε ) × log n \begin{cases}k_{\text{sim}}\text{=}O\left(\cfrac{\log{}m}{\varepsilon}\right)\\\\d_{\text{proj}}\text{=}O\left(\cfrac{1}{\varepsilon^{2}}\log{}(\cfrac{m}{\varepsilon})\right)\\\\R_{\text{reps}}\text{=}O\left(\cfrac{1}{\varepsilon^{2}}\log{}n\right)\end{cases}\xRightarrow{\quad}d_{\text{FDE}}\text{=}m^{O\left(\frac{1}{\varepsilon}\right)}\text{×}\log{}n ⎩ ⎨ ⎧ksim=O(εlogm)dproj=O(ε21log(εm))Rreps=O(ε21logn)dFDE=mO(ε1)×logn
- 结论 1 1 1:假设 P i P_i Pi是用 Muvera \text{Muvera} Muvera方法找到的最相似文档, P j P_j Pj是真实的最相似文档
- NChamfer ( Q , P i ) \text{NChamfer}\left(Q,P_{i}\right) NChamfer(Q,Pi)和 NChamfer ( Q , P j ) \text{NChamfer}\left(Q,P_{j}\right) NChamfer(Q,Pj)互相的差距不会大于 ε \varepsilon ε
- 该结论以 1 – 1 poly ( n ) 1\text{–}\cfrac{1}{\text{poly}(n)} 1–poly(n)1的概率成立
- 结论 2 2 2:从 { P 1 , … , P n } \{P_{1},\ldots,P_{n}\} {P1,…,Pn}中找出最 Q Q Q的最相似文档耗时 O ( ∣ Q ∣ max { d , n } 1 ε 4 log ( m ε ) log n ) \displaystyle{}O\left(|Q|\max\{d,n\}\frac{1}{\varepsilon^{4}}\log{}\left(\frac{m}{\varepsilon}\right)\log{}n\right) O(∣Q∣max{d,n}ε41log(εm)logn)
3. \textbf{3. } 3. 实验及结果
3.1. \textbf{3.1. } 3.1. 离线检索的评估
1️⃣离线的实现
- 向量生成:用 ColBERTv2 \text{ColBERTv2} ColBERTv2为每个 Token \text{Token} Token生成 128 \text{128} 128维的向量,同时强制查询向量数固定 m = 32 m\text{=}32 m=32
- 检索设置:让 Muvera \text{Muvera} Muvera对段落进行排序(不进行任何重排),并以真实的 Chamfer \text{Chamfer} Chamfer相似度为基准评估
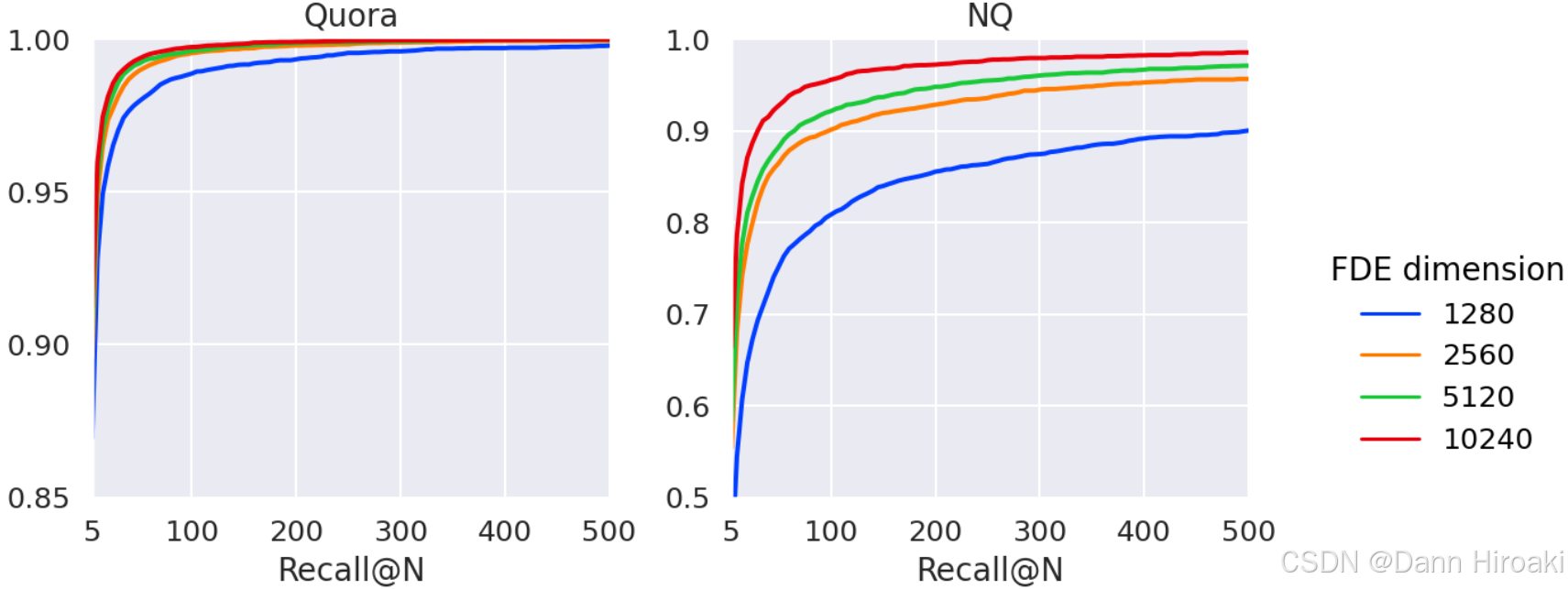
2️⃣ Muvera \text{Muvera} Muvera实验结果
- 维度 / / /参数对 Muvera \text{Muvera} Muvera性能的影响
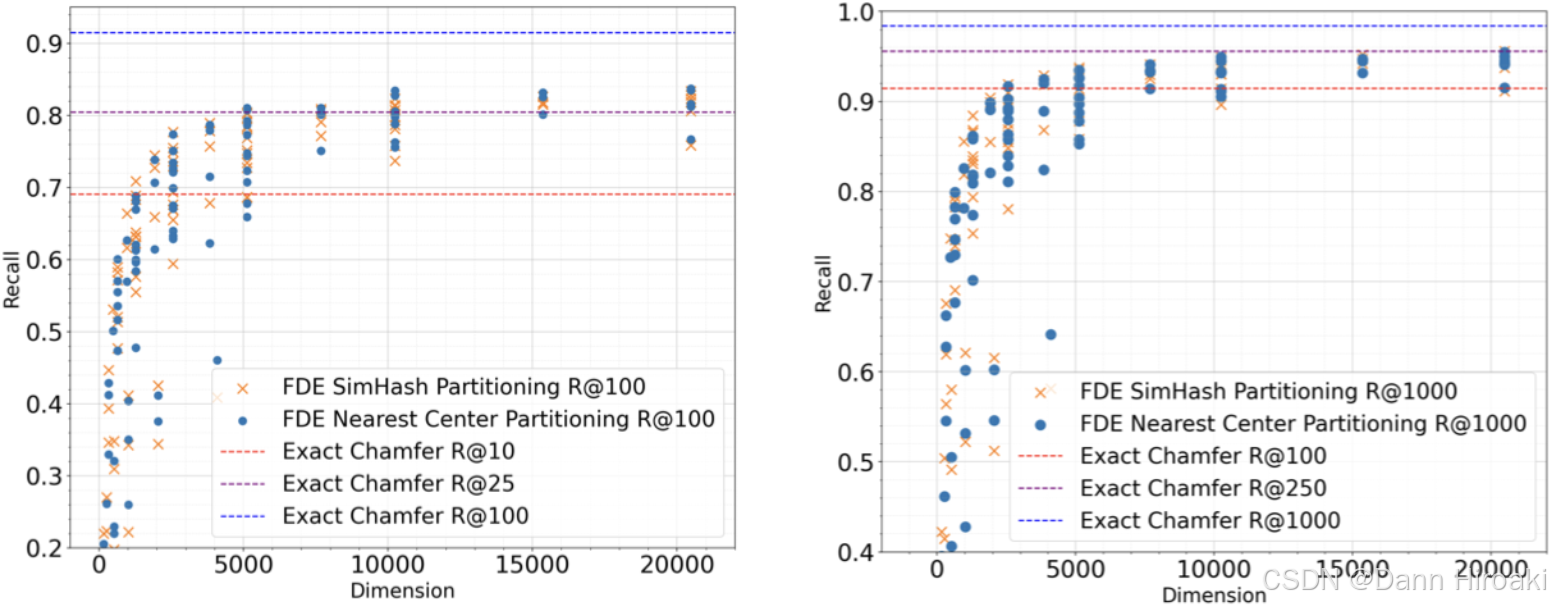
- 维度变化时:随着总维度 d FDE = d proj 2 k s i m R reps d_{\text{FDE}}\text{=}{d_{\text{proj}}2^{k_{sim}}R_{\text{reps}}} dFDE=dproj2ksimRreps的提升 Muvera \text{Muvera} Muvera的检索质量提高
- 维度限定时:参数设置 ( R reps , k sim , d proj ) ∈ { ( 20 , 3 , 8 ) , ( 20 , 4 , 8 ) ( 20 , 5 , 8 ) , ( 20 , 5 , 16 ) } \left({{R}_{\text{reps}},{k}_{\text{sim}},{d}_{\text{proj}}}\right)\text{∈}\{\left({{20},3,8}\right),\left({{20},4,8}\right)\left({{20},5,8}\right),\left({{20},5,{16}}\right)\} (Rreps,ksim,dproj)∈{(20,3,8),(20,4,8)(20,5,8),(20,5,16)}在各自总维度上 Pareto \text{Pareto} Pareto最优
- 与 Chamfer \text{Chamfer} Chamfer距离:以暴力算出的 Chamfer \text{Chamfer} Chamfer结果为基准(而非真实标注数据)的结果
- 不同实现的对比:将 SimHash \text{SimHash} SimHash分桶过程用 k -Means k\text{-Means} k-Means分簇代替后,相同维度 Muvera \text{Muvera} Muvera取得的性能下降
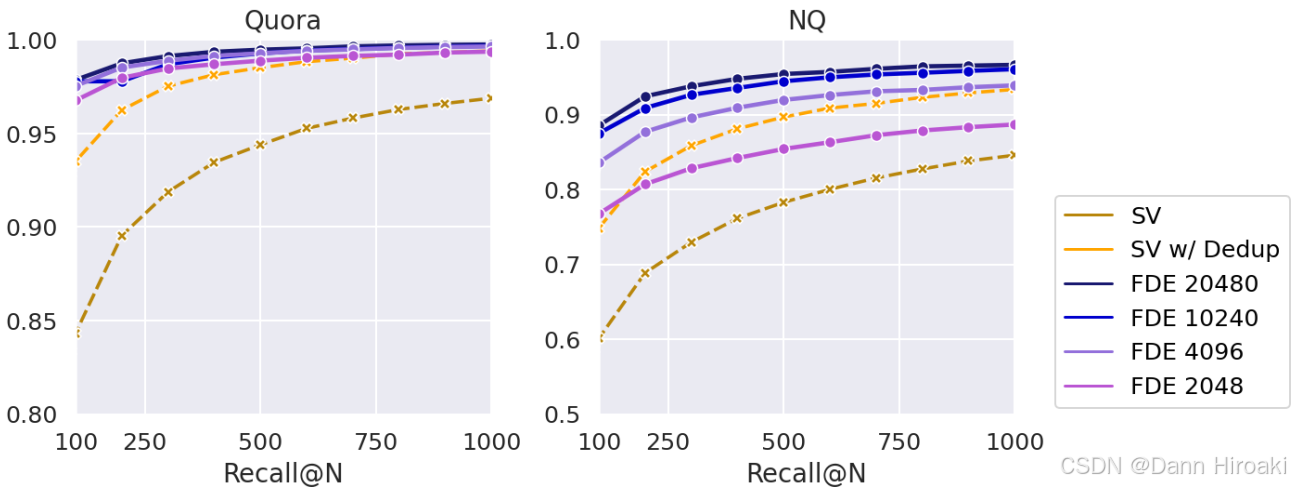
3️⃣与启发式单向量
- 启发式单向量:给定一个查询 Q = { q 1 , q 2 , . . . , q m } Q\text{=}\{q_1,q_2,...,q_m\} Q={q1,q2,...,qm}和一个包含 N N N个段落的段落集 P = { P ( 1 ) , P ( 2 ) , … , P ( N ) } \mathscr{P}\text{=}\left\{P^{(1)},P^{(2)},\ldots,P^{(N)}\right\} P={P(1),P(2),…,P(N)}
- 检索:让每个 q i ∈ Q q_i\text{∈}Q qi∈Q在所有段落子向量集 P ( 1 ) ∪ P ( 2 ) ∪ … ∪ P ( N ) P^{(1)}\text{∪}P^{(2)}\text{∪}\ldots\text{∪}P^{(N)} P(1)∪P(2)∪…∪P(N)中执行 MIPS \text{MIPS} MIPS(最大内积搜索),得到 Top- K \text{Top-}K Top-K的段落子向量
- 回溯:合并 n n n个 q i q_i qi的 Top- K \text{Top-}K Top-K共 n × K n\text{×}K n×K个段落向量,回溯每个向量到其所属段落得候选集 P ′ = { P ( 1 ) , P ( 2 ) , … , P ( M ) } \mathscr{P}^\prime\text{=}\left\{P^{(1)},P^{(2)},\ldots,P^{(M)}\right\} P′={P(1),P(2),…,P(M)}
- 重排:基于精确的 Chamfer ( Q , P ( i ) ) \text{Chamfer}\left(Q,P^{(i)}\right) Chamfer(Q,P(i))距离对候选集 P ′ \mathscr{P}^\prime P′进行排序,得到最终最相似段落
- 成本对比:要让 Q = { q 1 , q 2 , . . . , q m } Q\text{=}\{q_1,q_2,...,q_m\} Q={q1,q2,...,qm}对 P = { P ( 1 ) , P ( 2 ) , … , P ( N ) } \mathscr{P}\text{=}\left\{P^{(1)},P^{(2)},\ldots,P^{(N)}\right\} P={P(1),P(2),…,P(N)}进行查询,假设 P \mathscr{P} P中向量平均长度位 n avg n_{\text{avg}} navg
- Muvera \text{Muvera} Muvera的成本:让 Q Q Q扫描 N N N个但向量即可,每个向量为 d FDE d_{\text{FDE}} dFDE维,故一共需要扫描 N × d FDE N\text{×}d_{\text{FDE}} N×dFDE个浮点数(远小于后者)
- 启发式单向量成本:每个 q i q_i qi都要扫描 n avg n_{\text{avg}} navg个向量(共 m × n avg m\text{×}n_{\text{avg}} m×navg个向量),每次扫描涉及 d d d个浮点数故一共 d × m × n avg d\text{×}m\text{×}n_{\text{avg}} d×m×navg个
- 实验结果:对比 Muvera \text{Muvera} Muvera不同维度(各自 Pareto \text{Pareto} Pareto最优),以及启发式单向量 (SV) \text{(SV)} (SV)对候选段落去重 / / /不去重版本
3.2. \textbf{3.2. } 3.2. 在线端到端的结果
1️⃣端到端的实现
- 整体流程:粗筛 + \text{+} +重排
- 粗筛:将多向量用 Muvera \text{Muvera} Muvera转为单向两,用 DiskANN \text{DiskANN} DiskANN对单向两进行搜索,得到候选段落
- 重排:基于 Chamfer \text{Chamfer} Chamfer相似度对候选段落进行重排
- 球分割:对 Q = { q 1 , q 2 , . . . , q m } Q\text{=}\{q_1,q_2,...,q_m\} Q={q1,q2,...,qm}进行压缩,使得 Q Q Q中向量数目远小于 m m m
- 对于集合 Q = { q 1 , q 2 , . . . , q m } Q\text{=}\{q_1,q_2,...,q_m\} Q={q1,q2,...,qm},每次从集合 Q Q Q中随机选取一种子点 q i q_i qi
- 计算 q i q_i qi与 Q Q Q中剩余点的相似度,相似度大于阈值 τ \tau τ者从 Q Q Q中取出分到 q i q_i qi的簇
- 以此类推贪心地执行下去,不断从剩余集合中取出种子点,再用种子点取出向量构成簇,构成若干簇
- 得到簇质心集 Q C = { q c 1 , q c 2 , . . . , q c k } Q_C\text{=}\{q_{c_1},q_{c_2},...,q_{c_k}\} QC={qc1,qc2,...,qck},其中 k < m k\text{<}m k<m故可将 Q C Q_C QC看作 Q Q Q的一个近似量化
- PQ \text{PQ} PQ量化:对 Muvera \text{Muvera} Muvera向量 F d o c ( P ) \mathbf{F}_{\mathrm{doc}}(P) Fdoc(P)进行压缩,使得其维度远小于 d FDE d_{\text{FDE}} dFDE,用 PQ-C-G \text{PQ-C-G} PQ-C-G表示每 G G G维用 C C C个质心量化
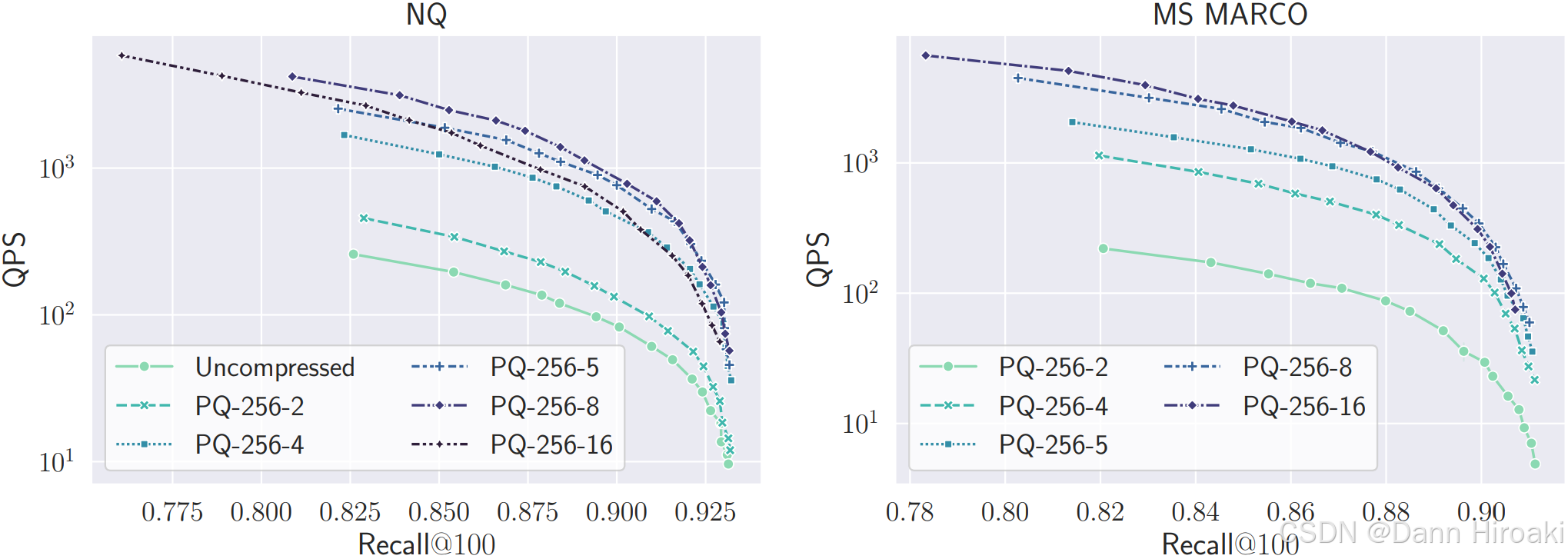
2️⃣实验结果
- QPS \text{QPS} QPS与召回: PQ-256-8 \text{PQ-256-8} PQ-256-8方案的端到端实现最具性能,并且 Muvera \text{Muvera} Muvera对数据的依赖较小
- 与 PLAID \text{PLAID} PLAID的对比:总的来说就是与 PLAID \text{PLAID} PLAID检索质量相当(甚至更优),但是延迟大大降低


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









