






一、引言
在现代网络环境中,视频内容的丰富性使得我们常常需要下载视频进行离线观看。在这篇博客中,我们将介绍一个用Python编写的应用,它可以从B站下载视频和音频并合并成一个文件。我们将使用几个常用的库,包括requests、lxml、fake_useragent、logging和subprocess。
二、项目结构
我们将创建一个简单的图形用户界面(GUI),用户可以在其中输入B站视频的URL,然后程序会抓取视频信息,下载视频和音频,并合并为一个文件。整个过程是异步进行的,确保用户界面的响应性。这里没有图形界面的代码
三、代码解析
1. 导入必要的库
import json
import threading
import requests
from fake_useragent import UserAgent
from lxml import etree
import logging
import os # 用于删除文件
import subprocess # 用于调用ffmpeg
from sp import Ui_MainWindow
json: 用于处理JSON数据,解析从B站获取的媒体信息。threading: 用于创建多线程,以实现异步下载,避免阻塞用户界面。requests: 发送HTTP请求,下载视频和音频数据。fake_useragent: 随机生成HTTP请求的User-Agent,帮助避免被反爬虫机制屏蔽。lxml.etree: 用于解析HTML文档,提取我们需要的信息,如视频标题和链接。logging: 记录程序运行状态,方便调试和查看日志信息。os: 提供与操作系统交互的功能,例如删除临时文件。subprocess: 用于调用外部命令(如ffmpeg)进行音视频合并。from sp import Ui_MainWindow: 导入用户界面类Ui_MainWindow,这通常是使用PyQt或PySide生成的。
2. 主界面类定义
PySide生成的界面和按钮以自己的为准
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
class mainUi(Ui_MainWindow):
def __init__(self, window):
super().__init__()
self.setupUi(window)
self.pushButton.clicked.connect(self.getRequest)
self.headers = {
"Referer": "https://www.bilibili.com/",
"User-Agent": UserAgent().random
}
self.urlList = []
logging.info("初始化完成")
class mainUi(Ui_MainWindow): 定义一个主界面类mainUi,继承自Ui_MainWindow,用于构建用户界面。__init__(self, window): 构造函数,初始化界面并设置事件处理。self.setupUi(window): 设置界面元素。self.pushButton.clicked.connect(self.getRequest): 连接按钮点击事件,触发getRequest方法。self.headers: 定义HTTP请求头,使用UserAgent().random生成随机User-Agent。self.urlList: 用于存储抓取到的URL。logging.info("初始化完成"): 记录初始化完成的日志信息。- 配置日志记录的级别为
INFO,并设置日志信息的格式,包括时间戳、日志级别和日志消息。
2.1视频和音频保存位置
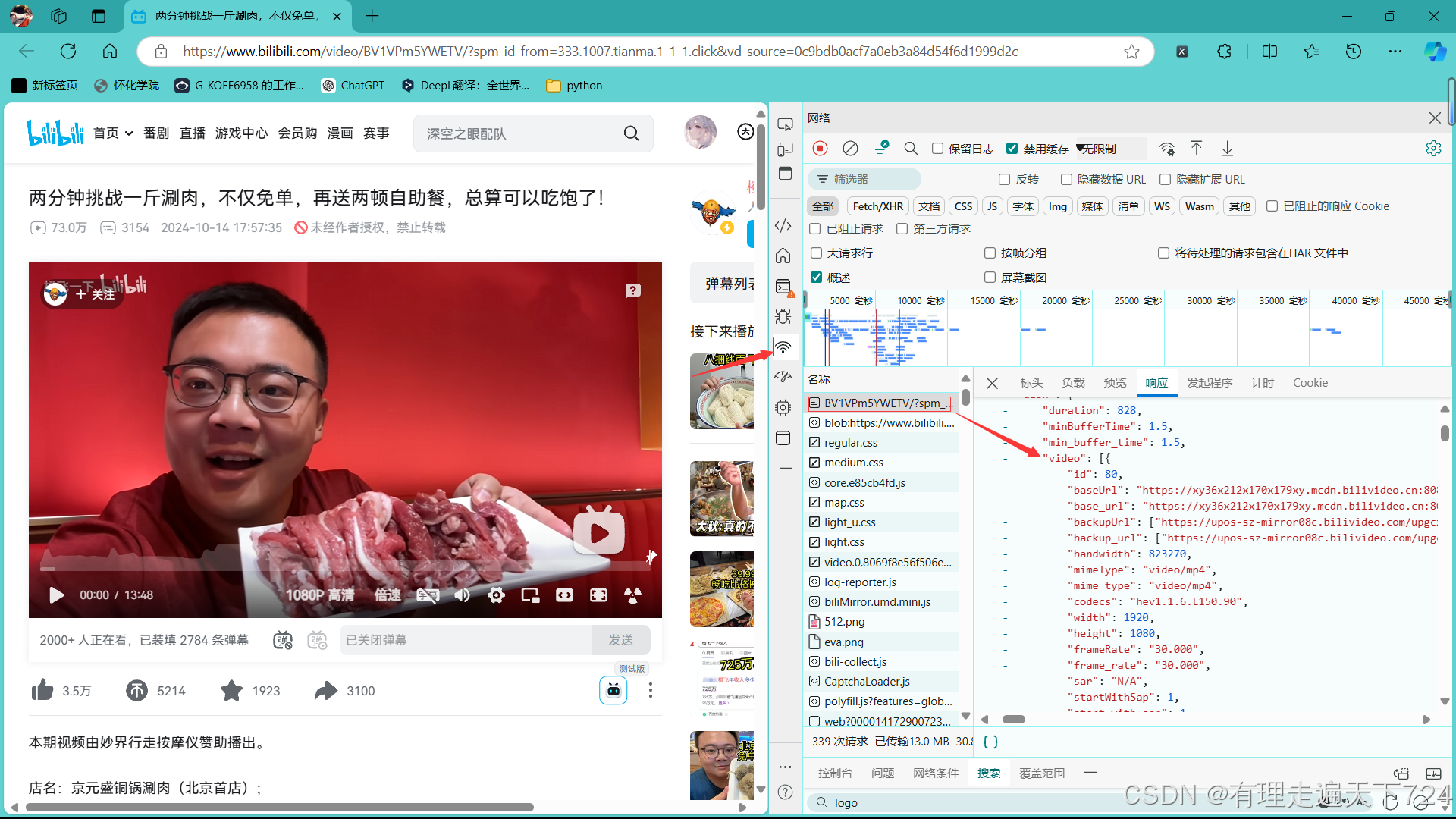 哔哩哔哩中的视频和音频是分开的,图片中是视频存储位置,音频还需往下滑
哔哩哔哩中的视频和音频是分开的,图片中是视频存储位置,音频还需往下滑
3. 请求处理方法
def getRequest(self):
logging.info("开始请求")
url = self.lineEdit.text()
try:
resp = requests.get(url, headers=self.headers, timeout=5).content
urls = etree.HTML(resp).xpath('//h3/a/@href')
logging.info(f"成功获取URL列表: {urls}")
except Exception as e:
logging.error(f"请求失败: {e}")
return
count = 1
for url in urls:
try:
self.urlList.append(url)
resp1 = requests.get(url, headers=self.headers, timeout=5).content
logging.info(f"请求URL: {url}")
title = etree.HTML(resp1).xpath("//h1/text()")
bfl = etree.HTML(resp1).xpath("//div[@class='view-text']/text()")
dm = etree.HTML(resp1).xpath("//div[@class='dm-text']/text()")
time = etree.HTML(resp1).xpath("//div[@class='pubdate-ip-text']/text()")
dz = etree.HTML(resp1).xpath("//div[@title='点赞(Q)']/span/text()")
self.textBrowser.append(f"标题:{title}\n播放量:{bfl}\n弹幕:{dm}\n时间:{time}\n点赞:{dz}\n")
self.textBrowser_2.append(f'<a href="{url}">{url}</a>')
self.textBrowser_2.setOpenExternalLinks(True)
base_info = "".join(etree.HTML(resp1).xpath("/html/head/script[4]/text()"))[20:]
info_dict = json.loads(base_info)
video_url = info_dict["data"]["dash"]['video'][0]["baseUrl"]
audio_url = info_dict["data"]["dash"]['audio'][0]["baseUrl"]
threading.Thread(target=self.saveVideo, args=(video_url, audio_url, count)).start()
count += 1
except Exception as e:
logging.error(f"处理 {url} 时发生错误: {e}")
continue
getRequest(self): 获取用户输入的B站视频URL,处理请求并解析数据。url = self.lineEdit.text(): 从输入框获取用户输入的URL。requests.get(url, headers=self.headers, timeout=5): 发送GET请求并获取响应内容。etree.HTML(resp).xpath('//h3/a/@href'): 使用XPath提取视频链接。self.textBrowser.append(...): 将视频信息添加到文本浏览器中显示。json.loads(base_info): 将抓取的JSON信息解析为Python字典,提取视频和音频的下载链接。threading.Thread(target=self.saveVideo, args=(video_url, audio_url, count)).start(): 启动新线程,异步下载视频和音频。
4. 下载视频和音频
def saveVideo(self, video_url, audio_url, count):
try:
logging.info(f"正在下载视频 {count}...")
video_path = f"video{count}.mp4"
audio_path = f"audio{count}.mp4"
output_path = f"output{count}.mp4"
video = requests.get(video_url, headers=self.headers, timeout=10).content
with open(video_path, "wb") as f:
f.write(video)
logging.info(f"视频 {count} 下载完成")
logging.info(f"正在下载音频 {count}...")
audio = requests.get(audio_url, headers=self.headers, timeout=10).content
with open(audio_path, "wb") as f:
f.write(audio)
logging.info(f"音频 {count} 下载完成")
threading.Thread(target=self.mergeVideoAudio, args=(video_path, audio_path, output_path)).start()
except Exception as e:
logging.error(f"下载或保存文件时出错: {e}")
saveVideo(self, video_url, audio_url, count): 下载视频和音频文件。video_path,audio_path,output_path: 定义保存视频、音频和合并后文件的路径。requests.get(video_url, headers=self.headers, timeout=10).content: 下载视频和音频内容。with open(video_path, "wb") as f: 以二进制写模式保存下载的内容。threading.Thread(target=self.mergeVideoAudio, ...): 下载完成后,启动新线程合并音频和视频。
4.1ffmpeg安装
这里需要去官网下载ffmpeg
ffmpeg官网下载地址Download FFmpeg
下载和配置教程可以看别人写的博客ffmpeg下载安装教程_ffmpeg官网下载-CSDN博客
5. 合并视频和音频
def mergeVideoAudio(self, video_path, audio_path, output_path):
try:
logging.info(f"正在合并视频和音频为 {output_path}...")
ffmpeg_path = r'D:\ffmpeg-7.1-essentials_build\ffmpeg-7.1-essentials_build\bin\ffmpeg.exe'
command = [ffmpeg_path, '-i', video_path, '-i', audio_path, '-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental', output_path]
subprocess.run(command, check=True)
logging.info(f"视频和音频合并完成: {output_path}")
# 删除原始的音频和视频文件
if os.path.exists(video_path):
os.remove(video_path)
logging.info(f"已删除视频文件: {video_path}")
if os.path.exists(audio_path):
os.remove(audio_path)
logging.info(f"已删除音频文件: {audio_path}")
except subprocess.CalledProcessError as e:
logging.error(f"合并视频和音频时出错: {e}")
mergeVideoAudio(self, video_path, audio_path, output_path): 合并视频和音频文件。ffmpeg_path: 指定ffmpeg的安装路径。command: 构造ffmpeg命令行参数,用于合并音频和视频。subprocess.run(command, check=True): 执行合并命令。- 删除临时视频和音频文件,以释放存储空间。
希望这篇博客能对你有所帮助!如果你有任何问题,欢迎在评论区留言。

















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









