







第7章-文件和数据格式化。
1、文件的使用
文件是存储在辅助存储器上的一组数据序列,可以包含任何数据内容。概念上,文件是数据的集合和抽象。文件包括文本文件和二进制文件两种类型。
- (1)、文件的类型
文本文件一般由单一特定编码的字符组成,如UTF-8编码,内容容易统一展示和阅读。大部分文本文件都可以通过文本编辑软件或文字处理软件创建、修改和阅读。由于文本文件存在编码,所以,它也可以被看作是存储在磁盘上的长字符串,如一个txt格式的文本文件。
二进制文件直接由比特О和比特1组成,没有统一的字符编码,文件内部数据的组织格式与文件用途有关。二进制是信息按照非字符但有特定格式形式的文件,如 png格式的图片文件、avi格式的视频文件。二进制文件和文本文件最主要的区别在于是否有统一的这符编码。二进制文件没有统一的字符编码,只能当作字节流,而不能看作是字符串。
无论文件创建为文本文件或者是二进制文件,都可以用“文本文件方式”和“二进制文件方式”打开,但打开后的操作不同。
一个文本文件 a.txt,其内容为“全国计算机等级考试”,采用文本方式打开。这里需要将文本文件与Python程序文件放在同一个目录中。
无论文件创建为文本文件或者是二进制文件,都可以用“文本文件方式”和“二进制文件方式”打开,但打开后的操作不同。
一个文本文件 a.txt,其内容为“全国计算机等级考试”,采用文本方式打开。这里需要将文本文件与Python程序文件放在同一个目录中。
对于大多数中文环境的 Windows 操作系统,默认编码是 GBK。因此,如果你在 Windows 上使用 open() 函数打开一个文本文件时没有指定编码方式,它会默认使用 GBK 编码来读取文件内容。而二进制模式用于处理非文本文件,如图像、音频或视频文件。它不需要指定文件的编码
采用文本文件方式打开:
f=open(r"E:\计算机二级python\python练习代码\第七章\a.txt","rt",encoding="utf-8")
print(f.readlines())
f.close()
#运行结果:
#['小黑课堂\n', '未来教育\n', '计算机二级\n', 'Python复习']
采用二进制文件方式打开:
f=open(r"E:\计算机二级python\python练习代码\第七章\a.txt","rb")
print(f.readlines())
f.close()
#运行结果:
[b'\xe5\xb0\x8f\xe9\xbb\x91\xe8\xaf\xbe\xe5\xa0\x82\r\n', b'\xe6\x9c\xaa\xe6\x9d\xa5\xe6\x95\x99\xe8\x82\xb2\r\n', b'\xe8\xae\xa1\xe7\xae\x97\xe6\x9c\xba\xe4\xba\x8c\xe7\xba\xa7\r\n', b'Python\xe5\xa4\x8d\xe4\xb9\xa0']
- (2)、文件的打开和关闭
Python对文本文件和二进制文件采用统一的操作步骤,即“打开一操作一关闭”,操作系统中的文件默认处于存储状态,首先需要将其打开,使用得当前程序有权操作这个文件,打开不存在的文件系统可以创建这个文件。打开后的文件处于占用状态,此时,另一个进程不能操作这个文件。可以通过一组方法读取文件的内容或向文件写入内容,操作之后需要将文件关闭,关闭将释放对文件的控制使用文件恢复成存储状态,此时,另一进程能够操作这个文件.
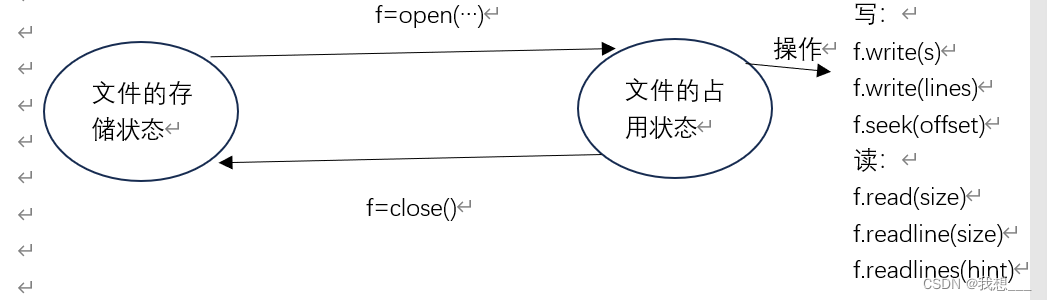
Python通过 open()函数打开一个文件,并返回一个操作这个文件的变量。
语法结构:
变量名=open(文件路径及文件名,打开模式)
open()函数有两个参数:文件名和打开模式。文件名可以是文件的实际名字,也可以是包含完整路径的名字。打开模式用于控制使用何种方式打开文件,open()函数提供了7种基本的打开模式。
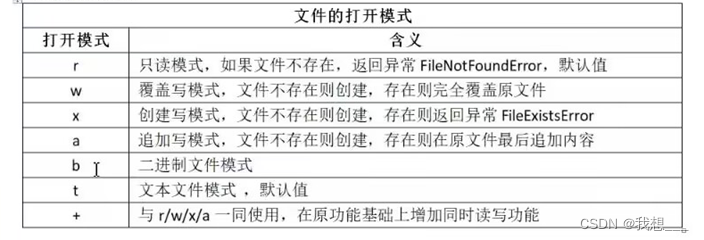
打开模式使用字符串方式表示,根据字符串定义,单引号或者双引号均可。上述打开模式中,r,w,x,a或以和 b,t,+组合使用,形成既表达读写又表达文件模式的方式。
打开文件有一些常用组合,使用方法如下:
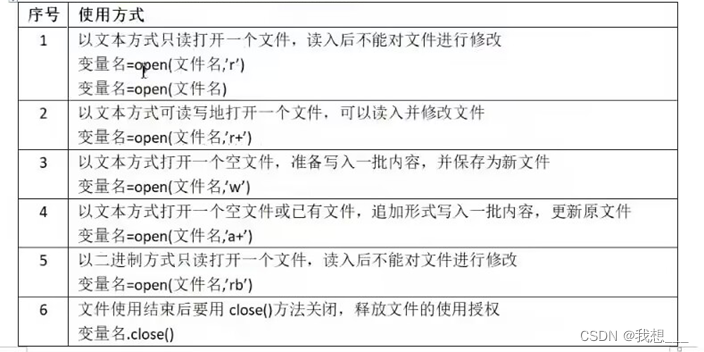
注意事项:由于“\”是字符串中的转义字符,所以表示路径时,使用“\”或“/”代替“\”。
当文件关闭后,再对文件进行读写将产生I/o操作错误。 - (3)、文件的读写
根据打开方式的不同,文件读写也会根据文本文件或二进制打开方式有所不同。
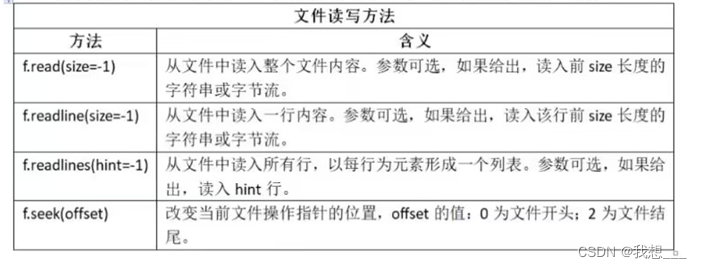
如果文件以文本文件方式打开,则读入字符串;如果文件以二进制方式打开,则读入字节流。
如下是a.txt文件的内容:
“小黑课堂
未来教育
计算机二级
Python复习“
对a.txt文件的读入实例如下。
f=open(r"E:\计算机二级python\python练习代码\第七章\a.txt","r",encoding='utf-8')
print(f.read())
f.seek(0)#将指针重新指向开头
print(f.readline())
f.seek(0)
print(f.readlines())
f.close()
#运行结果:
#小黑课堂
未来教育
计算机二级
Python复习
小黑课堂
['小黑课堂\n', '未来教育\n', '计算机二级\n', 'Python复习']
print(f.read()) 在输出文件内容时,默认不会添加换行符。
结合读取指针理解, f.read()方法已经读取了文件全部内容,读取指针在文件末尾,再次调用f.readlines()方法无法从当前读取指针处读入内容,因此会返回结果为空。
f.seek()方法能够移动读取指针的位置,f.seek(0)将读取指针移动到文件开头,f.seek(2)将读取指针移动到文件结尾。
从文本文件中逐行读入内容并进行处理是一个基本的文件操作需求。文本文件可以看作是由行组成的组合类型,因此,可以使用遍历循环逐行遍历文件。
语法格式:


f.write(s)向文件写入字符串 s,每次写入后,将会记录一个写入指针。该方法可以反复调用,在写入指针后分批写入内容,直至文件被关闭。
f=open(r"E:\计算机二级python\python练习代码\第七章\a.txt","w",encoding='utf-8')
f.write("Python123\n")
f.writelines(['Python','Java','go','c'])
f.close()
使用f.write(s)时,要显示地使用"\n"对写入文本进行分行,如果不进行分行,每次写入的字符串会被连接起来。
f.writelines(lines)直接将列表类型的各元素连接起来写入文件f。
2、数据组织的维度
一组数据在被计算机处理前需要进行一定的组织,表明数据之间的基本关系和逻辑,进而形成“数据的维度”。根据数据的关系不同,数据组织可以分为:一维数据、二维数据和高维数据。
- (1)、一维数据
一维数据由对等关系的有序或无序数据构成,采用线性方式组织,对应于数学中数组的概念。例如,计算机语言列表即可表示为一维数据,一维数据具有线性特点。

一维数据十分常见,任何表现为序列或集合的内容都可以看作是一维数据。
- (2)、二维数据
二维数据,也称表格数据,由关联关系数据构成,采用二维表格方式组织,对应于数学中的矩阵,常见的表格都属于二维数据。
- (3)、高维数据
高维数据由键值对类型的数据构成,采用对象方式组织。
高维数据在 Web系统中十分常用,作为当今Internet组织内容的主要方式,高维数据衍生出 HTML、XML、JSON等具体数据组织的语法结构。
以JSON格式为例,下面给出了描述“Python”的高维数据表示形式,其中冒号(:)形成一个键值对,逗号(,)分隔键值对,JSON格式中[]组织各键值对成为一个整体,与“Python”形成高层次的键值对。高维数据相比一维数据和二维数据能表达更加灵活和复杂的数据出产系。
‘Python’:[
{‘第一章’:’程序设计基本方法’},
{‘第二章’:’Python语言基本语法元素’},
{‘第三章’:’基本数据类型’},
{‘第四章’:’程序的控制结构’}
]
3、一维数据的处理
- (1)、一维数据的表示
一维数据是最简单的数据组织类型,由于是线性结构,在 Python语言中主要采用列表形式表示。例如,计算机语言可以采用一个列表变量表示。
_list=['Python','Java','go','C','C++']
print(_list)
采用列表类型表示一维数据的时候需要注意每个数据的数据类型。
- (2)、一维数据的存储
一维数据的文件存储有多种方式,总体思路是采用特殊字符分隔各数据。采用存储方法包括如下4种。
① 采用空格分隔元素
② 采用逗号分隔元素
③ 采用换行分隔元素
④ 其他特殊符号分隔
这4种方法中,逗号分隔的存储格式叫作CSV格式(Comma-Separated Values,即逗号分隔值),它是一种通用的、相对简单的文件格式,在商业和科学上广泛应用,大部分编辑器都支持直接读入或保存文件为CSV格式,如Windows平台上的记事本或微软Office Excel等。存储的文件一般采用.csv为扩展名。
一维数据保存成 CSV格式后,各元素采用逗号分隔,形成一行,这里的逗号是英文逗号。从 Python表示到数据存储,需要将列表对象输出为CSV格式以及CSV格式读入成列表对象。
列表对象输出为CSV格式文件方法如下,采用字符串的join()方法最为方便。
_list=['Python','Java','go','C','C++']
f=open(r"E:\计算机二级python\python练习代码\第七章\language.csv","w",encoding='utf-8')
f.write(','.join(_list)+'\n')
f.close()
- (3)、一维数据的处理
对一维数据进行处理首先需要从CSV格式文件读入一维数据,并将其表示为列表对象。
需要注意,从 CSV文件中获得内容时,如果最后一个元素后面包含了一个换行符〈“n”)或者其他字符。对于数据的表达和使用来说,这个换行符或其他字符是多余的,需要采用字符串的strip()方法去掉数据尾部的换行符或其他字符,进一步使用split()方法以逗号进行分隔。
_list=['Python','Java','go','C','C++']
f=open(r"E:\计算机二级python\python练习代码\第七章\language.csv","r",encoding='utf-8')
a=f.read()
print(a.split())
f.close()
#运行结果:
# ['Python', 'Java', 'go', 'C', 'C++']
4、二维数据的处理
- (1)、二维数据的表示
二维数据由多个一维数据构成,可以看作是一维数据的组合形式。因此,二维数据可以采用二维列表来表示,即列表的每个元素对应二维数据的一行,这个元素本身也是列表类型,其内部各元素对应这行中的各列值。
即二维数组。
提示:二维数据的数据类型
二维数据一般采用相同的数据类型存储数据,便于操作。
尽管在二维数据中存在大量数值,但由于本例中数值所在行或列不都是数字,存在字符文本,因此,将数值统一表示为字符串形式。
- (2)、二维数据的存储
二维数据由一维数据组成,用CSV格式文件存储。CSV文件的每一行是一维数据,整个CSV文件是一个二维数据。存储以下数据为.csv文件,名称为caa.csv
二维数据存储为CSV格式,需要将二维列表对象写入CSV格式文件以及将CSV格式读成二维列表对象。
二维列表对象输出为CSV格式文件方法如下
_list=[['Python','Java'],['go','C','C++']]
f=open(r"E:\计算机二级python\python练习代码\第七章\caa.csv","w",encoding='utf-8')
for row in _list:
f.write(','.join(row)+'\n')
f.close()
- (3)、二维数据的处理
对二维数据进行处理首先需要从CSV格式文件读入二维数据,并将其表示为二维列表对象。读取 CSV格式文件方法如下
_list=[]
f=open(r"E:\计算机二级python\python练习代码\第七章\caa.csv","r",encoding='utf-8')
for line in f:
_list.append(line.strip('\n').split(','))
f.close()
print(_list)
#运行结果
# [['Python', 'Java'], ['go', 'C', 'C++']]
二维数据处理等同于二维列表的操作。与一维列表不同,二维列表一般需要借助循环遍历实现对每个数据的处理。
语法结构:

_list=[]
f=open(r"E:\计算机二级python\python练习代码\第七章\caa.csv","r",encoding='utf-8')
for line in f:
_list.append(line.strip('\n').split(','))
f.close()
for row in _list:
for word in row:
print(word,end=' ')
#运行结果
# Python Java go C C++
5、选择题
(1)关于Python变量使用,下列说法中错误的是()
A、变量使用不必事先声明
B、变量使用无须先创建和赋值,可以直接使用
C、变量使用无须指定数据类型
D、可以使用del释放变量的内存资源
(2)关于文件,下列说法中错误的是()
A、对已经关闭的文件进行读写操作会默认再次打开文件
B、对文件操作完成后即使不关闭程序也不会报错,所以可以不关闭文件c.
C、对于非空文本文件,read()返回字符串,readlines()返回列表
D、file=open(filename,rb’)表示以只读、二进制方式打开名为filename的文件
(3)以下代码的运行结果是()
fname=input(‘请输入要写入的文件’)
fo=open(fname,‘w+’)
ls=[‘唐诗’∵宋词’;元曲’]
fo.writelines(ls)
fo.seek(0)
for line in fo:
print(line)
fo.close()
A、唐诗
宋词
元曲
B、’唐诗’
‘宋词’
‘元曲’
C、唐诗宋词元曲
D、‘唐诗宋词元曲’
(4)下列选项中不是 Python对文件读操作方法的是()
A、read()
B、readline()
C、readall()
D、readlines()
(5)将一个文件与程序中的对象关联起来的过程,称为()
A、文件读取
B、文件写入
C、文件打开
D、文件关闭
(6)在读写文件之前,需要创建文件对象,采用的方法是()
A、create
B、folder
C、open
D、File
(7)有一非空文本文件 textfile.txt,执行下述代码,程序的输出结果是()
file=open(‘textfile.txt’,r’)
for line in file.readlines()
line+=‘[prefix]’
file.close()
for line in file.readlines():
print(line)
A、逐行输出文件内容
B、逐行输出文件内容,但每行以[prefix]开头
C、报错
D、文件被清空,所以没有输出
(8)关于CSV文件处理,下述描述中错误的是()
A、因为CSV文件以半角逗号分隔每列数据,所以即使用列数据为空也要保留逗号
B、对于包含英文半角逗号的数据,以 CSV文件保存时需进行转码处理
C、因为CSV文件可以由Excel打开,所以是二进制文件
D、通常,CSV文件每行表示一个一维数据,多行表示二维数据。
(9)下列文件/语法格式通常不用作高维数据存储的一项是()
A、HTML
B、XML
C、JSON
D、CSV
10)采用Python语言对CSV文件写入,最可能采用的字符串方法是()
A、strip()
B、 split()
C、join()
D、format()
1B
2A
3C
4C
5C
6C
7C
8C
9D
10C
6、编程题
- (1)、输入一个文件和一个字符串,统计该字符在文件中出现的次数。
"""
- (1)、输入一个文件和一个字符串,统计该字符在文件中出现的次数。
"""
def count_string_occurrences(file_name, string):
count = 0
with open(file_name, 'r') as file:
for line in file:
count += line.count(string)
return count
#请确保将要统计的文件 example.txt 放置在与代码文件相同的目录下,并且文件中包含了要统计的字符串。
# 测试函数
file_name = 'example.txt'
string = 'apple'
occurrences = count_string_occurrences(file_name, string)
print(f"The string '{string}' occurs {occurrences} times in the file.")
- (2)、假设有一个英文文本文件,编写一个程序读取其内容并将里面的大写字母变成小写字母,小写字母变成大写字母。
"""
- (2)、假设有一个英文文本文件,编写一个程序读取其内容并将里面的大写字母变成小写字母,小写字母变成大写字母。
swapcase() 是Python字符串对象的一个内置方法,用于将字符串中的大写字母转换为小写字母,同时将小写字母转换为大写字母。
该方法的语法如下:
str.swapcase()
"""
def swap_case(file_name):
with open(file_name, 'r') as file:
content = file.read()
swapped_content = content.swapcase()
with open(file_name, 'w') as file:
file.write(swapped_content)
# 测试函数
file_name = 'example.txt'
swap_case(file_name)
print("Case swapping completed.")
- (3)、编写一个程序,生成一个10*10的随机矩阵并保存为文件(空格分隔行向量、换行分隔列向量),再写程序将刚才保存的矩阵文件另存为CSV格式,用 Excel或文本编辑器打开看看结果对不对。
"""
- (3)、编写一个程序,生成一个10*10的随机矩阵并保存为文件(空格分隔行向量、换行分隔列向量),
再写程序将刚才保存的矩阵文件另存为CSV格式,用 Excel或文本编辑器打开看看结果对不对。
"""
import numpy as np
import csv
# 生成随机矩阵
matrix = np.random.random((10, 10))
# 保存为文件,空格分隔行向量,换行分隔列向量
with open("matrix.txt", 'w') as file:
for row in matrix:
file.write(' '.join(str(element) for element in row))
file.write('\n')
# 将文件另存为CSV格式
with open("matrix.txt", 'r') as file:
reader = csv.reader(file, delimiter=' ')
matrix_data = list(reader)
with open("matrix.csv", 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(matrix_data)
print("Random matrix saved as matrix.txt and matrix.csv.")
- (4)、编写一个程序,读取一个 Python源代码文件,将文件中所有除保留字外的小写字母换成大写字母,生成后的文件要能够被解释器正确执行。
import re
import keyword
def replace_lowercase(file):
# 读取源代码文件内容
with open(file, 'r') as f:
code = f.read()
# 获取Python保留字
keywords = keyword.kwlist
# 替换小写字母为大写字母
updated_code = re.sub(r'\b([a-z]+)\b', lambda match: match.group(1).upper() if match.group(1) not in keywords else match.group(1), code)
# 生成新文件名
new_file = file.replace(".py", "_updated.py")
# 保存替换后的内容到新文件中
with open(new_file, 'w') as f:
f.write(updated_code)
return new_file
# 测试示例
source_file = "example.py"
new_file = replace_lowercase(source_file)
print(f"文件 {new_file} 生成成功。")
"""
在上述示例代码中,我们首先导入了 re 模块和 keyword 模块。
然后定义了一个名为 replace_lowercase 的函数,该函数接受一个源代码文件名作为参数。
在函数内部,我们首先使用文件操作函数 open() 以只读模式 'r' 打开源代码文件,并读取其内容保存在变量 code 中。
然后,我们使用 keyword.kwlist 获取所有Python保留字,并将它们保存在变量 keywords 中。
接下来,我们使用正则表达式 re.sub() 和匿名函数作为替换函数,将源代码文件中的所有小写字母替换为大写字母,
但在替换之前会检查该单词是否为保留字。替换操作的正则表达式模式 \b([a-z]+)\b
用于匹配一个或多个小写字母组成的完整单词即不包含其他字符)。替换函数通过判断单词是否在保留字列表中,
决定是保持原样还是转换为大写字母。
接着,我们生成一个新的文件名,将原文件名的 ".py" 后缀替换为 "_updated.py",并将新文件名保存在变量 new_file 中。
最后,我们使用文件操作函数 open() 以写入模式 'w' 再次打开一个文件,并写入替换后的代码内容到新文件中。
在测试部分,我们提供了一个示例源代码文件 "example.py",然后调用 replace_lowercase() 函数,
将源代码文件中的所有小写字母(除保留字外)替换为大写字母,并将替换后的内容保存到新文件中。
最后,输出一个提示信息表示文件生成成功,并显示新文件的文件名。
运行上述示例代码后,你将在相同的目录下找到生成的新文件(例如 "example_updated.py")。
该新文件中的所有小写字母(除保留字外)都会被替换为大写字母,并且替换后的文件可以被Python解释器正确执行。
"""
- (5)、编写一个程序,要求能够将元素为任意Python支持的类型(包括含有半角逗号的字符串)的列表转储为CSV,并能够重新正确解析为列表。
import csv
def dump_to_csv(data, filename):
with open(filename, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(data)
def parse_from_csv(filename):
data = []
with open(filename, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
data.append(row)
return data
# 测试示例
my_list = [1, 'hello', [2, 3, 4], {'name': 'John', 'age': 30}]
csv_file = 'data.csv'
# 转储为CSV文件
dump_to_csv(my_list, csv_file)
print(f"转储成功:{csv_file}")
# 重新解析为列表
parsed_list = parse_from_csv(csv_file)
print("解析结果:")
for item in parsed_list:
print(item)
"""
在上述示例代码中,我们首先导入了 csv 模块。
然后,我们定义了一个名为 dump_to_csv 的函数,该函数接受两个参数:要转储的数据列表和目标CSV文件名。
在函数内部,使用 open() 函数以写入模式 'w' 打开目标CSV文件,并创建一个 csv.writer 对象来写入数据。
接下来,我们使用 writer.writerows() 方法将整个数据列表一次性写入CSV文件。
接着,我们定义了一个名为 parse_from_csv 的函数,该函数接受一个参数:要解析的CSV文件名。
在函数内部,使用 open() 函数以读取模式 'r' 打开CSV文件,并创建一个 csv.reader 对象来读取数据。
然后,我们使用一个循环遍历读取器对象,并逐行将数据添加到一个新的列表中。
最后,在测试部分,我们创建了一个包含各种Python支持的类型的列表 my_list,包括整数、字符串、列表和字典。
然后,我们调用 dump_to_csv 函数,将列表转储为CSV文件,并指定文件名为 'data.csv'。成功转储后,我们输出一条提示信息。
接着,我们调用 parse_from_csv 函数,重新解析CSV文件,并将解析结果保存在变量 parsed_list 中。
最后,我们通过一个循环遍历解析结果,并逐个打印出每个元素。
运行上述示例代码后,你将看到CSV文件 'data.csv' 被成功创建,并且解析结果与原始列表 my_list 相同。
"""















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









