






DataFrame增
df<-data.frame(c(1,2,3,4),c(2,3,4,5))
df<-data.frame(list1,list2)
df<-rbind(df,as.data.frame(row_list))
df<-cbind(col_list)
df['new_col'] <- df['col1'] + df['col2']
DataFrame删
df <- df[-2,]
df <- df[,-3]
df <- df[-c(2,4)]
df<-df[ -manyNAs(df) , ]
DataFrame改
改列名
names(df)[ names(df) == 'old_name' ] <- 'new_name'
colnames(df) <- 'new_name'
改数据:
df[a,b] <- new_val
df$col_b[ 谓词(df$col_a) ] <- val_b
df[ ,col_b] <- col_b
df[row_b, ] <- row_b
改数据类型
df$col_a <- as.character(df$col_a)
df$col_a <- as.Date(df$col_a)
蒙版法
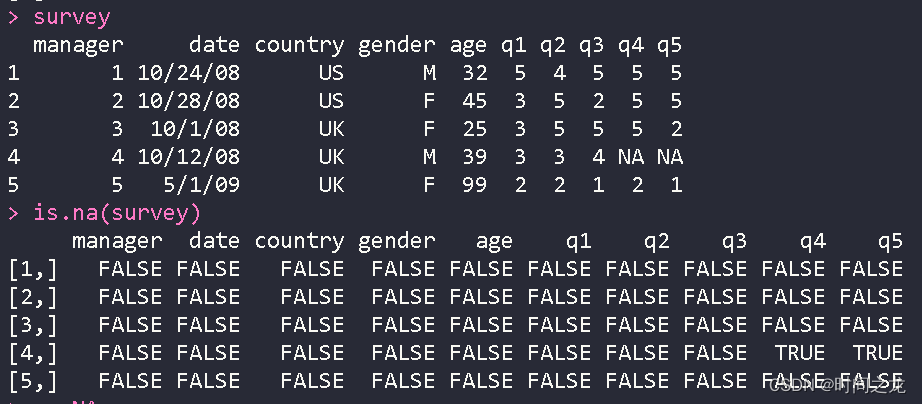
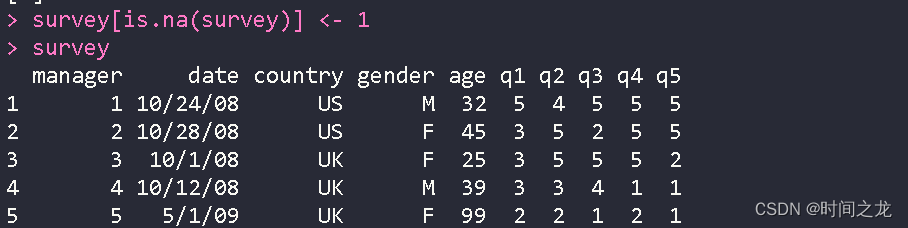
DataFrame查
查列
df$col_a
df['col_a']
df[ , col_a]
df[ , c(col_a, col_b) ]
df[ which(谓词(df$col_a)) , ]
student[which(student$Gender=="F"),]
student[which(student$Gender=="F"),"Age"]
查元素
df$col[1]
df[a,b]
查子集
subset查
subset(student, Gender=="F" & Age<30 , select=c("Name","Age"))
SQL查
library(sqldf)
result <- sqldf("select Name,Age from student where Gender='F' and Age<30")
连接merge
内联:
merge(x = df1, y = df2, by = "CustomerId", all = TRUE)
library('dplyr')
inner_join(x,y, by='col')
左外:
merge(x = df1, y = df2, by = "CustomerId", all.x = TRUE)
library('dplyr')
left_join(x,y, by='col')
右外:
merge(x = df1, y = df2, by = "CustomerId", all.y = TRUE)
library('dplyr')
right_join(x,y, by='col')
全外:
merge(x = df1, y = df2, by = NULL)
library('dplyr')
full_join(x,y, by='col')
交interset
data_z <- interset(data_x, data_y)
并union
data_z <- union(data_x, data_y)
补diffset
data_z <- diffset(data_x, data_y)















 1698
1698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









