






所需文件:
Windos10系统 (建议工作站与工作组,激活Win)
VMware16.2.4 Pro版
CentOS 7 (我用的1810)
hadoop-3.2.2
zookeeper-3.7.1
hbase-2.3.5-bin.tar.gz
目录
前期准备
Windos10 激活 连接工作站 升为专业工作站版
安装并激活 VMware16.2.4 Pro版
VMware虚拟机最小化安装 CentOS 7系统
CentOS 7 需要工具安装与 静态地址配置
虚拟机快照的创建 (很重要)
java环境的配置
克隆CentOS 7并修改 静态IP地址
修改主机名 与 SSH免密登录
利用脚本传输/更新文件
开始搭建Hadoop集群
注意事项
zookeeper配置安装
hadoop配置安装
hbase配置安装
spark配置安装
Java环境的配置
我是使用的虚拟机自带的yum源来进行安装与配置的.
yum list | grep java-1.8.0-openjdk* 我们就下载 java 1.8版本
我们就下载 java 1.8版本
yum install -y java-1.8.0-openjdk*查看java下载的版本
java -version
查看java安装的位置
whereis java
我们可以看到 这里有一个 /usr/lib目录 而/usr/lib 存放常用的动态链接库和软件包的配置文件
我们利用这里面的 路径来配置 java环境变量
进入 /etc/profile 来配置环境变量
vim /etc/profile在 /etc/profile 中添加下面的代码
# # #JAVA
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib

source /etc/profile保存现阶段配置的环境变量
export 的就是让系统去后面这个路径去找 bin sbin等用于系统命令的运行 与 Win下的环境变量一致
查看 java环境配置情况 查看你的 java配置路径
echo $JAVA_HOME
进入 java环境配置目录
cd $JAVA_HOME修改主机名 与 SSH免密登录
修改主机名
master slave1 slave2 slave3 ....
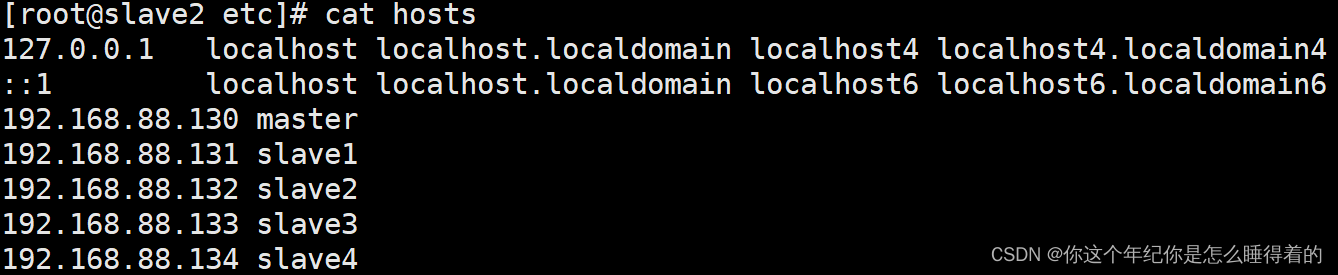
hostnamectl set-hostname masterhostnamectl set-hostname slave1在/etc/hosts 文件中添加 集群的静态IP(每个机子都要有)
SSH免密登录
注意每台虚拟机都要进行 这个操作
进入 root的家目录 利用下列命令获取 密钥与公钥(与git获取命令相同) 并回车三次
ssh-keygen -t rsa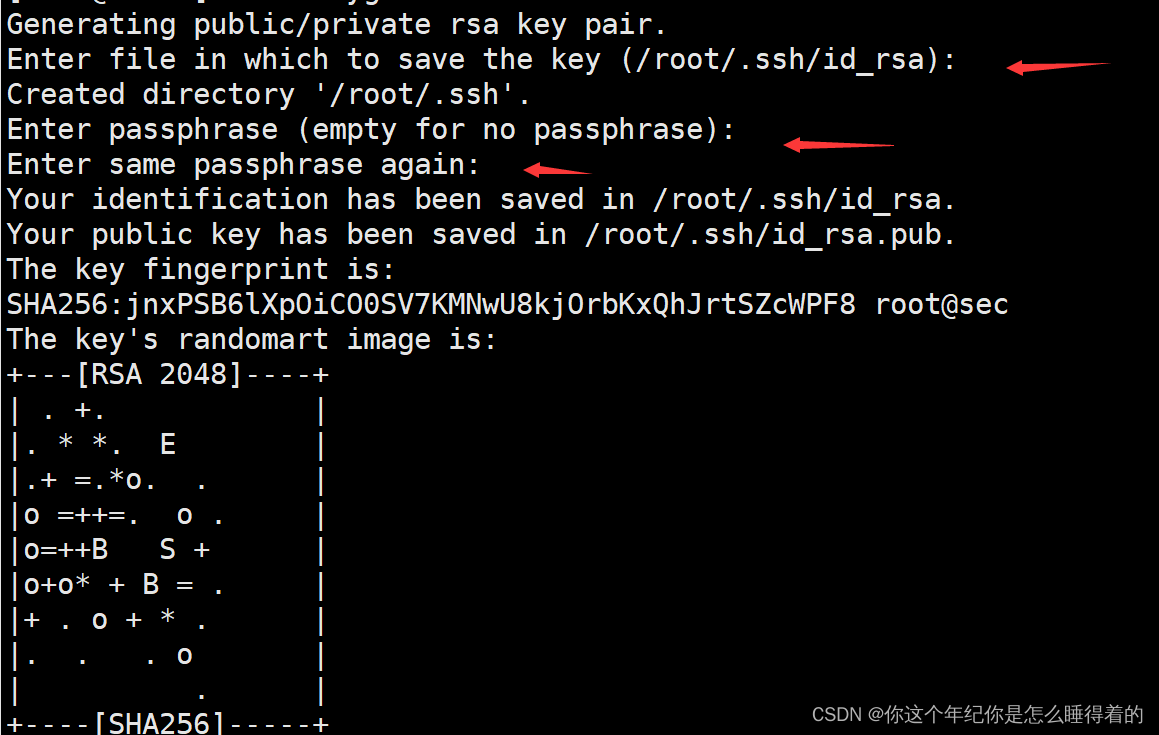
每台虚拟机都有了 密钥后 进入 .ssh目录 将这个虚拟机的公钥拷给 集群中的其他机子
# -a 查看隐藏文件
ll -a
cd .ssh
#拷贝master公钥到 slave1 slave2 slave3 slave4中保存
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
ssh-copy-id slave4
ssh-copy-id master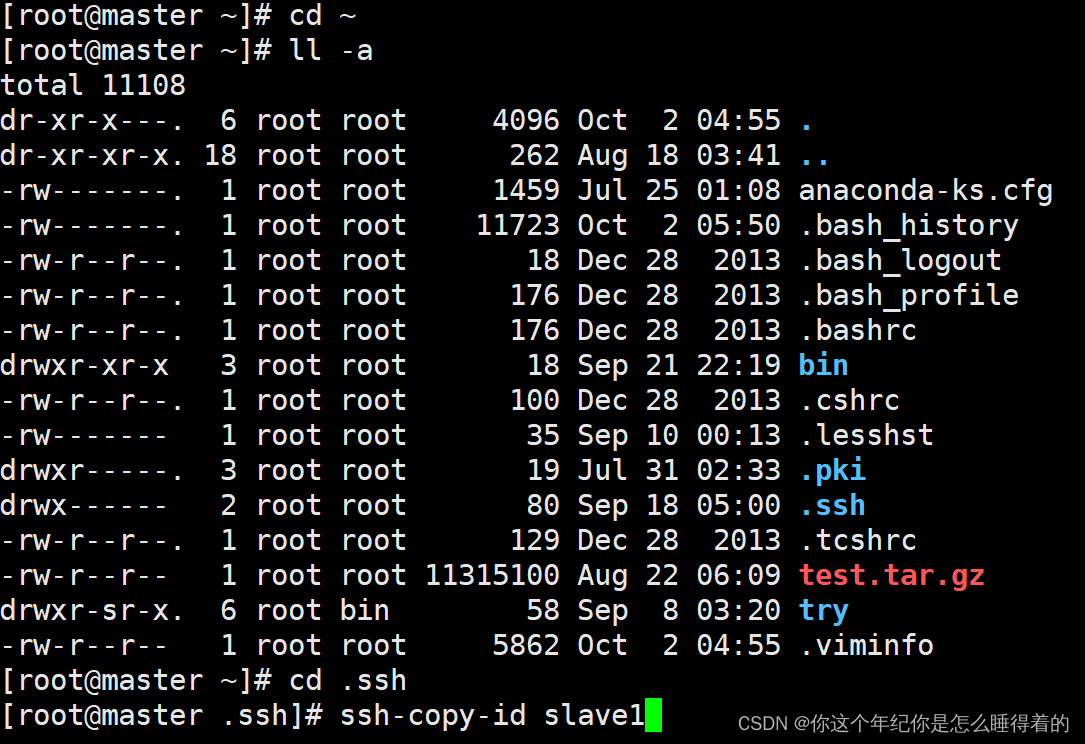
利用脚本传输/更新文件
进入 root的家目录 并创建一个 bin/bash (脚本运行)目录
#进入家目录
cd ~
mkdir -p bin/bash
cd bin/bash创建一个名为xsync 的脚本 并修改其的权限
touch xsync
#修改权限
chmod 777 xsyncvim xsync#!/bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2.遍历集群所有机器
for host in master slave1 slave2 slave3 slave4
do
echo ==================== $host ===================
#3.遍历所有目录,挨个发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#5.获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6.获取当前文件名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
这时我们就可以用这个脚本来进行 文件的同步与更新了
/root/bin/bash/xsync /opt/zookeeper- 注意事项
1. 版本对应
我们再进行安装的时候会看到有许多的版本, 这时我们就要看我们安装的软件的版本是不是对应上的, 如果不是对应的就会出现许多的问题, 为了使我们搭建的集群 稳定运行一定要看清楚版本是否对应.
2. 所使用的版本
java-1.8.0-openjdk
zookeeper-3.7.1
https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
hadoop-3.2.2
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
hbase-2.3.5-bin.tar.gz
http://archive.apache.org/dist/hbase/2.3.5/hbase-2.3.5-bin.tar.gz
大数据环境搭建(1)- HBase,Hadoop,Zookeeper对应关关系_XiaHeShun的博客-CSDN博客_zookeeper和hadoop版本对应
zookeeper配置安装
下载
zookeeper-3.7.1
https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
将安装包放在 /opt/software 目录中
这里直接用 Xshell 来较为方便 (直接拖入就行)
opt 目录 某些可选软件安装后放入此目 安装额外软件所用的目录
software 目录 我用来存放 一些 压缩文件的
cd /opt/software
#没有 software 就创建一个
cd /opt
mkdir software
用Xshell 将下载的 apache-zookeeper-3.7.1-bin.tar.gz拖入这个目录中
解压在 /opt/zookeeper 目录下
cd /opt
mkdir zookeeper
#回去/opt/software目录方便解压
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/software
配置文件
进入apache-zookeeper-3.7.1-bin/conf文件
将zoo_sample.cfg 复制一份命名为 zoo.cfg
#在/opt/zookeeper目录下
#进入apache-zookeeper-3.7.1-bin
cd a*
#查看里面的文件
ll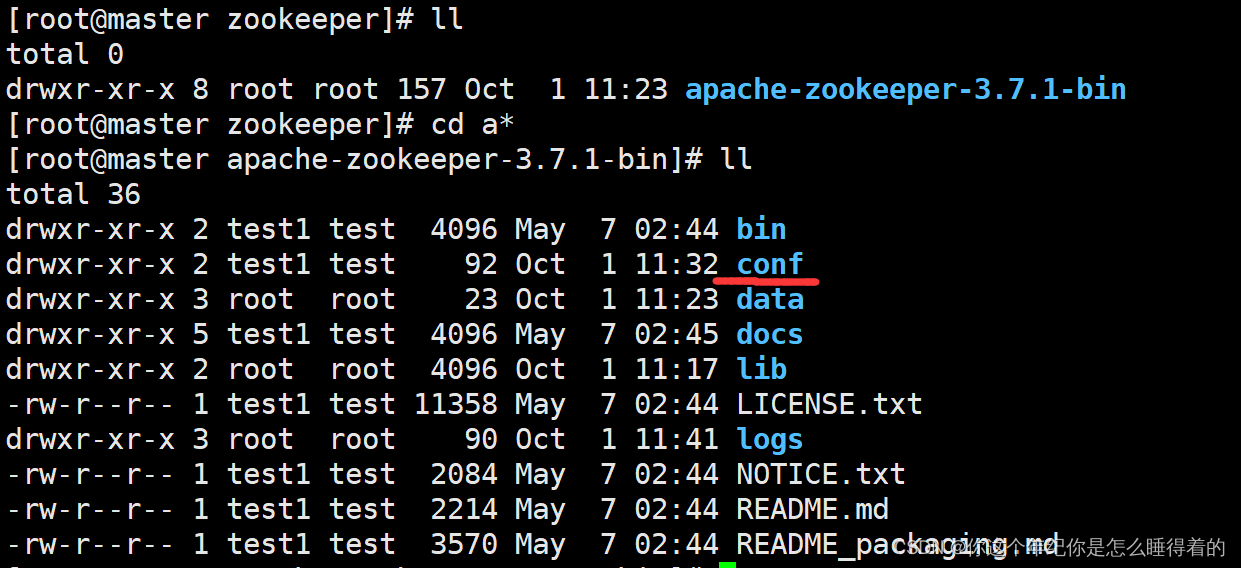
创建 logs目录用来存日志 data目录用来存数据与数据持久化
数据持久化用一个形象的比喻就是 玩游戏保存你的游戏进度
mkdir logs
mkdir data
#进入配置文件中
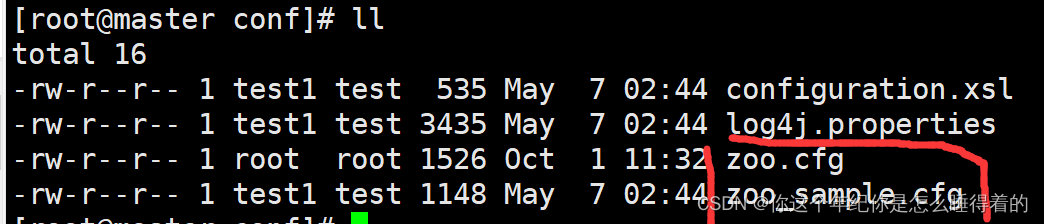
cd conf
#查看里面的配置文件
ll
#复制一份zoo.cfg用与配置
cp zoo_sample.cfg zoo.cfg
进入 zoo.cfg文件中配置
vim zoo.cfg#存放数据 +数据持久化路径
dataDir=/opt/zookeeper/apache-zookeeper-3.7.1-bin/data
#存放日志
dataLogDir=/opt/zookeeper/apache-zookeeper-3.7.1-bin/logs
#客户端端口
clientPort=2181
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小事清理一次
autopurge.purgeInterval=1
initLimit=10
syncLimit=5
#通信心跳数,Zookeeper服务器与客户端心跳时间
tickTime=2000
globalOutstandingLimit=200
# 集群中服务器地址
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
server.4=slave3:2888:3888
server.5=slave4:2888:3888保存退出后 进入刚刚新建的 data目录 创建一个myid文件 并在其中写入编号 给zookeeper用于 选举leader
#放回上一级
cd ..
cd data
#在myid中写入编号 利用了重定向
echo "1" > myid后面在进入 /opt目录中 将zookeeper这个文件所有的内容传递给 其他的几个集群中的机子中
/root/bin/bash/xsync ./zookeeper后修改 刚刚data目录下myid文件的 数字编码
cd /opt/z*/a*/data
echo "2" > myid
echo "3" > myid后面配置/etc/profile中的zookeeper环境变量
export ZOOKEEPER_HOME=/opt/zookeeper/apache-zookeeper-3.7.1-bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin

更新集群中的每一个环境变量
/root/bin/bash/xsync /etc/profile
#记住 保存
source /etc/profile最后就可以运行zookeeper了
当然第一次 可以进入 zookeeper中的bin目录下来开启
cd /opt/z*/a*/bin
#运行zookeeper
sh ./zkServer.sh start注意zookeeper 每一个机子都要打开(使用如下的命令)
zkServer.sh start
查看 zookeeper运行情况 leader 与 follower
zkServer.sh status

jps查看zookeeper的进程运行是否成功
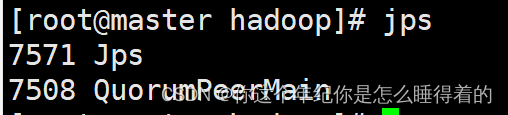
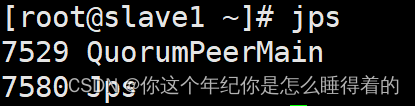
hadoop-3.2.2 配置安装
下载
hadoop-3.2.2
https://dlcdn.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
将安装包 放到 /opt/software中 解压放到 /opt/module中
# 创建 module目录 用存放hadoop-3.2.2
mkdir /opt/module
# 解压放到/opt/module
tar -zxvf hadoop-3.2.2.tar.gz -C /opt/module进入/opt/module/hadoop-3.2.2/etc/hadoop中修改配置文件
core-site.xml
# 修改core-site.xml配置文件
<configuration>
<!--HDFS 临时路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.2/tmp</value>
</property>
<!--HDFS 的默认地址、端口 访问地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>创建 /opt/module/hadoop-3.3.2/tmp目录
mkdir /opt/module/hadoop-3.3.2/tmphdfs-site.xml
<configuration>
<!--hdfs web的地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--是否启用HDFS权限,当值为false时,代表关闭-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--块大小,默认字节128MB-->
<property>
<name>dfs.blocksize</name>
<!--128m-->
<value>134217728</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!--local表示本地运行,classic表示经典mapreduce框架,yarn表示新的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--如果map和reduce任务访问本地库(压缩等),则必须保留原始值
当此值为空时,设置执行环境的命令将取决于操作系统-->
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.2</value>
</property>
<!--可以设置AM【AppMaster】端的环境变量-->
<property>
<name>yarn.app.mapreduce.an.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.2</value>
</property>
</configuration>注意这里的是3.3.2版本通用的没有问题 后面在module目录下 会出现一个 hadoop-3.3.2

yarn-site.xml
<!--集群master-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--容器可能会覆盖的环境变量,而不是使用NodeManager的默认值-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value>
</property>
<!--关闭内存检测,在虚拟机环境中不做配置会报错-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
workers
修改workers文件
vim workers
slave1
slave2
slave3
slave4这里配置我是查看的下面这篇文章【初学大数据】CentOS7安装hadoop3.3.2完全分布式详细流程_栗子叔叔的博客-CSDN博客
后面就是配置 hadoop的环境变量
vim /etc/profile
# # #HADOOP
export HADOOP_HOME=/opt/module/hadoop-3.2.2
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin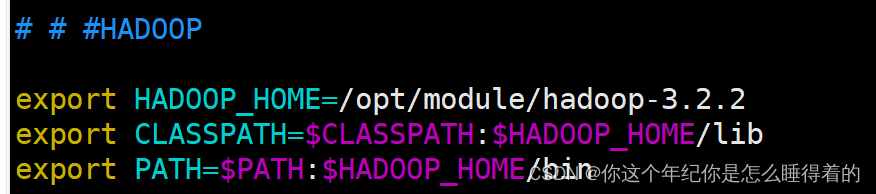
同步module文件 与 /etc/profile文件
/root/bin/bash/xsync /etc/profile
/root/bin/bash/xsymc /opt/mudole在每个机子上 保存环境变量
source /etc/profile分配好了后就基本上安装好了,后面就是
初始化/格式化 Hadoop集群
hadoop namenode -format再打开集群
注意:是在 master的主机下打开集群
# 打开集群
start-all.sh
# 关闭集群
stop-all.sh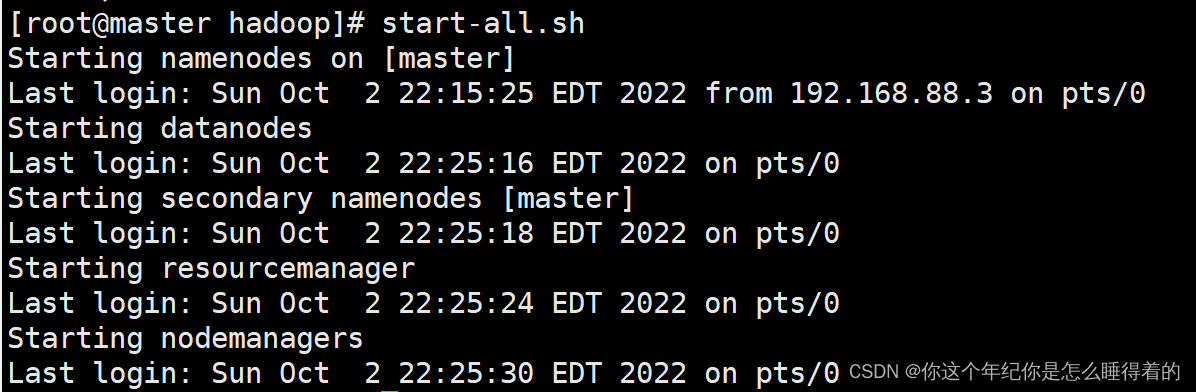
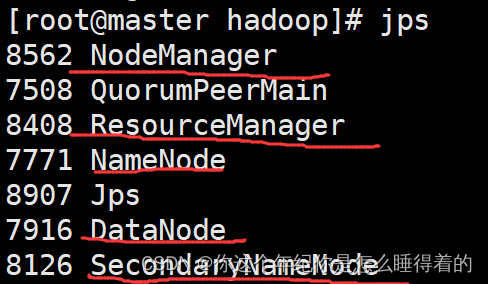
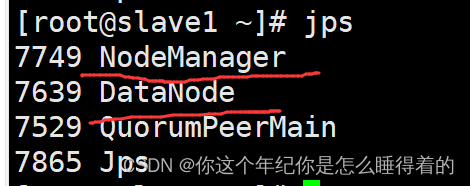
使用 jps查看 hadoop集群是否运行
在监控端口中查看 Web网页中输入
192.168.88.130:50070安装hadoop中的一些问题
在关闭hadoop集群的时候在进行修改
第一个是 datanode启动成功了 但是jps没有显示datanodehadoop中datanode启动成功了,但jps没有的问题_Knight_AL的博客-CSDN博客_datanode启动成功jps不显示
问题产生: data与name中的VERSION中的UUID不一致
cd /opt/module/hadoop-3.3.2/tmp/dfs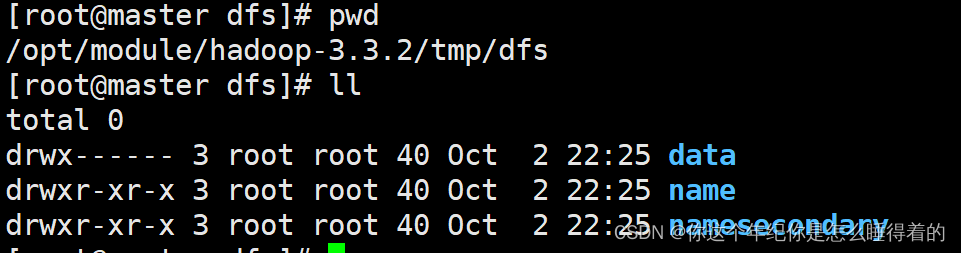
data与name中的 VERSION 有UUID
在这里建议大家不要经常 格式化集群会导致 name中的UUID与data中的UUID不一致
这个时候就要去将name中的UUID复制给data中的UUID
第二个问题是 启动了hadoop集群结果 jps看到每个节点都有 datanode但是在web监控见面下去查看datanode只有 一个 刷新网页的时候还会出现 master与slave(1~4)相互出现
问题产生: 在用xsync 更新的时候 将VERSION中的UUID一起发过去了,导致在集群查找datanode的地址的时候就只有 一个地址可用,
在这里你要删除之前配置静态网络中的UUID这个物理地址(mac)
然后直接就 初始化 就行了
hadoop namenode -format后面可能会出现上述 问题一不过没有关系 跟这上述以问题改就行
第三个问题: 因为我们上面做的是 完全分布式 配置,master主节点也会保存 hdfs的数(datanode) 在后面存的多了,会导致master效率的下降,现在我们想要关闭/禁用master中的datanode
在/opt/module/hadoop-3.2.2/etc/hadoop目录中创建 excludes文件 写入你要禁用的master节点(每个节点都要有)
cd /opt/module/hadoop-3.2.2/etc/hadoop
touch excludes
/root/bin/bash/xsync ./excludeshdfs-site.xml 中添加
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.2.2/etc/hadoop/excludes</value>
</property> 刷新节点使用
刷新Hadoop集群节点
#在master节点下
hdfs dfsadmin -refreshNodes
start-balancer.sh最后我们在尝试一哈 hdfs能不能使用
hdfs dfs -ls -R /当然如果还有什么问题可以去搜一哈 看看其他的文章是怎么弄的 搜问题也行
hbase-2.3.5配置安装
http://archive.apache.org/dist/hbase/2.3.5/hbase-2.3.5-bin.tar.gz
将安装包放在 /opt/software 目录中
解压安装包到/opt目录下
tar -zxvf hbase-2.3.5-bin.tar.gz -C /opt
修改配置文件
进入/opt/hbase-2.3.5
添加要使用的一些目录
data 放数据 logs 放日志 pids 文件
mkdir data pids logs
进入conf目录 修改配置文件
hbase-env.sh
vim hbase-env.sh
#1、设置java安装路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
#2、设置hbase的日志地址
export HBASE_LOG_DIR=${HBASE_HOME}/logs
#3、设置是否使用hbase管理zookeeper(因使用zookeeper管理的方式,故此参数设置为false)
export HBASE_MANAGES_ZK=false
#4、设置hbase的pid文件存放路径
export HBASE_PID_DIR=/opt/hbase-2.3.5/pidshbase-site.xml
<configuration>
<!-- Cluster -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
<description>region server的共享目录,用来持久化HBase</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>HBase的运行模式。false是单机模式,true是分布式模式</description>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase-2.3.5/data</value>
<description>本地文件系统的临时文件夹。</description>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.39</value>
<description>storefile的读缓存占用Heap的大小百分比,当然是越大越好,如果读比写多,开到0.4-0.5也没问题。如果读写较均衡,0.3左右。如果写比读多,果断默认吧。</description>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>900000</value>
<description>hbase client中的rpc请求超时时间</description>
</property>
<!-- Master -->
<property>
<name>hbase.master</name>
<value>master:9000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
<description>HBase Master web 界面端口. 设置为-1 意味着你不想让他运行。</description>
</property>
<!-- regionserver -->
<property>
<name>hbase.regionserver.port</name>
<value>60020</value>
<description>HBase RegionServer绑定的端口</description>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>60030</value>
<description>HBase RegionServer web 界面绑定的端口 设置为 -1 意味这你不想与运行 RegionServer 界面</description>
</property>
<property>
<name>hbase.regionserver.lease.period</name>
<value>180000</value>
<description>客户端租用HRegion server 期限,即超时阀值。单位是毫秒。默认情况下,客户端必须在这个时间内发一条信息,否则视为死掉。</description>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
<description>遇到ZooKeeper session expired(过期), regionserver将选择 restart 而不是 abort(终止)</description>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>100</value>
<description>RegionServers处理远程请求的线程数,如果注重TPS(每秒事务数),可以调大,默认10。
1)值设得越大,意味着内存开销变大;
2)对于提高write的速度,如果瓶颈在做flush、compact、split的速度,磁盘io跟不上,提高线程数,意义不大。</description>
</property>
<property>
<name>hbase.regionserver.codecs</name>
<value>snappy,gz</value>
<description></description>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>2</value>
<description>regionserver在写入时会检查每个region对应的memstore的总大小是否超过了memstore默认大小的2倍(hbase.hregion.memstore.block.multiplier决定),如果超过了则锁住memstore不让新写请求进来并触发flush,避免产生OOM。</description>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>134217728</value>
<description>在当前ReigonServer上单个Reigon的最大存储空间,单个Region超过该值时,这个Region会被自动split成更小的region。</description>
</property>
<!-- Client参数 -->
<property>
<name>hbase.client.scanner.caching</name>
<value>10000</value>
<description>客户端参数,HBase scanner一次从服务端抓取的数据条数</description>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>900000</value>
<description>scanner过期时间</description>
</property>
<!-- Zookeeper -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>1200000</value>
<description>RegionServer与Zookeeper间的连接超时时间。当超时时间到后,ReigonServer会被Zookeeper从RS集群清单中移除,HMaster收到移除通知后,会对这台server负责的regions重新balance,让其他存活的RegionServer接管</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data</value>
<description>ZooKeeper的zoo.conf中的配置。 快照的存储位置</description>
</property>
</configuration>
这里我主要看的是下面的文章来进行配置的,当然我对其中的一些配置 进行了更改最后才成功了。
从零开始搭建个人大数据集群(5)——HBASE 2.3.5安装 - 忘尘客栈
regionservers
slave1
slave2
slave3
slave4
将hadoop配置文件中的core-site.xml hdfs-site.xml 复制过来
cp /opt/module/had*/etc/h*/core-site.xml core-site.xml
cp /opt/module/had*/etc/h*/hdfs-site.xml hdfs-site.xml 
移动包到lib中
cd /opt/hbase*/lib
mkdir native
cd native
ln -s /opt/module/h*/lib/native Linux-amd64配置环境变量 与 分发
# # #hbase-2.3.5
export HBASE_HOME=/opt/hbase-2.3.5
export PATH=$PATH:$HBASE_HOME/bin:/$HBASE_HOME/sbin
export PATH=$PATH:$HBASE_HOME/bin/hbase shell
export HBASE_LIBRARY_PATH=${HBASE_HOME}/lib/native/Linux-amd64
/root/bin/bash/xsync /etc/profile
/root/bin/bash/xsync /opt/hbase-2.3.5
source /etc/profile最后就是打开看看了 先开zookeeper 后 hadoop 最后 hbase
zkServer.sh start
start-all.sh
# 第一次打开hbase
cd /opt/h*/bin
# . 这里是运行的意思
. start-hbase.sh
. hbase shell
# 后面就可以不用进入 bin目录里了
start-hbase.sh
hase shell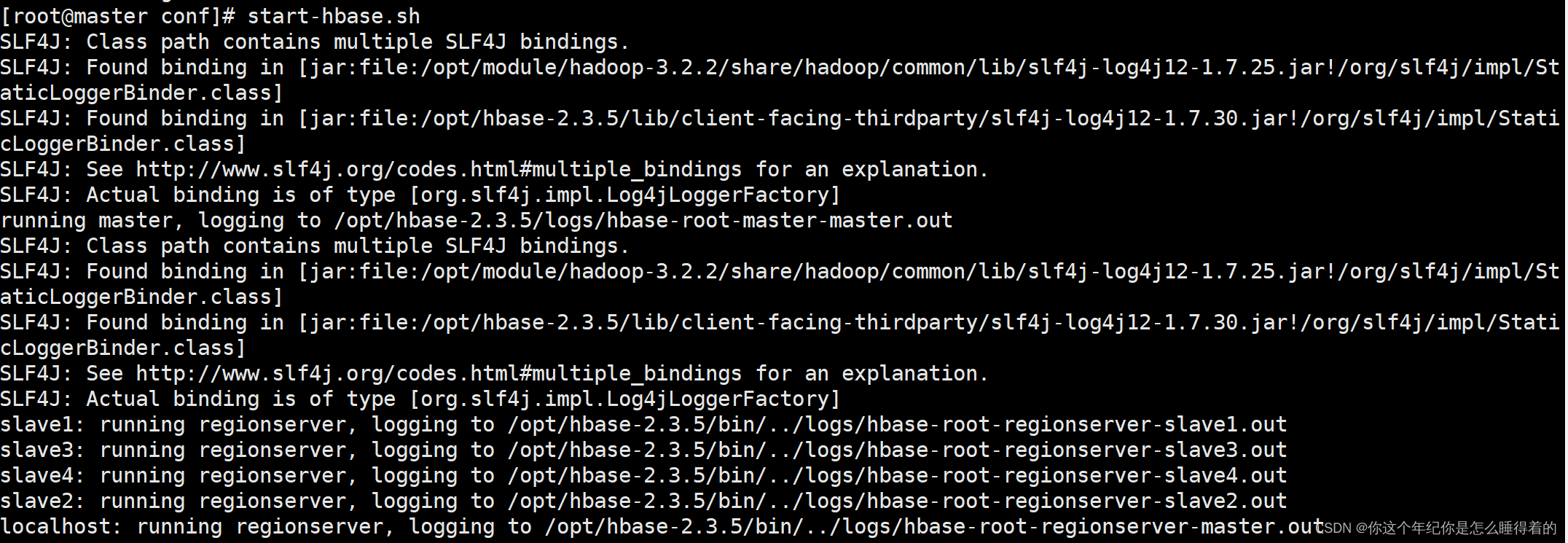 jps查看 进程
jps查看 进程
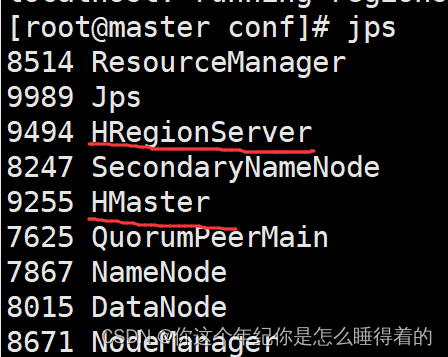
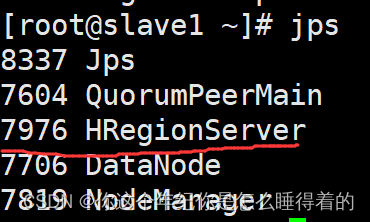
进入 Web网页查看 监控
19.168.88.130:60010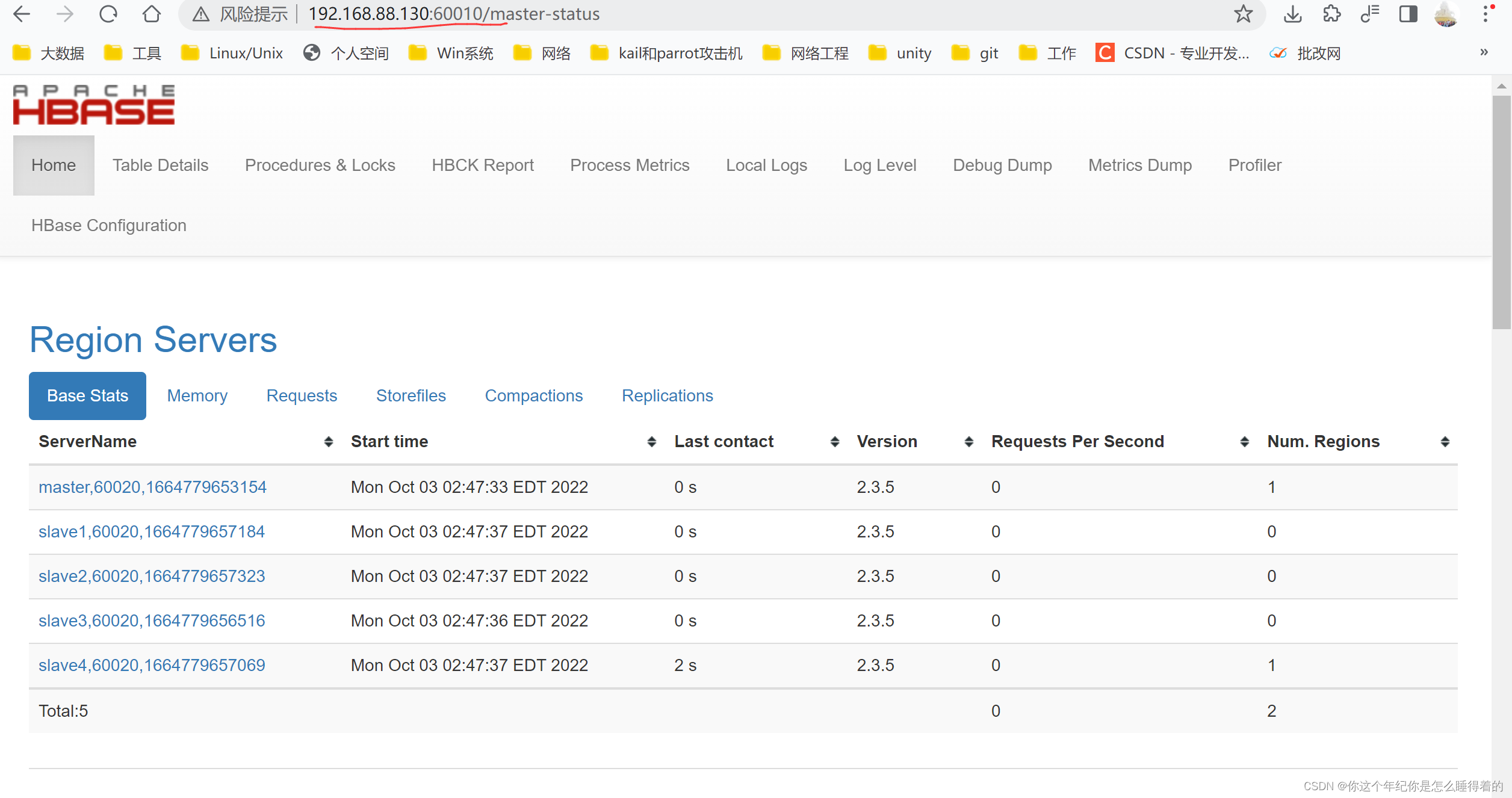
在master主节点下 打开hbase shell
hbase shell使用 status 查看hbase 的状态 出现下面的状态才算成功
status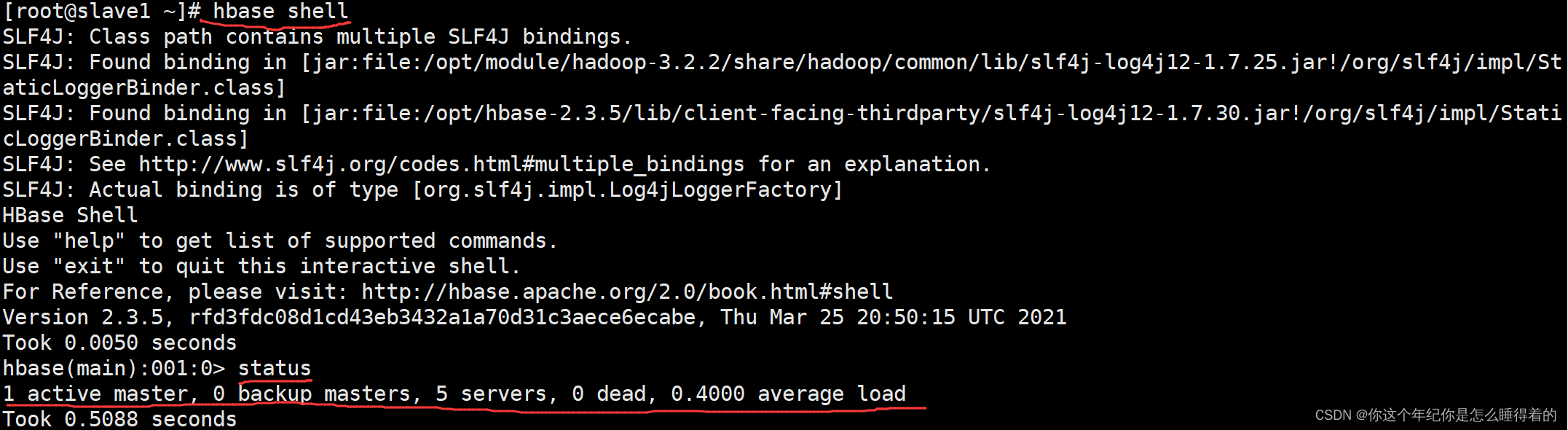
退出
exitstop-hbase.sh
都是在 master主节点下完成的
hbase配置的时候出现的一些问题 (关闭所有hadoop运行进程)
第一个问题: 关闭hbase的时候会出现 no hbase master found 但是 HMaster和HRegionServer都存在
这个问题应该不会出现 它就是 tmp目录 与 pids目录 路径有没有问题
但是还有一种情况是也是no hbase master found 这种情况是zookeeper中没有保存/连接有关的hbase数据 或者是 保存了以前的hbase的数据
打开zookeeper (zkServer.sh) 进入zookeeper命令界面看看
zkCli.sh
#查看有没有hbase目录(数据)
ls /
有就删除
注意: 删除的时候一定要小心使用这个命令
在没有出现这个问题的时候一定不要删除
rmr /hbase没有就说明 上面的配置文件不对,就要重新看看了
退出 zookeeper
quit第二个问题: 如果发现修改了配置文件并重新启动的时候 总是会报一长串的错误,这个时候你可以删除hbase-2.3.5目录与 和它有关的目录/文件,重新开始进行配置了
spark-3.1.3-bin-hadoop3.2的完全分布式安装
去除master中的worker使其自做master资源控制 减少master的负载均衡
先安装scala
scala-2.12.17
https://downloads.lightbend.com/scala/2.12.17/scala-2.12.17.tgz
spark 的运行环境是 scala
spark-3.1.3-bin-hadoop3.2
https://dlcdn.apache.org/spark/spark-3.1.3/spark-3.1.3-bin-hadoop3.2.tgz
将安装包放在 /opt/software 目录中

解压安装包到/opt目录下
cd /opt/software
tar -zxvf scala-2* -C /opt
tar -zxvf spark-3* -C /opt
修改环境变量
vim /etc/profile
# # #scala
export SCALA_HOME=/opt/scala-2.12.17
export PATH=$PATH:$SCALA_HOME/bin
# # #spark
export SPARK_HOME=/opt/spark-3.1.3-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin 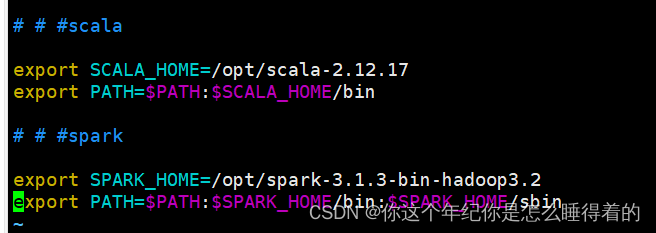
修改配置spark中的配置文件
cd /opt/spark-3.1.3-bin-hadoop3.2/conf
cp spark-defaults.conf.template spark-defaults.conf 修改配置文件
cp workers.template workers 指定workers
cp spark-env.sh.template spark-env.sh 配置环境变量
cp /opt/module/hadoop-3.2.2/etc/hadoop/yarn-site.xml yarn-site.xml 配置yarn框架
cp /opt/module/hadoop-3.2.2/etc/hadoop/hdfs-site.xml hdfs-site.xml 配置hdfs底层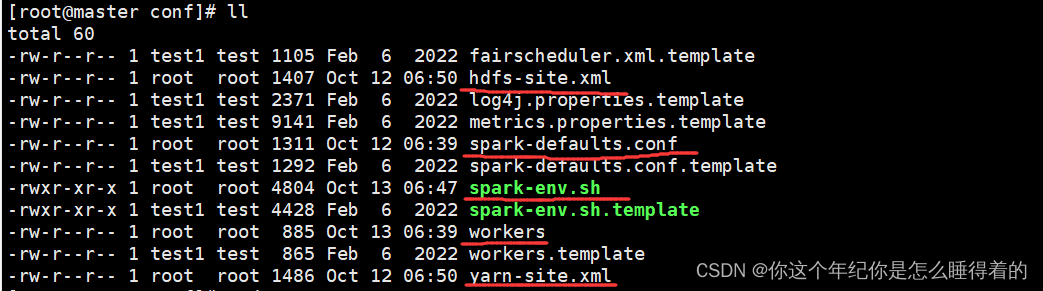
spark-env.sh
vim spark-env.sh
# 指定java环境
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
# 指定 master(资源控制者)
export SPARK_MASTER_HOST=master
# 指定 master的监控端口
export SPARK_MASTER_PORT=7077
# spark改成集群模式
# 指定 hadoop的环境配置文件
export HADOOP_CONF_DIR=/opt/module/hadoop-3.2.2/etc/hadoop
# 指定 yarn框架的配置文件
export YARN_CONF_DIR=/opt/module/hadoop-3.2.2/etc/hadoop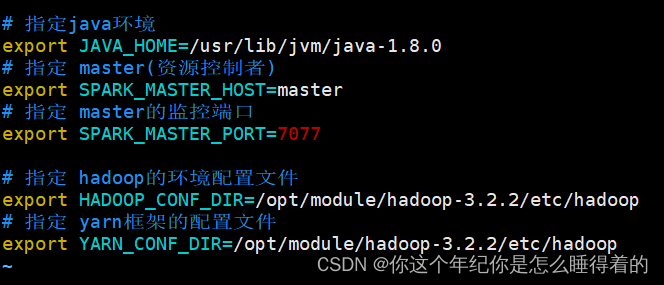
workers
vim workers
slave1
slave2
slave3
slave4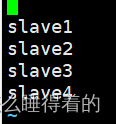
spark-defaults.conf
vim spark-defaults.conf
#使用yarn模式
spark.master yarn
将文件发配给每一个子机
/root/bin/bash/xsync /opt/spark*
/root/bin/bash/xsync /opt/scala*
/root/bin/bash/xsync /etc/profile最后更新环境变量
source /etc/profile开启zk hadoop集群
zkServer.sh start
start-all.sh开启spark中的master与worker节点
start-master.sh
start-workers.sh

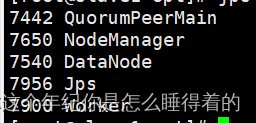
# 进入spark shell命令行
spark-shell 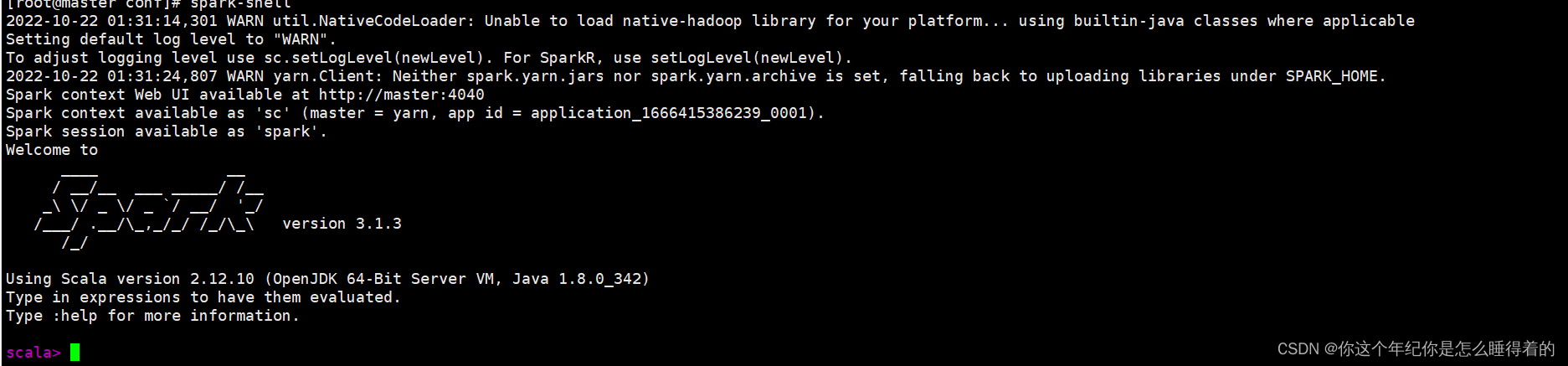
如果上面的命令 不能打开那就
cd /opt/spark-3.1.3-bin-hadoop3.2/sbin
sh start-master.sh
sh start-workers.sh
sh stop-master.sh
sh stop-workers.sh查看监控端口
192.168.88.130:8080
或者是
192.168.88.130:8081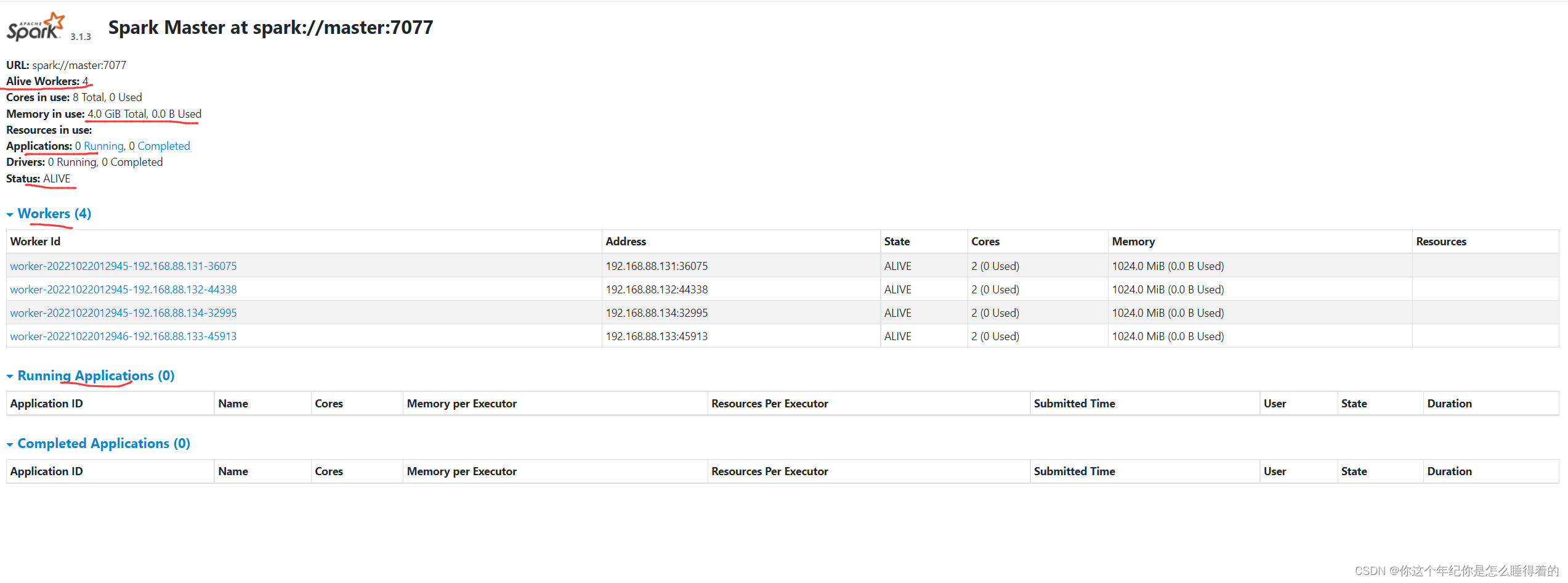
成功
后续更新
















 4614
4614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











