







一.需求分析
根据电商日志文件,分析:
1. 统计页面浏览量(每行记录就是一次浏览)
2. 统计各个省份的浏览量 (需要解析IP)
3. 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city。
二.准备工作
1.启动Hadoop
sbin/start-dfs.sh2.在hdfs上新建输入文件夹和输出文件夹,将原数据放入input文件夹中
hdfs dfs -mkdir -p /trackinfo/input
hdfs dfs -mkdir -p /trackinfo/output
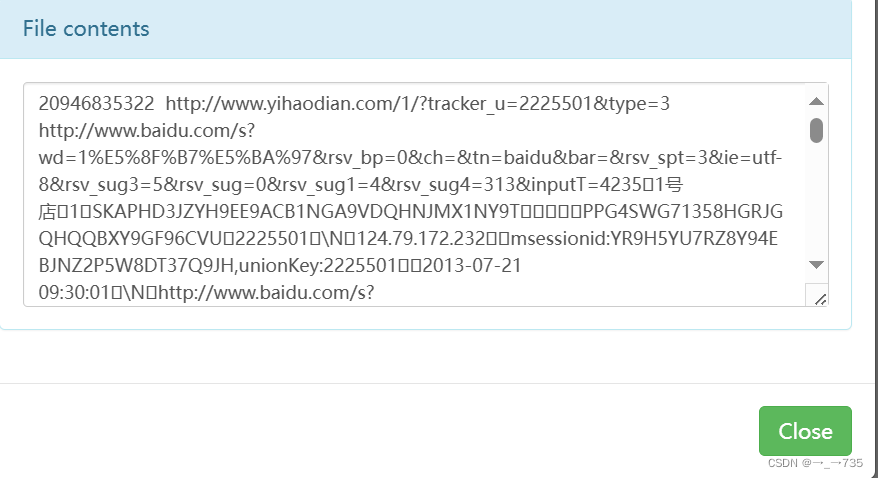
三.第一问(页面浏览量)分析实现
1.Map阶段
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









