






原因:
可能是多次格式化NameNode后未删除相关文件,需要检查在hadoop中查看hdfs-site.xml和core-site.xml配置文件,确认其中的相关配置项是否正确设置,查看目录路径,然后删除相关文件。
解决:
一.查看并删除hdfs-site.xml文件
使用vi查看文件hdfs-site.xml。

可以看到name和data文件的路径。
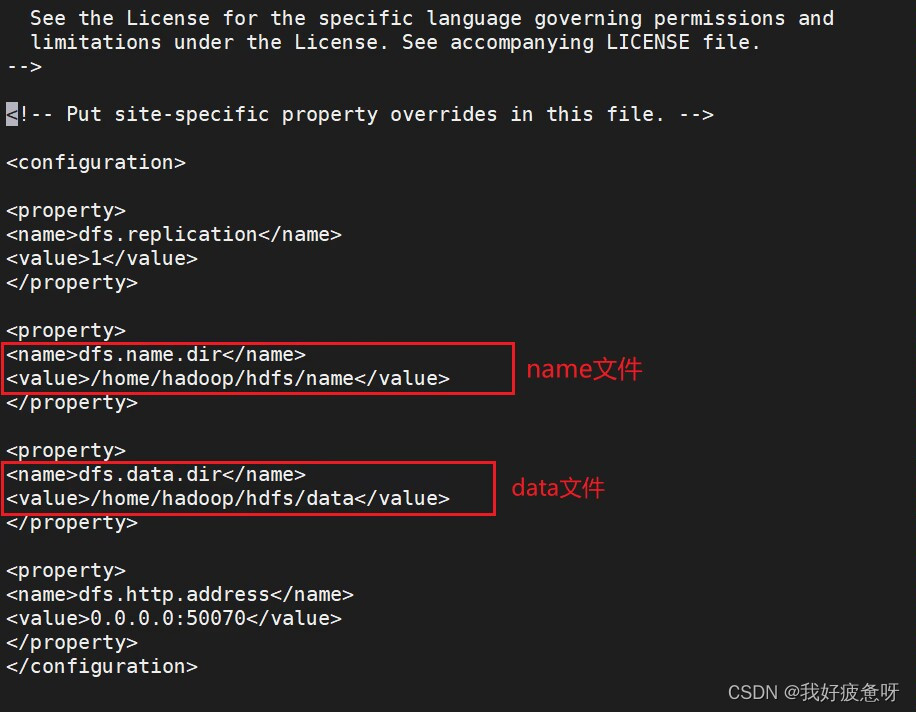
进入该路径可以看到这两个文件,删除name和data文件。
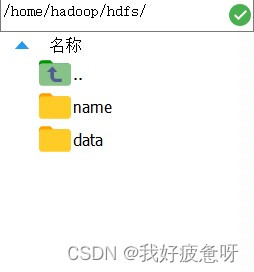
二.查看并删除core-site.xml文件
使用vi查看core-site.xml文件。
可以看到tmp文件的路径。
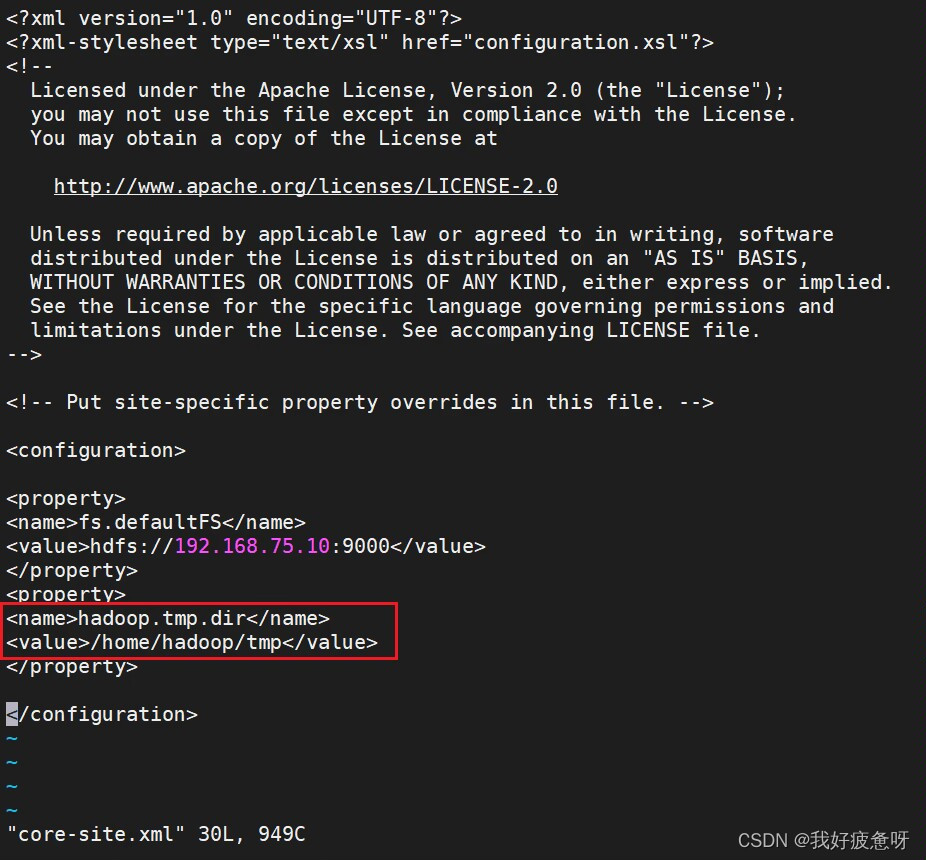
进入该路径可以看到这两个文件,删除nm-local-dir和dfs文件。
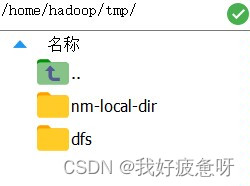
三.格式化和启动
1.初始化
输入hdfs namenode -format重新进行格式化。

2.启动测试
输入start-all.sh启动文件。

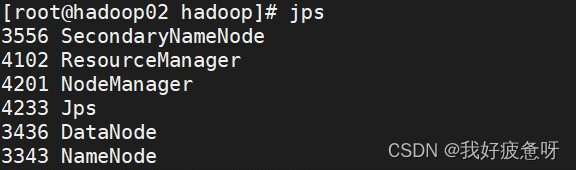
输入jps后可以看到出现namenode和datanode。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









