







文件操作类
ls:列出目录内容的指令
-
ls -a:列出目录中的所有文件,包括以点(.)开头的隐藏文件。 -
ls -l:以长格式列出文件信息,包括文件权限、所有者、大小和最后修改时间。 -
ls -h:与-l选项一起使用,以更易读的格式显示文件大小(例如 KB、MB)。 -
ls -t:按照最后修改时间排序文件和目录。 -
ls -S:按文件大小排序。 -
ls -r:逆序排列文件(与-t或-S结合使用时非常有用)。 -
ls -R:递归地列出所有子目录的内容。
find:在文件系统中基于各种条件搜索文件
find [path...] [options...] [expression]
其中,[path...] 是要搜索的目录路径,默认为当前目录。[options...] 可以指定搜索行为,而 [expression] 用来描述搜索的条件和动作。
-
find . -name filename:在当前目录及子目录中查找名为filename的文件。 -
find /path/to/folder -type f:只查找指定路径下的文件。 -
find /path/to/folder -type d:只查找指定路径下的目录。 -
find . -size +50M:查找当前目录及子目录下大小超过 50MB 的文件。 -
find . -mtime -7:查找在最近 7 天内被修改过的文件。 -
find . -perm 755:查找当前目录及子目录下权限设置为 755 的文件。 -
find . -user username:查找属于指定用户username的文件。 -
find . -exec grep "text" {} \;:对找到的文件执行grep命令,搜索包含 "text" 文本的行。
rm:删除文件或目录
rm [options] file...
这里的 file... 代表一个或多个要删除的文件或目录。
-
-i:交互模式,在删除每个文件之前都会提示用户确认。例如,rm -i filename会在删除文件filename之前询问用户。 -
-f:强制删除,忽略不存在的文件,不提示任何信息。例如,rm -f filename会尝试删除filename,即使它不存在也不会显示错误信息。 -
-r或-R:递归删除,用于删除目录及其内容。例如,rm -r directoryname会删除directoryname及其所有子目录和文件。 -
-v:冗余模式,会输出详细信息,显示rm命令正在执行的操作。例如,rm -v filename在删除文件filename时会显示更多信息。
mv:移动或重命名文件和目录
mv [options] source destination
-
source:源文件或目录的路径,可以是一个或多个。 -
destination:目标路径。如果source是多个文件,则destination必须是一个目录。 -
-i(--interactive):交互式移动。在覆盖目标路径的文件之前,会提示用户确认。 -
-f(--force):强制移动文件或目录,如果目标位置已有同名文件,将不提示用户直接覆盖。 -
-n(--no-clobber):不覆盖已存在的文件或目录(与-f选项相对)。 -
-u(--update):只有当源文件更新于目标文件时才会移动。 -
-v(--verbose):详细模式,展示移动文件和目录时的信息。
例子:
-
mv file1.txt /path/to/destination/:将文件file1.txt移动到指定的目录中。 -
mv file1.txt file2.txt:将file1.txt重命名为file2.txt。 -
mv -i file1.txt /path/to/destination/file1.txt:在覆盖目标位置中的file1.txt之前,会提示用户确认。 -
mv -u oldfile.txt /path/to/destination/:只有当oldfile.txt比目标路径中的同名文件更新时,才会执行移动。
cp:复制文件或目录
cp [options] source destination
-
source:要复制的源文件或目录的路径,可以是一个或多个。 -
destination:目标路径。如果source包含多个文件,则destination必须是一个目录。 -
-i(--interactive):交互模式,在覆盖目标路径的文件之前会提示用户确认。 -
-r或-R(--recursive):递归复制,用于复制目录及其内容。 -
-a(--archive):存档模式,等于-dR --preserve=all,它尽可能复制原始文件的所有属性,包括链接、文件属性,以及复制目录及其内容。 -
-v(--verbose):冗余模式,显示详细的复制进度信息。 -
-f(--force):强制覆盖目标位置已有的文件,而不提示用户。 -
-u(--update):只在源文件比目标文件新,或者目标文件不存在时才复制文件。
例子:
-
cp file1.txt /path/to/destination/:将file1.txt复制到指定的目录中。 -
cp -r /path/to/source_dir /path/to/destination_dir:递归地复制源目录source_dir及其所有内容到目的地destination_dir。 -
cp -i file1.txt /path/to/destination/:复制file1.txt到目标位置前会提示用户确认。 -
cp -vu source_file target_file:在复制source_file到target_file时会显示详细信息,并且只在source_file新于target_file时执行复制。
touch:创建空文件或更改文件时间戳
touch [options] file...
这里的 file... 代表一个或多个文件。
-
-a: 只改变文件的访问时间。 -
-m: 只改变文件的修改时间。 -
-c或--no-create: 如果文件不存在,不创建新的文件。 -
-rfile: 使用参考文件的时间而非当前时间。 -
-t[YYYYMMDDhhmm]: 使用自定义的时间戳而非当前时间。格式为:4位年份(YYYY), 2位月份(MM), 2位日期(DD), 2位小时(hh), 2位分钟(mm)。
举例:
-
touch newfile.txt: 如果newfile.txt不存在,touch将创建一个名为newfile.txt的空文件。如果该文件已存在,命令将更新文件的访问和修改时间戳至当前系统时间。 -
touch -a file.txt: 只更新file.txt的访问时间。 -
touch -m file.txt: 只更新file.txt的修改时间。 -
touch -c nofile.txt: 如果nofile.txt不存在,touch不会创建新文件。 -
touch -t 202203111405 example.txt: 将example.txt的访问和修改时间戳更新为 2022年03月11日的14时05分。
mkdir:创建目录
mkdir [options] directory...
这里的 directory... 代表一个或多个你想要创建的目录。
mkdir 命令中的一些常用选项包括:
-
-p或--parents:允许创建多级目录,如果目录已存在则忽略错误。 -
-m或--mode:设置新目录的权限。需要使用八进制数表达权限,比如755或644等。 -
-v或--verbose:打印一条消息来说明每个被创建的目录。
以下是使用 mkdir 命令的一些示例:
-
mkdir new_directory:创建名为new_directory的新目录。 -
mkdir dir1 dir2 dir3:同时创建三个名为dir1、dir2和dir3的新目录。 -
mkdir -p /path/to/dir:创建dir及其所有未存在的父目录;如果全路径已经存在,不会报错。 -
mkdir -m 755 secure_dir:创建名为secure_dir的目录,设置权限为755(即所有者有全部权限,组用户和其他用户可以读取和执行)。 -
mkdir -pv /path/to/dir/subdir:递归地创建目录,并打印出那些被创建的目录。
rmdir:删除目录
rmdir [options] directory...
这里的 directory... 指的是一个或多个你想要删除的目录路径。
-
-p或--parents:递归删除目录,即当子目录被删除后,如果其父目录变为空,则也一并删除,直到某一个目录非空或者达到根目录。 -
--ignore-fail-on-non-empty:即使某些目录非空也不显示错误消息。
示例:
-
rmdir empty_directory:删除名为empty_directory的空目录。 -
rmdir dir1 dir2 dir3:尝试删除dir1、dir2和dir3这三个目录,它们都必须是空的。 -
rmdir -p path/to/empty_directory:如果empty_directory是空的,那么它将被删除,并且如果path/to变为空的话,也会一并删除。
chmod:修改文件权限/chown:修改文件所有者和所属组


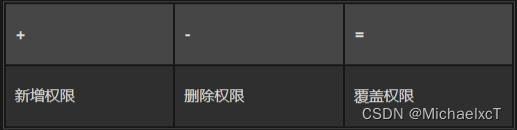
chmod

chmod(change mode)命令用于更改文件或目录的权限。它可以使用符号表示法(如 u、g、o、a 表示用户、用户组、其他用户和所有用户)或八进制数表示法(如 755、644)来设置权限。
示例:
-
chmod u+x file: 给文件所有者添加执行权限。 -
chmod 755 file: 设置文件的权限为所有者读写执行,用户组和其他用户读执行。
chown
chown(change owner)命令用于更改文件或目录的所有者和/或组。它通常需要超级用户权限来执行。
示例:
-
chown user file: 更改文件的所有者为 user。 -
chown user:group file: 同时更改文件的所有者为 user,和用户组为 group。 -
chown -R user:group directory: 递归地更改目录及其内部所有文件和子目录的所有者和组。
chgrp
语法:chgrp [OPTION] GROUP FILE

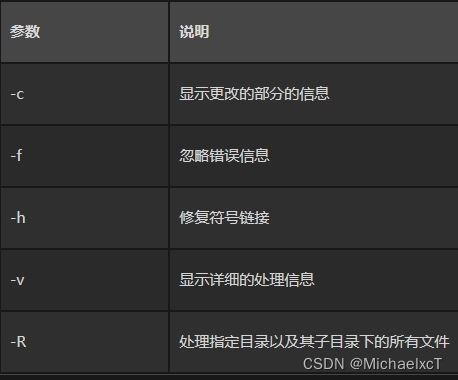
diff:比较两个文件之间的差异
diff [options] file1 file2
这里的 file1 和 file2 是欲比较的两个文件。diff 命令会显示出所有必要的更改,以便从 file1 修改得到 file2。
一些常用的 diff 选项包括:
-
-c: 生成包含修改内容差异以及周围具体行的统一上下文格式。 -
-u: 输出以统一格式显示的差异,通常用于创建补丁文件。 -
-i: 在比较时忽略大小写。 -
-b: 在比较时忽略行尾连续空格的变化。 -
-w: 完全忽略空格字符。 -
-r: 递归地比较目录下的所有文件。 -
-q: 报告文件是不是不同,不细述差异。 -
-B: 忽略空白行的变化。
dd:复制文件和数据流
dd if=输入文件 of=输出文件 [选项]
其中,if 表示输入文件(input file),而 of 表示输出文件(output file)。如果不指定 if,dd 默认使用标准输入;如果不指定 of,dd 默认使用标准输出。
一些常见的含义和 dd 命令中常用的参数选项包括:
-
bs: 块大小,dd一次读写的数据量。 -
count: 复制的块的数量。 -
skip: 输入文件中跳过的块数。 -
seek: 输出时跳过的块数。 -
conv: 数据转换选项,如notrunc(不截短输出文件)、sync(填充每个输入块以输入块大小)、noerror(在发生错误时继续处理)。
示例:
-
dd if=/dev/sda of=/dev/sdb bs=4096: 将 /dev/sda 设备的内容复制到 /dev/sdb 设备,块大小为 4096 字节。 -
dd if=/dev/zero of=/dev/sda bs=1M count=10: 向 /dev/sda 设备写入 10M 的零。 -
dd if=/path/to/file.iso of=/dev/sdb bs=4M && sync: 将 ISO 镜像文件写入到 USB 设备 /dev/sdb,写入完成后执行 sync,确保所有缓存的数据都被写入。
系统信息类
ps:显示进程状态
ps
-
-e或-A: 显示所有进程。 -
-f: 显示完整格式的信息。 -
-u [username]: 仅显示指定用户的进程。 -
-p [PID]: 仅显示指定PID的进程信息。 -
-o: 自定义输出的列。 -
-l: 长格式输出。
例如,如果你想看到所有进程的全列表,可以用下面的命令:
ps -e
或者,如果你想查看某个特定用户的所有进程:
ps -u username
ps 命令的输出通常包括PID(进程号)、TTY(终端类型)、TIME(CPU时间)和CMD(运行的命令)。
top:显示系统中的活动进程
top 命令是 Unix 和类 Unix 系统上的一个实用工具,它提供了一个实时更新的查看系统中正在运行的进程的界面。它显示的信息包括进程的统计信息、系统运行时间、CPU和内存使用率等。
top [选项]
当你在终端执行 top 命令时,它会开启一个交互式的界面,你可以在这个界面中执行命令以控制显示的输出或修改显示的行为。
一些常见的 top 界面操作包括:
-
按
q退出top。 -
按
M按内存使用率排序。 -
按
P按CPU使用率排序。 -
按
T按累计时间排序。 -
按
h或?显示帮助菜单。
此外,top 也有命令行选项可以在启动时定制它的行为:
-
-d:指定刷新延迟间隔。 -
-n:指定top更新的次数,之后将退出。 -
-u:仅显示指定用户的进程。 -
-p:仅监视指定PID的进程。
top 命令的输出头部通常显示系统信息,比如当前时间、系统运行时间、用户数量,以及系统负载。下面的部分是进程的列表,包含了PID、用户、优先级、CPU占用率和内存占用率等信息。
df:显示磁盘空间使用情况
df 是 Unix 和类 Unix 系统中的一个命令行工具,用于显示文件系统的磁盘空间使用情况。它会列出文件系统的总空间、已使用空间、可用空间以及挂载点信息。这个工具非常有用,用来快速查看硬盘的空间分布和哪些分区的使用接近其容量限制。
df [选项] [文件]
不带任何参数运行 df,将会列出所有已挂载文件系统的磁盘使用情况。
可以用的一些常用选项包括:
-
-h或--human-readable:以可读的格式(如 KB、MB、GB)显示大小。 -
-T:显示文件系统类型。 -
--total:在输出的最后一行显示总计。 -
-i:显示inode信息,而不是块使用信息。
在Linux和其他类Unix系统中,inode(索引节点)是一个非常重要的概念,用于描述文件系统中的文件的元数据。每个文件和目录在文件系统中都有一个与之对应的inode,它包含了关于文件的大多数信息,除了文件名和实际数据内容之外。
一个inode通常包含以下信息:
-
文件类型:这说明了对象是普通文件、目录、字符设备、块设备、管道、链接还是套接字。
-
权限:这表示文件的访问控制信息,包括所有者、组以及其他用户的读、写和执行权限。
-
所有者和组:文件的用户ID(UID)和组ID(GID)。
-
文件大小:文件的字节大小。
-
时间戳:包含文件的创建时间、最后修改时间和最后访问时间。
-
链接计数:链接到文件的硬链接数。当这个数降至0时,该文件将被删除。
-
数据块指针:文件系统中实际数据的位置。inode会指向这些数据块。
-
扩展属性:如访问控制列表(ACL)等额外设置。
文件在文件系统中通过名称引用,而文件名本身是存储在目录的数据部分中的。目录文件将文件名映射到inode号。此外,inode没有包含文件名的信息是因为一个文件可以有多个名称(即硬链接)。所有这些名称都映射到同一个inode号。
在文件系统中,有一个特定区域是专门用于存储inode的,称为inode表。通过inode号可以索引到inode表中的具体inode项。
-
-a:显示所有文件系统的信息,包括通常不显示的文件系统。
例如,要以人类可读的形式查看磁盘空间使用情况,可以运行:
df -h
这将会以 GB、MB 等单位显示每个挂载点的磁盘空间使用情况,而不是以默认的512字节块显示。
df 命令的输出通常包括以下列:
-
文件系统(Filesystem):文件系统的名称,通常是设备名。
-
块(1K-块、大小):文件系统的大小。
-
已用(Used):已使用的磁盘空间。
-
可用(Avail):还剩多少空间可用。
-
已用%(Use%):已使用的白分比。
-
挂载点(Mounted on):文件系统挂载的目录。
du:显示目录或文件的磁盘使用情况
du(disk usage)是 Unix 和类 Unix 系统上用于计算文件和目录所占磁盘空间大小的命令行工具。它可以帮助用户理解哪些文件和目录在消耗磁盘空间,并常用于磁盘空间的管理和分析。
du [选项] [文件或目录...]
如果不带任何参数,du 会从当前目录开始,递归地为每个子目录显示磁盘使用情况。
常见的 du 选项包括:
-
-h或--human-readable:以可读的格式(KB、MB、GB)显示大小。 -
-s或--summarize:仅显示总计(仅对指定目录)。 -
-a或--all:显示所有个别文件的磁盘使用情况,而不仅仅是目录。 -
--max-depth=N:显示N级子目录的信息。
例如,你可以使用以下命令来获取当前目录中每个子目录的磁盘使用情况的汇总,并以易读的格式显示:
du -sh *
这个命令会列出当前目录下每个文件和子目录的大小,但不会列出它们子目录的内容。输出以可读的形式显示(例如 MB、GB)。
另一个示例,如果你只想看到当前目录总使用空间:
du -sh
uname:显示系统信息
uname 是在Unix及类Unix的操作系统中用来打印系统信息的一个命令行工具。执行这个命令可以返回一些基本的系统信息,比如操作系统的名字、版本以及硬件信息等。
不带任何参数地执行 uname 将返回内核名称。通过添加不同的选项,你可以获取更多的系统信息:
uname [选项]
以下是一些常用的 uname 选项:
-
-a或--all:打印所有可用的系统信息。 -
-r:打印内核发布版本号。 -
-s:打印内核名称,这也是默认行为。 -
-n:打印网络节点(主机)名称。 -
-v:打印内核版本。 -
-m:打印机器硬件名称(例如,x86_64、i686)。 -
-o:打印操作系统(这个选项在某些系统中可能不可用)。 -
-p:打印处理器类型(在某些系统上可能不提供)。 -
-i:打印硬件平台(在某些系统上可能不提供)。
例如,如果要获取内核版本和硬件架构,则可以使用以下命令:
uname -rm
uptime:显示系统运行时间和负载平均值
uptime 是 Unix 和类 Unix 系统中的一个常用命令,它用来查看系统已经运行了多长时间。命令的输出不仅包括系统的持续运行时间,还包括当前登录的用户数量以及系统在过去一段时间内的平均负载。
uptime [选项]
通常不需要任何选项,直接输入 uptime 并回车即可得到系统运行时间的信息。输出通常如下所示:
14:08:36 up 10 days, 3:44, 1 user, load average: 0.01, 0.03, 0.05
这其中:
-
第一部分 (
14:08:36) 表示当前的系统时间。 -
up 10 days, 3:44表示系统已连续运行了10天又3小时44分钟。 -
1 user表示当前有1个用户登录到系统。 -
最后的三个数字 (
load average: 0.01, 0.03, 0.05) 是系统1分钟、5分钟和15分钟的平均负载,这些指标有助于衡量系统的活动水平。
系统的平均负载是指在特定时间内运行队列中等待CPU的平均进程数。如果这个数大于CPU的核数,就可能意味着系统处于负载过高的状态。
free:显示系统内存使用情况
free 命令是在 Unix 和类 Unix 系统中,用于显示系统中空闲和被使用的物理内存及交换内存的工具,同时还可以显示被内核缓冲的内存量。这个命令允许用户迅速地获取关于系统内存使用情况的快照,对于监控和管理内存资源非常有用。
free [选项]
执行时,它会显示几行数据,其中包含了内存和交换分区(swap)的使用情况。
以下是一些常见的 free 命令选项:
-
-b:以字节为单位显示内存使用量。 -
-k:以千字节为单位显示内存使用量(默认)。 -
-m:以兆字节为单位显示内存使用量。 -
-g:以吉字节为单位显示内存使用量。 -
-h:以易读的格式显示内存使用量(例如,自动选用 M、G 来表示兆、吉字节)。 -
-t:添加一行显示物理内存和交换内存的总量。 -
-s N:持续显示内存使用情况,每 N 秒更新一次。
示例:
free -h
这将输出类似于下面的信息:
total used free shared buff/cache available Mem: 7.7Gi 1.5Gi 4.3Gi 125Mi 1.9Gi 5.9Gi Swap: 2.0Gi 0.0Ki 2.0Gi
在这个示例中,“total”列表示总内存,“used”表示已使用内存,“free”表示可用内存,“shared”表示多个进程共享的内存,“buff/cache”表示被系统缓冲或者用作缓存的内存量,“available”表示可以给应用程序使用的内存(不包括已交换出去的内存)。
iostat:显示系统的 CPU 使用情况和设备的 I/O 统计信息。
iostat 是 Unix 和 Linux 系统中用于监视系统输入/输出设备和 CPU 使用情况的命令行工具。该命令可以用来收集并显示系统的 CPU 统计信息,以及所有块设备(硬盘、CD-ROM 等)和分区的 I/O 统计信息。
iostat [选项] [间隔 [次数]]
其中,“间隔”是两次报告之间的时间(以秒为单位),“次数”是生成报告的次数。如果不带任何参数,iostat 会显示从系统启动以来的摘要统计信息。
以下是一些常见的 iostat 命令选项:
-
-c:显示 CPU 使用率信息。 -
-d:显示磁盘 I/O 统计信息。 -
-x:显示扩展的磁盘 I/O 统计信息。 -
-m:输出结果以兆字节(MB)为单位。 -
-t:在输出中包含时间戳信息。
一个常见用例可能是监控 CPU 和磁盘使用情况,以每隔2秒报告一次,并且总共报告5次:
iostat -cdxt 2 5
这个命令会显示 CPU 的使用状况和所有磁盘的详细 I/O 性能数据,包括读写速率、读写次数等,以方便分析性能问题或正常的性能监控。
vmstat:显示系统的虚拟内存统计信息
vmstat(virtual memory statistics 的缩写)是一个在 Unix、Linux 和其他类 Unix 系统中常用的性能监控工具,它用于显示有关系统的虚拟内存、进程、CPU 活动等的信息。
vmstat [选项] [间隔 [次数]]
-
选项允许您自定义输出,例如-a包含活动/非活动内存信息,-s显示内存统计等。 -
间隔是指更新频率,即每隔多少秒收集一次数据。 -
次数是指收集数据的总轮数。
没有任何参数运行 vmstat 时,它通常会显示自系统启动以来的平均值。如果指定了 间隔 和 次数,它会以指定的时间间隔更新信息,显示指定的次数。
vmstat 输出的示例和解释:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 104700 88236 198144 0 0 92 65 123 234 3 1 96 0 0
-
procs:显示进程统计(r= 等待运行的进程数,b= 阻塞的进程数) -
memory:有关系统内存的使用情况(swpd= 使用的交换空间,free= 空闲的内存,buff= 用作缓冲的内存,cache= 用作缓存的内存) -
swap:交换空间的使用情况(si= 从交换空间读取的内存,so= 写入交换空间的内存) -
io:输入/输出统计(bi= 块设备接收的块,bo= 发送的块) -
system:系统相关的事件(in= 每秒中断数,cs= 每秒上下文切换数) -
cpu:CPU 的使用情况(us= 用户态时间,sy= 系统态时间,id= 空闲时间,wa= I/O 等待时间,st= 被偷走的时间)
iftop:实时监视网络流量
iftop 是 Linux 和类 Unix 系统中一个实用的监控工具,主要用于显示网络接口的实时带宽使用情况。它提供了一个实时更新的界面,显示了网络上的流量统计信息,包括各个连接的源地址、目的地址、传输速率等。
iftop
这将默认监控第一个网络接口的流量。如果您想指定某个特定的网络接口,可以使用 -i 选项:
iftop -i eth0
这里 eth0 是需要监视的网络接口名称,可以根据实际情况替换。
iftop 显示的输出分为几列,通常包括:
-
源主机名/地址
-
目标主机名/地址
-
两条线之间的数据流量(上传和下载)
它还包括一些有用的特性和选项,例如:
-
-b:不显示栏位栏 (bar graph) 的输出。 -
-n:不要尝试解析主机名。 -
-p:以预设模式运行;不转入混合模式。 -
-B:以位元、千位元、兆位元等单位显示带宽。
last:显示指定用户或者所有用户的登录记录
last 是一个在 Linux 和 Unix 系统中使用的命令,它用于显示系统中用户登录和注销的信息。该命令会读取 wtmp 文件(通常位于 /var/log/wtmp),该文件记录了每个用户登录和注销的历史记录。
username tty1 :0 Fri Mar 11 16:42 still logged in username pts/0 192.168.1.2 Fri Mar 11 16:39 still logged in ...
-
username是登录系统的用户名称。 -
tty1,pts/0等是用户登录的终端设备。 -
192.168.1.2是用户登录时所在的主机地址。 -
最后一列是登录时间和注销时间(或者显示为“still logged in”如果用户目前还登录着)。
除了默认的显示方式,last 命令还有一些常用选项:
-
-f指定其他的文件来代替默认的wtmp文件。 -
-n指定要显示的记录行数。 -
-a在最后一列显示主机名。 -
-d对于不可识别的主机和用户显示 IP 地址。 -
-R不显示主机名字段。
例如,如果我们只想看最近10条记录,可以执行以下命令:
last -n 10
history:显示用户执行过的命令历史记录
history 是一个在 Linux 和其他 Unix 类系统的 shell 环境中使用的命令,它用来显示当前用户在当前终端会话中执行过的命令的列表。这个命令对于快速找回和重用先前输入的命令特别有用。
history
输出将会是命令的列表,每个命令前都有一个编号:
501 ls -l 502 cd /var/www 503 nano index.html 504 gcc -o myapp main.c ...
你可以结合使用行号和 ! 符号来快速执行历史中的命令。例如,输入 !502 将会执行列表中第 502 个命令。类似地,输入 !! 将会执行上一个命令。
history 命令也有一些常用的选项,例如:
-
-c清空整个历史记录。 -
-d offset删除历史列表中位置为 offset 的一条命令。 -
history n显示最近的 n 条命令。
此外,你还可以利用 grep 来搜索特定命令。以下是一个搜索使用 cd 命令的例子:
history | grep cd
历史命令记录存储在用户的家目录下一个名为 .bash_history(对于 Bash shell)的隐藏文件中,所以即便是退出当前终端会话后再次登录,这些历史命令记录依然可以被访问。
lsblk:列出所有可用块设备的命令
lsblk 是 Linux 系统中用于列出所有可用块设备的命令。它可以显示设备相关的信息,比如分区、挂载点、分区类型以及磁盘大小等。lsblk 命令不仅适用于硬盘驱动器,还适用于其他类型的块设备,如 USB 驱动器、RAM 磁盘和其它存储设备。
lsblk [options] [device]
-
[options]:是可选参数来修改lsblk的行为。 -
[device]:指定特定的块设备。
lsblk 输出的参数涵义:
-
NAME:设备或分区的名称。 -
MAJ:MIN:主要(MAJ)和次要(MIN)设备号。这对于内核识别设备和分区是必要的。 -
RM:移除设备标记。值为1表示可移除设备(即 USB 驱动器),0表示非可移除设备。 -
SIZE:设备或分区的大小。 -
RO:只读设备标记。值为1表示只读,0表示可读写。 -
TYPE:设备类型。常见的类型包括disk(磁盘),part(分区),lvm(LVM 逻辑卷),等等。 -
MOUNTPOINT:设备或分区的挂载点。如果设备或分区已挂载,则会显示挂载点路径,否则此处为空。
运用 lsblk 的一些常用选项:
-
-f:显示文件系统类型以及挂载点。 -
-l:使用列表格式显示信息,而不是默认的树状图。 -
-o:指定输出列,例如-o NAME,SIZE只显示设备名和大小。 -
-m:显示权限和所有者信息。
例如:
lsblk -f
这个命令会显示所有设备的名称、文件系统类型、标签、挂载点等详细信息。
文本处理类
grep:搜索文本
grep 是一款强大的文本搜索工具,允许你在文件或由其他命令产生的输出中搜索包含特定模式的字符串。在 Linux 和其他类 Unix 系统中,grep 是常用的文本处理工具。
grep 'pattern' filename
这条命令会在指定的文件 filename 中搜索字符串 pattern,并输出包含该模式的所有行。
除了基本搜索,grep 还有很多有用的选项:
-
-i:忽略大小写。 -
-v:反转匹配,即只显示不匹配模式的行。 -
-c:计数,只输出匹配模式的行数。 -
-n:输出匹配行及其行号。 -
-R或-r:递归搜索,在指定目录下的所有文件中查找匹配的字符串。 -
-l:只输出包含匹配字符串的文件名。 -
-o:只输出匹配到的部分,而不是整行内容。
例如,要在当前目录下所有 .txt 文件中递归搜索忽略大小写的 hello 字符串,你可以使用:
grep -Ri 'hello' *.txt
还可以将 grep 和其他命令配合使用,例如通过管道与 ps 命令配合,来搜索特定的进程:
ps aux | grep 'httpd'
这条命令会搜索所有包含 httpd 的进程信息。
grep 的强大之处在于它支持正则表达式,这让它可以执行复杂的文本匹配和搜索操作。使用正则表达式时,你应当使用 egrep 或 grep -E。
sed:流编辑器,用于文本替换和处理
sed(stream editor)是一个非常强大的流式文本编辑器,允许你对来自文件或管道的文本进行过滤和转换。在 Linux 和 Unix 系统中,sed 被广泛用于快速编辑文件中的文本,执行基本的文本替换,以及作为其他命令输出的处理器。
sed 's/old_pattern/new_pattern/' filename
这个命令将会把文件 filename 中所有的 old_pattern 替换成 new_pattern 并且输出到标准输出(屏幕)。默认情况下,sed 输出替换结果,而不改变原始文件。
sed 的一些常用选项包括:
-
-i:直接编辑文件,即原地修改文件内容而不是输出到标准输出。 -
-e:允许多个编辑命令;可以在处理时应用多条sed命令。 -
-n:默认情况下,sed会打印出所有的处理过的行,通过-n选项可以只打印那些被模式匹配到的行。
要在文件中每次仅替换第一次出现的匹配模式,你可以使用:
sed 's/old_pattern/new_pattern/' filename
若要替换所有出现的匹配模式,你需要添加全局替换标志 g:
sed 's/old_pattern/new_pattern/g' filename
此外,如果你想要删除文件中的某些行,你可以这么做:
sed '/pattern_to_match/d' filename
上面的命令会删除所有包含 pattern_to_match 的行。
sed 支持正则表达式,使其成为修改复杂文本模式的强大工具。由于它的高效和表达强度,它被广泛应用在脚本中进行自动化文本处理。
awk:文本处理工具,用于分析和处理文本数据
awk 是一个非常强大的文本处理命令,主要用于数据提取和报告生成。awk 程序的行为由指定的 pattern {action} 对构成,在每行上匹配 pattern 后执行 {action}。如果省略 pattern,则 {action} 将应用于所有行。awk 非常擅长处理字段分隔数据,如 CSV 或空格分隔的文本。
FS:列分隔符。指定每行文本的字段分隔符,默认为空格或制表位,与“ -F ”作用相同 OFS:输出分隔符。指定输出字段间的分隔符。 RS:行分隔符。awk从文件读取资料时,将根据RS的定义把资料切割为多条记录, awk一次仅读取一条记录,以进行处理,预设值为 \n (换行符) NF:当前处理行的字段个数 NR:当前处理行的行号 FNR:awk当前读取的记录数,其变量值小于等于NR (比如当读取第二个文件时,FNR是从0开始重新计数,而NR不会)。 NR==FNR:用于在读取两个或两个以上的文件时,判断是不是在读取第一个文件 $0:当前处理行的整行内容 $n:当前处理行的第 n 个字段(第 n 列) FILENAME:被处理的文件名
打印出文件 filename 的所有内容。
awk '{print}' a.txt
或
awk '{print $0 }' a.txt
1.按行输出文本
输出指定行号的内容
#打印1-3行的行内容
awk 'NR==1,NR==3{print $0}' a.txt
#打印1-3行的行内容,&&表示“与”
awk '(NR>=1)&&(NR<=3){print $0}' a.txt
#打印行号小于4的行内容,!表示取反
awk '!(NR>4){print $0}' a.txt
输出奇偶行内容
#输出奇数行,行号取余=1为奇数行
awk '(NR%2)==1{print $0}' a.txt
#输出偶数行
awk '(NR%2)==0{print $0}' a.txt
输出匹配行的行内容
#输出以 n 开头的行内容
awk '/^n/{print $0}' a.txt
#输出以 e 结尾的行内容
awk '/e$/{print $0}' a.txt
2.按字段输出文本
输出指定字段
# -F 指定分隔符;$1 所在行以分隔符分隔的第一个字段
awk -F ":" '{print $1}' a.txt
# $NF 表示所在行最后一个字段,NR 表示当前行的行号
awk -F ":" '{print NR,$NF }' a.txt
输出结果指定分隔符
#输出第1和第3个字段,输出结果默认以 空格 分隔
awk -F ":" '{print $1,$3 }' a.txt
awk -F ":" '{print $1","$3 }' a.txt
awk -F ":" '{print $1"=="$3 }' a.txt
OFS指定输出结果分隔符
echo 'A B C D' | awk '{OFS=":";print $0}'
A B C D
# $1=$1 用来激活$0的重新赋值,通常是在改变OFS后而需要输出$0时这样做
echo 'A B C D' | awk '{OFS=":";$1=$1;print $0}'
A:B:C:D
输出匹配字段的行内容
[root@michaelxct etc] cat passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
nginx:x:997:995:Nginx web server:/var/lib/nginx:/sbin/nologin
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
saslauth:x:996:76:Saslauthd user:/run/saslauthd:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
elk:x:1000:1000::/home/elk:/bin/bash
apm-server:x:995:994:apm-server:/var/lib/apm-server:/bin/bash
ftpuser:x:1001:50::/data/ftp/ftpuser:/usr/bin/nologin
#输出第3字段大于50的行的第1和第3字段
awk -F ":" '$3>50{print $1,$3}' passwd
nobody 99
systemd-network 192
dbus 81
polkitd 999
tss 59
sshd 74
postfix 89
chrony 998
nginx 997
saslauth 996
elk 1000
apm-server 995
ftpuser 1001
#输出第7字段中包含/bash的行内容
awk -F ":" '$7~"/bash"{print $0}' passwd
root:x:0:0:root:/root:/bin/bash
elk:x:1000:1000::/home/elk:/bin/bash
apm-server:x:995:994:apm-server:/var/lib/apm-server:/bin/bash
3.三元运算符
条件表达式?值1:值2
若条件表达式成立,则取值1;反之,取值2。
awk -F ":" '{print $3,$4}' passwd
0 0
1 1
2 2
3 4
4 7
5 0
6 0
7 0
8 12
11 0
12 100
14 50
99 99
192 192
81 81
999 998
59 59
74 74
89 89
998 996
997 995
27 27
48 48
996 76
38 38
1000 1000
995 994
1001 50
#三元运算符,如果第3个字段的值大于等于第4个字段的值,则把第3个字段的值赋给max,
#否则第4个字段的值赋给max
awk -F ":" '{max=($3>=$4)?$3:$4;{print max}}' passwd
0
1
2
4
7
5
6
7
12
11
100
50
99
192
81
999
59
74
89
998
997
27
48
996
38
1000
995
1001
4.通过管道符、双引号调用shell命令
统计行数
awk -F ":" '/bash$/{print}' passwd
root:x:0:0:root:/root:/bin/bash
elk:x:1000:1000::/home/elk:/bin/bash
apm-server:x:995:994:apm-server:/var/lib/apm-server:/bin/bash
#调用 wc -l 统计使用bash的行数
awk -F ":" '/bash$/{print|"wc -l"}' passwd
3
查看当前内存使用百分比
#查看当前内存使用百分比
free -m | awk '/Mem:/{print int($3/($3+$4)*100)"%"}'
19%
下面是命令各部分的详细解释:
-
free -m:free命令用于显示系统内存的统计信息。-m选项意味着所有的数值以兆字节(MB)为单位。
total used free shared buff/cache available Mem: 3770 451 1817 208 1501 2872 Swap: 0 0 0
-
|:这个符号是管道,它的作用是将前一个命令的输出作为下一个命令的输入。 -
awk '/Mem:/{print int($3/($3+$4)*100)"%"}:awk是一个功能强大的文本分析工具。这里它用于处理free -m命令的输出。-
/Mem:/:这部分告诉awk只对包含 "Mem:" 的行进行操作。 -
$3和$4:在awk中,这些表示输入行的第三和第四个字段。对于free -m命令的输出,这通常分别是 "used" (已使用内存)和 "free" (空闲内存)的值。 -
int($3/($3+$4)*100):这个表达式计算已使用内存与总内存(已使用内存加空闲内存)的比例,然后乘以 100,得到使用的百分比。int函数将结果转换为整数。 -
"%":在awk输出中追加一个百分号,使得输出的结果更为直观。
-
awk 的一些常用功能包括:
-
字段替换和重新格式化输出
-
数据汇总和计算
-
文本分析和处理
具体的 awk 选项和用法非常多,这里是一些常用的例子:
-
-F:用来定义字段分隔符,如-F:表示使用冒号作为字段分隔符。 -
BEGIN和END:BEGIN在处理任何文本行之前执行一次,而END在处理完所有文本行之后执行一次。 -
NR和NF:NR保存当前的记录数(通常是当前行号),NF存储当前行的字段数。
cut:提取文本中的字段
cut 命令在 Unix 和类 Unix 系统中用于文本处理,主要用来从文件或文本流中提取文本列。它通过按列切割数据来显示每行中的指定部分,通常用于提取表格数据或某些固定格式文本的某些字段。cut 可以根据字节(byte)、字符(character)或字段(field)分隔符来进行切分。
-
通过字节位置提取文本:
cut -b 1-10 filename
这个命令会提取每行的第 1 到第 10 个字节。
-
通过字符位置提取文本:
cut -c 1-10 filename
这个命令会提取每行的第 1 到第 10 个字符。
-
通过字段提取文本:
cut -f 1,3 -d ',' filename
这个命令会使用逗号作为字段分隔符,并提取每行的第 1 和第 3 个字段。
关键选项:
-
-b:按字节切割。 -
-c:按字符切割。 -
-f:选择字段,字段通常是由-d指定的分隔符隔开的文本列。 -
-d:指定字段分隔符,默认是制表符(tab)。
例如,如果你有一个 CSV 文件,每行中的值由逗号分隔,并且你只想提取第二列,你可以使用以下命令:
cut -f 2 -d ',' filename.csv
sort:对文本进行排序
sort 命令在 Unix 和类 Unix 系统中用于对文本文件的内容进行排序。它可以按照文本,数值或者其他排序标准对文本文件中的行进行排序,非常适合处理大量数据。
sort filename
这将以升序对文件 filename 中的行进行字典排序,并将结果输出至标准输出。
sort 命令的常见选项:
-
-n:根据行内的数值进行排序。 -
-r:以降序进行排序。 -
-b:以升序进行排序。 -
-k:指定排序时所用的键(字段)。 -
-t:指定字段分隔符。 -
-u:删除排序结果中的重复行。
例如,如果要按数值排序:
sort -n filename
如果要基于文件中的第二列进行排序,并且字段以逗号分隔,可以使用:
sort -t, -k 2,2 filename
这个命令使用逗号作为字段分隔符,并且以第二个字段为键来进行排序。
要进行降序排序,可以结合使用 -r 选项:
sort -r filename
要进行复合排序,即先按第一个键排序,如果相同则按第二个键排序,可以:
sort -k 1,1 -k 2,2 filename
此外,sort 还有很多其他选项可以进行更复杂的排序,如稳定排序(-s)、忽略大小写(-f)等。
uniq:删除重复行
uniq 命令在 Unix 和类 Unix 操作系统中用于报告或过滤文本文件中重复的行。它常常与 sort 命令一起使用,因为 uniq 要求重复的行必须是连续的。如果你想从文件中删除重复的行,首先通常需要使用 sort 对文件进行排序,然后再用 uniq 过滤重复内容。
uniq filename
这个命令读取 filename 文件,然后输出去除了重复连绀行后的内容。
uniq 命令还有一些常用选项:
-
-c:显示每行在文件中出现的次数。 -
-d:仅显示重复过的行。 -
-u:仅显示未曾重复的行。
当你想知道每行重复的次数时,可以使用:
uniq -c filename
如果你只想看到至少重复一次的行,可以使用:
uniq -d filename
对于只打印出文件中的唯一行,可以使用 -u 选项:
uniq -u filename
uniq 命令通常与 sort 结合使用来获得更多的实际效果。例如,要对文件进行排序并删除重复行的标准操作是:
sort filename | uniq
这将首先对 filename 进行排序,使得所有的重复行都是连续的,然后 uniq 默认过滤掉重复行。
uniq 命令是文本处理中重要的工具之一,特别是用于处理那些只需要简单快速移除或计数重复行的场景。
wc:统计文件中的行数、字数和字符数
wc(word count)命令在 Unix 和类 Unix 操作系统中用于计算文本文件中的行数、单词数以及字节(或字符)数。这个命令在文本分析和统计工作中非常有用,尤其是在需要快速了解文件内容大致情况时。
wc filename
执行这个命令,它会返回三个数字:首先是文件中的行数,然后是单词数,最后是字节数。
wc 也可以使用标准输入,通过管道操作符与其他命令结合使用。例如,你可以使用 grep 搜索文件,并统计匹配行的数量:
grep 'pattern' filename | wc -l
在这个例子中,wc -l 命令只会计算行数,忽略单词数和字节数。
wc 的其它一些常用选项包括:
-
-l:只计算行数。 -
-w:只计算单词数。 -
-c:只计算字节数。 -
-m:只计算字符数。
例如,如果只想知道文件中的字符数,你可以使用:
wc -m filename
若有多个文件,wc 还会提供每个文件的统计数和一个总计数。例如:
wc filename1 filename2
以上命令将分别显示 filename1 和 filename2 的行数、单词数、字节数,以及所有文件的总计。
wc 命令因其功能简单直观而广泛使用,尤其适合作为管道命令链中的一个环节,用于快速得到文件或输出的统计信息。
echo:打印指定的字符串或变量的值
echo 是 Unix 和类似 Unix 的操作系统中一个非常基础的命令,主要用于在终端或者将文本输出到文件。echo 命令将后面的字符串参数显示在标准输出下,也就是通常情况下显示在你的终端或者命令行界面上。
echo "This is a text"
这将在终端打印出 This is a text。
echo 命令还可以用于显示变量的值。例如,如果您有一个名为 VAR 的环境变量,您可以使用如下命令来显示它的值:
echo $VAR
除此之外,echo 命令常与重定向一起使用,将输出内容写入文件而不是显示在屏幕上:
echo "Some text" > file.txt
这将覆盖 file.txt 文件的内容(如果文件已存在)并写入 Some text。如果要追加内容而不是覆盖,可以使用 >>:
echo "Some text" >> file.txt
echo 的一些变种选项包括:
-
-n:在字符串末尾不输出换行符。 -
-e:允许解释字符串中的转义字符(例如,\t表示一个制表符,\n表示一个新的行)。
例如:
echo -e "Line 1\nLine 2"
这将打印两行文本:
Line 1 Line 2
在使用 -e 选项时,你可以在文本中嵌入各种转义字符来格式化输出。
cat:显示文本文件的内容、将文件合并以及创建新的文本文件
cat 命令是一个多用途的工具,它主要用于在Linux和类Unix系统中显示文本文件的内容、将文件合并以及创建新的文本文件。下面是一些关于 cat 命令的更详细信息:
cat [options] [file_name(s)]
-
cat后面可以跟上一个或多个文件名,它会按照文件名列出的顺序来显示所有文件的内容。 -
如果没有指定文件名,或者文件名为
-,则cat将读取标准输入(stdin)。 -
-A,--show-all:等同于-vET的组合,会显示所有控制字符。 -
-b,--number-nonblank:给非空输出行编号。 -
-e:在每行的结束处显示$字符并且显示控制字符(-v 的一部分)。 -
-E,--show-ends:在每行的结束处显示$字符。 -
-n,--number:给所有输出的行编号。 -
-s,--squeeze-blank:当文件中出现多个连续的空白行时,将其压缩为一行。 -
-T,--show-tabs:将制表符显示为^I。 -
-v,--show-nonprinting:使用^和M-符号,除了 LFD 和 TAB 之外显示所有控制字符。
-
浏览文件内容:
cat file.txt
这会显示 file.txt 文件的所有内容。
cat file1.txt file2.txt > combined.txt
这会将 file1.txt 和 file2.txt 的内容合并,并将合并后的内容写入 combined.txt 文件。
-
追加文件内容:
cat anotherfile.txt >> file.txt
这将把 anotherfile.txt 的内容追加到 file.txt 文件的末尾。
-
在命令行中创建文件:
cat > newfile.txt
在这个命令后输入的任何内容都会被写入 newfile.txt;结束输入并保存文件通常需要按 CTRL+D。
-
显示换行符:
cat -E file.txt
这会在每个换行符处显示一个美元符号 ($)。
cat 命令通常用于简单的文本文件查看和处理,由于它将完整文件的内容直接输出到终端,所以对于大型文件来说不如分页查看命令 less 或 more 方便。
tail:输出文件的最后部分
tail 命令在 Linux 和类 Unix 操作系统中用于输出文件的最后部分(默认为最后10行)。它尤其用于查看大文件的尾部或监视文件变化,如实时日志查看。以下是 tail 命令的一些详细介绍和用法:
tail [选项] [文件]
-
-n或--lines=: 后跟一个数字,用于指定要显示的最后几行。 -
-f或--follow: 用于持续监视文件的新增内容。如果文件被重新生成,可以与--follow=name结合使用,这样tail会尝试重新打开该文件。 -
-c: 后跟数字,显示最后若干字节的内容。
-
查看文件最后10行(默认行为):
tail filename.txt
这会显示 filename.txt 的最后10行内容。
-
查看文件指定的行数:
tail -n 20 filename.txt
这会显示 filename.txt 的最后20行内容。
-
实时监控文件的新增内容:
tail -f filename.txt
使用 -f 选项,tail 会实时打印 filename.txt 文件的新增内容。很适合查看日志文件等。
-
查看文件的最后若干字节:
tail -c 100 filename.txt
这会显示 filename.txt 的最后100字节内容。
less:交互式地浏览文本文件
less 是一个程序,允许你以交互式地浏览文本文件,同时不需要一次性加载整个文件。这非常适用于读取大型文件,因为它可以立刻开始阅读文件而不需要等待整个文件都被载入。你可以前后滚动查看文件内容,这与 more 命令类似,但 less 提供了更强大的特性和更方便的导航。
less [options] file_name
运行这个命令后,less 会打开文件,显示文件的内容,并且等待用户的输入进行导航。
在 less 程序中,你可以使用多种键盘命令来浏览文件:
-
空格键或f:向前滚动一屏。 -
b:向后滚动一屏。 -
d:向前滚动半屏。 -
u:向后滚动半屏。 -
Enter:向前滚动一行。 -
y或k:向后滚动一行。 -
g:移动到文件的第一行。 -
G:移动到文件的最后一行。 -
/:后接文本进行向前搜索。 -
?:后接文本进行向后搜索。 -
n:重复上次搜索(下一个结果)。 -
N:反向重复上次搜索。 -
q:退出less程序。
less largefile.log
这个命令会打开 largefile.log 文件以浏览。由于使用了 less,即便文件很大,也可以快速开始阅读而无需等待整个文件加载。
-
-N:显示行号。 -
-S:按行显示长行(默认情况下,长行会被换行显示)。 -
-R:支持颜色显示,适合查看包含颜色代码的日志文件。
head:输出文件的开头部分
head 命令是 Linux 和类 Unix 系统中的一个基本命令,用于输出文件的开头部分(默认是前10行)。这个命令对于预览文件内容或检查数据文件的格式特别有用。以下是 head 命令的一些详细信息和使用方法:
head [选项] [文件...]
-
-n或--lines=: 后跟数字,指定要输出的行数。 -
-c或--bytes=: 后跟数字,指定要输出的字符数。 -
-q或--quiet或--silent: 不显示每个文件名的头信息。 -
-v或--verbose: 总是显示文件名的头信息。
-
预览文件开头的内容(默认输出前10行):
head filename.txt
这将输出 filename.txt 文件的前10行内容。
-
输出指定行数的内容:
head -n 5 filename.txt
这将输出 filename.txt 文件的前5行内容。
-
同时预览多个文件的开头内容:
head filename1.txt filename2.txt
这将分别输出 filename1.txt 和 filename2.txt 文件的前10行内容,并在每个文件内容前显示其文件名。
-
输出文件开头的指定字节数的内容:
head -c 20 filename.txt
这将输出 filename.txt 文件的前20个字符。
head 命令通常与 tail 命令一起使用,以便于用户查看文件的开头和结尾的内容。这在检查日志文件或大型数据集的结构时非常有用。当你只需要了解文件的大体内容,而无需查看完整文件时,使用 head 命令可以节省时间和资源。
vim:功能强大的文本编辑器
vim 是一个功能强大的文本编辑器,广泛用于 Unix 和 Linux 系统。它是 vi 编辑器的改良版,提供了许多增强功能,包括语法高亮、代码折叠、可扩展的插件系统等。vim 以其模式编辑功能而著名,其中最常用的模式包括普通模式、插入模式和命令模式。
在命令行里输入 vim 加上文件名,可以新建或编辑该文件:
vim filename.txt
如果该文件已存在,vim 将打开它;如果不存在,vim 将在您第一次保存时创建一个新文件。
-
普通模式(Normal Mode): 这是
vim启动后的默认模式。在这个模式下,你可以使用快捷键来移动光标、复制和粘贴文本、查找和替换文本等。 -
插入模式(Insert Mode): 通过按
i进入插入模式,在这种模式下,你可以输入文本。 -
命令模式(Command Mode): 通过按
:从普通模式进入命令模式,在这种模式下,你可以输入命令来保存或关闭文件、设置环境选项等。
0. Vim常用基本操作
-
i: 在当前光标位置进入插入模式。
-
Esc: 从插入模式返回普通模式。
-
:w: 保存(write)文件。
-
:q: 退出(quit)
vim。 -
:wq 或 :x: 保存并退出。
-
:q!: 不保存并退出。
-
h, j, k, l: 在普通模式下分别用来向左、下、上、右移动光标。
-
/text: 查找文本
text,按n查找下一个匹配,按N查找上一个匹配。 -
dd 删除光标所在行
-
gg 跳至文首
-
G 调至文尾
-
yy 复制一行
-
yw 复制一个字
-
u 撤销
-
p 粘贴粘贴板的内容到当前行的下面
-
P 粘贴粘贴板的内容到当前行的上面
-
cc 删除当前行并进入编辑模式
-
cw 删除当前字并进入编辑模式
1、移动光标
-
h j k l 上 下 左 右
-
ctrl-y 上移一行
-
ctrl-e 下移一行
-
ctrl-u 上翻半页(up)
-
ctrl-d 下翻半页(down)
-
ctrl-f 上翻一页(forward)
-
ctrl-b 下翻一页(backward)
-
w 跳到下一个字首,按标点或单词分割
-
W 跳到下一个字首,长跳,如end-of-line被认为是一个字
-
e 跳到下一个字尾
-
E 跳到下一个字尾,长跳
-
b 跳到上一个字
-
B 跳到上一个字,长跳
-
0 跳至行首,不管有无缩进,就是跳到第0个字符
-
^ 跳至行首的第一个字符
-
$ 跳至行尾
-
gg 跳至文首
-
G 调至文尾
-
5gg/5G 调至第5行
-
gd 跳至当前光标所在的变量的声明处
-
fx 在当前行中找x字符,找到了就跳转至
-
; 重复上一个f命令,而不用重复的输入fx
-
* 查找光标所在处的单词,向下查找
-
# 查找光标所在处的单词,向上查找
2、删除复制
-
dd 删除光标所在行
-
dw 删除一个字(word)
-
d/D 删除到行末
-
x 删除当前字符
-
X 删除前一个字符
-
yy 复制一行
-
yw 复制一个字
-
y/Y 复制到行末
-
p 粘贴粘贴板的内容到当前行的下面
-
P 粘贴粘贴板的内容到当前行的上面
3、插入模式
-
i 从当前光标处进入插入模式
-
I 进入插入模式,并置光标于行首
-
a 追加模式,置光标于当前光标之后
-
A 追加模式,置光标于行末
-
o 在当前行之下新加一行,并进入插入模式
-
O 在当前行之上新加一行,并进入插入模式
-
Esc 退出插入模式
4、编辑
-
J 将下一行和当前行连接为一行
-
cc 删除当前行并进入编辑模式
-
cw 删除当前字,并进入编辑模式
-
c$ 擦除从当前位置至行末的内容,并进入编辑模式
-
s 删除当前字符并进入编辑模式
-
S 删除光标所在行并进入编辑模式
-
xp 交换当前字符和下一个字符
-
u 撤销
-
ctrl+r 重做
-
~ 切换大小写,当前字符
-
>> 将当前行右移一个单位
-
<< 将当前行左移一个单位(一个tab符)
-
== 自动缩进当前行
5、查找替换
-
/pattern 向后搜索字符串pattern
-
?pattern 向前搜索字符串pattern
-
"\c" 忽略大小写
-
"\C" 大小写敏感
-
n 下一个匹配(如果是/搜索,则是向下的下一个,?搜索则是向上的下一个)
-
N 上一个匹配(同上)
-
:%s/old/new/g 搜索整个文件,将所有的old替换为new
-
:%s/old/new/gc 搜索整个文件,将所有的old替换为new,每次都要你确认是否替换
退出 vim 时,你需要先确保进入普通模式(通常按 Esc),然后输入 : 进入命令模式,并根据你的需要选择以上退出命令。
cat和tail不同的使用场景:
cat 和 tail 命令在 Linux 中有不同的使用场景:
-
cat 命令:
-
查看小文件全文:当你需要查看整个小型文件的内容时,
cat很有用。 -
连接多个文件:
cat命令经常用于将多个文本文件的内容合并起来查看或者用重定向创建一个新的合并文件。 -
创建文件:使用
cat > filename可以快速创建一个新的文件并输入内容。 -
查看文件内容添加到另一个文件尾部:可以用
cat file1 >> file2将file1的内容追加到file2的末尾。
-
cat file.txt cat file1.txt file2.txt > combinedfile.txt
-
tail 命令:
-
查看文件的最后部分:
tail默认显示文件的最后10行,但你可以通过-n选项修改这个行数。 -
实时监控日志文件:使用
-f选项,tail可以实时显示文件末尾新增的内容,这非常适合监控逐步增长的日志文件。
-
tail -n 20 file.txt # 查看文件的最后20行 tail -f /var/log/messages # 实时监控系统消息日志文件
因此,cat 命令更多用于短文件或者文件合并的场景,而 tail 命令则适合查看大型文件的尾部内容或者实时监控文件的新增内容。
网络操作类
ping:测试主机之间的连通性
ping 是一个常用的网络管理员工具,用来测试网络连接的可用性。此命令会向特定的主机(可以是一个 IP 地址或者是一个域名)发送 ICMP(Internet Control Message Protocol)回声请求报文,并监听回声应答来检查主机的可达性。
ping [options] destination
其中 destination 可以是一个 IP 地址或是一个域名,例如:
ping 8.8.8.8 ping google.com
这将分别向 8.8.8.8(Google 的公共 DNS 服务器之一)和 Google 的主页发送请求。
ping 发出的是一系列网络请求包,每收到一个回应就显示一个结果,包括:
-
时间(通常以毫秒计):数据包往返时间。
-
TTL(Time To Live):经过的网络节点(路由器)数量上限。
以下是 ping 命令中一些经常使用的选项:
-
-c count:指定发送的回声请求的数量。 -
-w deadline:指定等待回声回复的最大秒数。 -
-i interval:指定连续两个请求之间的间隔秒数。
例如,如果你想发送 5 个 ICMP 请求给 google.com:
ping -c 5 google.com
如果你想指定 10 秒的截止时间,可以这么使用:
ping -w 10 google.com
通常情况下,如果网络连接正常,你将会看到类似于以下的输出:
64 bytes from 8.8.8.8: icmp_seq=1 ttl=56 time=15.6 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=56 time=18.4 ms
这显示了 ICMP 回声请求和响应之间的时间、TTL 值和数据包的大小等信息。
如果回声请求没有得到回应,一般来说是因为网络不通,目的主机不可达,或者 ICMP 请求被目的主机或中间网络设备屏蔽。
ifconfig:显示或配置网络接口信息
ifconfig(interface configuration)是 Unix 和类 Unix 系统中传统的命令行工具,用于配置、控制和查询 TCP/IP 网络接口参数。使用 ifconfig,用户可以启用或禁用接口,管理 IP 地址、子网掩码、广播地址,查看接口统计信息等。
ifconfig
在不带任何参数的情况下,ifconfig 命令将显示当前系统上所有活动接口的状态。
要查看特定接口的详情,可以指定接口名称,例如:
ifconfig eth0
这将只显示 eth0(通常是系统上的第一个以太网适配器)的配置。
ifconfig 也可以用于配置接口参数,例如设置 IP 地址和子网掩码:
ifconfig eth0 192.168.1.10 netmask 255.255.255.0 up
以上命令将 eth0 接口的 IP 地址设置为 192.168.1.10,子网掩码设置为 255.255.255.0,并启动接口。
另外的一些常用选项还包括:
-
up:激活指定的网络接口。 -
down:禁用指定的网络接口。 -
mtu:设置接口的最大传输单元(MTU)大小。 -
add:为接口添加一个新的 IP 地址。
netstat:显示网络连接、路由表和接口统计信息
netstat(network statistics)是一个用于检查各种网络相关统计的命令行工具。它可以显示网络接口统计、路由表、连接信息(包括 TCP 和 UDP 协议的连接),以及多种网络协议(如 IP、TCP、UDP 和 ICMP 等)的统计数据。
显示所有端口(包括监听和非监听端口):
netstat -a
显示所有 TCP 连接:
netstat -t
显示所有 UDP 连接:
netstat -u
显示所有监听中的端口:
netstat -l
显示每个协议的统计数据:
netstat -s
以持续刷新的方式显示网络信息(每隔一秒更新一次):
netstat -c
显示路由表:
netstat -r
显示带有进程 ID 的网络连接,这个选项对于确定哪些程序在使用哪些连接特别有用:
netstat -p
在使用 netstat 命令时,选项可以结合使用。比如,如果你想看所有的 TCP 连接,并且带有对应进程的信息,你可以使用:
netstat -tp
需要注意的是,在某些系统上,你可能需要有管理员权限或 sudo 权限才能看到某些网络统计数据和进程信息。
nslookup:查询 DNS 信息
nslookup 是一个用来查询域名系统(DNS)来获取域名或IP地址映射的命令行工具。它用于查找特定域名的DNS记录,如IP地址(A 和 AAAA记录)、邮件服务器的MX记录、名称服务器的NS记录等。
查询域名的IP地址:
nslookup example.com
查询特定DNS服务器上的域名信息:
nslookup example.com ns1.example.com
其中 ns1.example.com 是你想要查询的DNS服务器。
在交互模式下使用 nslookup:
nslookup > server ns1.example.com > set type=any > example.com
这会设置 nslookup 使用指定的DNS服务器,并查询所有类型的DNS记录。
nslookup 同时支持反向DNS查找,即根据IP地址查找对应的主机名:
nslookup 192.0.2.1
nslookup 有两种模式:交互模式和非交互模式。在非交互模式下,nslookup 命令执行完后会立即退出。而在交互模式下,用户可以连续地执行多个查询直到手动退出。
traceroute:跟踪数据包的路由路径
traceroute 是一个网络诊断工具,其主要用途是跟踪数据包从一台主机传输到另一台主机所经过的路径。这个命令会显示数据包到达目标地址每一跳(hop)的时间和路径。traceroute 通过发送一系列带有逐渐增长的生存时间(TTL)值的ICMP请求,来确定到达目标的路由路径。每增加一跳,TTL值就增加1,当TTL值过期后,中间的路由器就会发送一个ICMP超时响应给发送端。
traceroute example.com
这条命令将跟踪数据包到达域名 "example.com" 的路径。
traceroute 具有多个选项,比如可以指定查询最大跳数、选择使用UDP、ICMP或TCP数据包进行追踪等。例如:
-
指定最大跳数限制为30:
traceroute -m 30 example.com
-
使用ICMP回显请求而非默认的UDP数据包进行追踪:
traceroute -I example.com
-
指定数据包大小:
traceroute -s 60 example.com
traceroute 在不同的操作系统中可能有些许差异。例如,在Windows操作系统上,相似功能的命令是 tracert。
而Linux和macOS上通常用的就是 traceroute 命令。它非常有用于确定数据包传输中的故障点,以及了解网络数据包的路径结构。然而,由于现代网络环境的复杂性以及防火墙的存在,有时数据包可能不会到达目的地,此时 traceroute 提供的路径仅供参考。
yum:软件包管理
yum(Yellowdog Updater, Modified)是一个在基于RPM的Linux系统中使用的包管理器,它协助用户安装、更新、删除和管理软件包,同时处理依赖关系的解决。它常用于Fedora、CentOS和RHEL等发行版。
安装软件包:
yum install package_name
删除(卸载)软件包:
yum remove package_name
更新所有已安装的软件包到最新版本:
yum update
列出所有可用的软件包:
yum list available
搜索软件包:
yum search keyword
清除缓存(包括软件包和头文件的缓存):
yum clean all
列出所有已安装的软件包:
yum list installed
获取软件包的信息:
yum info package_name
yum 使用软件仓库的概念来管理软件包。默认情况下,发行版会提供一些标准的软件仓库,但用户也可以添加更多的第三方仓库来扩展软件包的选择。
此外,yum 还有一个重要的特点:它会自动解决依赖问题。当你尝试安装某个软件包时,如果这个软件包需要其他的软件包作为依赖,yum 将自动寻找、下载和安装这些依赖,使得用户的软件安装过程简化。
ss:查看系统网络状态的命令
ss(socket statistics)是一个用于检查套接字统计信息的实用工具,它可以显示像 netstat 一样的网络连接信息,但它更快,可以提供更多的统计信息。
列出所有打开的网络连接端口:
ss -l
显示所有TCP套接字:
ss -t -a
显示所有的UDP套接字:
ss -u -a
显示所有正在监听的套接字:
ss -ltn
显示所有ESTABLISHED状态的TCP连接:
ss -t state established
结合使用过滤条件,只显示来自特定ip和端口的连接:
ss src ipaddress:port
查看进程使用的套接字:
ss -tp
输出内存使用情况:
ss -tm
ss 提供的是动态的、实时的系统套接字连接情况。它被广泛用于了解系统的网络连接状态,也是系统管理员和网络工程师经常使用的诊断工具。随着 Linux 系统的更新和升级,ss 由于其高效和快速的特性,逐渐取代了 netstat。
wget:用于从网络上下载文件
wget 是一个命令行工具,它支持下载文件,支持HTTP、HTTPS和FTP协议。wget 常被用于下载文件或整个网站的内容,并支持后台下载、断点续传以及限制下载速度等功能。
命令格式:
wget [选项]... [URL]...
1.启动
-V, --version 显示 Wget 的版本信息并退出。 -h, --help 打印此帮助。 -b, --background 启动后转入后台。 -e, --execute=COMMAND 运行一个“.wgetrc”风格的命令。 ## 显示 Wget 的版本信息并退出 [root@network test]# wget -V [root@network test]# wget --version ## 打印 wgt 帮助信息 [root@network test]# wget -h ## 启动后转入后台下载,将把输出写入至 "wget-log" [root@network test]# wget -b https://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz ## 可以使用以下命令来察看下载进度 [root@network test]# tail -f wget-log
2.日志和输入文件
日志和输入文件:
-o, --output-file=FILE 将日志信息写入 FILE。
-a, --append-output=FILE 将信息添加至 FILE。
-d, --debug 打印大量调试信息。
-q, --quiet 安静模式 (无信息输出)。
-v, --verbose 详尽的输出 (此为默认值)。
-nv, --no-verbose 关闭详尽输出,但不进入安静模式。
--report-speed=TYPE Output bandwidth as TYPE. TYPE can be bits.
-i, --input-file=FILE 下载本地或外部 FILE 中的 URLs。
-F, --force-html 把输入文件当成 HTML 文件。
-B, --base=URL 解析与 URL 相关的
HTML 输入文件 (由 -i -F 选项指定)。
--config=FILE Specify config file to use.
3.下载
-t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。
--retry-connrefused 即使拒绝连接也是重试。
-O, --output-document=FILE 将文档写入 FILE。
-nc, --no-clobber skip downloads that would download to
existing files (overwriting them).
-c, --continue 断点续传下载文件。
--progress=TYPE 选择进度条类型。
-N, --timestamping 只获取比本地文件新的文件。
--no-use-server-timestamps 不用服务器上的时间戳来设置本地文件。
-S, --server-response 打印服务器响应。
--spider 不下载任何文件。
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。
--dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。
--connect-timeout=SECS 设置连接超时为 SECS 秒。
--read-timeout=SECS 设置读取超时为 SECS 秒。
-w, --wait=SECONDS 等待间隔为 SECONDS 秒。
--waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒。
--random-wait 获取多个文件时,每次随机等待间隔
0.5*WAIT...1.5*WAIT 秒。
--no-proxy 禁止使用代理。
-Q, --quota=NUMBER 设置获取配额为 NUMBER 字节。
--bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)。
--limit-rate=RATE 限制下载速率为 RATE。
--no-dns-cache 关闭 DNS 查寻缓存。
--restrict-file-names=OS 限定文件名中的字符为 OS 允许的字符。
--ignore-case 匹配文件/目录时忽略大小写。
-4, --inet4-only 仅连接至 IPv4 地址。
-6, --inet6-only 仅连接至 IPv6 地址。
--prefer-family=FAMILY 首先连接至指定协议的地址
FAMILY 为 IPv6,IPv4 或是 none。
--user=USER 将 ftp 和 http 的用户名均设置为 USER。
--password=PASS 将 ftp 和 http 的密码均设置为 PASS。
--ask-password 提示输入密码。
--no-iri 关闭 IRI 支持。
--local-encoding=ENC IRI (国际化资源标识符) 使用 ENC 作为本地编码。
--remote-encoding=ENC 使用 ENC 作为默认远程编码。
--unlink remove file before clobber.
4.目录
-nd, --no-directories 不创建目录。
-x, --force-directories 强制创建目录。
-nH, --no-host-directories 不要创建主目录。
--protocol-directories 在目录中使用协议名称。
-P, --directory-prefix=PREFIX 以 PREFIX/... 保存文件
--cut-dirs=NUMBER 忽略远程目录中 NUMBER 个目录层。
5.HTTP/HTTPS 选项
HTTP 选项:
--http-user=USER 设置 http 用户名为 USER。
--http-password=PASS 设置 http 密码为 PASS。
--no-cache 不在服务器上缓存数据。
--default-page=NAME 改变默认页
(默认页通常是“index.html”)。
-E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档。
--ignore-length 忽略头部的‘Content-Length’区域。
--header=STRING 在头部插入 STRING。
--max-redirect 每页所允许的最大重定向。
--proxy-user=USER 使用 USER 作为代理用户名。
--proxy-password=PASS 使用 PASS 作为代理密码。
--referer=URL 在 HTTP 请求头包含‘Referer: URL’。
--save-headers 将 HTTP 头保存至文件。
-U, --user-agent=AGENT 标识为 AGENT 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive (永久连接)。
--no-cookies 不使用 cookies。
--load-cookies=FILE 会话开始前从 FILE 中载入 cookies。
--save-cookies=FILE 会话结束后保存 cookies 至 FILE。
--keep-session-cookies 载入并保存会话 (非永久) cookies。
--post-data=STRING 使用 POST 方式;把 STRING 作为数据发送。
--post-file=FILE 使用 POST 方式;发送 FILE 内容。
--content-disposition 当选中本地文件名时
允许 Content-Disposition 头部 (尚在实验)。
--content-on-error output the received content on server errors.
--auth-no-challenge 发送不含服务器询问的首次等待
的基本 HTTP 验证信息。
HTTPS (SSL/TLS) 选项:
--secure-protocol=PR choose secure protocol, one of auto, SSLv2,
SSLv3, TLSv1, TLSv1_1 and TLSv1_2.
--no-check-certificate 不要验证服务器的证书。
--certificate=FILE 客户端证书文件。
--certificate-type=TYPE 客户端证书类型,PEM 或 DER。
--private-key=FILE 私钥文件。
--private-key-type=TYPE 私钥文件类型,PEM 或 DER。
--ca-certificate=FILE 带有一组 CA 认证的文件。
--ca-directory=DIR 保存 CA 认证的哈希列表的目录。
--random-file=FILE 带有生成 SSL PRNG 的随机数据的文件。
--egd-file=FILE 用于命名带有随机数据的 EGD 套接字的文件。
6.FTP选项
FTP 选项:
--ftp-user=USER 设置 ftp 用户名为 USER。
--ftp-password=PASS 设置 ftp 密码为 PASS。
--no-remove-listing 不要删除‘.listing’文件。
--no-glob 不在 FTP 文件名中使用通配符展开。
--no-passive-ftp 禁用“passive”传输模式。
--preserve-permissions 保留远程文件的权限。
--retr-symlinks 递归目录时,获取链接的文件 (而非目录)。
7.递归下载
递归下载:
-r, --recursive 指定递归下载。
-l, --level=NUMBER 最大递归深度 (inf 或 0 代表无限制,即全部下载)。
--delete-after 下载完成后删除本地文件。
-k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件。
--backups=N before writing file X, rotate up to N backup files.
-K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
-m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
-p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
--strict-comments 用严格方式 (SGML) 处理 HTML 注释。
示例:
下载单个文件:
wget http://example.com/file.iso
下载整个网站:
wget --mirror --convert-links --adjust-extension --page-requisites --no-parent http://example.com
继续未完成的下载(断点续传):
wget -c http://example.com/file.iso
下载文件并保存为不同的文件名:
wget -O newfilename http://example.com/file.iso
限制下载速度:
wget --limit-rate=100k http://example.com/file.iso
下载多个文件(从文本文件中读取URL列表):
wget -i filelist.txt
下载并转换链接以适合本地浏览(例如下载网页):
wget --convert-links http://example.com
示例:
wget -r -nH -nd -np --reject="index.html*" --reject="*sha1" http://172.20.47.129/wjx/3-king_pan_bak/YonBIP-R5-2312-X86/server/
这条 wget 命令使用多个参数来自定义下载过程,适用于从给定的 HTTP 服务器递归地下载文件。具体来说,这条命令会从指定的 URL 下载文件,但会排除某些类型的文件。下面是该命令各个参数的详细解释:
-
wget:是一个非交互式的网络下载工具,可以下载文件从互联网上。 -
-r:递归下载,它会下载指定 URL 下的所有文件及子目录下的文件。 -
-nH:禁止创建远程服务器上的目录层次结构。通常wget会在本地创建一个与远程服务器相同的目录结构,但使用此选项,wget不会创建基于远程服务器的目录。 -
-nd:不创建目录,所有下载的文件都直接存放在当前目录。 -
-np:不进行爬行下载,也就是说不会下载任何父目录中的内容。 -
--reject="index.html*":排除所有匹配index.html*模式的文件,这通常用于避免保存自动生成的索引文件。 -
--reject="*sha1":这会排除所有扩展名为.sha1文件,这些通常是包含文件哈希的校验和文件。 -
http://172.20.47.129/.../server/:是你指定的 URL,wget会从这个 URL 开始下载内容,根据上述条件递归地下载文件。
curl:用于与 URL 相关的操作,包括下载文件、发送请求、获取响应等
curl 是一个非常强大的命令行工具,用于传输或获取数据,支持多种协议,包括 HTTP、HTTPS、FTP、FTPS、SCP、SFTP、TFTP、LDAP、LDAPS、DICT、FILE、TELNET 和 SMTP。curl 可以用于提交表单数据、上传文件以及包括 RESTful 服务在内的各种其他场景。
发送 GET 请求:
curl http://example.com
发送 POST 请求:
curl -X POST http://example.com/login -d "username=username&password=password"
上传文件:
curl -F "file=@path/to/localfile" http://example.com/upload
保存下载的文件:
curl -o localfilename http://example.com/remote_file
发送 HTTP 头信息:
curl -H "X-My-Header: 123" http://example.com
使用用户名和密码进行HTTP认证:
curl -u username:password http://example.com
通过代理访问:
curl -x proxy-server:port http://example.com
检索 HTTP 头信息:
curl -I http://example.com
在请求中包含cookie:
curl -b "name=value" http://example.com
tcpdump:网络抓包工具,用于捕获和分析网络数据包
tcpdump 是一个强大的命令行网络分析工具,它可以捕获和分析经过网络接口的数据包。它在网络故障排除和安全分析中非常有用,能够显示全部或部分的网络数据包的内容,还可以基于字符串或十六进制表达式过滤数据包。
捕获特定接口上的所有数据包:
tcpdump -i eth0
保存捕获的数据包到文件中:
tcpdump -w capture_file.pcap
从文件中读取数据包:
tcpdump -r capture_file.pcap
只捕获特定主机的数据包:
tcpdump host example.com
只捕获特定端口的数据包:
tcpdump port 80
捕获包含特定协议的数据包,如 icmp:
tcpdump icmp
与逻辑运算符结合,捕获复杂的数据包条件,例如,IP 地址和端口号:
tcpdump 'src host 192.168.0.1 and dst port 22'
限制捕获的数据包数量:
tcpdump -c 100
细粒度控制数据包的输出内容:
tcpdump -A # 以 ASCII 格式显示每个包(不进行链路层头的输出) tcpdump -XX # 以十六进制和ASCII两种格式显示数据包的内容,包括链路层头
tcpdump 工具拥有非常多的命令行选项,可以通过 man tcpdump 或 tcpdump --help 命令来查看更详细的帮助信息和用法。适当地使用 tcpdump,可以帮助你深入了解网络流量和检测潜在的问题。
进程管理类
kill:终止进程
kill 命令是一个用于发送信号给特定进程的工具。在 Unix 和类 Unix 系统中,可以使用这个命令终止或控制进程执行。当没有指定信号时,默认发送的是 SIGTERM(信号15),它会告诉进程应该正常关闭。
终止一个进程:
kill PID
这里的 PID 是你想要终止的进程ID。如果不知道进程ID,可以使用 ps 命令、top 命令或其他工具来查找。
发送特定信号到进程:
kill -s SIGNAL PID
比如,你可以使用 SIGKILL 信号(信号9),该信号会强制终止进程:
kill -SIGKILL PID
或者使用更短的形式:
kill -9 PID
如果你想要向所有具有相同名字的进程发送信号,可以使用 pkill 或 killall 命令。
使用 pkill 发送信号:
pkill -SIGNAL process_name
或者使用 killall:
killall -SIGNAL process_name
注意在使用 kill 命令时一定要小心,尤其是使用 SIGKILL 信号。因为 SIGKILL 信号会立刻终止进程,不会给进程任何清理资源和保存工作的机会,可能会导致数据丢失或其他问题。
ps:显示进程状态
ps 命令通常用于查看当前系统中的活动进程。它提供了进程的详细列表,包括进程ID(PID)、运行时间、内存使用、命令等信息。ps 命令是“process status”的缩写,是系统监控和管理中常用的工具。
查看与当前终端关联的所有进程:
ps
显示所有运行的进程:
ps -e
或者:
ps -A
显示所有进程及其详细信息:
ps -ef
或者:
ps -aux
查看特定用户的进程:
ps -u username
以全格式显示进程(用户,PID,%CPU,内存等):
ps -ef
查看进程树(带层级结构的进程列表):
ps -ejH
或者:
ps axjf
更新输出的间隔(实时监控进程状态,每2秒更新一次):
ps -e --forest --watch 2
top:显示系统中的活动进程
top 命令是一个非常实用的动态交互式工具,它提供了实时的系统状态监控视图,包括CPU使用率、内存使用、进程信息等。通过这个命令,用户可以迅速地查看系统资源的使用情况,以及当前运行的进程状态。
当输入 top 后,你会看到一个更新的显示屏,包含了以下几部分:
-
系统概览:包括系统运行时间,登录用户数,平均负载等。
-
任务队列信息:显示正在运行、休眠、停止和僵尸状态的进程数。
-
CPU状态:显示用户、系统、空闲和等待IO等状态的CPU使用率。
-
内存使用状态:显示物理内存、交换分区等使用情况。
-
进程列表:显示各个进程的用户、优先级、虚拟内存使用、物理内存使用、共享内存使用、状态、CPU占用率以及执行的命令。
top
此外,top 命令提供了多种交互式命令,可以在运行 top 时执行:
-
h或者?:显示帮助。 -
k:杀掉一个进程。会要求输入PID和发送的信号。 -
f:添加或删除显示的列。 -
r:重新设定一个进程的nice值。 -
z:切换颜色高亮。 -
c:切换显示命令全路径和仅显示命令名。 -
M:按内存使用量排序。 -
P:按CPU使用率排序。
要退出 top,可以使用 q 键。
nice:调整进程的优先级
nice 命令在 Unix 和类 Unix 系统中使用,它用于设置一个进程的调度优先级。当多个进程同时运行时,Linux 内核根据这个优先级(也叫 nice 值)来决定分配给每个进程的 CPU 时间。nice 值的范围从 -20(最优先)到 19(最不优先),默认情况下,进程创建时的 nice 值是 0。
使用 nice 命令,你可以在启动进程时赋予它一个特定的 nice 值,这样能够在系统负载高的情况下让某些进程运行得更快,或者在负载低时让其他进程有更多机会运行。
启动一个新进程并设置 nice 值:
nice -n NICE_VALUE command [arguments...]
比如,要启动 my_command 并给它设置 nice 值 10:
nice -n 10 my_command
要更改一个正在运行的进程的 nice 值,可以使用 renice 命令:
renice NICE_VALUE -p PID
这里的 PID 是你想要更改的进程的进程ID。
例如,如果你想要将 PID 为 1234 的进程的 nice 值设置为 5,可以执行以下命令:
renice 5 -p 1234
只有 root 用户或具有适当权限的用户可以将进程的 nice 值设置为比当前值更低(即更优先)。普通用户只能增加他们自己的进程的 nice 值(即使其更不优先)。
renice:修改进程的优先级
renice 命令在 Unix 和类 Unix 系统中被用来改变正在运行的进程的 nice 值。这个命令是 nice 命令的补充,它允许你调整已经创建的进程的调度优先级。更改进程的 nice 值可以影响进程的CPU时间配比,从而优化系统的性能。
使用 renice 命令,您可以指定一个新的 nice 值给一个或多个正在运行的进程。命令的一般格式如下:
renice NICE_VALUE -p PID
其中:
-
NICE_VALUE是您希望设定的新的 nice 值。可接受的值范围是 -20 到 19。 -
PID是进程的进程标识符(Process ID)。
此外,您还可以针对进程组(使用 -g 选项)或用户所有的进程(使用 -u 选项)重新分配 nice 值。
例如,要将 PID 为 1234 的进程的 nice 值修改为 5,可以使用以下命令:
renice 5 -p 1234
这会将该进程的 nice 值设置为 5。值得注意的是,只有具有相应权限(通常是 root 用户或进程的所有者)的用户才能降低 nice 值(使进程运行得更快)。任何用户都可以提高他们拥有的进程的 nice 值(使进程运行得更慢)。
系统管理和远程操作类
scp:安全复制文件
scp(安全复制)命令是一个在本地和远程主机之间复制文件的工具,它是通过 SSH 协议提供加密的文件传输服务。这个命令在用户需要传输敏感数据时非常有用,因为所有传输的数据都会被加密,这有助于防止数据在传输过程中被拦截。
从本地复制文件到远端服务器:
scp local_file username@remotehost:remote_file
从远端服务器复制文件到本地:
scp username@remotehost:remote_file local_file
在这里:
-
local_file是要复制的本地文件路径。 -
remote_host是远程主机的地址。 -
username是远程主机上的用户名。 -
remote_file是要复制到远程主机上的文件路径或要从远程主机复制到本地的文件路径。
此外,scp 也支持复制目录,可以通过 -r 选项来实现:
从本地复制整个目录到远端服务器:
scp -r local_directory username@remotehost:remote_directory
从远端服务器复制整个目录到本地:
scp -r username@remotehost:remote_directory local_directory
在复制大文件或者低速网络环境下,scp 支持 -C 选项来开启压缩功能,可以加快传输速度。
ssh:安全 Shell
SSH(Secure Shell)是一种网络协议,用于在网络上提供加密的终端会话连接。它在不安全的网络上提供安全的数据传输、命令执行以及其他网络服务。SSH指令通常用于远程登录到服务器上。
ssh username@hostname
在上面的用法中,username 是您希望登陆的远程用户,hostname 可以是服务器的IP地址或者域名。
选项详解:
-
-p <port>:指定SSH服务器监听的端口号,默认是22。 -
-i <keyfile>:使用指定的私钥文件来认证登录。 -
-t:强制分配一个伪终端,这通常是在执行远程命令时自动发生的。 -
-v,-vv,-vvv:提供详细程度递增的调试信息,一般用于排查连接问题。
端口转发:
-
-L [bind_address:]port:host:hostport:本地端口转发。把本地的某个端口转发到远程主机的指定端口。 -
-R [bind_address:]port:host:hostport:远程端口转发。把远程主机的某个端口转发到本地的指定端口。
文件复制(利用 SSH 协议):
-
scp: SSH Copy,用于通过SSH协议复制文件。 -
sftp: SSH File Transfer Protocol,提供类似FTP的文件传输功能,但是使用SSH进行加密。
批量执行命令:
ssh username@hostname "command1; command2; command3"
这会在远程服务器上依次执行command1, command2, command3。
密钥认证机制: 您可以生成SSH密钥对(公钥和私钥),并将公钥放置在远程服务器的~/.ssh/authorized_keys文件。这样,您便可以无需输入密码来登录服务器。
防止连接超时: 在长时间未有操作时,SSH连接可能会自动断开。为了保持连接,您可以使用以下两种方式:
-
服务器端设置:在服务器的
/etc/ssh/sshd_config配置文件中,设置ClientAliveInterval和ClientAliveCountMax。 -
客户端设置:使用
-o选项在SSH命令中设置ServerAliveInterval。
例如,ssh -o ServerAliveInterval=60 username@hostname会每60秒发送一次保活信号。
代理跳板: 利用-A选项,您可以在多层SSH连接中转发您的SSH代理会话。这在需要通过一个跳板机(代理)连接到另一个服务器时非常有用。
Enabling X11 Forwarding: 通过使用-X选项,您可以启用X11转发,这允许您从远程机器上运行图形界面的程序。
使用别名快速连接: 您可以在本地用户的~/.ssh/config文件中设置别名来简化SSH连接的命令。例如:
Host myserver
HostName server.example.com
User myuser
Port 2222
IdentityFile ~/.ssh/mykey
设置后,您可以仅使用ssh myserver来快速连接。
安全相关设置: 您也可以通过参数来提高SSH连接的安全性,例如使用-o "Cipher=blowfish-cbc"来指定更加高效的加密算法,或使用-o StrictHostKeyChecking=no来避免主机键检查。然而,这些选项应谨慎使用,可能会带来安全上的风险。
rsync:远程文件同步工具
rsync 就是远程同步的意思remote sync. rsync 被用在UNIX / Linux执行备份操作操作. rsync 工具包被用来从一个位置到另一个位置高效地同步文件和文件夹. rsync可以实现在同一台机器的不同文件直接备份,也可以跨服务器备份.
rsync [OPTION]... SRC [SRC]... DEST
一般同步传输目录都使用azv选项. -v, --verbose 详细模式输出 -q, --quiet 精简输出模式 -c, --checksum 打开校验开关,强制对文件传输进行校验 -a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于-rlptgoD -r, --recursive 对子目录以递归模式处理 -R, --relative 使用相对路径信息 -b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用--suffix选项来指定不同的备份文件前缀。 --backup-dir 将备份文件(如~filename)存放在在目录下。 -suffix=SUFFIX 定义备份文件前缀 -u, --update 仅仅进行更新,也就是跳过所有已经存在于DST,并且文件时间晚于要备份的文件。(不覆盖更新的文件) -l, --links 保留软链结 -L, --copy-links 想对待常规文件一样处理软链结 --copy-unsafe-links 仅仅拷贝指向SRC路径目录树以外的链结 --safe-links 忽略指向SRC路径目录树以外的链结 -H, --hard-links 保留硬链结 -p, --perms 保持文件权限 -o, --owner 保持文件属主信息 -g, --group 保持文件属组信息 -D, --devices 保持设备文件信息 -t, --times 保持文件时间信息 -S, --sparse 对稀疏文件进行特殊处理以节省DST的空间 -n, --dry-run现实哪些文件将被传输 -W, --whole-file 拷贝文件,不进行增量检测 -x, --one-file-system 不要跨越文件系统边界 -B, --block-size=SIZE 检验算法使用的块尺寸,默认是700字节 -e, --rsh=COMMAND 指定使用rsh、ssh方式进行数据同步 --rsync-path=PATH 指定远程服务器上的rsync命令所在路径信息 -C, --cvs-exclude 使用和CVS一样的方法自动忽略文件,用来排除那些不希望传输的文件 --existing 仅仅更新那些已经存在于DST的文件,而不备份那些新创建的文件 --delete 删除那些DST中SRC没有的文件 --delete-excluded 同样删除接收端那些被该选项指定排除的文件 --delete-after 传输结束以后再删除 --ignore-errors 及时出现IO错误也进行删除 --max-delete=NUM 最多删除NUM个文件 --partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输 --force 强制删除目录,即使不为空 --numeric-ids 不将数字的用户和组ID匹配为用户名和组名 --timeout=TIME IP超时时间,单位为秒 -I, --ignore-times 不跳过那些有同样的时间和长度的文件 --size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间 --modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为0 -T --temp-dir=DIR 在DIR中创建临时文件 --compare-dest=DIR 同样比较DIR中的文件来决定是否需要备份 -P 等同于 --partial --progress 显示备份过程 -z, --compress 对备份的文件在传输时进行压缩处理 --exclude=PATTERN 指定排除不需要传输的文件模式 --include=PATTERN 指定不排除而需要传输的文件模式 --exclude-from=FILE 排除FILE中指定模式的文件 --include-from=FILE 不排除FILE指定模式匹配的文件 --version 打印版本信息 --address 绑定到特定的地址 --config=FILE 指定其他的配置文件,不使用默认的rsyncd.conf文件 --port=PORT 指定其他的rsync服务端口 --blocking-io 对远程shell使用阻塞IO -stats 给出某些文件的传输状态 --progress 在传输时现实传输过程 --log-format=formAT 指定日志文件格式 --password-file=FILE 从FILE中得到密码 --bwlimit=KBPS 限制I/O带宽,KBytes per second -h, --help 显示帮助信息
示例 1.:同步同一台机上的两个目录
rsync -zvr /var/opt/installation/inventory/ /root/temp building file list ... done sva.xml svB.xml . sent 26385 bytes received 1098 bytes 54966.00 bytes/sec total size is 44867 speedup is 1.63
说明:
-
-z: --compress 使用压缩机制
-
-v: --verbose 打印详细信息
-
-r: --recursive 以递归模式同步子目录
注意: 同步完成后, 我们会发现文件的时间戳timestamps发生了改变.
ls -l /var/opt/installation/inventory/sva.xml /root/temp/sva.xml -r--r--r-- 1 bin bin 949 Jun 18 2009 /var/opt/installation/inventory/sva.xml -r--r--r-- 1 root bin 949 Sep 2 2009 /root/temp/sva.xml
示例 2: 保留文件的时间戳
有时我们希望拷贝或同步时, 时间戳不要发生变化, 源文件是什么时间戳,目标文件就是什么时间戳, 这时我们需要使用 -a --archive 归档模式选项. -a 选项相当于7个选项的组合 -rlptgoD
-
-r, --recursive: 递归模式Recursive mode
-
-l, --links: 将符号链接当作符号链接文件拷贝, 不拷贝符合链接指向的文件内容.
-
-p, --perms: 保留文件权限
-
-t, --times: 保留修改时间戳
-
-g, --group: 保留用户组信息
-
-o, --owner: 保留用户信息(需要超级用户权限)
-
-D, 相当于 --devices --specials 的组合, 保留设备文件, 保留特殊文件.
rsync -azv /var/opt/installation/inventory/ /root/temp/ building file list ... done ./ sva.xml svB.xml . sent 26499 bytes received 1104 bytes 55206.00 bytes/sec total size is 44867 speedup is 1.63
同步完成后,时间戳信息得到了保留
ls -l /var/opt/installation/inventory/sva.xml /root/temp/sva.xml -r--r--r-- 1 root bin 949 Jun 18 2009 /var/opt/installation/inventory/sva.xml -r--r--r-- 1 root bin 949 Jun 18 2009 /root/temp/sva.xml
示例 3: 拷贝单个文件
rsync -v /var/lib/rpm/Pubkeys /root/temp/Pubkeys sent 42 bytes received 12380 bytes 3549.14 bytes/sec total size is 12288 speedup is 0.99
示例 4. 从本地拷贝多个文件到远端
使用rsync, 也可以从本地拷贝多个文件或目录到远端, 以下即为示例:
rsync -avz /root/temp/ thegeekstuff@192.168.200.10:/home/thegeekstuff/temp/ Password: building file list ... done ./ rpm/ rpm/Basenames rpm/Conflictname sent 15810261 bytes received 412 bytes 2432411.23 bytes/sec total size is 45305958 speedup is 2.87
示例 5. 从远程服务器拷贝文件到本地
与示例 4 稍有不同, 这时远端目录或文件作为源位置, 本地目录或文件作为目标位置, 示例如下:
rsync -avz thegeekstuff@192.168.200.10:/var/lib/rpm /root/temp Password: receiving file list ... done rpm/ rpm/Basenames . sent 406 bytes received 15810230 bytes 2432405.54 bytes/sec total size is 45305958 speedup is 2.87
示例 6. Remote shell for Synchronization
rsync 允许指定远程主机上运行shell命令. 这时需要使用 -e 选项: -e, --rsh=COMMAND 指定远端使用的shell命令
Use rsync -e ssh to specify which remote shell to use. In this case, rsync will use ssh. rsync -avz -e ssh thegeekstuff@192.168.200.10:/var/lib/rpm /root/temp Password: receiving file list ... done rpm/ rpm/Basenames sent 406 bytes received 15810230 bytes 2432405.54 bytes/sec total size is 45305958 speedup is 2.87
示例 7. 拷贝时不覆盖目标位置已修改过的文件
在一下特殊的使用场景中, 我们不希望拷贝文件时, 我们不希望拷贝过程覆盖掉目标位置中用户做出的修改. 这时我们需要使用 -u 选项明确的告诉rsync命令保留用户在目标文件中作出的修改. 在下面的例子中, 文件Basenames是用户基于上次的拷贝, 修改过的文件, 当我们使用了-u 选项后, 该文件中的修改将不会被覆盖掉.
ls -l /root/temp/Basenames total 39088 -rwxr-xr-x 1 root root 4096 Sep 2 11:35 Basenames
rsync -avzu thegeekstuff@192.168.200.10:/var/lib/rpm /root/temp Password: receiving file list ... done rpm/ sent 122 bytes received 505 bytes 114.00 bytes/sec total size is 45305958 speedup is 72258.31
ls -lrt total 39088 -rwxr-xr-x 1 root root 4096 Sep 2 11:35 Basenames
cron:定时任务管理器
cron是一种在Unix和类Unix操作系统中用于定时执行任务的程序。通过cron,用户可以安排脚本或命令在指定的时间和日期自动执行。这些计划任务称为cron jobs。
cron 系统基于cron daemon进行工作,这是一个持续运行的后台进程,它周期性地检查/etc/crontab文件、/etc/cron.*目录和/var/spool/cron或/var/spool/cron/crontabs目录下用户的个人crontab文件。
创建和编辑crontab文件:
要创建或编辑当前用户的crontab文件,请运行以下命令:
crontab -e
crontab 文件格式:
crontab文件中的每行都表示一个任务,格式如下:
* * * * * command-to-execute
这五个星号代表时间和日期的不同部分:
-
分钟(0-59)
-
小时(0-23)
-
日期(1-31)
-
月份(1-12 或 Jan,Feb,Mar等)
-
星期里的某天(0-7,其中0和7代表周日)
例子:
# 每晚的23:30重启Apache服务 30 23 * * * /etc/init.d/apache2 restart # 每周一的上午9点到下午5点,每小时的第15分钟执行脚本 15 09-17 * * 1 /path/to/script.sh # 每年1月1日的零点执行脚本 0 0 1 1 * /path/to/script.sh
星号可以被具体的数值或者-号分隔的范围替换,更复杂的时间计划可以使用,分隔的多个数值或/来指定步长。
列出crontab任务:
要列出当前用户的crontab文件中的所有任务,请使用:
crontab -l
删除crontab任务:
要删除当前用户的crontab文件中的所有任务,请使用:
crontab -r
注意: 请谨慎使用crontab -r,因为它将删除所有已安排的任务。
压缩解压类
zip和unzip
在Unix和类Unix系统中,zip和unzip是两个常见的命令,用于文件的压缩和解压缩。
使用zip压缩文件或目录:
zip [options] [zipfile] [file1] [file2] ...
-
[options]:是可选参数,比如-r表示递归处理,将指定目录下的所有文件和子目录一并压缩。 -
[zipfile]:是压缩后生成的文件名。 -
[file1] [file2] ...:是要压缩的文件列表。
例如,要将Documents目录压缩成名为archive.zip的压缩文件,使用:
zip -r archive.zip Documents/
使用unzip解压缩文件:
unzip [options] [zipfile]
-
[options]:是可选参数,如-d用来指定解压缩后文件的目录。 -
[zipfile]:是要解压的.zip文件。
例如,要解压archive.zip到当前目录,使用:
unzip archive.zip
要解压archive.zip到指定的目录/path/to/directory,可以使用
unzip archive.zip -d /path/to/directory
常用的zip选项:
-
-r:递归地包含目录,压缩目录及所有子目录和文件。 -
-m:在压缩后从磁盘上删除原文件。 -
-q:安静模式,不显示加压缩和解压缩的详细过程。 -
-e:创建加密的压缩文件。
常用的unzip选项:
-
-l:列出压缩文件里的内容,但不解压。 -
-o:覆盖现有的文件而不提示。 -
-v:显示详细信息,但不是仅仅显示列表。 -
-p:将文件解压到标准输出,通常与管道命令一起使用。
gzip:压缩文件
gzip(GNU zip)是一个用于文件压缩的程序,在Unix和类Unix操作系统中广泛使用。它通常用于减少文件的大小,从而节省磁盘空间或减少网络传输的时间。gzip仅能用于压缩单个文件,而不是整个目录。如果需要压缩目录,通常会先使用tar打包成一个文件,然后再用gzip进行压缩。
gzip filename
使用这个命令将filename文件压缩后,原文件会被压缩并替换为一个新的文件名filename.gz,原始文件则会被删除。
查看gzip压缩文件的内容:
gzip -l filename.gz
-l选项(list的缩写)允许你查看压缩文件的压缩比,未压缩大小等信息。
解压gzip文件:
gunzip filename.gz
或者
gzip -d filename.gz
gunzip是gzip -d的别名,都可以用来解压.gz文件。解压后,.gz文件会被删除,原来的文件会恢复到压缩前的状态。
保留原始文件:
gzip -c filename > filename.gz
或者
gzip -k filename
-c选项会将输出写到标准输出,通常和重定向操作符一起使用。-k(keep的缩写)选项会压缩文件到.gz格式,并保留原始文件。
指定压缩等级:
gzip -9 filename
-9表示最大压缩率,但同时也会占用更多的处理时间,gzip支持从-1(最快压缩,压缩比最低)到-9(最慢压缩,压缩比最高)的压缩等级。
使用gzip压缩tar文件:
tar cvf - directory | gzip > directory.tar.gz
以上命令会创建一个名为directory.tar.gz的压缩包,包含了directory目录下的所有文件和子目录。
gunzip:解压缩文件
gunzip是一个广泛应用于Unix和类Unix操作系统的命令,它用来解压缩由gzip程序压缩的文件。gunzip实际上是gzip -d的简写形式,其中-d参数代表解压缩(decompress)。
gunzip filename.gz
这里,filename.gz是要解压的文件。执行gunzip命令后,它会去掉.gz压缩文件扩展名,并恢复文件到压缩前的状态。filename.gz文件解压后,将会从磁盘上删除,只留下解压缩出来的文件。
要保留原始的.gz压缩文件,可以使用-c参数,并将解压缩的内容通过重定向输出到文件:
gunzip -c filename.gz > filename
解压缩多个文件:
gunzip *.gz
用星号*作为文件名的通配符,可以一次性解压缩当前目录下所有的.gz文件。
使用-v参数可以显示解压缩过程中的详细信息:
gunzip -v filename.gz
-v参数(verbose的缩写)将增加命令的冗长性,显示额外的信息,比如每个文件的压缩比和解压缩后释放出的字节数。
使用-r参数可以递归地解压缩目录中的文件:
gunzip -r directory
这个命令会搜索directory目录下所有的.gz文件,并解压缩它们。
tar:打包和解压文件
tar是一个强大的命令行工具,通常用于Unix和类Unix操作系统中,用于创建、维护、提取和操作归档文件(通常称为tarballs)。tar可以将许多文件合并成一个大文件,便于储存和传输,同时它也可以与压缩工具如gzip和bzip2结合使用,进一步减小归档文件的大小。
创建tar归档:
tar -cf archive.tar file1 file2 dir1
这里-c表示创建一个归档文件,-f后跟要创建的归档文件名。你可以在命令中添加任何数量的文件或目录,它们将被添加到归档文件中。
查看tar归档内容:
tar -tf archive.tar
-t选项用于列出tar归档中的内容而不解压归档。
解压tar归档:
tar -xf archive.tar
-x表示解压归档,-f后面跟归档的名称。这将在当前目录解压归档。
创建并压缩tar归档使用gzip:
tar -czf archive.tar.gz directory
-c表示创建归档,-z表示使用gzip压缩,-f用于指定归档文件的名称,此命令将整个目录压缩成.tar.gz文件。
解压gzip压缩的tar归档:
tar -xzf archive.tar.gz
-x表示解压归档,-z表示需使用gzip解压,-f后面跟.gz归档的名称。
创建并压缩tar归档使用bzip2:
tar -cjf archive.tar.bz2 directory
-j选项指示tar使用bzip2来压缩文件。
解压bzip2压缩的tar归档:
tar -xjf archive.tar.bz2
这行命令将.bz2归档解压到当前目录。
zip,unzip,gzip,gunzip,tar对比
相同点:
-
归档能力:
tar和zip都能将多个文件和目录打包成单个文件,以便于管理和传输。 -
压缩:
gzip、zip同样可以用来减少文件大小(tar本身不压缩,但经常与gzip或其他压缩工具配合使用)。 -
命令行工具: 这些工具都通过命令行界面使用。
-
自动替换: 在压缩时,
gzip和zip默认情况下替换原文件;gunzip和unzip在解压时替换压缩文件。
区别:
-
文件格式:
zip创建.zip文件,gzip创建.gz文件,而tar创建.tar文件(未压缩)。命令结合使用时(tar与gzip)通常创建.tar.gz或.tgz文件。 -
压缩算法: 每种命令使用不同的压缩算法。
gzip相较于zip,通常能提供更好的压缩比,尤其是在与tar结合使用时。 -
多文件支持:
gzip只能压缩单个文件。要压缩多个文件或目录,需要先用tar打包,再用gzip压缩。而zip可以直接压缩多个文件和目录,无需打包。 -
压缩和解压:
gzip用于压缩,gunzip用于解压(它们俩本质上是同一个程序)。zip用于压缩,unzip用于解压。 -
平台通用性:
zip和unzip由于其良好的跨平台性,文件格式在Windows系统中也广泛支持,而gzip、gunzip和tar更常见于Unix-like系统。 -
支持的功能:
tar操作单纯实现归档,不进行压缩(除非和gzip一起使用),而zip同时支持归档和压缩。 -
解压缩: 解压缩时,
unzip可以解压zip文件,gunzip可以解压.gz文件。而且tar命令常与-z参数一起使用来解压.tar.gz或.tgz文件。
这些工具经常在脚本和自动化任务中使用,根据需要的特点选择最合适的工具。例如,若需要跨平台兼容性,则倾向选择zip/unzip;若需要高压缩率,则可能选用tar配
标准输出、错误输出、重定向
在计算机术语中,标准输出(stdout)和标准错误(stderr)是操作系统提供的两个预定义的输出渠道,通常被用于显示命令行程序的输出结果。
标准输出(stdout):
-
这是程序输出数据的主要途径。
-
通常情况下,stdout被连接到终端窗口,直接显示命令的输出。
-
在编程语言中,如Python的
print()函数、C语言的printf()函数会输出内容到stdout。
标准错误(stderr):
-
专门用于输出错误消息和诊断信息。
-
默认情况下,stderr 也被连接到终端窗口,即使stdout被重定向,stderr也能保证错误信息能被及时输出和查看。
-
在很多编程语言中,有专门的语句或函数向stderr发送输出,如在Python里可以使用
sys.stderr.write()。
重定向(Redirection):
-
重定向是一种改变数据流方向的过程,可以将命令的输出从默认的地方(如控制台)转移到别处,比如文件或者其他设备。
-
使用操作符
>可以将stdout重定向到一个文件中,如command > file将会覆盖文件里的内容,如果文件不存在则会创建一个新文件。 -
使用操作符
>>可以将stdout附加到一个文件尾部,如command >> file。 -
使用操作符
2>可以重定向stderr到一个指定的文件,如command 2> error_file。 -
若要同时重定向stdout和stderr到同一个文件,可以使用
&>,如command &> file。
例如:
# 将标准输出重定向到outfile.txt ls -l > outfile.txt # 将错误输出重定向到errfile.txt ls -l 2> errfile.txt # 将标准输出和错误输出都重定向到同一个文件中 ls -l > outfile.txt 2>&1 # 将标准输出和错误输出都重定向到同一个文件中的另一种写法 ls -l &> outerrfile.txt
管道(Pipes):
-
管道是一个高级的重定向方式,允许将一个命令的stdout直接作为另一个命令的stdin。
-
使用管道符
|连接两个命令,如command1 | command2。
例如,以下命令会找出当前目录下的.txt文件数量:
ls -l | grep '.txt$' | wc -l
上面的命令流程是:ls -l产生当前目录的文件列表;grep '.txt$'检索所有以.txt结尾的行;wc -l统计所筛选出的行数,也就是.txt文件的数量。
FlowUs 息流 - 新一代生产力工具 【FlowUs 息流】Linux指令练习















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









