






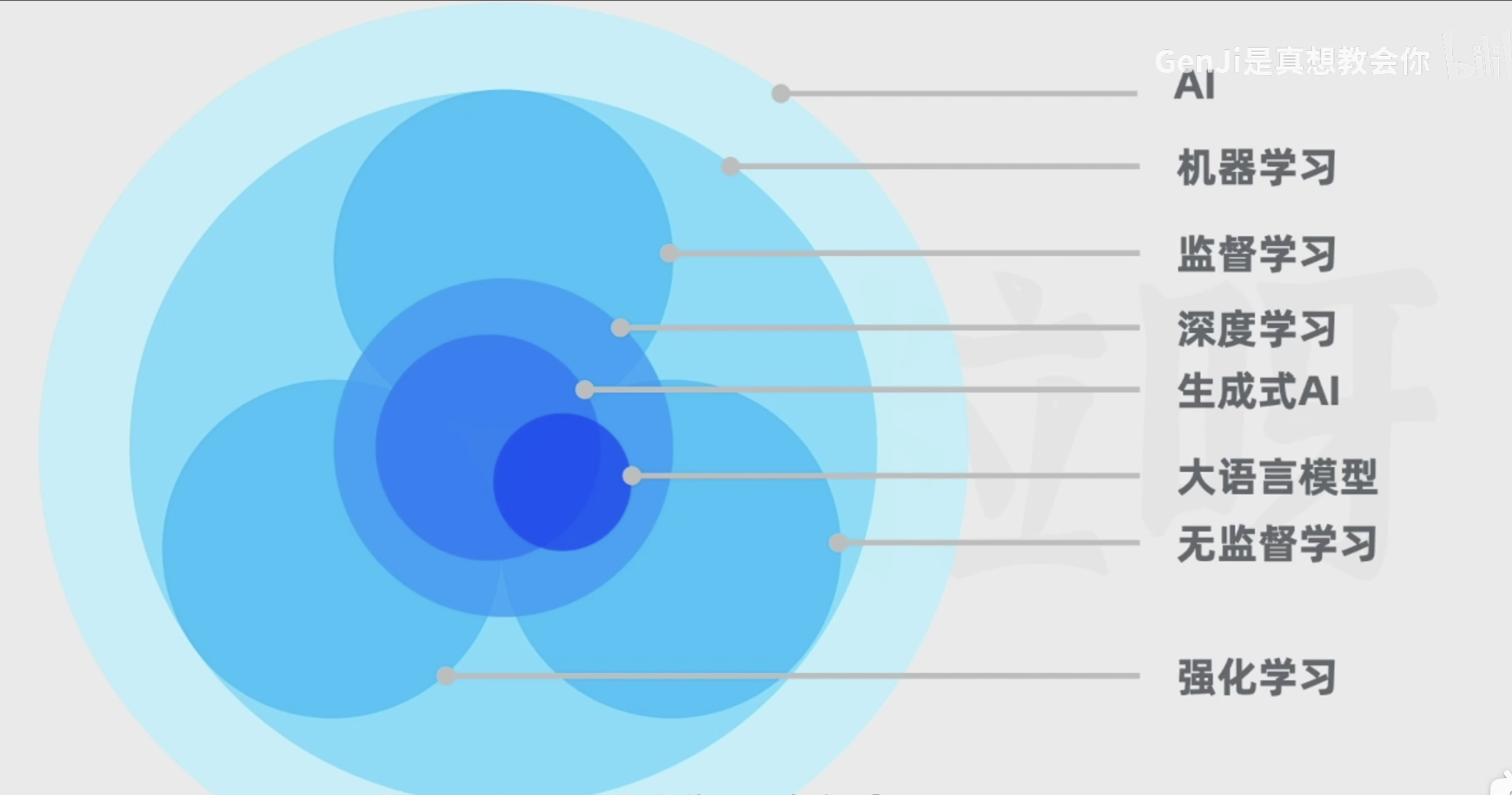
生成式ai生成内容就为AIGC

1. 监督学习
1.1概述:
- 监督学习是指模型在有标签的数据集上进行训练,以学习从输入到输出的映射关系。数据集中每个样本都包含一个或多个特征(输入)和一个目标变量(标签/输出)。
1.2 任务类型
- 分类:根据输入特征预测离散的类别标签。例如,垃圾邮件分类(垃圾邮件/非垃圾邮件)、图像识别(猫/狗/汽车等)。
- 回归:根据输入特征预测连续的数值。例如,房价预测、股票价格预测。
1.3 常用算法
- 线性回归
- 逻辑回归
- 决策树
- 支持向量机
- K近邻算法
- 神经网络
1.4 特点
- 需要大量带标签的数据进行训练
- 学习过程由输入特征和已知标签共同决定
2. 非监督学习
2.1 概述
- 非监督学习是指模型在没有标签的数据集上进行训练,目标是从数据中发现隐藏的结构或模式。数据集仅包含特征,没有目标变量(标签)。
2.2 任务类型
- 聚类:将数据分组,使得同一组内的数据点具有较高的相似性。例如,客户分群、图像聚类。
- 降维:将高维数据转换到低维空间,保留数据的主要特征。例如,主成分分析(PCA)、t-SNE。
- 异常检测:识别数据集中异常或离群点。例如,金融欺诈检测、网络入侵检测。
2.3 常用算法
- K-means 聚类(K-means Clustering)
- 层次聚类(Hierarchical Clustering)
- 主成分分析(PCA, Principal Component Analysis)
- 自编码器(Autoencoder)
- 孤立森林(Isolation Forest)
2.4 特点
- 无需标签数据,仅依赖数据的内部结构进行学习
- 常用于数据预处理、探索性数据分析和特征工程
3. 强化学习
3.1 概述
- 强化学习是指通过和环境交互,在试错过程中学习策略,以最大化其累积奖励。学习过程基于奖励和惩罚,不需要预定义的标签。
3.2 任务类型
- 策略优化:选择最优行动策略以最大化累积奖励。例如,游戏AI、机器人控制、自动驾驶。
3.3 核运行模式
- 环境:学习系统所处的环境,提供状态信息并反馈奖励。
- 智能体:在环境中执行动作并接收反馈,目的是学习如何通过行动最大化累计奖励。
- 状态:环境的某一刻状态信息。
- 动作:智能体可以采取的操作。
- 奖励:智能体行动后环境给出的反馈信号,正值/负值表示奖励/惩罚。
- 策略:智能体选择动作的策略,定义了在各个状态下采取的行动。
3.4 常用算法
- Q学习(Q-Learning)
- 深度Q网络(DQN, Deep Q-Network)
- 策略梯度方法(Policy Gradient Methods)
- Actor-Critic 方法
3.5 特点
- 需要很多的尝试和探索来学习最优策略
- 与环境持续交互,学习过程不断调整
4. 区别总结
- 数据使用方式:
- 监督学习:使用带标签的训练数据。
- 非监督学习:使用未带标签的数据。
- 强化学习:通过环境反馈信号学习策略,不需要标签。
- 任务目标:
- 监督学习:预测已知标签。
- 非监督学习:发现数据内部结构。
- 强化学习:最大化累计奖励。
- 应用场景:
- 监督学习:分类、回归、检测等。
- 非监督学习:聚类、降维、探索性分析、异常检测等。
- 强化学习:游戏、机器人控制、策略优化等。
- 学习过程:
- 监督学习:依赖于事先标注好的训练数据集。
- 非监督学习:数据自带隐含结构,模型需自行发现。
- 强化学习:需要和动态环境交互,基于奖励信号调整策略。
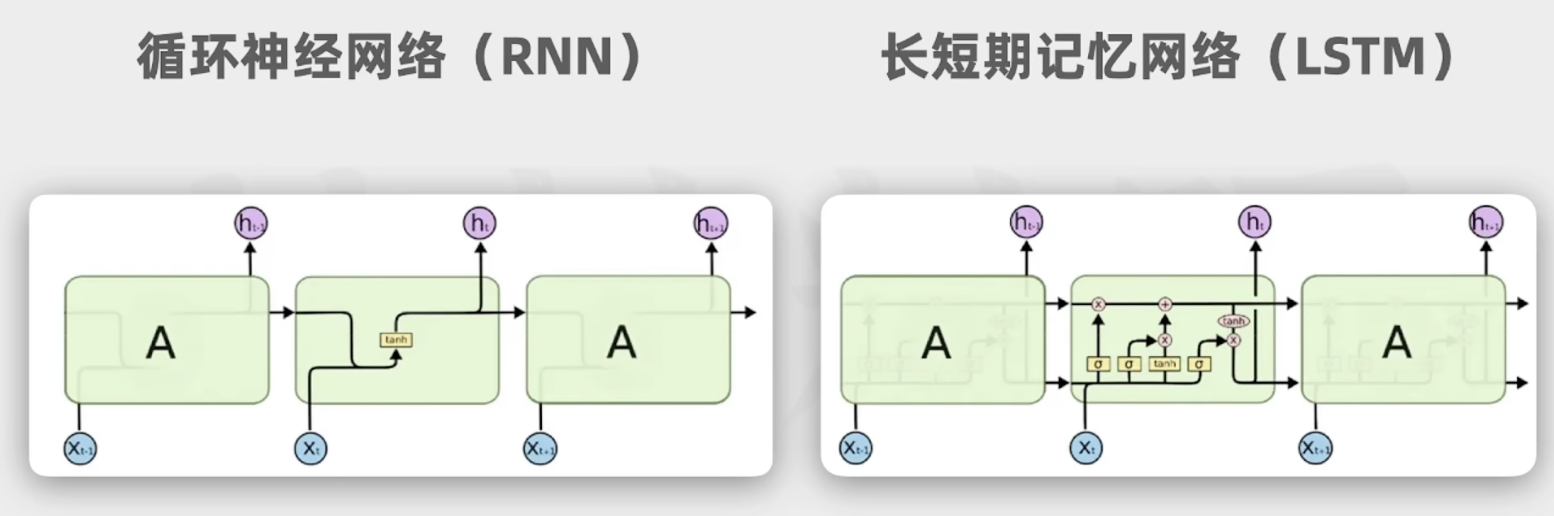
**递归神经网络(RNN)**是一类用于处理序列数据的神经网络,它通过循环连接保存前一时刻的状态信息,从而捕捉数据中的时间依赖性。这种特性使RNN特别适合应用于需要记忆之前输入信息的任务,例如语言翻译、语音识别、时间序列预测等。

5 RNN的优缺点
5.1优点
- 捕捉时间依赖:可以处理序列数据,记住之前的输入信息,适合处理时间序列、文本等序列性数据。
- 共享参数:在不同时间步共享同一组参数,减少了模型参数的数量。
5.2 缺点
- 梯度消失和爆炸:在长序列中训练RNN时,反向传播中的梯度可能会消失或爆炸,影响训练效果。梯度消失会导致远距离时间依赖信息难以捕获。
- 计算复杂度高:RNN的计算依赖于上一个时间步的状态,计算复杂度较高,训练时间较长。
- 难以并行计算:由于当前时间步计算依赖于前一个时间步,难以进行并行计算,限制了计算效率。
为了克服RNN的一些缺点,如梯度消失和爆炸问题,出现了一些变种和改进:
6. Transformers:
- Transformers 是近年来在自然语言处理(NLP)以及其他序列数据任务中取得巨大成功的一种模型架构。
- 他解决了前面RNN不擅长处理长序列的问题,词之间距离越远,前面的词对后面的词影响越低。难以捕获长距离语句之间的关系。他会学习语句里所有词之间的关系,他并不只关注输入和距离自己进的词,而是关注输入中所有的值,至于这个权重是通过学习得到的。能做做到这点就在于他的自注意机制
6.1 优点
- 高效处理长距离依赖:通过自注意力机制,能够高效捕捉序列中任意两个位置之间的关系。
- 并行计算:Transformers 允许序列中所有位置同时计算,提高了训练和推理效率,传输给神经网络时讲这个词在序列中的位置一并传输。
- 扩展性强:可以很容易堆叠更多的编码器和解码器层,以处理更复杂的任务。
6.2 缺点
- 计算资源需求高:对于长序列,自注意力机制的计算量是序列长度的平方级,资源消耗大。
- 占用显存多:在大型模型和长序列上,显存使用量可能非常大。
- 较弱的局部特征捕捉能力:对于局部特征的捕捉可能不如卷积神经网络(CNN)直接有效。
7. 得到一个CPT
- 架构设计:基于Transformer解码器,包含位置编码、多头自注意力机制、前馈神经网络及层归一化。
- 训练过程:
- 预训练:在大规模无标签文本数据上进行预训练,目的是预测下一个词。
- 微调:在特定任务的数据集上进行微调,适应各种具体任务。
- 生成和应用:经过训练后的GPT可以用于文本生成、情感分析、问答系统等多种NLP任务。




8. GPT的使用小技巧




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











