






事务的概念与ACID特性
Redis事务
Redis事务是一组命令的集合,一个事务中的所有命令都将被序列化,按照一次性、顺序性、排他性的执行一系列的命令。

Redis事务三大特性
- 单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断;
- 没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”。
- 不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚;
Redis事务执行的三个阶段
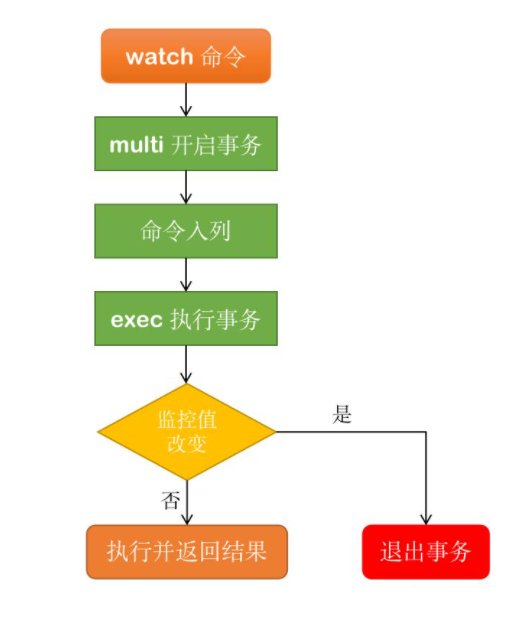
- 开启:以
MULTI开始一个事务; - 入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面;
- 执行:由
EXEC命令触发事务;
事务基本操作
Multi、Exec、discard
事务从输入Multi命令开始,输入的命令都会依次压入命令缓冲队列中,并不会执行,直到输入Exec后,Redis会将之前的命令缓冲队列中的命令依次执行。组队过程中,可以通过discard来放弃组队。
开启一个事务(可以先删除之前数据flushall):MULTI
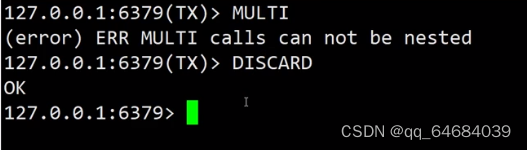
设置数据并提交数据:exec

注意:
1.命令集合中含有错误的指令(注意是语法错误),均连坐,全部失败。
2.运行时错误,即非语法错误,正确命令都会执行,错误命令返回错误。
Redis集群_主从复制
面临问题:
- 机器故障。我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的。
- 容量瓶颈。当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了。当然,你可以重新买个 128G 的新机器。
解决:
将原来集中式数据库的数据分别存储到其他多个网络节点上。
注意:
Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份从而保证数据和服务的高可用。
什么是主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制环境搭建
1.先停掉原本服务
lsof -i:6379
kill -9 服务的id
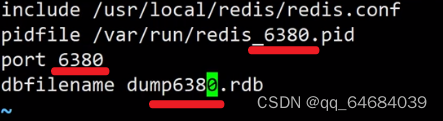
2.redis中编写配置文件redis6379.conf
include /usr/local/redis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
3.拷贝配置文件

redis中有三个配置文件
此时启动不同的文件服务
4.修改不同配置文件(80,81)中的端口号
eg:6380中修改
5.通过不同文件启动不同服务

6.查看是否成功启动

7.打开两个新窗口连接不同服务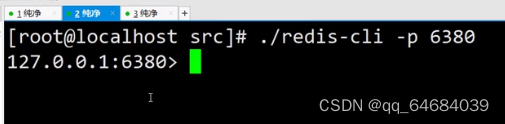
8.分别配置从库(80,81)服从主库(主库79不需要配置)

9.查看各机器信息:info replication
79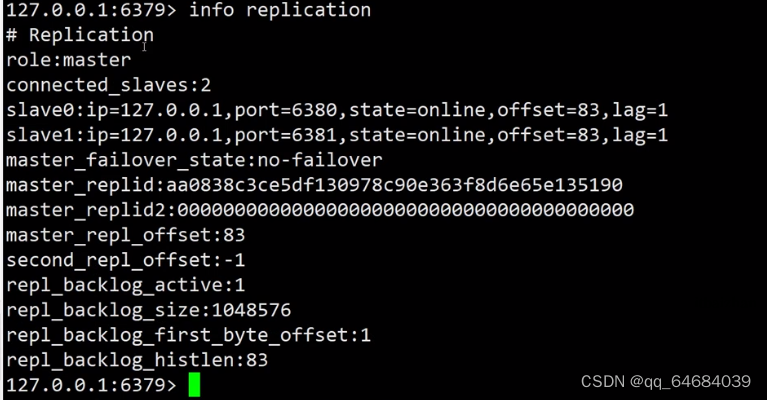
81
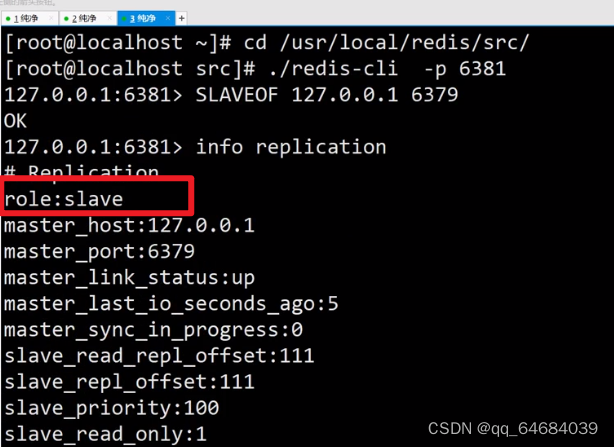
10.主节点中创建保存数据,从节点的数据可以读取
主从复制原理剖析
复制过程大致分为6个过程

主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。
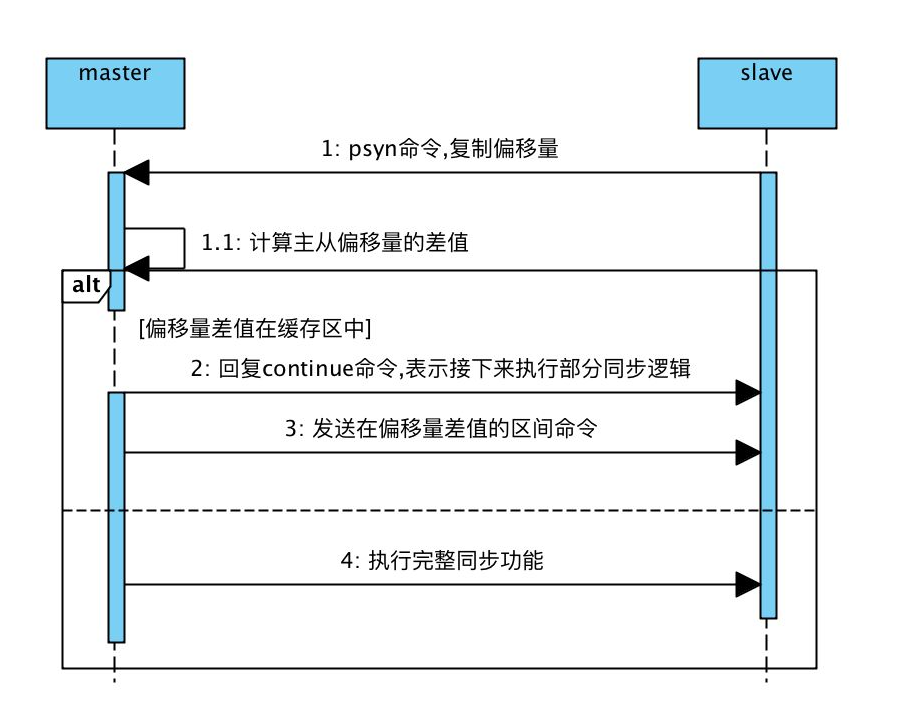
偏移量offset相同说明主从机器数据已经同步
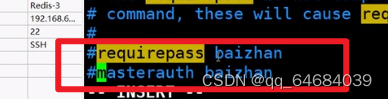
redis设置密码:requirepass
redis刚进行主从连接时,进行的是全量同步
哨兵监控
主机宕机后,只能手动切换从节点升级。考虑哨兵模式自动切换。
原理:哨兵通过发送命令等待redis服务器响应,从而监控reids运行的多个实例。

哨兵作用
- 集群监控:负责监控redis master和slave进程是否正常工作
- 消息通知:如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果master node挂掉了,会自动转移到slave node上
- 配置中心:如果故障转移发生了,通知client客户端新的master地址
哨兵模式解决主从切换问题
配置哨兵监控
搭建三台哨兵监控(集群奇数为例)
redis中创建配置文件:vim sentinel-26379.conf
#端口
port 26379
#守护进程运行
daemonize yes
#日志文件
logfile "26379.log"
sentinel monitor mymaster 127.0.0.1 6379 2
参数:
sentinel monitor mymaster 192.168.92.128 6379 2 配置的含义是:该哨兵节点监控192.168.92.128:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移。
复制配置文件分别为80,81,并修改端口,最后只需要监控主节点79
#端口
port 26380
#守护进程运行
daemonize yes
#日志文件
logfile "26380.log"
sentinel monitor mymaster 127.0.0.1 6379 2
哨兵启动
redis-sentinel sentinel-26379.conf
查看哨兵节点状态
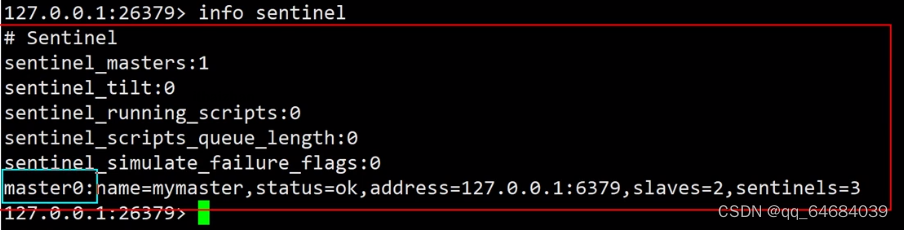
哨兵监控原理
监控阶段-通知阶段-故障转移阶段-投票方式
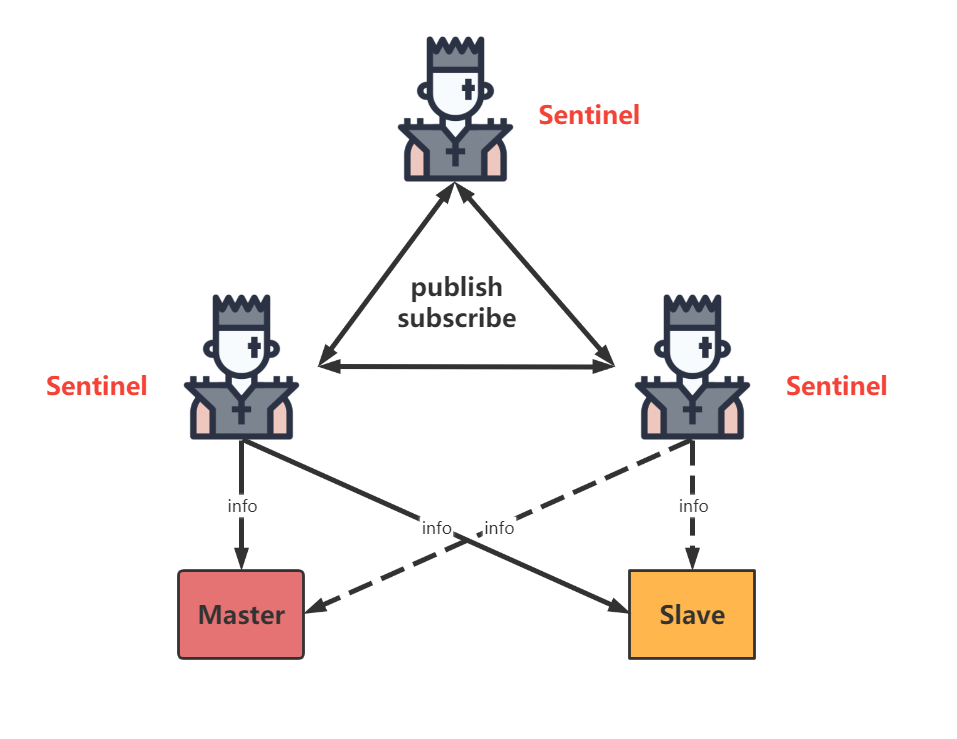
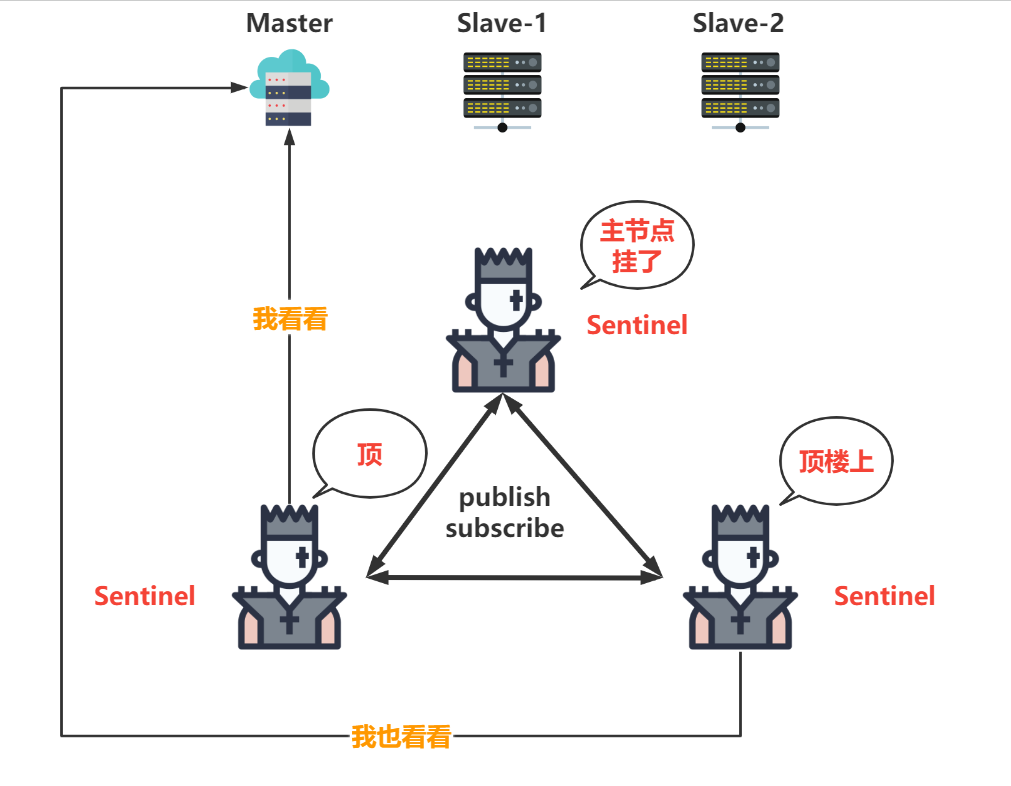
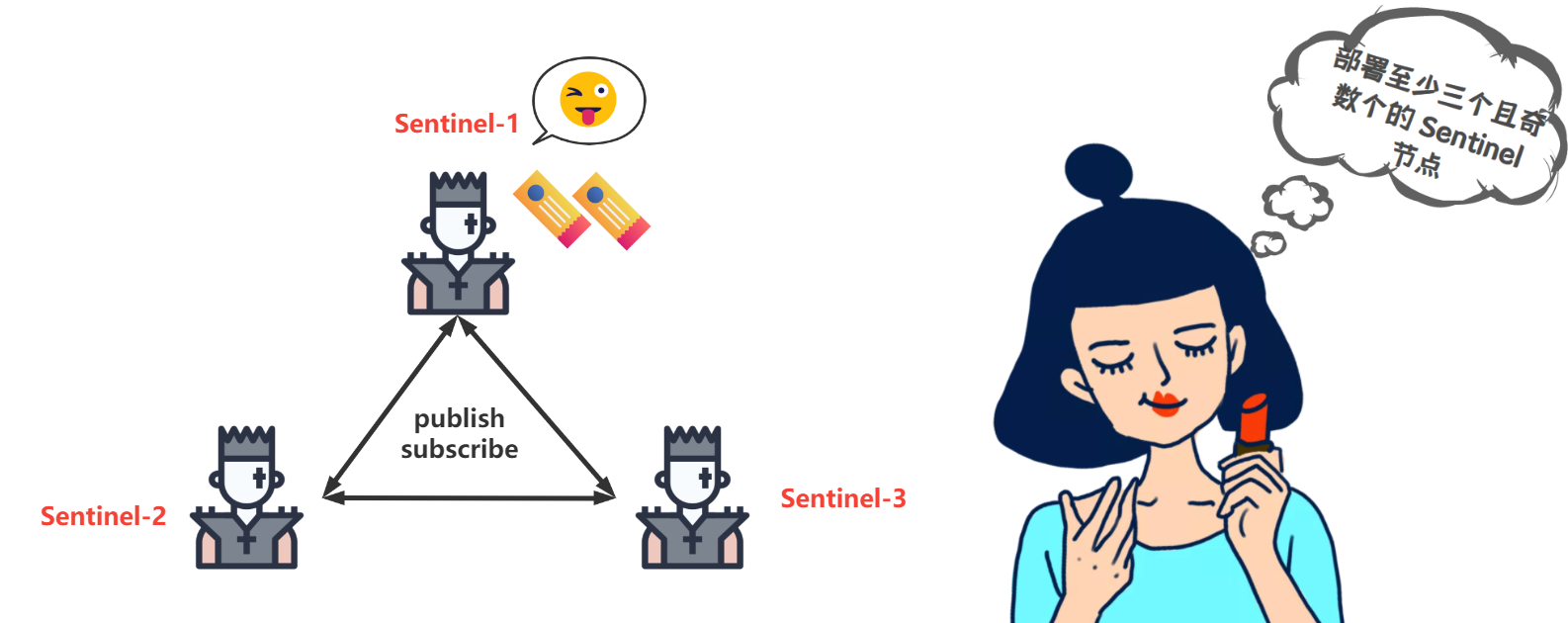
redis哨兵模式是一种高可用的架构
哨兵监控故障转移
杀掉掉79服务类似主机宕机:kill -9 主机id
此时无法连接主机79
哨兵会自动切换
连接查看,主机切换为80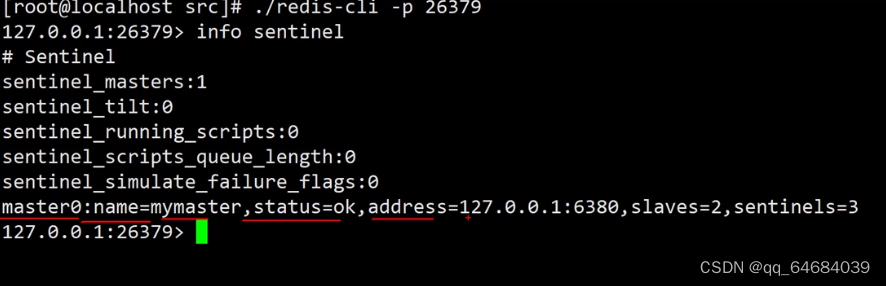
注意:
会发现主节点还没有切换过来,因为哨兵发现主节点故障并转移,需要一段时间。
重启6379节点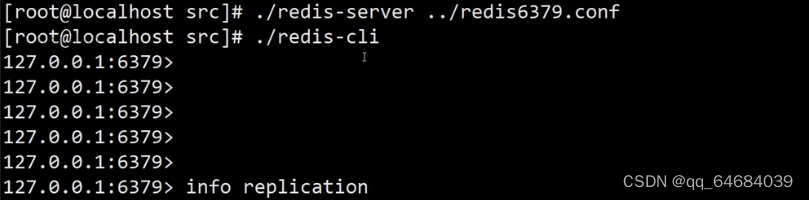
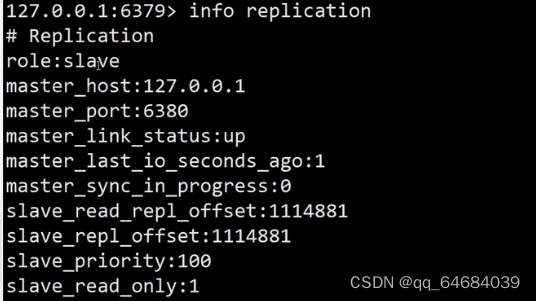
故障转移后,配置文件和主机都被修改
结论
- 哨兵系统中的主从节点,与普通的主从节点并没有什么区别,故障发现和转移是由哨兵来控制和完成的。
- 哨兵节点本质上是redis节点。
- 每个哨兵节点,只需要配置监控主节点,便可以自动发现其他的哨兵节点和从节点。
- 在哨兵节点启动和故障转移阶段,各个节点的配置文件会被重写(config rewrite)。
Cluster模式概述
redis三种集群模式:主从,sentinel,cluster
哨兵模式存在问题:
1.选举阶段redis无法提供服务,存在访问瞬断问题。
2.对外只有主节点可以写,从节点只读。主节点压力增加。
3.redis单节点内存不能过大,否则主从同步速度变慢。
采用cluster
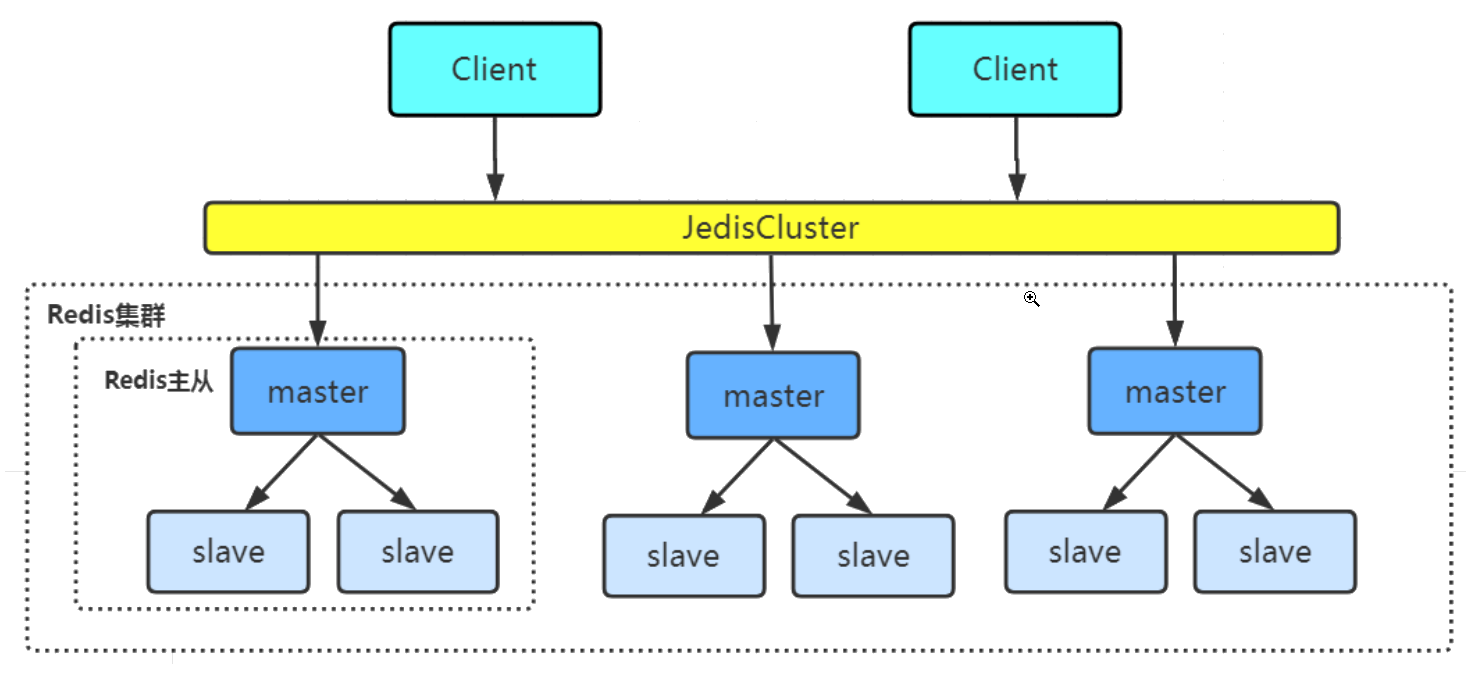
redis集群有多个主从节点群组成的分布式服务集群,具有复制,高可用和分片特性。
Cluster模式搭建
需要至少3个主节点
环境准备
第1台机器: 192.168.66.101 8001端口 8002端口
第2台机器: 192.168.66.102 8001端口 8002端口
第3台机器: 192.168.66.103 8001端口 8002端口
发送到所有回话
在三台机器中安装redis
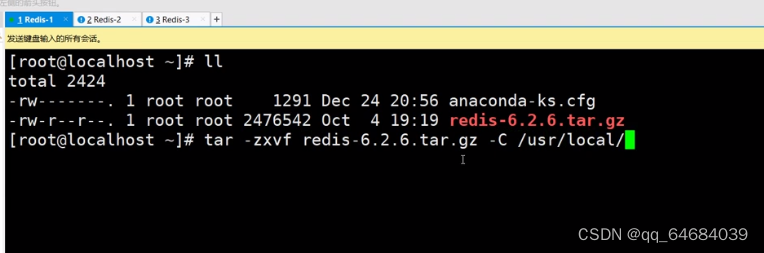
进入redids进行编译:make
安装:make install
重命名文件为redis

在redis中创建文件夹并创建配置文件夹
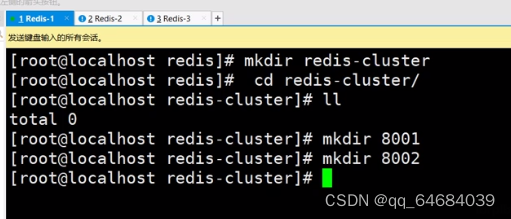
复制文件到8001

进入8001修改配置文件
1.端口号:8001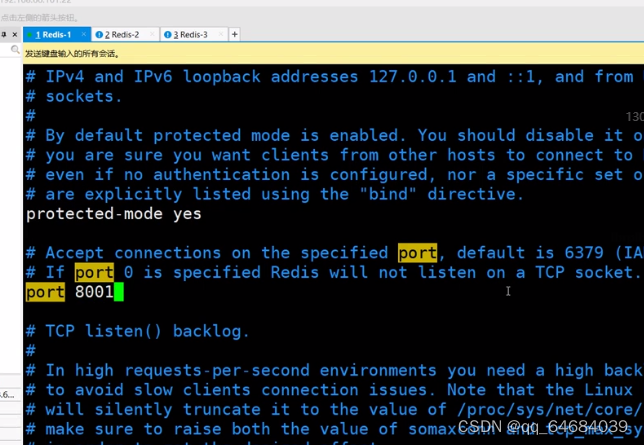
2.开启保护模式daemonize
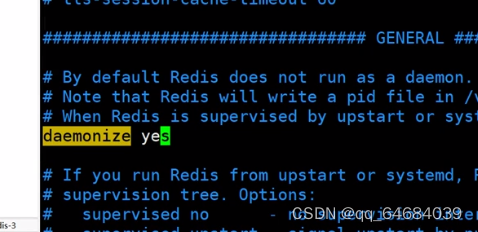
3.修改pidfile路径
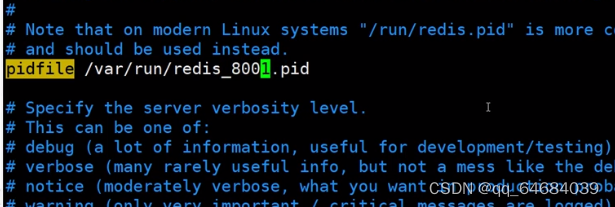
4.指定数据文件的存放位置,必须到指定不同的目录位置,否则丢失文件数据

5.打开cluster的集群模式

6.集群节点信息文件

7.节点离线的超时时间

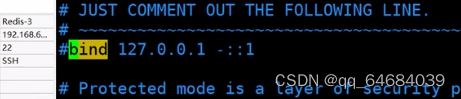
8.注释本地绑定
9.关闭保护模式

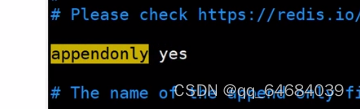
10.开启appendonly
11.根据需要配置密码(这里不设置密码)
修改8002:复制8001的文件到8002
利用一键替换的命令修改8002的配置文件(g为全局修改的意思)
![]()
注意关闭防火墙
启动每一台服务
查看服务

发送到当前会话创建集群:(如果设置了密码需要添加命令:-a 密码名)

参数:
- -a:密码
- --cluster-replicas 1:表示1个master下挂1个slave; --cluster-replicas 2:表示1个master下挂2个slave。
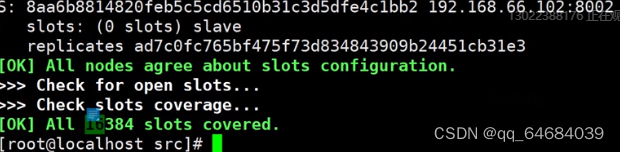
创建成功
寻求帮助
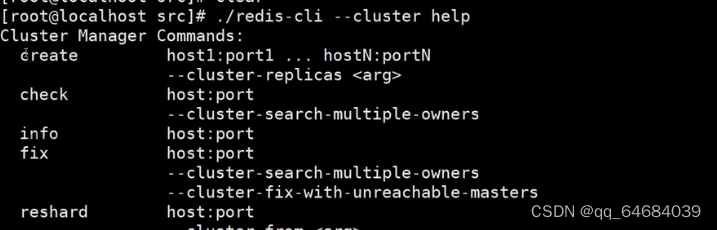
参数:
- create:创建一个集群环境host1:port1 ... hostN:portN
- call:可以执行redis命令
- add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
- del-node:移除一个节点
- reshard:重新分片
- check:检查集群状态
验证集群
连接任意一个客户端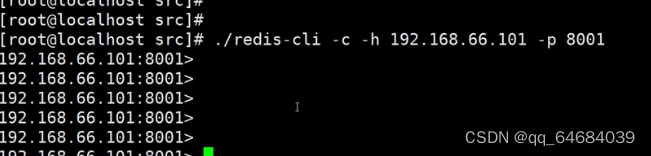
参数:
- ‐a表示服务端密码
- ‐c表示集群模式
- -h指定ip地址
- -p表示端口号
查看集群状态信息
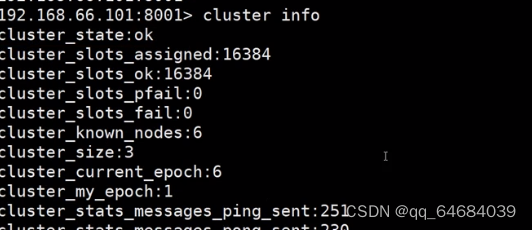
Cluster模式原理
Redis Cluster将所有数据划分为16384个slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。只有master节点会被分配槽位,slave节点不会分配槽位。
槽位定位算法: k1 = 127001
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH_SLOT = CRC16(key) % 16384
测试可以通过{}来定义组的概念,从而是key中{}内相同内容的键值对放到同一个slot中。
故障恢复
查看节点:192.168.66.103:8001> cluster nodes
杀死Master节点
lsof -i:8001
kill -9 pid
java操作redis集群
在之前创建的项目中添加一个测试类
@Test
public class clusterTest {
//构建set集合保存redis node
Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();
jedisClusterNode.add(new HostAndPort("192.168.66.101", 8001));
jedisClusterNode.add(new HostAndPort("192.168.66.102", 8001));
jedisClusterNode.add(new HostAndPort("192.168.66.103", 8001));
jedisClusterNode.add(new HostAndPort("192.168.66.101", 8002));
jedisClusterNode.add(new HostAndPort("192.168.66.102", 8002));
jedisClusterNode.add(new HostAndPort("192.168.66.103", 8002));
//构建Jediscluster实例,建立连接
JedisCluster jedisCluster = new JedisCluster(reidsNodes);
jedisCluster.set("name","baizhan");
//jedisCluster.get("name");
//System.out.println(name);
}
再创建一个SpringBoot项目

配置文件
##单服务器
spring.redis.cluster.nodes=192.168.202.101:8001,192.168.202.102:8001,192.168.202.103:8001,192.168.202.101:8002,192.168.202.102:8002,192.168.202.103:8002
## 连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=300
## Redis数据库索引(默认为0)
spring.redis.database=0
## 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
## 连接池中的最大空闲连接
spring.redis.pool.max-idle=100
## 连接池中的最小空闲连接
spring.redis.pool.min-idle=20
## 连接超时时间(毫秒)
spring.redis.timeout=60000
测试类操作
















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









