






非结构化数据
格式和长度不固定的数据。
全文检索
一种非结构化数据的搜索方式。
索引
例如将字典中字的拼音提取出来做成目录。
正排索引(正向索引)
文档id建立为索引,数据库中主键会创建爱你正排索引。
倒排索引(反向索引)
将数据中的关键词建立为索引,指向文档数据。
Elasticsearch本质
是一个java语言开发的web项目
应用场景
全站搜索。
维基百科以es为基础的核心搜索架构。
新浪使用es分析处理32亿条实时日志。
对比Solr
solr利用zookeeper进行分布式管理。
es只支持json文件格式。
solr高级功能多由第三方插件提供。
es处理实时搜索效率更高。
es数据结构
文档:可以被查询的最小数据单元。类似关系型数据库中记录的概念。
类型:类似于关系型数据库中数据表的概念。
索引:类似于关系型数据库中库的概念。
域:类似于关系型数据库中字段的概念。---->表
注:ES7.X之后删除了type的概念,一个索引不会代表一个库,而是代表一张表。我们课程中使用ES7.17,所以目前的ES中概念对比为:
| JAVA | 项目 | 实体类 | 对象 | 属性 |
|---|---|---|---|---|
| ES | Index | Document | Filed | |
| Mysql | Database | Table | Row | Column |
安装es服务
准备一台全新的虚拟机(es)
配置IP地址为192.168.0.187
减少卡顿可以在shell中关闭转发连接

关闭防火墙
systemctl stop firewalld.service
禁止防火墙自启动
systemctl disable firewalld.service
配置可创建文件数大小(由于linux自带可创建的文件数量太少,故需要手动修改配置)
打开系统文件
vim /etc/sysctl.conf
添加配置
vm.max_map_count=655360

配置生效
sysctl -p

由于es不能以root用户运行,所以创建一个es用户
useradd es
安装es服务
上传es文件
![]()
解压文件

修改文件名

移动文件到/usr/local下
![]()
创建es用户权限并以es用户进行操作
![]()
启动es服务

默认端口是9200,执行命令启动成功
安装kibana(可视化窗口)
对es数据可视化进行搜索查看,交互操作。
上传kibana文件
![]()
解压文件
tar -zxvf kibana-7.17.0-linux-x86_64.tar.gz -C /usr/local/
修改配置文件

注意空格

创建es访问kibana的权限并切换es用户

启动kibana服务

默认端口:5601
网页访问kibana:192.168.202.187:5601
如果报错堆栈内存不足:
修改配置文件

查看连接状态

docker安装
# 安装Docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
# 启动docker
systemctl start docker
拉取镜像
docker pull elasticsearch:7.17.0
启动容器
# docker容器间建立通信
docker network create elastic

# 创建es容器
docker run --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name='elasticsearch' --net elastic --cpuset-cpus="1" -m 1G -d elasticsearch:7.17.0

安装Kibana
拉取镜像
docker pull kibana:7.17.0
启动容器
docker run --name kibana --net elastic --link elasticsearch:elasticsearch -p 5601:5601 -d kibana:7.17.0
访问kibana:
http://192.168.202.187:5601

es的常用操作
索引操作
文档操作
域的属性
索引操作

创建一个空索引student

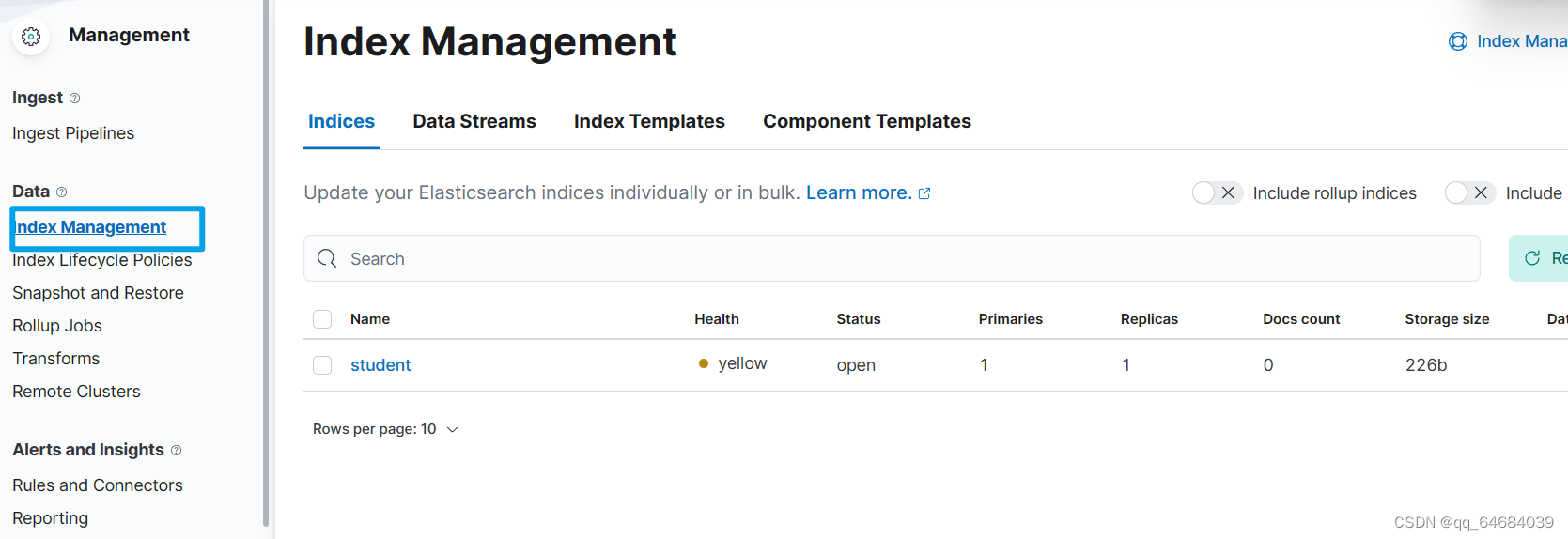
为该索引添加结构
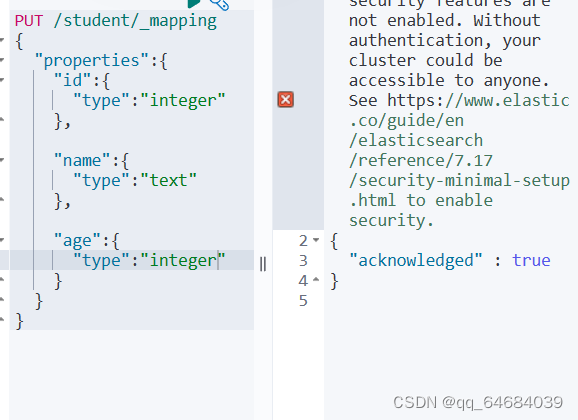

es是RESTful风格的HTTP请求
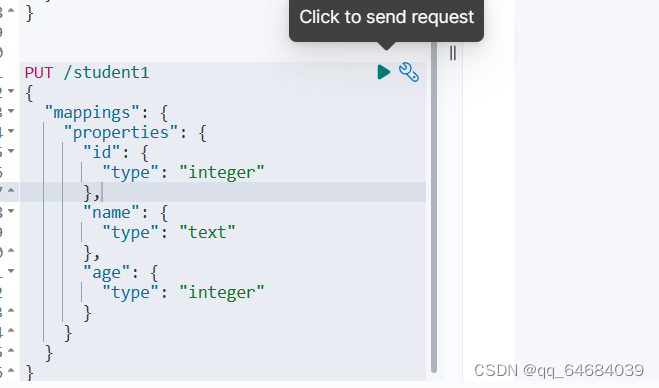
直接创建有结构的索引(自动整理格式)
注意添加“mappings”

删除索引
delete /索引名

文档操作
没有id值是会自动生成

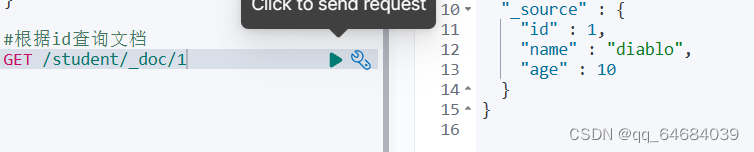
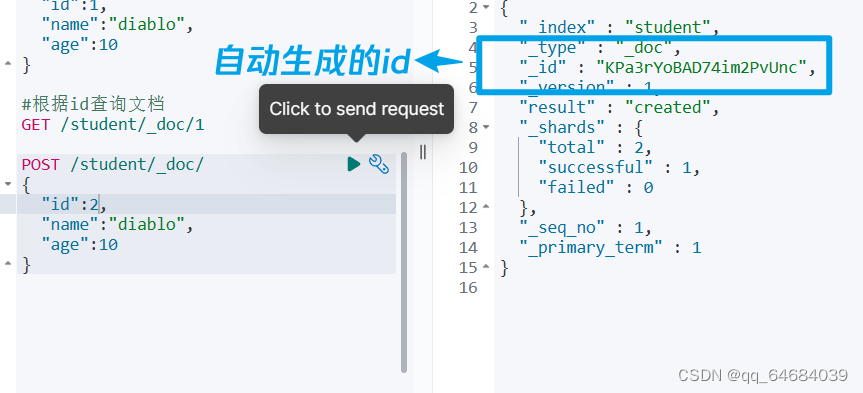
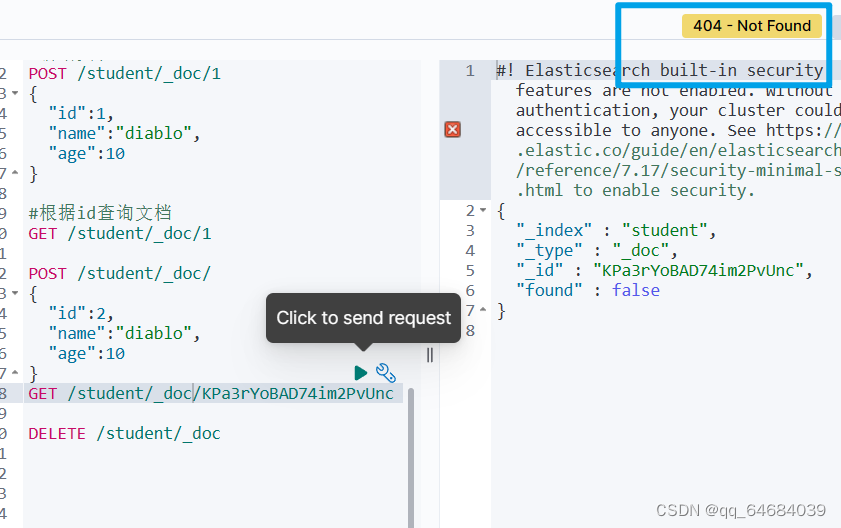
删除自动生成的id后将无法进行数据查询
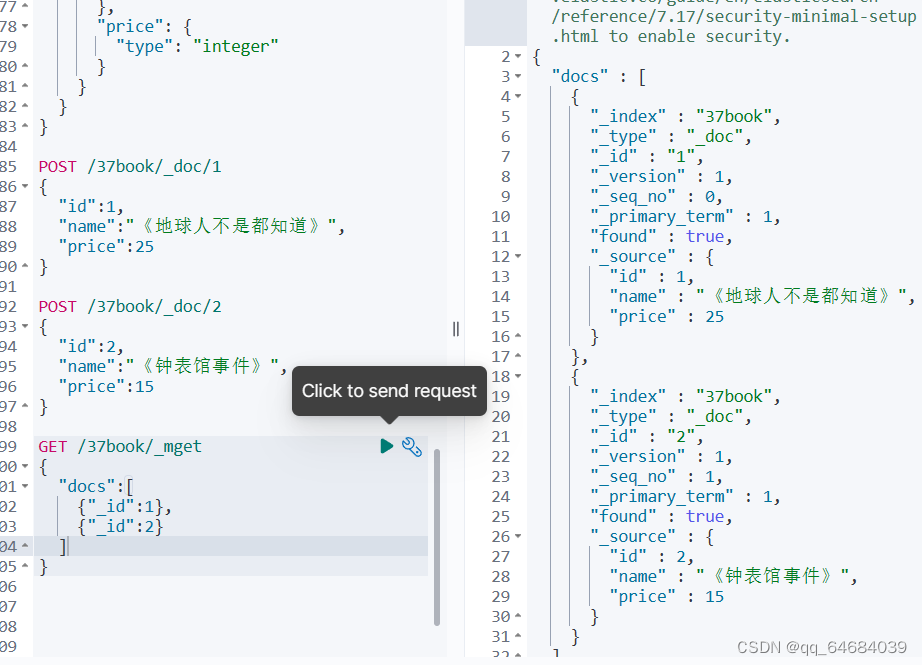
根据id批量查询文档
查询所有文档

#根据id批量查询文档
#1.创建一个图书类索引
#2.添加文档
#3.根据id批量查询文档
PUT /37book
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"price": {
"type": "integer"
}
}
}
}
POST /37book/_doc/1
{
"id":1,
"name":"《地球人不是都知道》",
"price":25
}
POST /37book/_doc/2
{
"id":2,
"name":"《钟表馆事件》",
"price":15
}
GET /37book/_mget
{
"docs":[
{"_id":1},
{"_id":2}
]
}
#查询所有文档
GET /37book/_search
{
"query": {
"match_all": {}
}
}
#修改文档名
POST /37book/_doc/2/_update
{
"doc":{
"name":"《月亮和六便士》"
}
}

域的属性
创建索引查看index的作用



type
域的类型
| 核心类型 | 具体类型 |
|---|---|
| 字符串类型 | text |
| 整数类型 | long, integer, short, byte |
| 浮点类型 | double, float |
| 日期类型 | date |
| 布尔类型 | boolean |
| 数组类型 | array |
| 对象类型 | object |
| 不分词的字符串 | keyword |
store
是否单独存储,如果设置为true,该域能够单独查询。

默认分词器
ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文档对应,这样就可以通过关键词查询文档。要想正确的分词,需要选择合适的分词器。
standard analyzer:Elasticsearch默认分词器,根据空格和标点符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。

IK分词器
可以实现对中文进行拆分
安装IK分词器
上传分词器
![]()
解压
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-ik
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch -d
cd /usr/local/kibana-7.17.0-linux-x86_64/bin
./kibana
测试ik分词器
GET /_analyze
{
"text":"测试语句",
"analyzer":"ik_smart/ik_max_word"
}
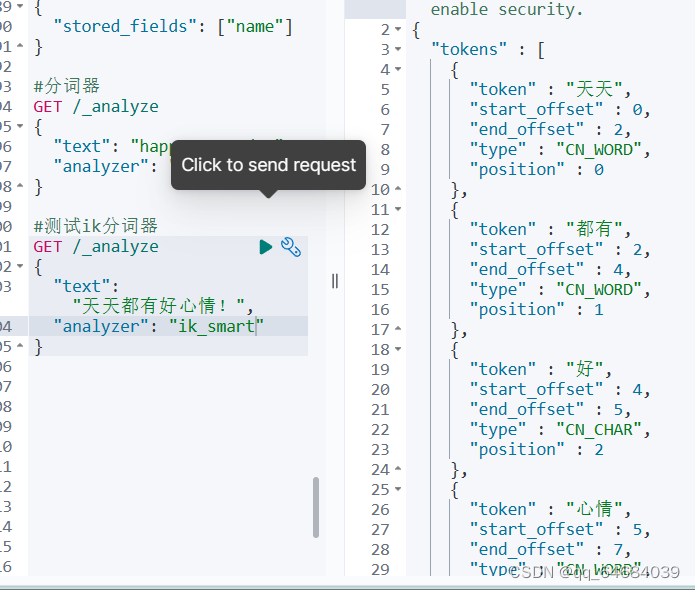

IK分词器词典


IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。
-
main.dic:IK中内置的词典。记录了IK统计的所有中文单词。
-
IKAnalyzer.cfg.xml:用于配置自定义词库。


![]()

查看

关闭es和kibana服务后重启

拼音分词器
关闭es、kibana服务

上传拼音分词器
解压
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis-pinyin

重新启动es服务
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:(-d后台启动)
./elasticsearch -d
cd /usr/local/kibana/bin/
./kibana
测试拼音分词器

自定义分词器
真实开发中我们往往需要对一段内容既进行文字分词,又进行拼音分词,此时我们需要自定义ik+pinyin分词器。
创建自定义分词器
- 在创建索引时自定义分词器
PUT /索引名
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik_pinyin" : { //自定义分词器名
"tokenizer":"ik_max_word", // 基本分词器
"filter":"pinyin_filter" // 配置分词器过滤
}
},
"filter" : { // 分词器过滤时配置另一个分词器,相当于同时使用两个分词器
"pinyin_filter" : {
"type" : "pinyin", // 另一个分词器
// 拼音分词器的配置
"keep_separate_first_letter" : false, // 是否分词每个字的首字母
"keep_full_pinyin" : true, // 是否分词全拼
"keep_original" : true, // 是否保留原始输入
"remove_duplicated_term" : true // 是否删除重复项
}
}
}
},
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
#创建索引时自定义分词器
PUT /book
{
"settings": {
"analysis": {
"analyzer": {
"ik_pinyin":{
"tokenizer":"ik_max_word",
"filter":"pinyin_filter"
}
},
"filter": {
"pinyin_filter":{
"type":"pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_pinyin"
},
"price":{
"type": "integer"
}
}
}
}
#测试自定义分词器
GET /book/_analyze
{
"text": "地球人不是都知道",
"analyzer": "ik_pinyin"
}

es搜索文档
GET /索引/_search
{
"query":{
搜索方式:搜索参数
}
}
准备文档数据并进行测试
#创建索引时自定义分词器
PUT /book
{
"settings": {
"analysis": {
"analyzer": {
"ik_pinyin":{
"tokenizer":"ik_max_word",
"filter":"pinyin_filter"
}
},
"filter": {
"pinyin_filter":{
"type":"pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_pinyin"
},
"price":{
"type": "integer"
}
}
}
}
#测试自定义分词器
GET /book/_analyze
{
"text": "地球人不是都知道",
"analyzer": "ik_pinyin"
}
#添加6条数据
POST /book/_doc/
{
"id":1,
"name":"c语言",
"info":"编程基础"
}
POST /book/_doc/
{
"id":2,
"name":"我从未如此眷恋人间",
"info":"散文"
}
POST /book/_doc/
{
"id":3,
"name":"月亮和六便士",
"info":"梦想"
}
POST /book/_doc/
{
"id":4,
"name":"钟表馆事件",
"info":"推理"
}
POST /book/_doc/
{
"id":5,
"name":"十万个为什么",
"info":"常识"
}
POST /book/_doc/
{
"id":6,
"name":"文化苦旅",
"info":"文学"
}
POST /book/_doc/
{
"id":7,
"name":"白鸟与蝙蝠",
"info":"推理 东野圭吾"
}
#文档搜索
#1.查询所有
GET /book/_search
{
"query": {
"match_all": {}
}
}
#2.全文检索,将查询条件分词后在进行搜索
GET /book/_search
{
"query": {
"match": {
"info": "识"
}
}
}
#范围搜索
GET /book/_search
{
"query": {
"range": {
"id": {
"gte": 1,
"lte": 5
}
}
}
}
#短语检索
GET /book/_search
{
"query": {
"match_phrase": {
"info": "推理"
}
}
}
#自定义排序
#desc降序
#asc升序
GET /book/_search
{
"query": {
"match": {
"info": "推理"
}
},
"sort": [
{
"id": {
"order": "desc"
}
}
]
}分页查询
GET /索引/_search
{
"query": 搜索条件,
"from": 起始下标,
"size": 查询记录数
}















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









