







tips:
列出虚拟环境:conda env list
激活虚拟环境:activate hi
进入jupyter-lab:jupyter lab
练习6
1. 处理字符串空格
- 发现问题: 使用
values属性查看数据时,如果发现Name列没有对齐,很可能是Name左右存在空格。 - 确认问题: 使用
inspection['Name'].values查看Name列的值,确认是否存在空格。 - 解决问题:
- 使用
str属性访问字符串方法:inspection['Name'] = inspection['Name'].str.strip() lstrip(): 去掉字符串左边空格rstrip(): 去掉字符串右边空格strip(): 去掉字符串两边空格
- 使用
- 覆盖原数据: 使用
inspection['Name'] = inspection['Name'].str.strip()将处理后的数据覆盖原数据,并再次使用values属性查看,确认空格已被去除。
2. 对所有列的字符串去空格
columns属性: 使用df.columns查看 DataFrame 的所有列名。- 迭代处理:
columns属性返回的是一个可迭代的Index对象,可以使用循环对每个列进行处理。for column in df.columns: df[column] = df[column].str.strip()
3. 大小写转换
str.lower(): 将字符串转换为小写。str.upper(): 将字符串转换为大写。capitalize(): 将字符串首字母大写,其余字母小写。title(): 将字符串中每个单词的首字母大写,其余字母小写。
4. 提取每行 Risk 的数字
-
unique(): 可以用于检查某一列中有哪些不同的值,方便我们了解数据的结构,例inspections['Risk'].unique()

1. "All":
All表示所有风险等级都适用,它是一个特殊的类别,不同于 "High", "Medium", "Low" 等具体等级。- 在数据分析中,你需要根据具体情况决定如何处理
All。- 保留: 如果
All有其特殊含义,可以将其作为单独的类别进行分析。 - 替换: 可以根据上下文将
All替换为更具体的风险等级,例如,如果所有风险等级都适用,可以将其替换为 "High"。 - 删除: 如果
All没有提供额外信息,可以将其从数据中删除。
- 保留: 如果
2. "nan":
nan代表缺失值,表示该数据点没有记录风险等级信息。- 处理
nan的方法有很多:- 删除: 最简单的处理方法是删除包含
nan的行,但可能会损失信息。 - 填充: 可以用其他值填充
nan,例如:- 众数填充: 用最常见的风险等级填充。
- 均值填充: 如果是数值型风险等级,可以使用均值填充。
- 模型预测: 可以使用机器学习模型预测缺失的风险等级。
- 保留: 在某些情况下,
nan本身也包含信息,可以将其作为单独的类别进行分析。
- 删除: 最简单的处理方法是删除包含
-
正则表达式: 使用
str.extract()方法,结合正则表达式可以高效地提取数字。df['Risk_Num'] = df['Risk'].str.extract(r'(\d+)')
#删除nan数据,保持格式一致
inspections = inspections.dropna(subset=['Risk'])
# 替换数据
inspections = inspections.replace(to_replace='All', value='Risk 4 (Extreme)')
5. 替换数据
-
replace(): 用于替换数据,可以替换单个值或多个值。# 替换单个值 df['Risk'] = df['Risk'].replace('Low', '低') # 替换多个值 df['Risk'] = df['Risk'].replace({'Low': '低', 'High': '高'})
6. 提取 Risk 中的数字(切片操作)
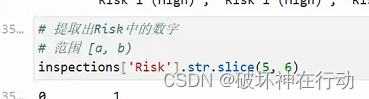
slice(): 用于提取字符串的一部分,可以通过索引或切片语法实现。- inspections['Risk'].str.slice(5, 6)
- inspections['Risk'].str[5:6]
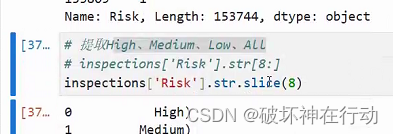
- 提取 "high"、"medium"、"low"、"all":
df['Risk_Level'] = df['Risk'].str.slice(start=0, stop=-4) - 去括号:
df['Risk_Level'] = df['Risk_Level'].str.strip('()')
- 提取 "high"、"medium"、"low"、"all":
7. 提取包含特定数据的行
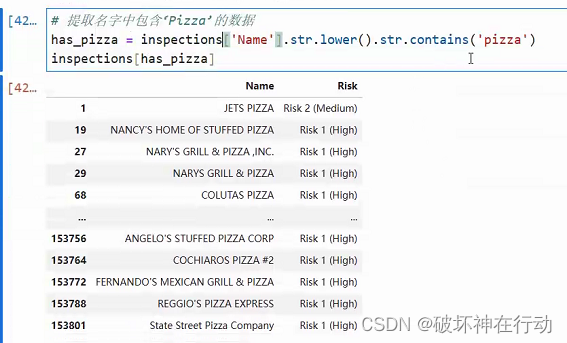
-
str.contains(): 用于判断字符串是否包含某个子字符串,返回布尔值。可以结合布尔索引提取包含特定数据的行。# 提取包含 "High" 的行 high_risk = df[df['Risk'].str.contains("High")]
8. 找出以特定字符串开头/结尾的数据
-
str.startswith(): 判断字符串是否以某个子字符串开头,返回布尔值。 -
str.endswith(): 判断字符串是否以某个子字符串结尾,返回布尔值。# 提取以 "Low" 开头的 Risk 数据 low_start = df[df['Risk'].str.startswith("Low")] # 提取以 "(1)" 结尾的 Risk 数据 risk_1 = df[df['Risk'].str.endswith("(1)")]
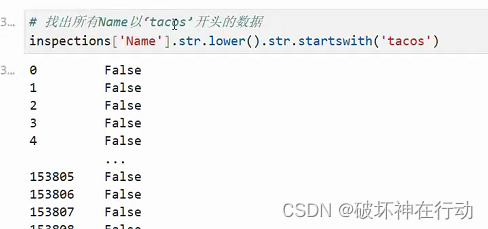

9. str.len()
-
用于获取字符串的长度。
# 获取 Risk 列字符串长度 df['Risk_Length'] = df['Risk'].str.len()
10. 字符串处理(按 "-"、" " 等方式划分)
-
str.split(): 用于根据指定分隔符分割字符串,返回一个列表。split(): 默认按空格分割。split(pat=" "): 按空格分割。split(pat=" ", n=1): 按空格分割,最多分割一次。
# 按空格分割 Risk 列 df['Risk_Parts'] = df['Risk'].str.split() # 按 "-" 分割,最多分割一次 df['Risk_First_Part'] = df['Risk'].str.split("-", n=1) # 提取First name # 从每行的分割后的list中按照list的index提取 customers['Name'].str.split(' ', n=1).str.get(0) # 通过get(index)获取list中指定index处的值 # 获取last name customers['Name'].str.split(' ', n=1).str.get(1) # 将 split 后的多个部分分别作为列 # 返回DataFrame customers['Name'].str.split(pat=' ', n=1, expand=True) # 如果没有控制 split 后得到的 list 的长度 # pandas 会自动取最长的len(list), 且缺失值处显示 None customers['Name'].str.split(pat=' ', expand=True)
11.给原来的DataFrame添加新列
# 把Name拆为1 、 2
customers[
['Name1','Name2']
] = customers['Name'].str.split(pat = ' ', n = 1, expand=True)

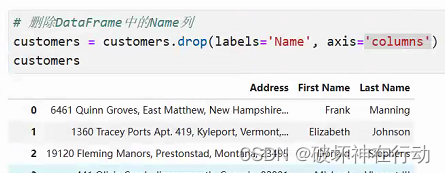
练习题
# customers.csv包括一个地址列。
# 每个地址由一条街道、城市、州和邮政编码组成。
# 分离这四个值;
# 将它们分配到DataFrame中新的Street、City、State和Zip列;
# 然后删除地址列。
customers
customers['Address'].values
split_Address = customers['Address'].str.split(', ', expand=True)
split_Address
customers[['Street', 'City', 'State', 'Zip']] = split_Address
customers = customers.drop(labels='Address', axis='columns')
customers
练习7
MultiIndex
MultiIndex(多级索引) 允许使用多个索引级别来组织数据,从而创建出层次化的数据结构。 这使得数据的分析和操作更加灵活和强大。
1. 创建
创建 MultiIndex 的方法有很多:
-
from_tuples: 从元组列表创建 MultiIndex
import pandas as pd
tuples = [(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')]
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
data = pd.DataFrame({'A': [1, 2, 3, 4]}, index=index)
print(data)
-
from_arrays: 从数组列表创建 MultiIndex
arrays = [[1, 1, 2, 2], ['a', 'b', 'a', 'b']]
index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
data = pd.DataFrame({'A': [1, 2, 3, 4]}, index=index)
print(data)
-
from_product: 从多个迭代器创建 MultiIndex
iterables = [[1, 2], ['a', 'b']]
index = pd.MultiIndex.from_product(iterables, names=['first', 'second'])
data = pd.DataFrame({'A': [1, 2, 3, 4]}, index=index)
print(data)
2. 访问数据
使用 MultiIndex 可以更方便地访问和操作数据:
-
loc: 使用标签进行访问
# 获取 first 为 1,second 为 'a' 的数据
print(data.loc[(1, 'a')])
# 获取 first 为 1 的所有数据
print(data.loc[1])
# 获取 second 为 'a' 的所有数据
print(data.loc[:, 'a'])
-
iloc: 使用位置进行访问
# 获取第一行数据
print(data.iloc[0])
# 获取前两行数据
print(data.iloc[:2])
-
xs: 访问特定级别的值
# 获取 first 为 1 的所有数据
print(data.xs(1, level='first'))
# 获取 second 为 'a' 的所有数据
print(data.xs('a', level='second'))
3. 数据操作
MultiIndex 允许对数据进行更灵活的操作:
-
排序: 可以根据不同级别的索引进行排序
# 根据 first 级别升序排序
print(data.sort_index(level='first'))
# 根据 second 级别降序排序
print(data.sort_index(level='second', ascending=False))
-
分组: 可以根据不同级别的索引进行分组
# 根据 first 级别进行分组
grouped = data.groupby(level='first')
# 计算每个组的平均值
print(grouped.mean())
-
切片: 可以根据不同级别的索引进行切片
# 获取 first 级别为 1 的所有数据
sliced = data.loc[1]
# 获取 second 级别为 'a' 的所有数据
sliced = data.loc[:, 'a']
查询
可以理解为数据降维

import pandas as pd
address = ('8890 Flair Square', 'Toddside', 'IL', '37206')
address
address = [
("8809 Flair Square", "Toddside", "IL", "37206"),
("9901 Austin Street", "Toddside", "IL", "37206"),
("905 Hogan Quarter", "Franklin", "IL", "37206"),
]
pd.MultiIndex.from_tuples(tuples=address)
# 给每个level取个名字
row_index = pd.MultiIndex.from_tuples(
tuples=address, names=['Street', 'City', 'State', 'Zip'])
row_index
# 使用MultiIndex创建DataFrame
# 对 DataFrame 的行使用 MultiIndex
data = [
['A', 'B+'],
['C+', 'C'],
['D-', 'A']
]
columns = ['Schools' ,'Cost of Living']
area_grades = pd.DataFrame(
data=data, index=row_index, columns=columns
)
area_grades
area_grades.columns
area_grades.index
# 对 DataFrame 的列使用 MultiIndex
column_index = pd.MultiIndex.from_tuples(
[
("Culture", "Restaurants"),
("Culture", "Museums"),
("Services", "Police"),
("Services", "Schools"),
]
)
column_index
#row_index 需要3行数据
#column_index 需要4列数据
#所以需要新建一个3×4的dataframe
data = [
["C-", "B+", "B-", "A"],
["D+", "C", "A", "C+"],
["A-", "A", "D+", "F"]
]
pd.DataFrame(
data=data, index=row_index, columns=column_index
)
neighborhoods(行列名操作)
neighborhoods = pd.read_csv('neighborhoods.csv')
neighborhoods
# 通过index_col指定前三列为index列。列的序号从0开始,所以指定0, 1, 2
# pandas 自动为DataFrame创建用于行的MultiIndex
neighborhoods = pd.read_csv('neighborhoods.csv', index_col=[0, 1, 2])
neighborhoods
# 通过 header 指定前两行是列名
neighborhoods = pd.read_csv(
'neighborhoods.csv',
index_col=[0, 1, 2],
header=[0, 1]
)
neighborhoods
neighborhoods.info()
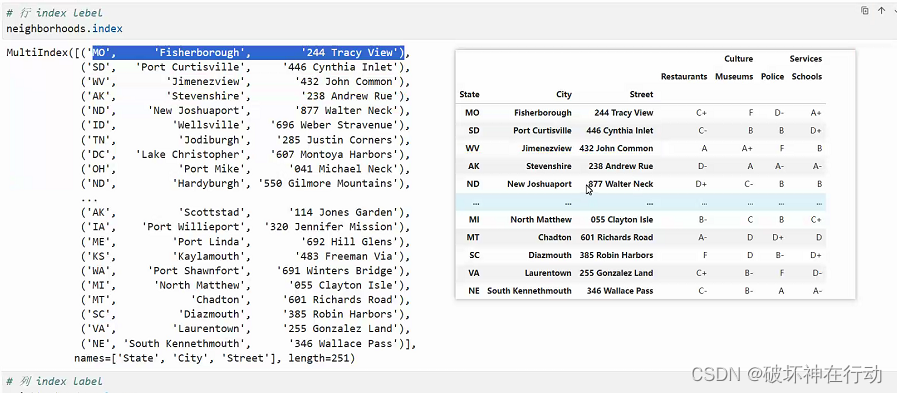
# 行 index lebel
neighborhoods.index
# 列 index label
neighborhoods.columns
# MultiIndex 是由多个 Index 组合而成的
neighborhoods.index.names
# 通过给定的数字序号或者level名字获取指定level的所有index值
# neighborhoods.index.get_level_values(1)
neighborhoods.index.get_level_values('City')
#给列设置名字
neighborhoods.columns.names
# 给column index设置名字(两层名字)
neighborhoods.columns.names = ['Category', 'Subcategory']
neighborhoods.columns.names
# 获取column MultiIndex的值(按实际的列返回)
# neighborhoods.columns.get_level_values(0)
neighborhoods.columns.get_level_values('Category')
neighborhoods.head(1)
#有多少不同值
neighborhoods.nunique()排序
# 按照index排序,默认为升序
# 先在State level上进行排序,然后是City level, 最后是Street level
neighborhoods.sort_index()
# 先在State level上进行排序,然后是City level, 最后是Street level
# 每次排序都使用降序
neighborhoods.sort_index(ascending=False)
# 通过一个包含boolean的list指定每个level的排序规则
# 第一层升序,第二层降序,第三层升序
neighborhoods.sort_index(ascending=[True, False, True])
# 在指定level上进行排序
# neighborhoods.sort_index(level=1)
neighborhoods.sort_index(level='City')
# 按照指定的level顺序进行排序
# neighborhoods.sort_index(level=[1, 2])
# 先按City排序,后对Street排序
neighborhoods.sort_index(level=['City', 'Street'])
# 先按City升序排序,再按照Street降序排序
neighborhoods.sort_index(level=['City', 'Street'], ascending=[True, False])
# 对列排序
# neighborhoods.sort_index(axis=1)
neighborhoods.sort_index(axis='columns')
# 对列的多级索引按Subcategory排序,降序
neighborhoods.sort_index(axis=1, level='Subcategory', ascending=False)
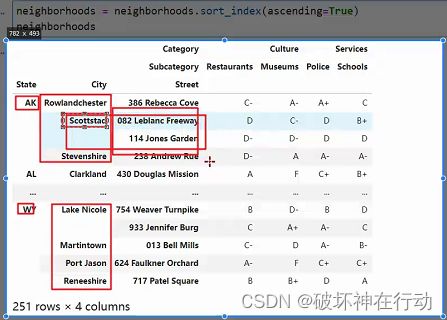
# 修改DataFrame,使用传出来的值(默认升序)
neighborhoods = neighborhoods.sort_index(ascending=True)
neighborhoods
构造数据
data = [
[1, 2],
[3, 4]
]
# 第一行A,第二行B
# 第一列X,第二例Y
df = pd.DataFrame(
data=data, index=['A', 'B'], columns=['X', 'Y']
)
df
df['X']neighborhoods(提取多列)
neighborhoods
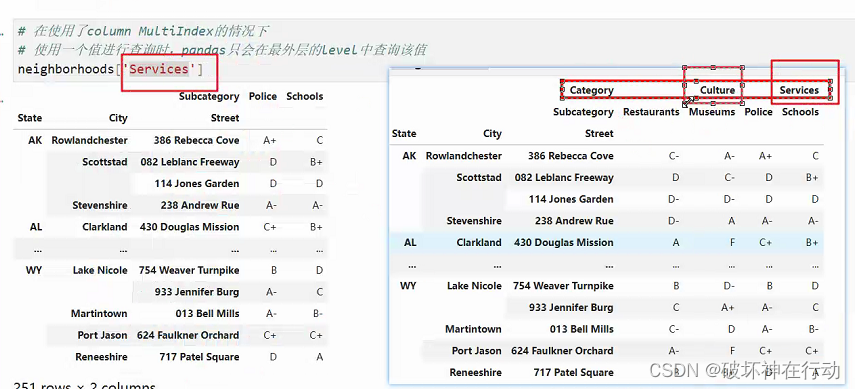
# 在使用了column MultiIndex的情况下
# 使用一个值进行查询时,pandas只会在最外层的level中查询该值
neighborhoods['Services']
# 'Schools'不是最外层的level
try:
neighborhoods['Schools']
except KeyError as e:
print('KeyError:', e)
# 第一层列索引Services,第二层列索引Schools
neighborhoods[('Services', 'Schools')]
type(neighborhoods[('Services', 'Schools')])
# 按照指定顺序显示数据(指定多维数组中具体查看哪一列)
# 第一层列索引中有Services索引中的Schools索引
neighborhoods[[('Services', 'Schools'), ('Culture', 'Museums')]]
# 交换顺序显示
neighborhoods[[('Culture', 'Museums'), ('Services', 'Schools')]]
# 避免写错,拆开写
columns = [
('Services', 'Schools'),
('Culture', 'Museums')
]
neighborhoods[columns]
neighborhoods(提取多行)
# 提取多行
df
df.loc['A']
df.iloc[1]
# 行索引(根据行索引定位该行数据)
neighborhoods.loc[('TX', 'Kingchester', '534 Gordon Falls')]
# 如果只传入一个label,则只匹配行的最外层 level
# 即:State = 'CA'
# 类似直角坐标系(State为X,City为Y,Street为Z)根据某一坐标匹配其他坐标
# 可以视为行索引上的降维
neighborhoods.loc['CA']
# 多级索引
neighborhoods.loc['CA', 'Dustinmouth']
# 在行的最外层label中搜索 CA,在列的最外层label中搜索Culture
neighborhoods.loc['CA', 'Culture']
# neighborhoods.loc['CA', 'Culture']这种写法有歧义
# 没有歧义的写法(只看行索引)
neighborhoods.loc[('CA', 'Dustinmouth')]
# 注意最后的逗号(左边是行索引,右边是列索引)使用元组,注意逗号隔开
neighborhoods.loc[('CA', 'Dustinmouth'), ('Services', )]
neighborhoods.loc[('CA', 'Dustinmouth'), ('Services', 'Schools')]
# 选择连续的行
# 区间 ['NE', 'NH'],考虑区间左右两边是否取值
# 只传入最外层值,故在最外层查找
neighborhoods['NE':'NH']
# 从第一层到第二层
neighborhoods.loc[('NE', 'Shawnchester') : ('NH', 'North Latoya')]
# 避免写错,拆开写
start = ('NE', 'Shawnchester')
end = ('NH', 'North Latoya')
neighborhoods.loc[start : end]
start = ('NE', 'Shawnchester')
end = ('NH', )
neighborhoods.loc[start : end]iloc(使用数字类型的索引进行定位)
# iloc
neighborhoods.iloc[25]
# row with index position 25, column with index position 2
neighborhoods.iloc[25, 2]
# row index 是25和30的2行数据
neighborhoods.iloc[[25, 30]]
# 行区间 [25, 30)
neighborhoods.iloc[25:30]
# 列区间 [1, 3)
neighborhoods.iloc[25:30, 1:3]
neighborhoods.iloc[-4:, -2:]
# 找出所有City为Lake Nicole的数据
# neighborhoods.xs(key='Lake Nicole', level=1)
neighborhoods.xs(key='Lake Nicole', level='City')
# 查询Subcategory中Museums列的数据
neighborhoods.xs(key='Museums', axis=1, level='Subcategory')
neighborhoods.xs(key=('AK', '238 Andrew Rue'), level=['State', 'Street'])
neighborhoods
#重新指定MultiIndex中各个index的顺序
new_order = ['City', 'State', 'Street']
neighborhoods.reorder_levels(order=new_order)
# 使用数字指定位置
neighborhoods.reorder_levels(order=[1, 0, 2])
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









