




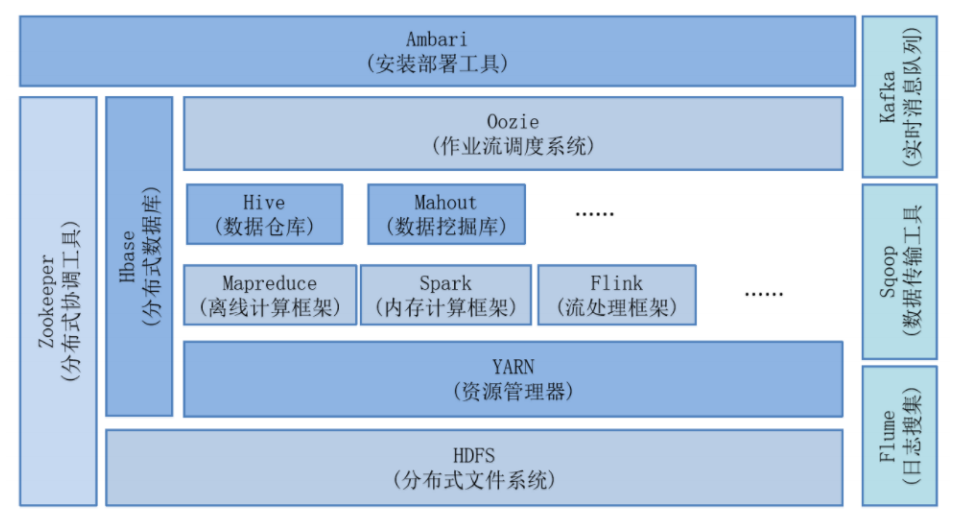
一、Hadoop介绍
Hadoop 分为三部分 : Common、HDFS 、Yarn、MapReduce(有点过时了)
Hadoop生态圈:除了hadoop技术以外,还有hive、zookeeper、flume、sqoop、datax、azkaban等一系列技术。
Hadoop 是 道格·卡丁 本身他是Lucene的创始人。
Lucene 其实是一个jar包。
检索现在主流的是Solr以及ES(Elastic Search)。
比如现在每一个网站,都有一个检索的输入框,底层技术: Solr (稍微有点过时了) , ES (正在流行中)
首先面临的问题是:海量数据如何存储?
根据谷歌推出的三篇论文:
BigTable -- HBase
GFS -- HDFS
MapReduce -- MapReduce
并将这些技术统称为 Hadoop (Logo 大象)。
Hadoop的三个版本:
Apache 版本(开源版本) 3.3.1 非常的新了
Cloudera 版本--商⽤版(道格·卡丁) CDH
Hortonworks --hadoop的代码贡献者在这家公司非常的多。
现在各个大公司都在推出自己的大数据平台--> 大数据平台开发工程师
DataLight --> 国产的CDH平台


二、HDFS的本地模式
:::success
hdfs: 分布式文件管理系统
海量数据存储的终极解决方案:整出来一个平台,这个平台的服务器可以无限扩展。
:::
:::info
HDFS : 解决海量数据的存储问题 1p = 1024 T
Yarn : 计算的资源基础,所有的MR任务需要运行在Yarn上。
MapReduce:解决计算问题,它是一个计算框架(需要写代码的)
:::
HDFS三种模式:本地模式,伪分布模式,全分布模式
配置:
1、上传
2、解压
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/installs/
3、重命名
cd /opt/installs/
mv hadoop-3.3.1 hadoop
4、开始配置环境变量
vi /etc/profile
export HADOOP_HOME=/opt/installs/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置文件
source /etc/profile
6、验证hadoop命令是否可以识别
hadoop version

使用一下hadoop这个软件(案例WordCount):
词频统计就是我们大数据中的HelloWorld!
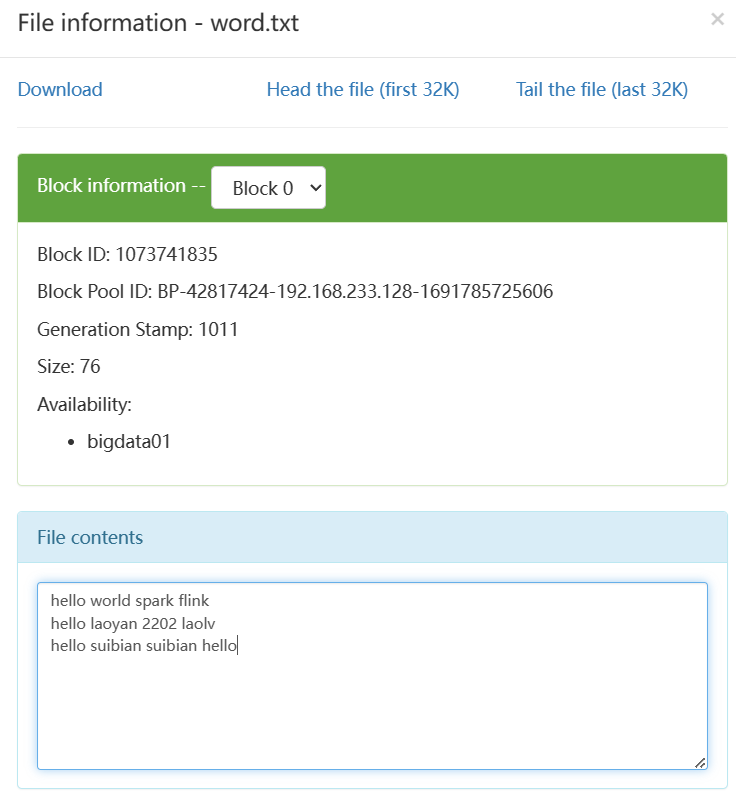
在 /home 下创建了一个文件 wc.txt 命令: touch wc.txt
需要统计的词如下:
hello world spark flink
hello laoyan 2202 laolv
hello suibian suibian hello
接着使用自动的wordCount工具进行统计:
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /home/wc.txt /home/output
hadoop jar 执行某个jar包(其实就是java代码)
/opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 这个是jar的地址
/home/wc.txt 要统计的文件
/home/output 统计结果放哪里
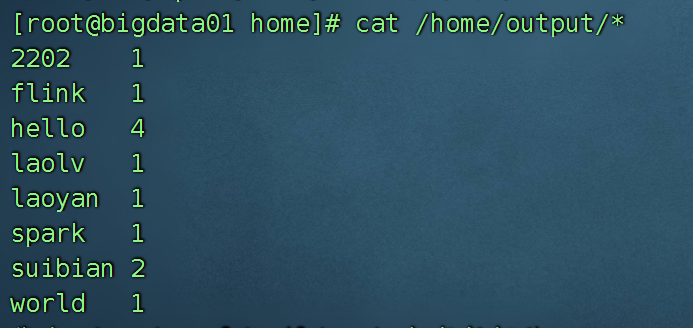

如果统计的结果文件夹已经存在,会报错。
上面总结一下:
数据在本地磁盘上 /home/wc.txt
计算的结果也是在本地磁盘上 /home/ouput
案例二:PI的计算
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 100
10 代表10个任务
100 代表的是100次/每个任务
三、hdfs 伪分布模式
:::info
伪分布:按照分布式的步骤搭建,但是呢,服务器只有一台。
:::
只能用于开发、和学习用。
比如我想搭建一个集群,将集群中的所有磁盘连接在一起形成一个云端的hdfs.
但是公司就买了一台服务器。所以搭建出来的就是伪分布模式。
伪分布的意思:按照全分布的步骤搭建的集群,但是linux服务器只有一台。
进行搭建之前的一些准备工作:
环境准备⼯作:
1、安装了jdk
2、安装了hadoop
3、关闭了防⽕墙
systemctl status firewalld
4、免密登录
⾃⼰对⾃⼰免密
ssh-copy-id bigdata01 选择yes 输⼊密码
测试免密是否成功: ssh bigdata01
5、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
6、设置host映射
配置开始:
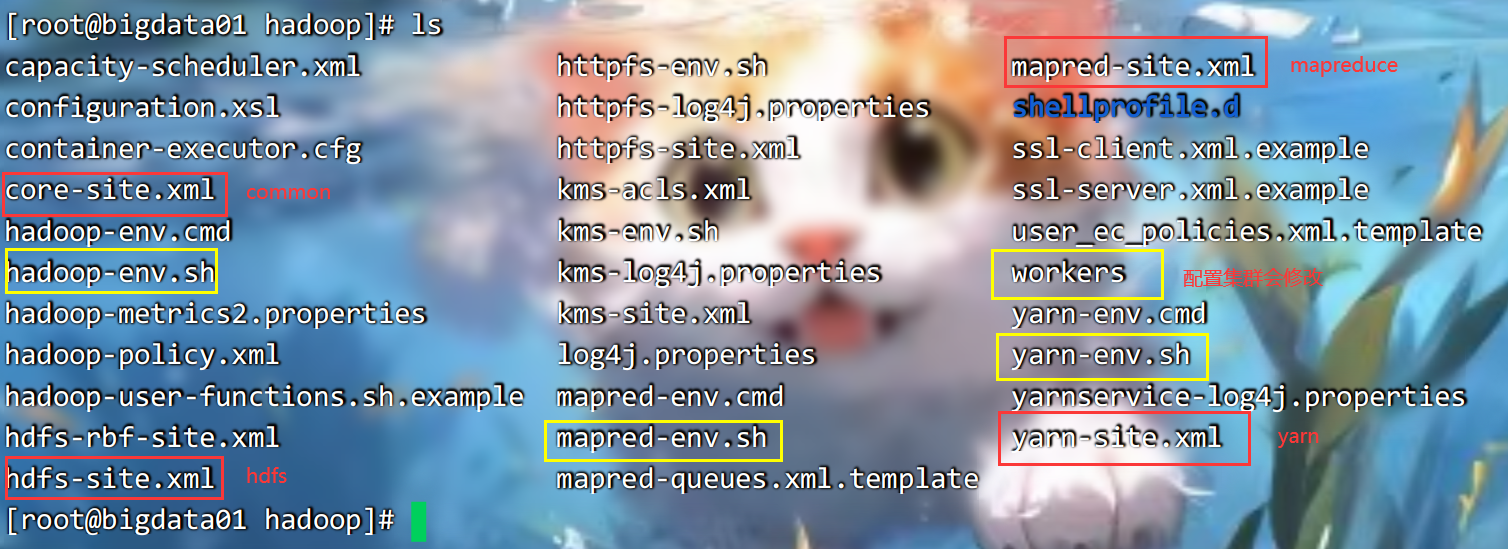
位置: /opt/installs/hadoop/etc/hadoop
以下圈住的都是重要的文件:
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>
<configuration>
<property>
<!--备份数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>
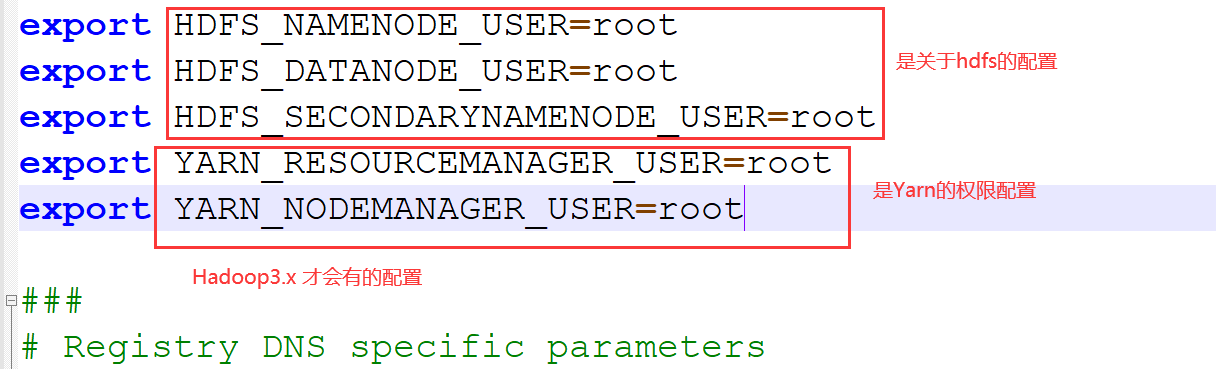
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/opt/installs/jdk
修改workers 文件:
vi workers
修改里面的内容为: bigdata01 保存
对整个集群记性namenode格式化:
hdfs namenode -format
:::info
格式化其实就是创建了一系列的文件夹:
这个文件夹的名字是 logs tmp
假如你想格式化第二次,需要先删除这两个文件夹,然后再格式化
:::
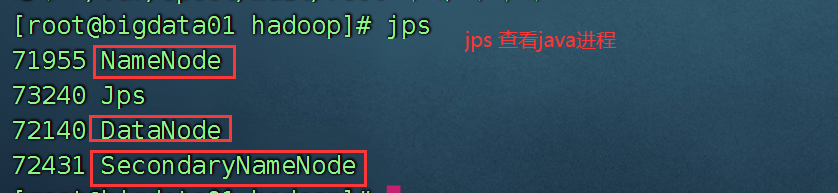
启动集群:
start-dfs.sh
通过网址访问hdfs集群:
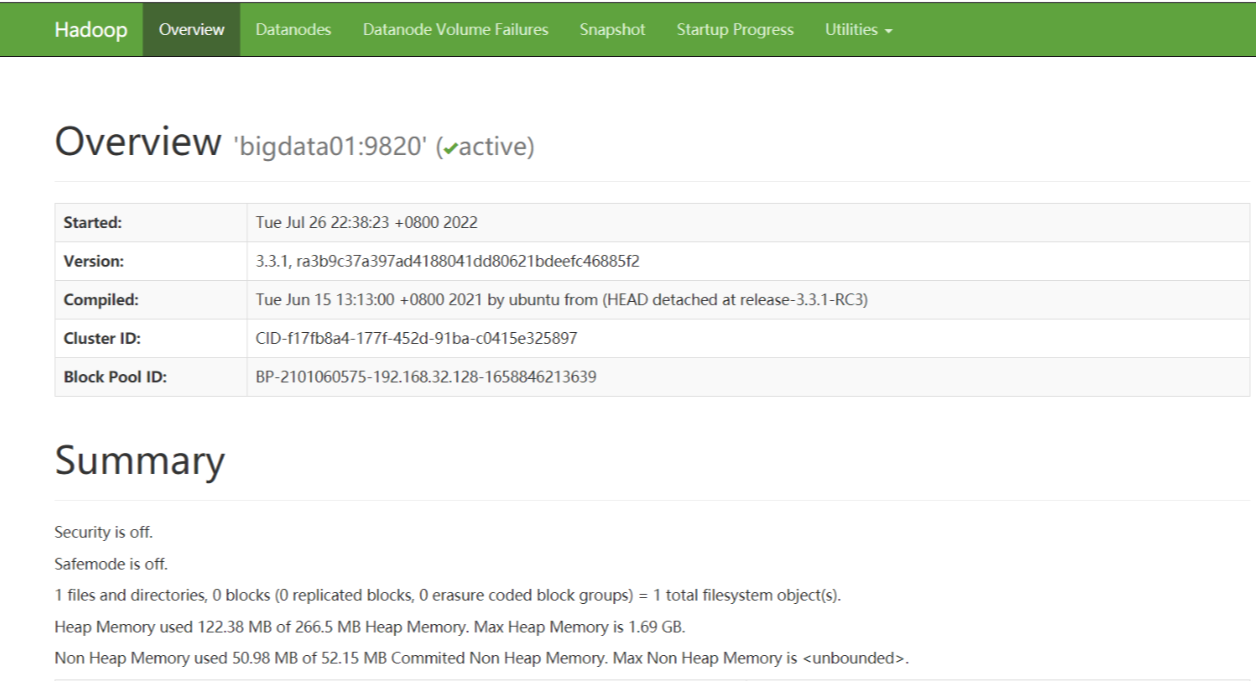
如果访问不到:检查防火墙是否关闭。
测试一下这个hdfs的文件系统:
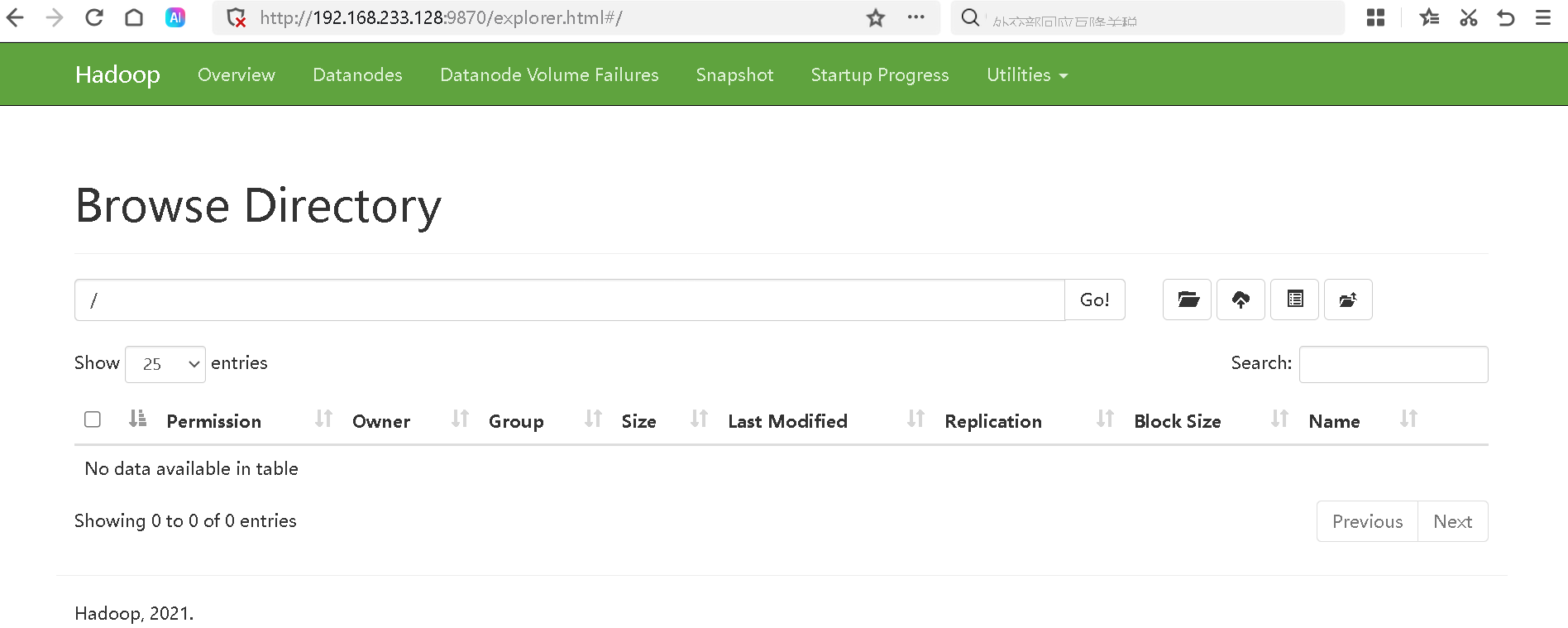
:::color2
目前搭建的这个到底是hdfs的伪分布还是hadoop伪分布?
答案是 hdfs的伪分布,但是hdfs 也是hadoop的一部分。
真正的hadoop伪分布还需要配置yarn 才算真正的伪分布。
:::
使用这个文件系统:
1、将要统计的内容上传至hdfs文件系统
hdfs dfs -mkdir /home
hdfs dfs -put /home/wc.txt /home
2、使用wordcount统计wc.txt
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /home/wc.txt /home/output
3、查看统计结果
hdfs dfs -cat /output/*
:::success
假如你的环境是伪分布式模式,那么本地模式直接被替换了,回不去了。
:::
此模式跟本地模式有何区别?
这两种方式,首选统计的代码都在本地,但是本地模式,数据和统计的结果都在本地。
伪分布模式,它的数据来源在 hdfs 上,统计结果也放在 hdfs上。
如果此时再执行以前的workcount就会报错,原因是以前是本地模式,现在是伪分布模式,伪分布模式,只会获取hdfs上的数据,将来的结果也放入到hdfs上,不会获取本地数据:
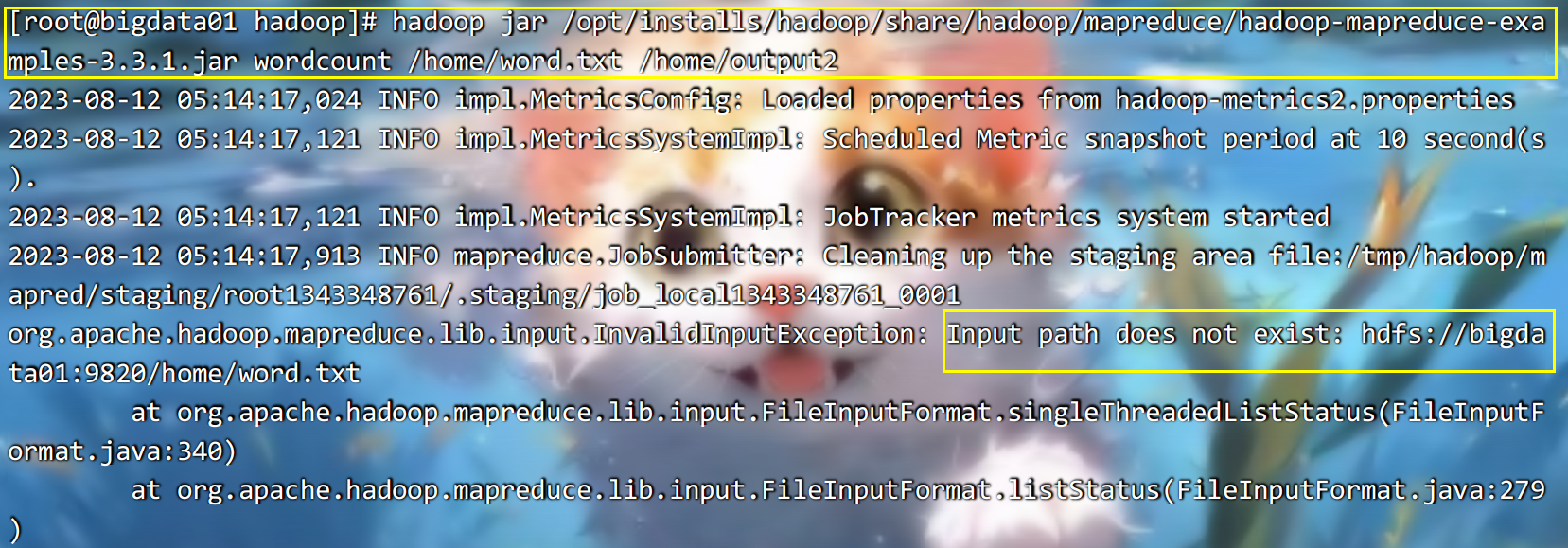
四、Hdfs中的shell命令
假如你想通过web界面查看一个文件的内容,点击报错:
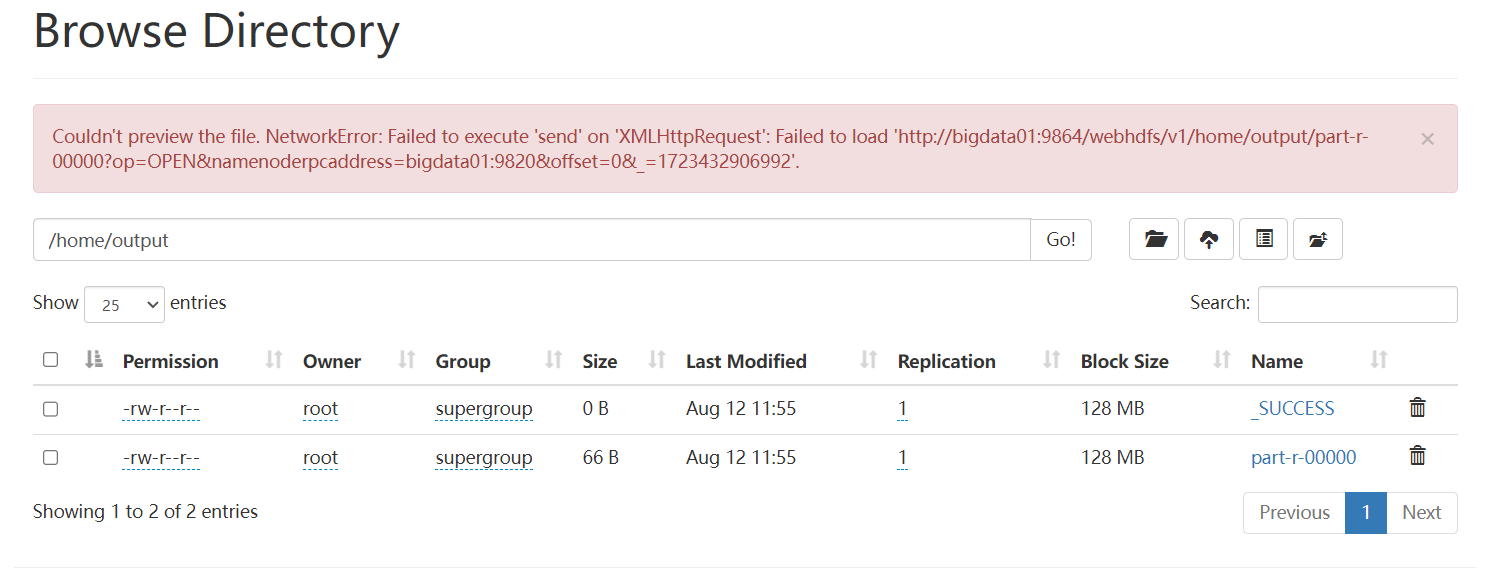
Couldn't preview the file. NetworkError: Failed to execute 'send' on 'XMLHttpRequest': Failed to load 'http://bigdata01:9864/webhdfs/v1/output/part-r-00000?op=OPEN&namenoderpcaddress=bigdata01:9820&offset=0&_=1692068863115'.
默认是要报错的,因为这是一种安全机制,可以修改一下:
在hdfs-site.xml 中添加如下配置:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
在windows本机,修改hosts映射关系。
C:\Windows\System32\drivers\etc\hosts
修改内容如下:
192.168.233.128 bigdata01
192.168.233.129 bigdata02
192.168.233.130 bigdata03
关于hdfs文件系统,有三种操作方式:
1、图形化界面 比如 http://IP地址:9870
2、shell命令操作 比如 hdfs dfs -put 上传 -cat 查看
3、通过java代码操作
shell命令操作:东西特别的多,只学其中一些。
hdfs dfs -put 本地文件 hdfs路径
hdfs dfs -mkdir /abc 创建文件夹
hdfs dfs -mkdir -p /abc/bcd/cde 创建多级文件夹使用-p
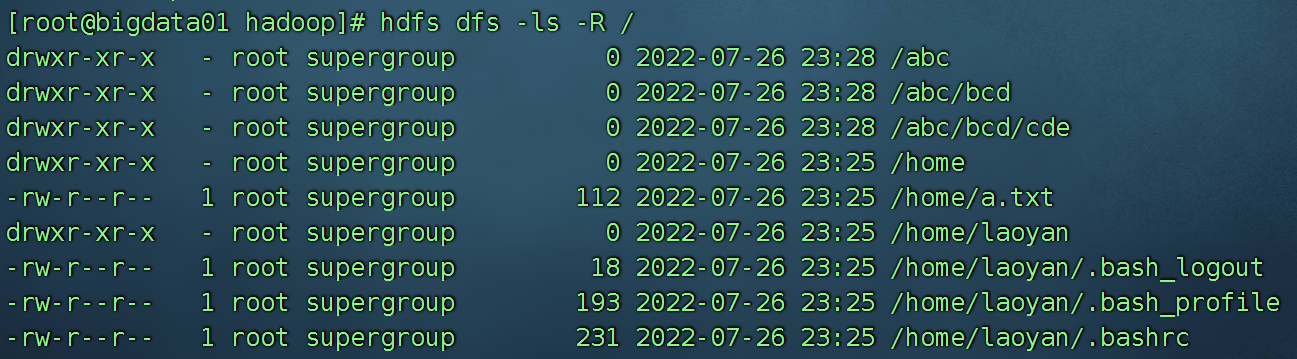
hdfs dfs -ls / 查看某个路径下的文件或者文件夹
hdfs dfs -ls -R / 不仅查看某个路径,还把嵌套的文件夹都展示出来,有一种递归的赶脚
hdfs dfs -cat /hdfs上的文件 查看某个文件
hdfs dfs -moveFromLocal 本地文件 hdfs的路径
跟put上传不一样的是,move结束后,本地文件会消失
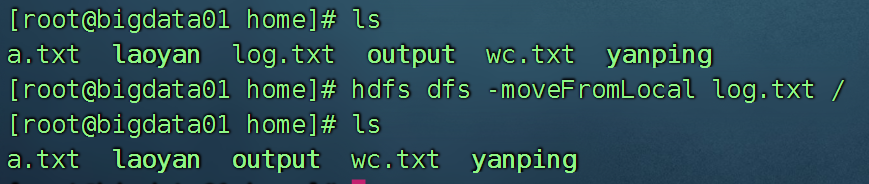
hdfs dfs -get hdfs的路径 本地文件 此操作要谨慎

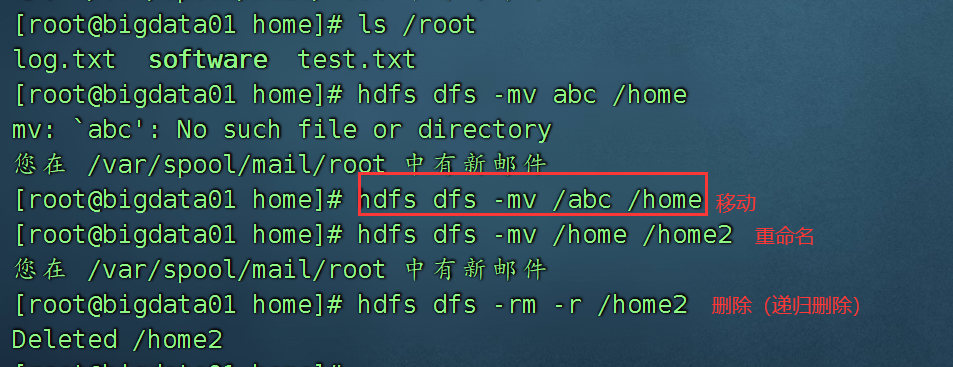
hdfs dfs -cp /log.txt /ouput 将hdfs上的一个文件拷贝到另一个文件夹
hdfs dfs -chmod 777 /wc.txt hdfs上的文件也可以赋权限
五、全分布搭建
全分布模式:必须至少有三台以上的Linux
前期准备工作:
1、准备三台服务器
目前有两台,克隆第二台(因为第二台没有安装mysql), 克隆结束后,进行修复操作
1) 修改IP 2) 修改主机名 3)修改映射文件hosts
检查是否满足条件:
:::color2
环境准备⼯作:
1、安装了jdk
2、设置host映射
192.168.32.128 bigdata01
192.168.32.129 bigdata02
192.168.32.130 bigdata03
远程拷贝:(如果三台服务器都已经配置过了,就不需要远程拷贝了)
scp -r /etc/hosts root@bigdata02:/etc/
scp -r /etc/hosts root@bigdata03:/etc/
3、免密登录
bigdata01 免密登录到bigdata01 bigdata02 bigdata03
ssh-copy-id bigdata03
4、第一台安装了hadoop
先不要急着拷贝,因为后面需要修改 bigdata01 上的 hadoop
5、关闭了防⽕墙
systemctl status firewalld
6、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
:::
2、检查各项内容是否到位
:::success
如果以前安装的有伪分布模式,服务要关闭。 stop-dfs.sh
:::
3、修改bigdata01配置文件
路径:/opt/installs/hadoop/etc/hadoop
跟伪分布一样:不需要修改
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>
跟伪分布一样,不需要修改
export JAVA_HOME=/opt/installs/jdk
# Hadoop3中,需要添加如下配置,设置启动集群⻆⾊的⽤户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改workers
bigdata01
bigdata02
bigdata03
删除 bigdata01 下的 hadoop 下的 logs 以及 tmp 文件
rm -rf /opt/installs/hadoop/logs /opt/installs/hadoop/tmp
修改完了第一台的配置文件,开始分发到其他两台上去。
:::color3
假如以前没有将bigdata01上的hadoop 拷贝给 02 和 03
那么就远程拷贝:
scp -r /opt/installs/hadoop/ root@bigdata02:/opt/installs/
scp -r /opt/installs/hadoop/ root@bigdata03:/opt/installs/
:::
拷贝环境变量:
scp -r /etc/profile root@bigdata02:/etc/
scp -r /etc/profile root@bigdata03:/etc/
在02 和 03 上刷新环境变量 source /etc/profile
4、格式化namenode 【bigdata01】
hdfs namenode -format
5、启动hdfs
只在第一台电脑上启动
start-dfs.sh
启动后jps,看到
| bigdata01 | bigdata02 | bigdata03 |
|---|---|---|
| namenode | secondaryNameNode | x |
| datanode | datanode | datanode |
web访问:namenode 在哪一台,就访问哪一台。http://bigdata01:9870
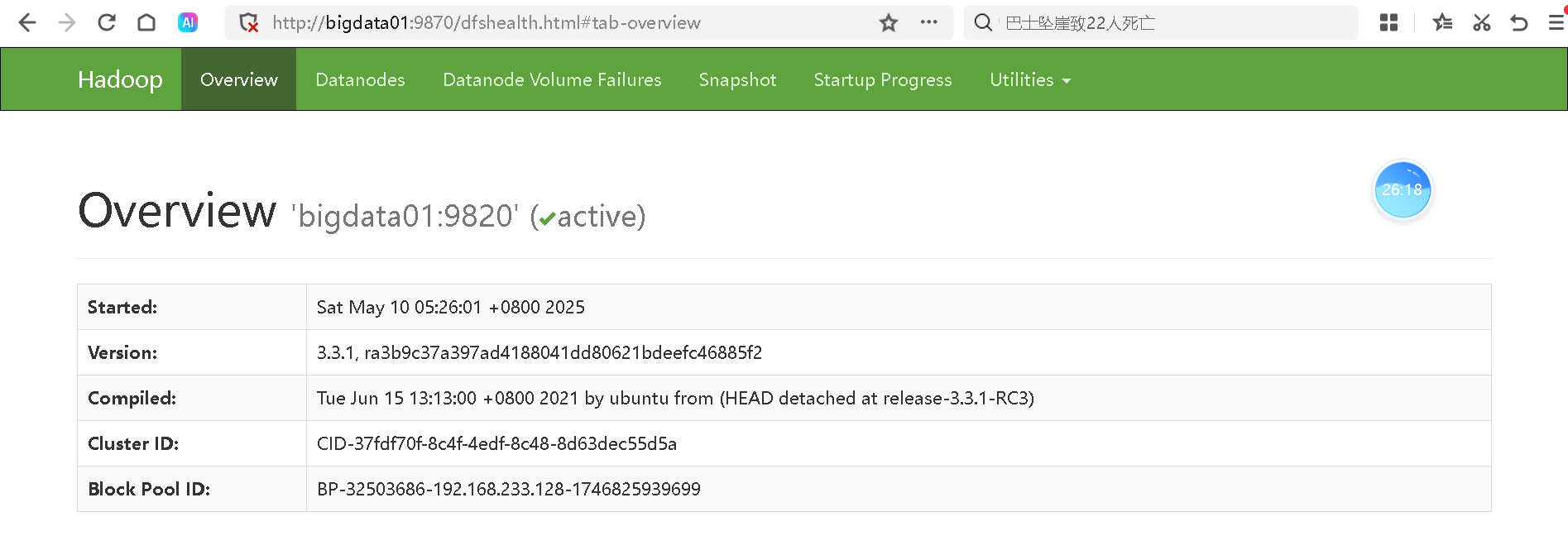
总结:
1、start-dfs.sh 在第一台启动,不意味着只使用了第一台,而是启动了集群。
stop-dfs.sh 其实是关闭了集群
2、一台服务器关闭后再启动,上面的服务是需要重新启动的。
这个时候可以先停止集群,再启动即可。也可以使用单独的命令,启动某一个服务。
hdfs --daemon start namenode # 只开启NameNode
hdfs --daemon start secondarynamenode # 只开启SecondaryNameNode
hdfs --daemon start datanode # 只开启DataNode
hdfs --daemon stop namenode # 只关闭NameNode
hdfs --daemon stop secondarynamenode # 只关闭SecondaryNameNode
hdfs --daemon stop datanode # 只关闭DataNode
3、namenode 格式化有啥用
相当于在整个集群中,进行了初始化,初始化其实就是创建文件夹。创建了什么文件夹:
logs tmp
你的hadoop安装目录下。
六、使用Java代码操作HDFS
上传文件,创建文件夹,删除文件,下载等等
1、环境准备
1)解压hadoop的安装包
解压,有时候会报错,可以参考这篇文章:https://blog.csdn.net/qq_43674360/article/details/116332731
或者使用 360 压缩 这个软件也可以。
2)配置环境变量
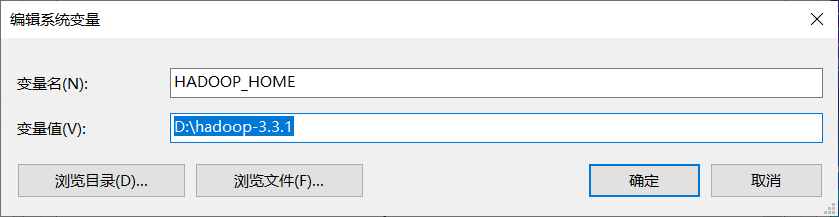
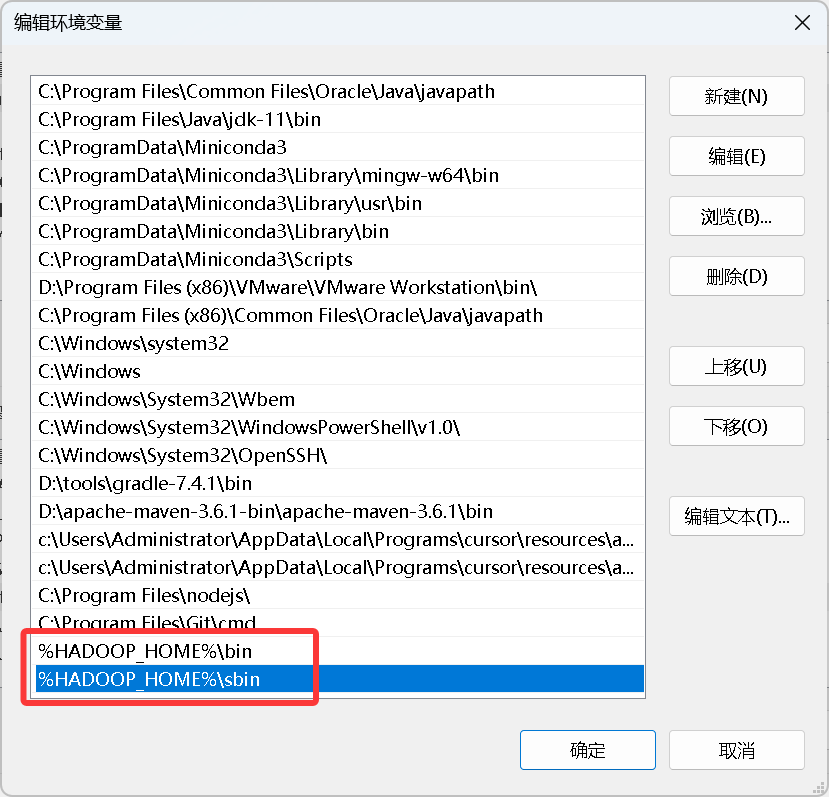
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
如果你出现了如下错误:
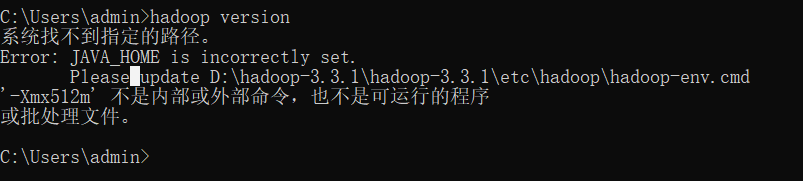
他的意思是你的java_home ,需要修改一个地方:
在 /etc/hadoop 下的 hadoop-env.cmd 中大约25行
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_241
一定确保你的jdk路径是正确的。
Program Files == PROGRA~1
黑窗口先关闭,再打开即可。
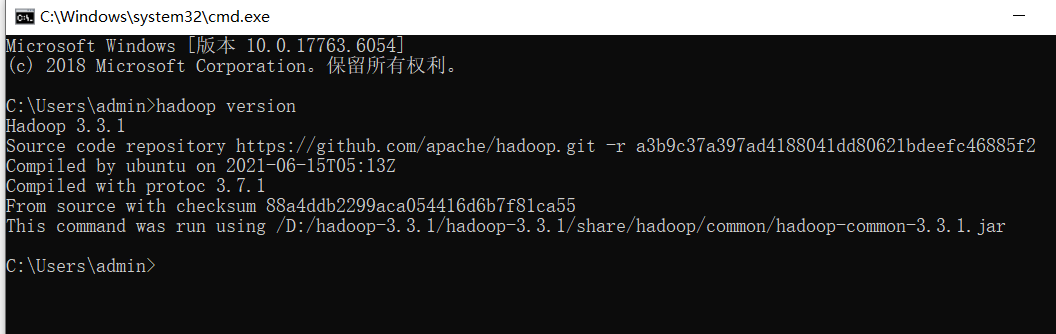
最后一项:
粘贴一个补丁文件:
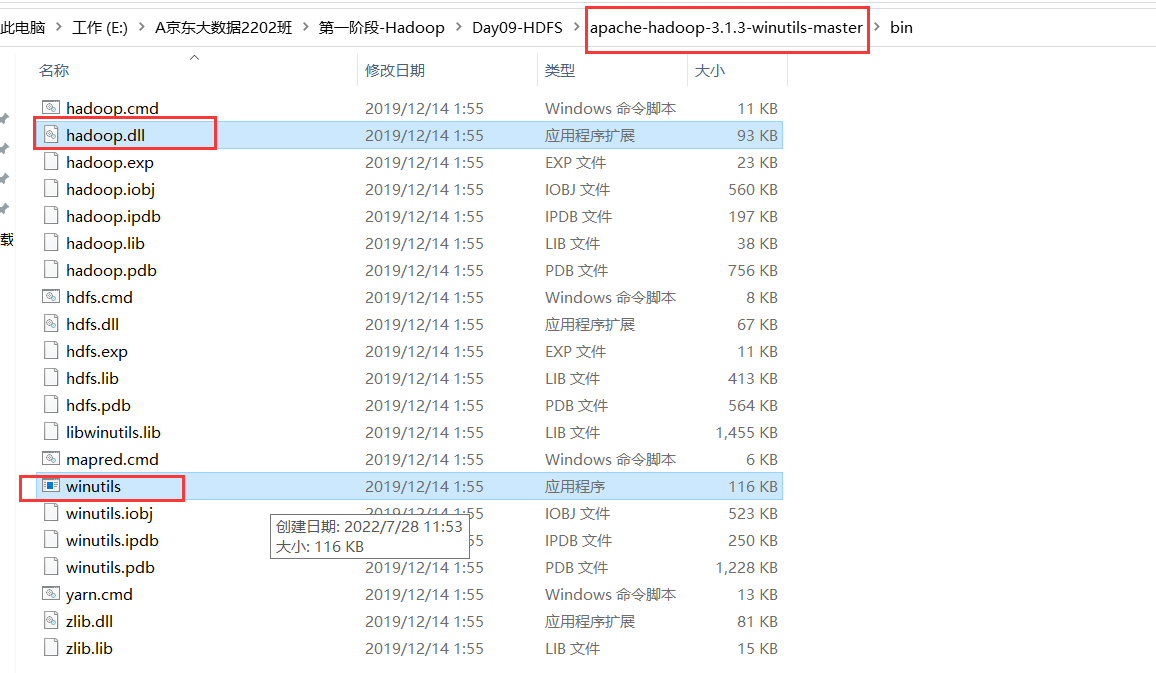
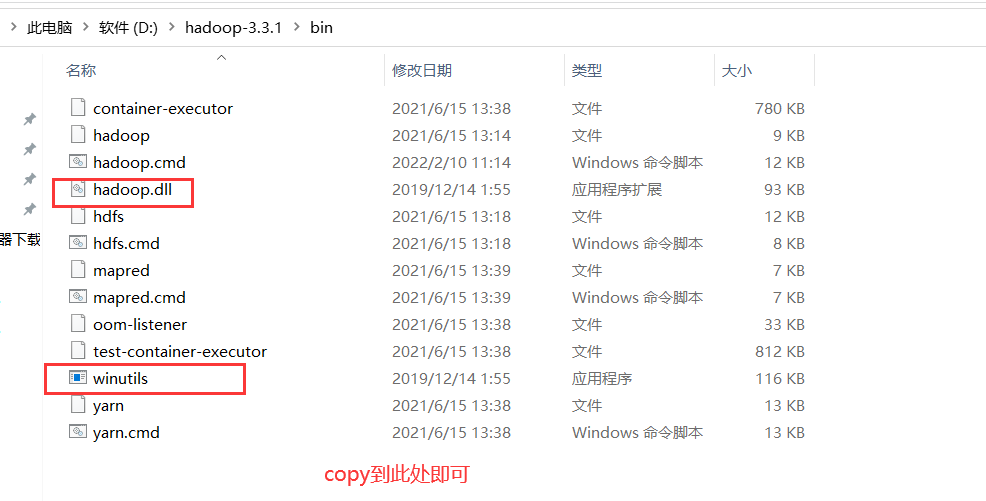
:::color2
另外,假如你的 java 版本有问题,也会报这个错误,比如我们需要 64 位的操作软件,你安装了一个 32 位的,请卸载 jdk,并重新安装和配置环境变量。
:::
2、单元测试(Junit)
类似于Main方法。
首先需要导入Junit包:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
第二步:写单元测试代码
最好写在test 文件夹下(专门写测试的文件夹)
单元测试方法:
1、方法上必须有@Test注解
2、方法必须是public void 开头
3、方法没有参数
4、不要将类名写成Test,后果自负
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/7/28 14:17
* @Version 1.0
*/
public class TestUnit {
@Before // 每次单元测试方法执行前都会执行该方法 该方法一般存放一些初始化的代码
public void init(){
System.out.println("我是开始代码");
}
@After// 每次单元测试方法执行后都会执行该方法 该方法一般都是存放一些连接关闭等收尾工作
public void destory(){
System.out.println("我是结束代码");
}
@Test // 该方法即一个单元测试方法,这个方法是一个独立的方法,类似于Main方法。
public void testA(){
System.out.println("Hello World!");
}
@Test
public void testB(){
System.out.println("Hello World!");
}
}
以下是通过chatgpt帮我生成的代码:
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class MyUnitTest {
@Before
public void setUp() {
// 在每个测试方法之前执行的准备工作
System.out.println("setUp() method called");
}
@After
public void tearDown() {
// 在每个测试方法之后执行的清理工作
System.out.println("tearDown() method called");
}
@Test
public void testMethod1() {
// 测试方法1
System.out.println("testMethod1() called");
// 添加测试逻辑和断言
}
@Test
public void testMethod2() {
// 测试方法2
System.out.println("testMethod2() called");
// 添加测试逻辑和断言
}
}
第三步:使用java代码连接hdfs
获取hdfs连接的四种方法:
首先导入需要的jar包:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
代码演示:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
public class TestHDFS {
@Test
public void getHDFS() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://bigdata01:9820");
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem);
}
@Test
public void getHDFS2() throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://bigdata01:9820"),configuration);
System.out.println(fileSystem);
}
@Test
public void getHDFS3() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://bigdata01:9820");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem);
}
@Test
public void getHDFS4() throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://bigdata01:9820"),configuration);
System.out.println(fileSystem);
}
}
通过代码上传一个文件到hdfs上。
public class Demo02 {
@Test
public void testUpload() throws Exception {
System.setProperty("HADOOP_USER_NAME","root");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.32.128:9820");
FileSystem fileSystem = FileSystem.get(configuration);
Path localPath = new Path("D:\\a.txt");
Path hdfsPath = new Path("/");
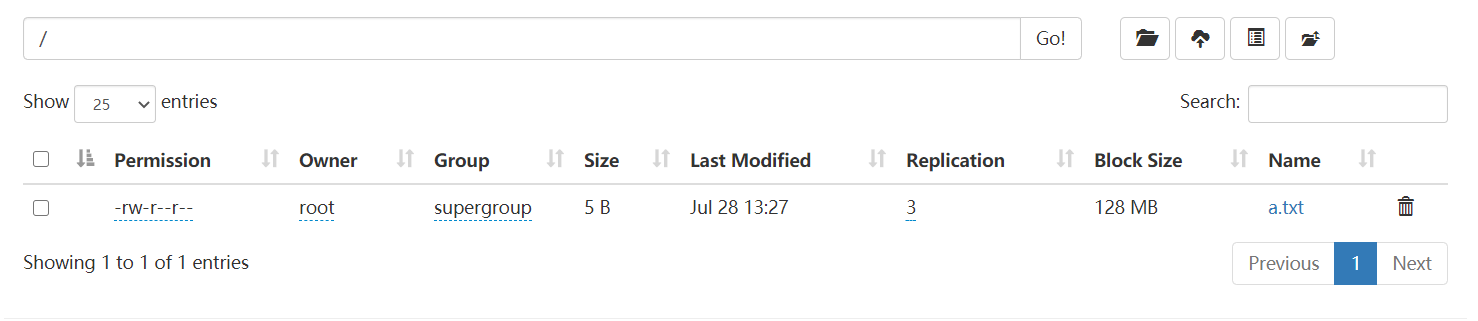
fileSystem.copyFromLocalFile(localPath,hdfsPath);
System.out.println("上传成功!");
}
}

添加这一句话,需要在init的第一句。否则可能不起作用。
System.setProperty("HADOOP_USER_NAME","root");
package com.bigdata;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class HdfsUtils {
private FileSystem fileSystem;
@Before
public void setUp() throws IOException {
System.setProperty("HADOOP_USER_NAME","root");
// 在每个测试方法之前执行的准备工作
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://bigdata01:9820"); // 设置 HDFS 地址
fileSystem = FileSystem.get(conf);
}
@After
public void tearDown() throws IOException {
// 在每个测试方法之后执行的清理工作
fileSystem.close();
}
@Test
public void testUploadFile() throws IOException {
String localFilePath = "C:\\Users\\admin\\Desktop\\edip";
String hdfsFilePath = "/";
fileSystem.copyFromLocalFile(new Path(localFilePath), new Path(hdfsFilePath));
}
@Test
public void testCreateFile() throws IOException {
String hdfsFilePath = "/newfile.txt";
fileSystem.createNewFile(new Path(hdfsFilePath));
}
@Test
public void testDownloadFile() throws IOException {
String hdfsFilePath = "/newfile.txt";
String localFilePath = "C:\\Users\\admin\\Desktop\\file.txt";
fileSystem.copyToLocalFile(new Path(hdfsFilePath), new Path(localFilePath));
}
@Test
public void testDeleteFile() throws IOException {
String hdfsFilePath = "/newfile.txt";
fileSystem.delete(new Path(hdfsFilePath), false);
}
@Test
public void testMkDir() throws IOException {
fileSystem.mkdirs(new Path("/input"));
System.out.println("创建文件夹成功");
}
@Test
public void testRename() throws IOException {
fileSystem.rename(new Path("/edip"),new Path("/aaa.txt"));
}
// 打印 一个目录下的所有文件,包含文件夹中的文件
@Test
public void testLs() throws Exception {
// rm -r
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path("/"), true);
while(iterator.hasNext()){
LocatedFileStatus locatedFileStatus = iterator.next();
System.out.println(locatedFileStatus.getPath().getName());
}
}
// 返回当前目录下的所有文件以及文件夹
@Test
public void testList2() throws Exception {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath().getName());
}
}
}
3、常见错误
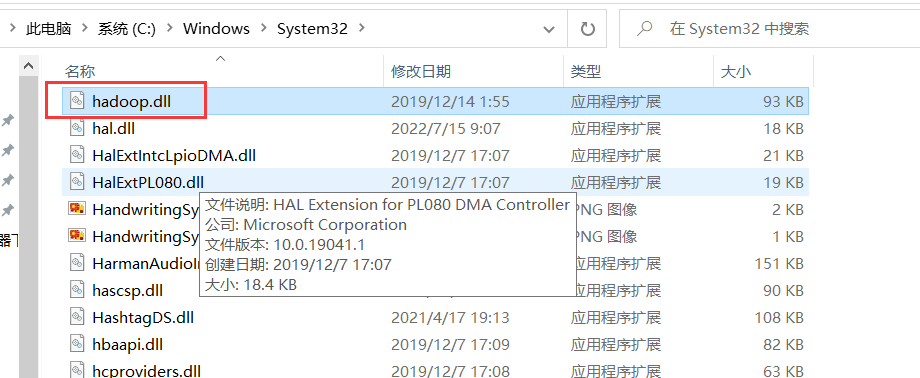
**1) 下载中**如果报错了:
需要将hadoop.dll 拷贝到 C:\windows\system32 这个文件夹下一份
- 9820 误写成 9870
:::warning
9820:是 hdfs 的内部通信端口。
9870:是 hdfs 的 web 端口,用于访问 hdfs 的页面的
:::

















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









