




 HDFS是Hadoop的核心组件,用于大规模数据存储。集群架构包括NameNode和DataNode,NameNode管理元数据,DataNode存储数据块。HDFS支持一次写入、多次读取,但不适合大量小文件存储。每个数据块通常被复制三次,以确保容错性。
HDFS是Hadoop的核心组件,用于大规模数据存储。集群架构包括NameNode和DataNode,NameNode管理元数据,DataNode存储数据块。HDFS支持一次写入、多次读取,但不适合大量小文件存储。每个数据块通常被复制三次,以确保容错性。
一,分布式系统概述
Hadoop的两大核心组件
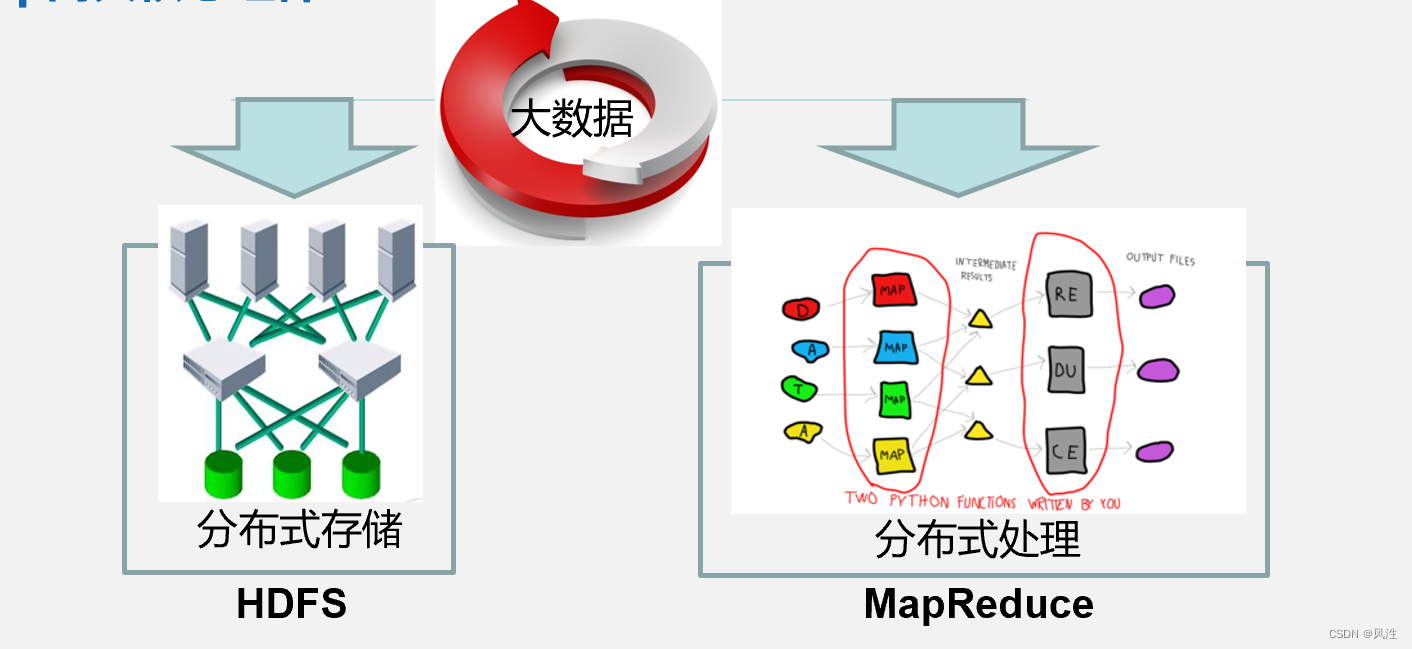
HDFS(Hadoop Distributed Filesystem):是一个易于扩展的分布式文件系统,运行在成百上千台低成本的机器上。HDFS具有高度容错能力,旨在部署在低成本机器上。HDFS主要用于对海量文件信息进行存储和管理,也就是解决大数据文件(如TB乃至PB级)的存储问题,是目前应用最广泛的分布式文件系统。
分布式系统的演变: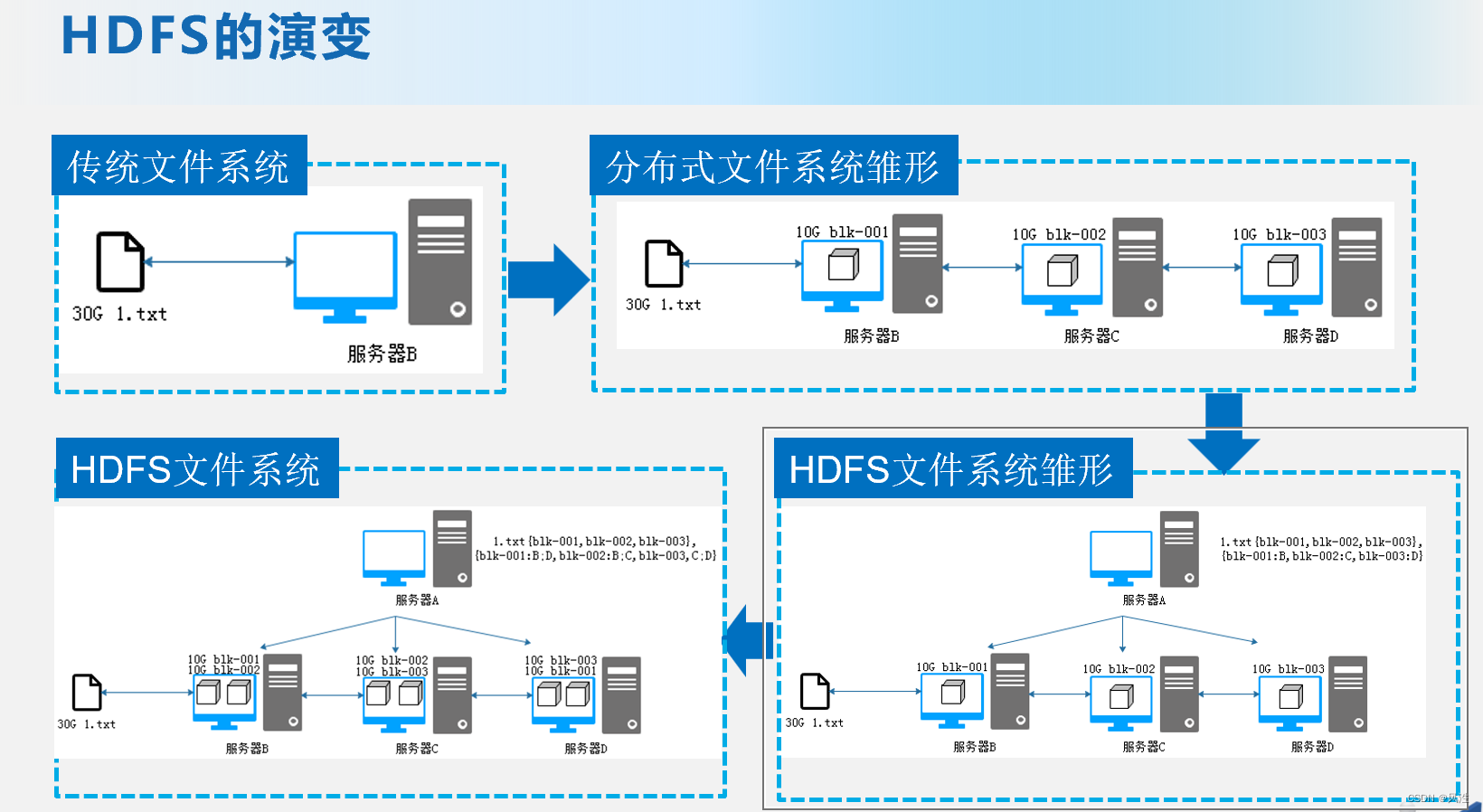
传统文件系统遇到的问题 :
传统文件系统的问题:
•当数据量越来越大时,会遇到存储瓶颈,需要扩容;
•由于文件过大,上传下载都非常耗时
分布式文件系统的雏形:
•横向扩容,即增加服务器数量,构成计算机集群
•将大文件切割成多个数据块,将数据块以并行的方式,分布地在多个计算机节点上进行存储、读取
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4014
4014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









