






 博主遇到了在VSCode中使用Python的requests库获取网页源码时,输出到终端的内容不完整的问题。经排查,发现是VSCode编辑器的限制导致。为解决此问题,博主尝试了将源码写入文件的方式,通过创建b.txt文件来完整保存网页源码。虽然这不是最理想的解决方案,但能暂时解决问题。同时,博主对VSCode和VS2019进行了对比,后者能正常显示完整源码。
博主遇到了在VSCode中使用Python的requests库获取网页源码时,输出到终端的内容不完整的问题。经排查,发现是VSCode编辑器的限制导致。为解决此问题,博主尝试了将源码写入文件的方式,通过创建b.txt文件来完整保存网页源码。虽然这不是最理想的解决方案,但能暂时解决问题。同时,博主对VSCode和VS2019进行了对比,后者能正常显示完整源码。
更新一下。
giao,找到解决方案了,这是一个输出信息太长,终端输出不全的问题。已经有很多大佬提出解决方案了。
这好像是vscode的这个编辑器的问题,我换用了vs2019就获得了完整源码。我到现在都没搞明白,vscode哪里出了问题。
我从别人的文章找到了解决方法:就是不用print函数输出,而是将源代码写进一个文件,从文件中查看网页源代码。这个方法可以获得完整的网页源代码,但我感觉有点不方便,这么看源代码有点别扭。诶,vscode这方面到底是先天不足,还是我环境搭建有问题。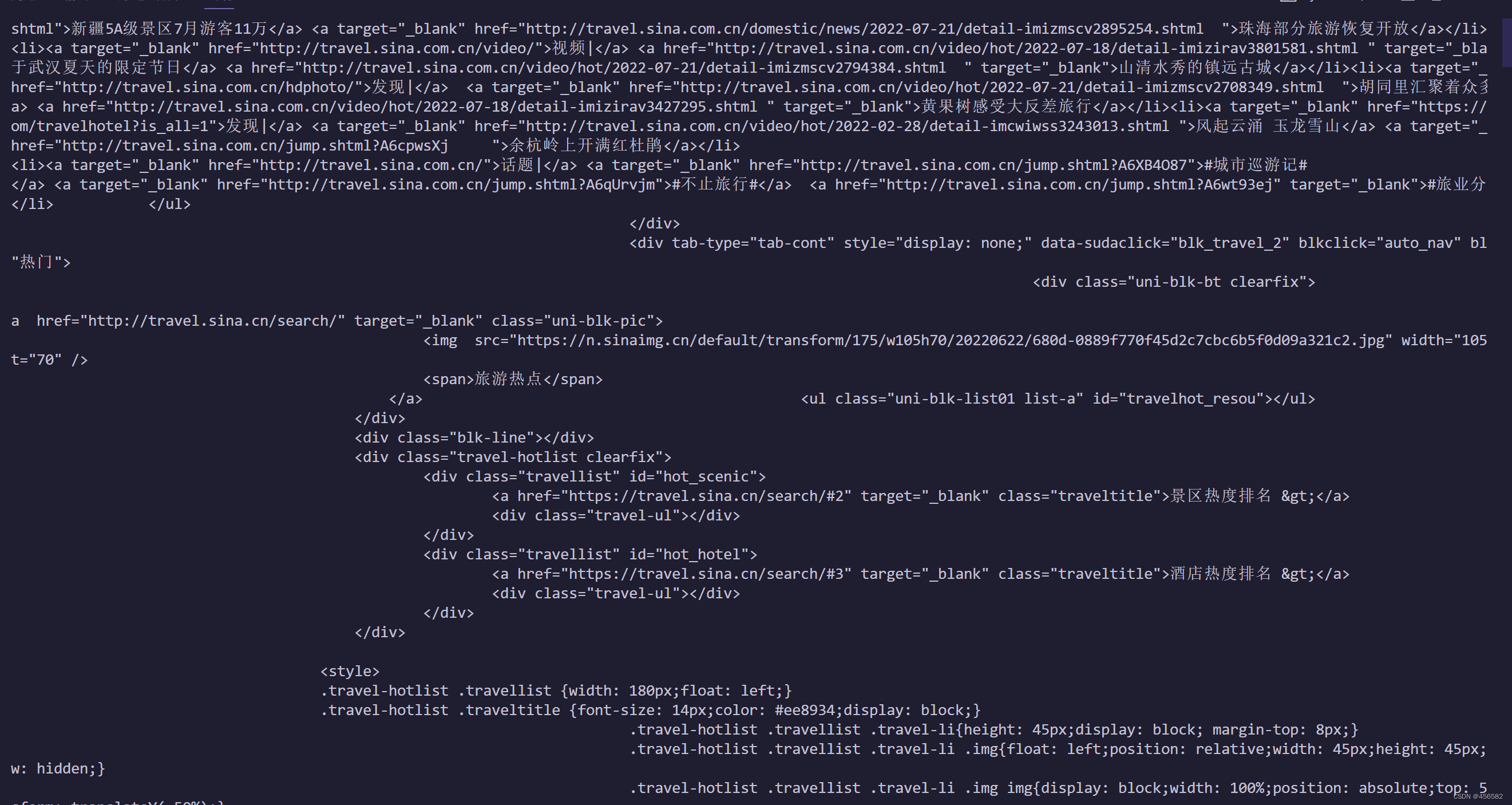
少了开头到将近中间的那一半
import requests
import re
url = "https://www.sina.com.cn/"
response = requests.get(url)
print(response.status_code)
response.encoding = "utf-8"
page_txet = response.text
with open("b.txt","w+",encoding="utf-8") as f:
f.write(page_txet)
用with f 将源代码写进b.txt中
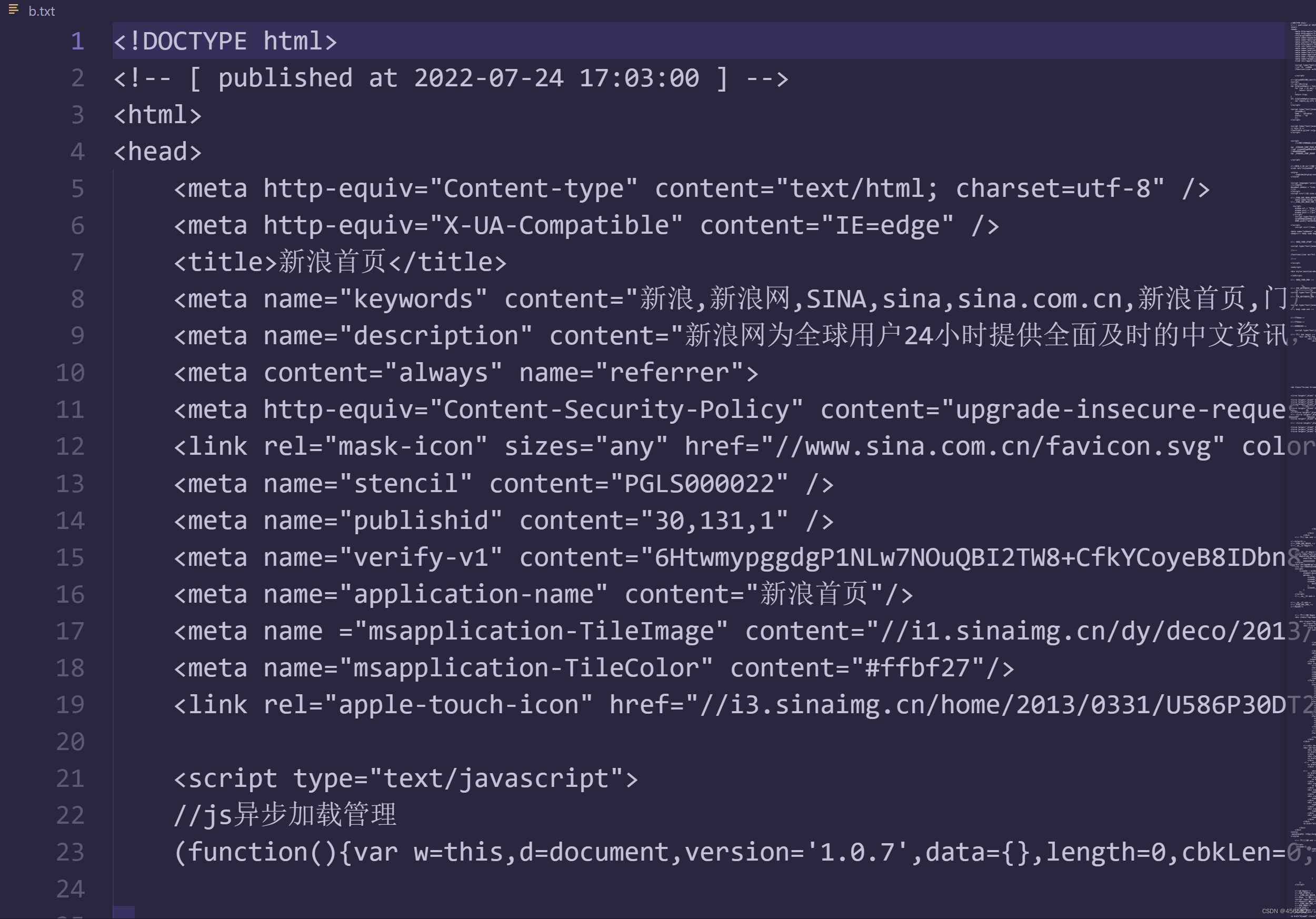
就能得到完整的源代码了
这个方法只是个补丁,不知道有没有大佬能真正解决这个问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









