






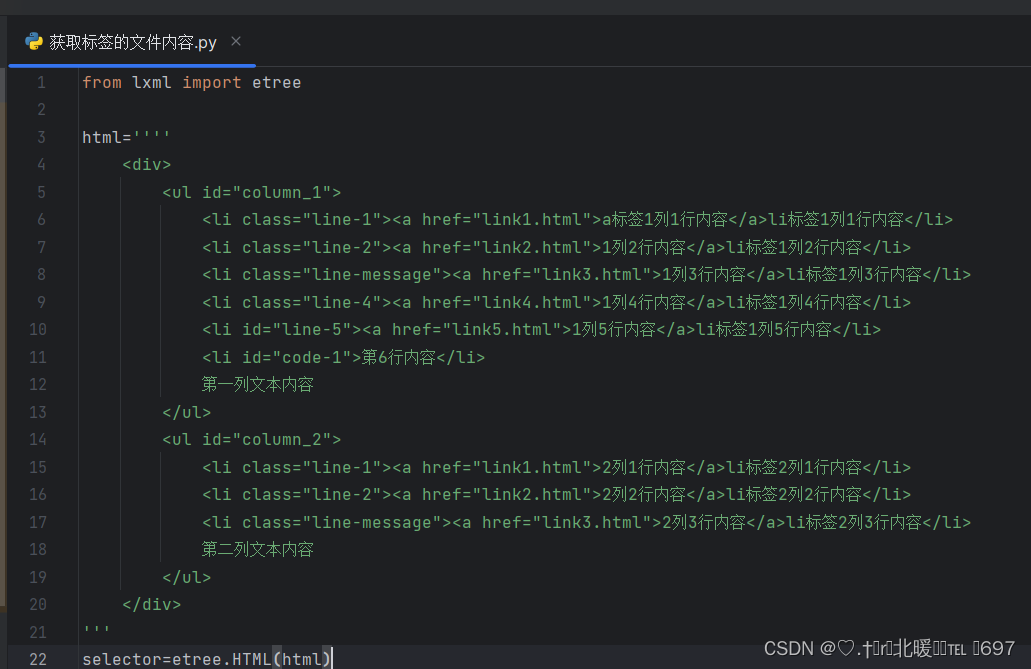
1.首先我们应该在pythonProject里创建一获取网页标签内容的文件,为了更好地区分每个文件的作用,那我们的命名就要清楚明了,因此,我们就将这次文件的内容命名为“获取标签的文本内容”。
我们应该在这选择我们要创建的文件类型,
再输入文件的名字,以便与其他的文件用作区分。
2.文件创建好了之后,我们就应该先下载lxml,为了更好地获取数据,在终端使用pip install lxml来进行下载

下载完成之后,我们就可以开始获取我们网页的数据了
这是我们在使用lxml对我们的网页进行一个数据的获取
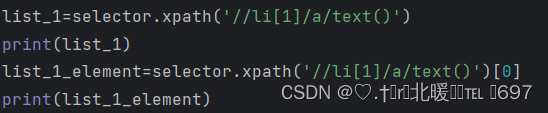
3.当我们要获取【li】中第一个【li】标签下的a元素文本时,就要使用以下代码来进行获取。
4.当我们想要通过class属性定位查找出已知的html中的标签属性和a元素文本内容时,

5.想要通过href属性定位查找出标签属性和啊元素文本内容时,

6.当我们想要通过某种特殊文本内容查找的想要的文本内容时,

如果我们想要获取文本中包括“line-”的所有文本内容时,“”里面输入我们想要查找的文本就可以了,当然了,获取指定的文本内容肯定不止这一种方法,其余的还需要大家多多发现。
7.当我们想要获取网页中所有的元素时,就要通过网页的url地址来进行获取

在代码中还有很多种方法来获取网页的内容,大家也都要努力啊!!!















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









