






在介绍正题之前,先来个开胃菜,介绍一个好玩的东西:charmap面板!
(注意:这个和正题内容没有任何关系,不想看的直接翻过去即可👇👇👇)
打开方式:键盘组合键:win(开始)+R;输入内容:“charmap”;按下键盘中的“Enter”键
这里面有着大量的符号和各种小图,根据代码进行输入即可实现,先举个例子:
我们先打开这个面板:
我们将鼠标悬停到每一个符号上面的时候,它会显示对应的编码和名字,我们尝试着用代码表示出来:
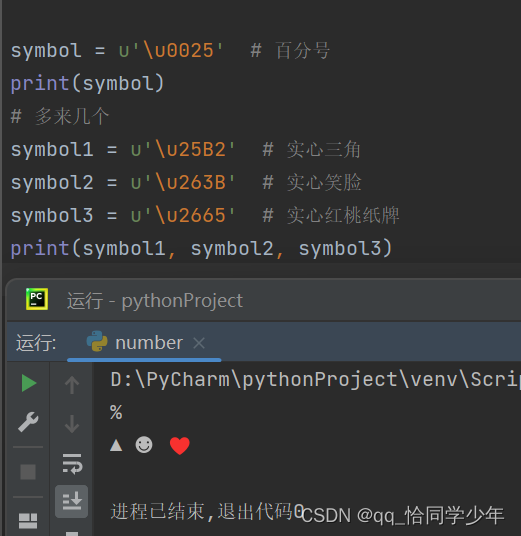
下面我们进入正题:
首先,我介绍一下什么是“质数”, 什么是“合数(想必有朋友想了:小学水平的知识还用介绍?)。哈哈哈,的确是这样。而我这么做就是让大家再次明确一下质数和合数的区别:
除了1和自身以外有没有其他整除因数。
1、质数:质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
2、合数:合数是指在大于1的整数中除了能被1和本身整除外,还能被其他数(0除外)整除的数。
另外,需要说明一下,为了便于观察,我尽量将它们放到列表中。
1、输出n以内的所有质数 思考:为什么lst的定义要放在for循环的里面
lst1 = []
for s in range(2, 101):
lst = []
for i in range(2, s):
if s % i == 0:
lst.append(i)
if not lst: # 这里相当于 if lst == []:
lst1.append(s)
print(lst1)这个还比较简单,大家应该都能看懂,按照大多数人的需求,直接输出100以内的质数,让n等于100。当然,如果大家想换其它值的话,直接将这个101改掉就行了,下面的也一样。有人可能会问,for循环里为什么是101,关于这个问题,建议先了解for循环的结构和相关语法。
2、输出n以内的合数,求其所有因数
for s in range(2, 10001):
lst = []
lst1 = []
for i in range(2, s):
if s % i == 0:
lst.append(i)
if lst: # 这里相当于 if lst != []:
print(s, "不是质数", end="\t")
for j in range(2, s):
if s % j == 0:
lst1.append(j)
print(s, "的因数有:", lst1)这个我让n直接等于10000,我是有其他目的的,可以到最后一部分进行查看哦!
3、输出n以内的合数,求其所有质因数
for s in range(2, 101):
lst = []
lst3 = []
for i in range(2, s):
if s % i == 0:
lst.append(i) # 如果列表为空列表,则为质数,否则是合数
if lst: # 这里相当于 if lst != []:
print(s, "不是质数")
print(s, "的因数有:", lst)
for k in lst:
lst2 = []
for m in range(2, k):
if k % m == 0:
lst2.append(m)
if not lst2:
lst3.append(k)
print(s, "的质因数有:", lst3)
else:
print(s, "是质数")这个同样是将n弄成了100。
4、输出n以内的合数,将其分解质因式
def prime(n): # 一个判断质数的函数,如果是质数,返回这个数,如果不是质数,不返回
for i in range(2, n):
if n % i == 0:
break
else:
return n
for num in range(2, 101):
n = num
i = 1 # 设置“哨兵变量”为1
lst = [n, "=", ]
if num >= 2:
while i <= num: # 注意这里一定要用while语句循环,因为“哨兵变量”最后要被更新
i = i + 1
if num % i == 0:
lst.append(prime(i))
lst.append("*")
num = num / i # 此时更新一下num
i = 1 # 记得把哨兵重新设置为1,这样循环才会更新,for语句循环,无法从头开始循环
lst.pop() # 删除最后一个乘号
print("分解式:", end="")
for j in lst:
print(j, end="")
print("\n")
else:
print("error") # 不符合条件,就输出错误由于这个实现起来比较麻烦,动用了函数的定义调用,希望大家能够看懂,如果对函数的定义和调用不太明白的,可以先去找一些简单的例子学习一下。
5、输入一个数,判断,质数直接输出,合数求其所有因数
s = int(input("请输入一个数字: "))
lst = []
lst1 = []
for i in range(2, s):
if s % i == 0:
lst.append(i)
if lst: # 这里相当于 if lst != []:
print(s, "不是质数")
for j in range(2, s):
if s % j == 0:
lst1.append(j)
print(s, "的因数有:", lst1)
else:
print(s, "是质数")
6、输入一个数,判断,质数直接输出,合数求其所有质因数 思考:为什么lst2的定义要放在for循环的里面
s = int(input("请输入一个数字: "))
lst = []
lst3 = []
for i in range(2, s):
if s % i == 0:
lst.append(i) # 如果列表为空列表,则为质数,否则是合数
if lst: # 这里相当于 if lst != []:
print(s, "不是质数")
print(s, "的因数有:", lst)
for k in lst:
lst2 = []
for m in range(2, k):
if k % m == 0:
lst2.append(m)
if not lst2:
lst3.append(k)
print(s, "的质因数有:", lst3)
else:
print(s, "是质数")
7、输入一个数,判断,质数直接输出,合数将其分解质因式
def prime(n): # 一个判断质数的方法,如果是质数,就返回这个数,如果不是质数,就什么也不返回
for i in range(2, n):
if n % i == 0:
break
else:
return n
num = int(input("请输入一个数字: "))
n = num # 这里是因为到最后num的值发生了变化,等式需要用原来的值进行表示
i = 1 # 设置哨兵变量为1
lst = [n, "=", ]
if num >= 2:
while i <= num: # 注意这里一定要用while语句循环,因为“哨兵变量”最后要被更新
i = i + 1 # 尝试遍历从1到num的所有数
if num % i == 0:
lst.append(prime(i))
lst.append("*")
num = num / i # 此时更新一下num
i = 1 # 记得把哨兵重新设置为1,这样循环才会更新,用for语句循环,无法从头开始循环
lst.pop() # 删除最后一个乘号
print("分解式:", end="")
for j in lst:
print(j, end="")
else:
print("error") # 不符合条件,就输出错误关于质数和合数的相关操作我介绍的也差不多了,我想到的大概只有这些了,如果大家还有其他的,欢迎在评论区进行补充。
下面来简单介绍一下上面我将 n 设置成10000的目的:
实际上,这个和咱们的主题无关,只不过在这个过程中我做的一个尝试而已。
针对上面那个代码,我做了一个简单的测试,虽然这个测试并没有做完,但是从结果上来看已经很明显了,我先把结果放上让大家看看。
看到这个图,我想大家已经明白了,就是在n取不同的值的情况下,执行代码所需要的时间。在n小于10000的时候,基本上看不出什么变化。10000次和1000次循环所需时间差不多就是十倍的关系。但是当把n的值增加到20000和30000甚至100000的时候,时间的差距便体现出来了,而且十分明显。
不过令大家失望的是,根据这些数据,我并没有得出十分明确的结论,为什么这样说呢,因为随着n的值发生变化,每一次循环所处理的数据量也会随之增加,从而导致每一次循环所需时间发生差异,所以后面的时间变化便可以理解了。
好了,本来就只是把质数合数相关的内容弄完就差不多了,前后加的两个内容就当看着玩吧,如果实在想进一步了解的,大家可以自己去尝试一下,如果对代码有什么问题的小伙伴,当然也欢迎评论留言哦!

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









