






一、量化的 编码-解码:零点值的双重身份
1. 编码阶段(量化)
- 零点值作为标尺零点:将浮点数的0精确映射到整数范围(例如INT8的128),相当于建立了一个新的坐标系。
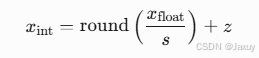 ,这里的z是浮点0的整数化身,确保量化后0的真实性。
,这里的z是浮点0的整数化身,确保量化后0的真实性。
2. 解码阶段(反量化)
- 零点值作为还原基准:计算完成后,需通过零点值将整数结果恢复为浮点值
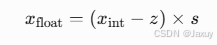 ,减去零点值是为了解除量化阶段的坐标系偏移,还原到原始浮点空间。
,减去零点值是为了解除量化阶段的坐标系偏移,还原到原始浮点空间。
二、计算时为何必须暂时减去零点值?
1. 数学本质:消除系统偏移
- 量化后的整数是偏移数:若直接使用
计算,所有数值都叠加了z的偏移,导致计算结果整体偏离。例如:
,将会引入交叉项和二次项误差。
2. 硬件计算的优化需求
- 避免冗余计算:在计算前减去零点值,可将所有操作统一到无偏移的坐标系中,使乘加运算的硬件电路无需处理额外的偏移补偿逻辑。
三、减去零点值后如何保证精度?
1. 计算流程分析:
- 首先,输入预处理:
- 其次,开始硬件计算:
- 最后,结果还原:
2. 数值稳定性分析:
- 输出零点值会重新引入偏移,确保最终结果与浮点模型对齐。
- 所有中间计算均在无偏移空间进行,避免了偏移量的逐层放大。
总结:矛盾背后的统一
- 编码时:零点值是浮点0的守护者,确保量化不扭曲基准。
- 计算时:零点值是误差的隔离墙,通过暂时消除自身,保证计算的纯粹性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









