






Redis主要有以下的数据结构:
- SDS,链表,压缩链表,哈希表,整数集合,跳表,quicklist,listpack
目录
一、SDS(简单动态字符串)
Redis是通过C语言实现的,但是却未延用C语言的char字符数组来实现字符串,而是封装了一个SDS简单动态字符串的数据结构实现字符串,原因如下:
- C语言字符串依靠识别末尾的 '\0',来判断字符串的结束与长度。
- 获取字符串长度时间复杂度为O(n),效率低。
- 且字符串中不能存放 '\0' 字符,否则字符串识别会提前结束。
- 且因为 '\0' 的存在导致char字符数组只能存储文本数据。
- C语言字符数组不记录本身缓冲区大小,容易发生缓冲区溢出
所以SDS简单动态字符串解决了以上字符数组问题,使得字符串效率更高,应用更广泛等
SDS设计了如下成员变量:
- len:记录了字符串长度,获取字符串长度时间复杂度变成了O(1)。
- alloc:记录分配给字符数组的空间长度,可通过alloc-len计算出缓冲区剩余空间容量,若空间不足SDS则会进行扩容,从而避免缓冲区溢出
- 扩容规则:若所需SDS长度小于1MB,则分配所需空间的2倍;若所需SDS长度大于1MB,则分配所需空间+1MB的空间大小
- 为减少内存分配次数,SDS扩容时SDS API还会为SDS分配额外的 [未使用空间],下次内存足够可直接使用 [未使用空间]。
- flags:记录SDS的类型
- 分别有sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64五种类型,不同类型中len和alloc成员变量的数据类型不同,存储的字符数组的长度和分配空间长度对应不同
- 在struct声明了__attribute__ ((packed)),作用是取消编过程的优化对齐,按照实际占用字节数进行对齐
- buf[]:字符数组,保存实际数据
二、链表
Redis实现的链表为双向链表,每个链表节点封装了指向前节点及后节点的指针
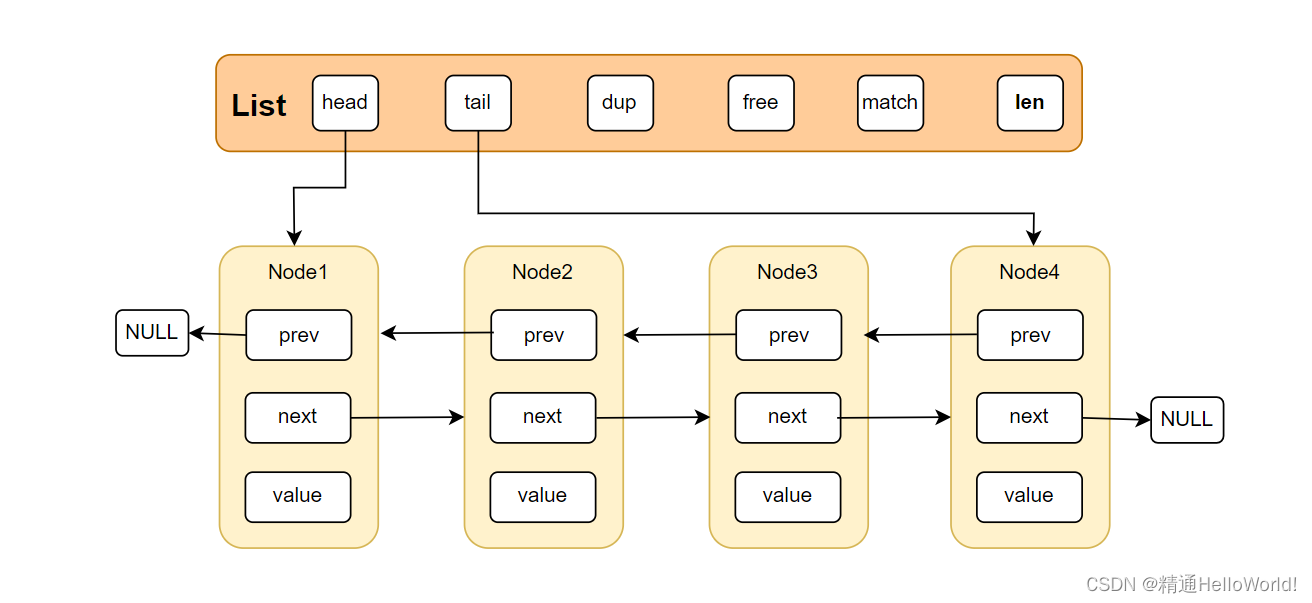
List链表结构如下:
- ListNode *head:List链表的头节点。
- 其中链表节点封装了一下成员变量:(由于每个节点都记录了前置节点和后置节点,所以该List链表为双向链表,遍历查找更加便利)。
- ListNode *prev:该节点的前置节点
- ListNode *next:该节点的后置节点
- void *value:该节点的值
- 其中链表节点封装了一下成员变量:(由于每个节点都记录了前置节点和后置节点,所以该List链表为双向链表,遍历查找更加便利)。
- ListNode *tail:List链表的尾节点。
- void *(*dup)(void *prt):节点值复制函数。
- void (*free)(void *prt):节点值释放函数。
- int (*match)(void *prt, void *key):节点值比较函数。
- unsigned long len:List链表节点数量,可直接返回链表节点数量,时间复杂度为O(1)。
三、压缩列表
压缩列表是类似于数组的连续型内存空间的顺序型数据结构
压缩列表的表头组成:
- zlbytes:记录整个压缩列表占用的内存字节数
- zltail:记录压缩列表尾部节点距离起始地址有多少字节(列表尾的偏移量)
- zllen:记录整个压缩列表包含的字节数量
- zlend:记录压缩列表的结束点,固定值0xFF
压缩列表的节点组成:
- prevlen:记录前一节点的长度
- 前一节点长度小于254字节,prevlen需要使用1字节空间来保存该长度值
- 前一节点长度大于254字节,prevlen需要使用5字节空间来保存该长度值
- encoding:记录当前节点数据的类型(字符串、整数) 和长度
- data:记录当前节点的数据

压缩列表的连锁更新问题:由于前一节点的长度会导致所使用的字节空间不同,所以当链表头部节点更改时会导致下一节点的prevlen改变,进而该节点长度改变,导致下一节点prevlen改变,直到尾部节点改变,这样会导致压缩列表占用的内存空间要多次重新分配
又因为压缩列表字段仅便于查找头部节点和尾部节点,所以
压缩列表只适合保存节点较少的情况!
四、哈希表
Redis保存是一种key-value结构,哈希表的结构则是在Redis的value中保存key-value结构,每一个key都是唯一标识一个value,并且哈希表的查找时间复杂度为O(1)。
哈希表结构:
- dictEntry **table:哈希表的数组
- unsigned long size:哈希表的总大小
- unsigned long sizemask
- unsigned long used:哈希表已存入的节点数量
哈希表节点结构:
- key:键
- value:值
- next:哈希冲突时指向下一节点连接形成哈希桶
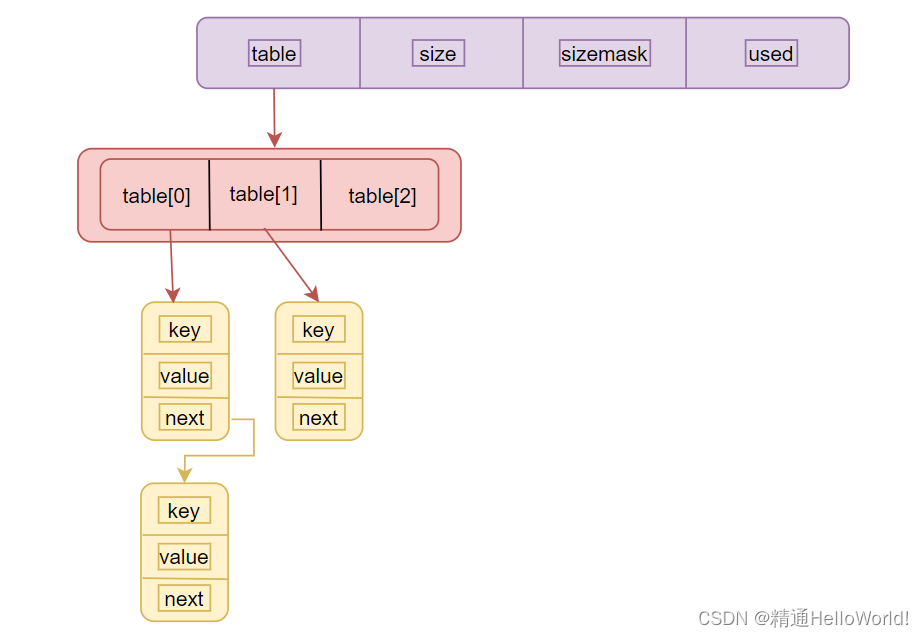
哈希表实质上是一个数组,首先会对存入的键计算哈希值,不同值对应数组不同位置,当哈希值相同时则形成了哈希冲突,此时可以通过链式哈希解决,通过每一个哈希节点的next指针连接,形成一个链式的结构连在数组的该位置。
当哈希表链表长度过长,查找效率就会降低,所以当链表长度过长会对哈希表进行扩容(rehash)
rehash
Redis定义的dict结构中定义了两个哈希表,一般只会存储到哈希表1中,哈希表2不会分配内存,随着哈希表1的逐渐增多,触发rehash操作:
- 给哈希表2分配哈希表1两倍大小的内存
- 将哈希表1的数据复制到哈希表2中
- 释放哈希表1的内存,将哈希表2变为哈希表1,并创建一个未分配内存的哈希表2
渐进式rehash
rehash中第二步对哈希表1复制到哈希表2时,若拷贝数据量过大则会导致服务阻塞停止,所以渐进式rehash主要思想就是将哈希表1到哈希表2的赋值操作分批次进行,避免redis长时间阻塞
- 给哈希表2分配哈希表1两倍大小的内存
- 在对哈希表进行增删改查的时候执行当前操作后,并将哈希表1对应数据复制到哈希表2中
- 在执行的操作逐渐增多时,哈希表1的数据全部被复制到哈希表2中,完成rehash
五、整数集合
整数集合是类似于数组的连续型内存空间的顺序型数据结构,所以该结构适合于少量数据的情况,并且该结构只能保存整数数据
整数集合结构:
- uint32_t encoding:整数集合编码方式,编码方式决定了contents数组类型(编码方式INTSET_ENC_INT16 对应数组类型 int16_t)
- unit32_t length:该整数集合包含的数据数量
- int8_t contents[]:保存整数集合数据的数组
初始化时整数集合数组类型为int16_t,当插入的数据为int32_t比数组类型长时,此时需要对该整数集合进行升级,即将当前数组类型int16_t扩展为int32_t类型
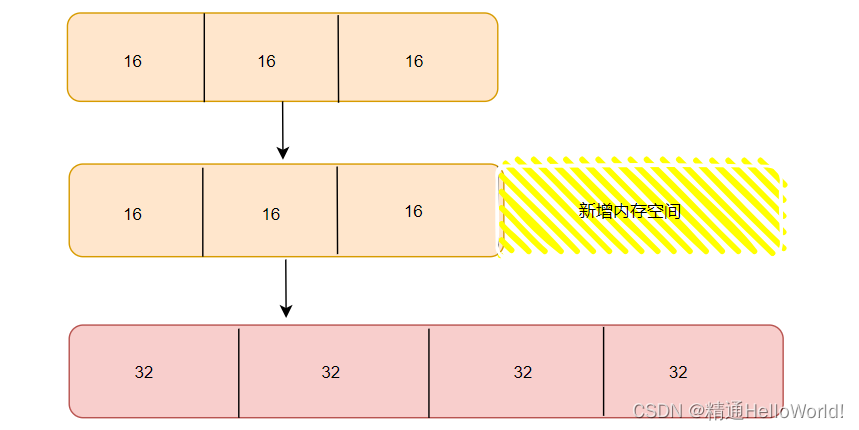
整数集合升级可以对于存放不同长度的数据进行灵活处理,在未存储较长长度数据时,可以开辟较小内存空间,从而节约内存空间,而后续如果需要存放较长数据时,就可对整数集合进行升级
六、跳表
跳表是基于链表的一种结构,跳表每一个节点可有多层结构,便于节点查询操作
跳表结构zkiplist:
- structzkiplistNode *header,*tail:该跳表的头节点,尾节点
- unsigned long length:该跳表的长度
- int level:该跳表的节点最大层数
跳表节点结构zkiplistNode:
- sds ele:存入的数据值
- double score:数据的权重值
- struct zskiplistNode *backward:后向指针(指向前一节点)
- 多层节点数组结构zkiplistLevel level[]:
- struct zkiplistNode *forward:指向跳表下一节点的指针
- unsigned long span:到跳表下一节点的跨度

七、quicklist
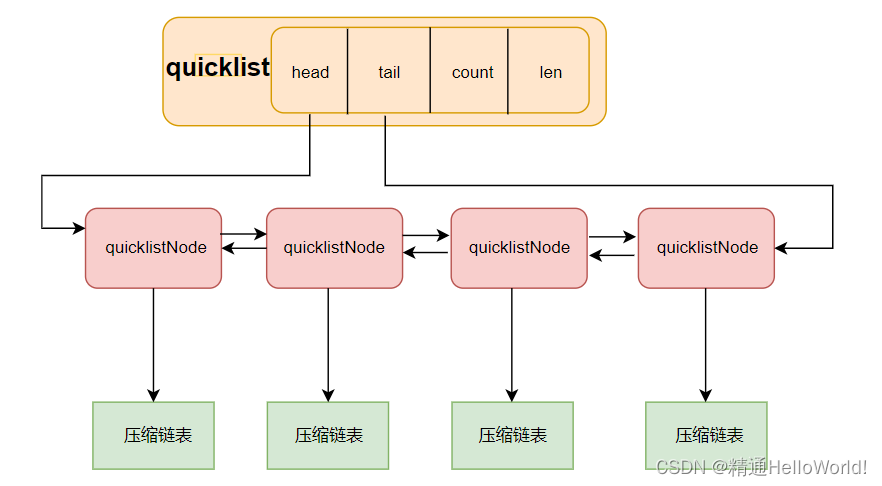
quicklist本质是双向链表加压缩表形式,双向链表的每一个节点都是压缩链表
quicklist结构:
- quicklistNode *head:quicklist链表的头节点
- quicklistNode *tail:quicklist链表的尾节点
- unsigned long count:quicklist链表及压缩链表中的所有节点个数
- unsigned long len:quicklist链表的节点个数
quicklist链表节点quicklistNode结构:
- struct quicklistNode *prev:该节点的前节点
- struct quicklistNode *next:该节点的后节点
- unsigned char *zl:该节点指向的压缩链表
- unsigned int sz:压缩链表的字节大小
- unsigned int count:压缩链表的元素个数
八、listpack
listpack也是类似于数组的连续型内存空间的顺序型数据结构,实质上是改变了压缩链表的结构,为了解决压缩列表连锁更新问题,listpack去掉了压缩链表记录前一节点长度变量
listpack结构:
- total bytes:记录整个压缩列表占用的内存字节数
- num elem:记录整个压缩列表包含的字节数量
- End:记录压缩列表的结束点,固定值0xFF
listpack节点结构:
- len:记录encoding+data总长度
- encoding:记录当前节点的编码类型
- data:记录当前节点的数据

总结:
- 压缩链表不适合数据过多,适合少量数据及数据变化量小
- 哈希表适合保存对象数据且对数据操作较简单
- 整数集合只适用于保存整数对象且数据量少
- 跳表的查询效率较双向链表更快
总结完数据结构,接下来就是基于数据结构实现的数据类型:Redis-数据类型















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









