






目录
前言
⭐ 本文基于学校的课程内容进行总结,所爬取的数据均为学习使用,请勿用于其他用途
一、准备工作
在开始爬取之前,我们需要做好以下准备工作:
- 确定目标网站:首先,明确要爬取的学校官网地址,并熟悉其新闻发布页面的结构和规律。
- 安装必要的库:使用Python进行网络爬虫需要安装一些必要的库:
requests:是一个 Python 的 HTTP 客户端库,使用requests可以方便地发送所有类型的 HTTP 请求。lxml:是一个用于处理 XML 和 HTML 文档的 Python 库。openpyxl:是一个用于读写Excel文件(特别是.xlsx格式)的Python库。它提供了一种方便的方式来操作Excel文件,包括读取和写入单元格数据、创建和修改工作表、设置样式以及执行其他与Excel相关的操作。
二、编写爬虫代码
首先,导入requests和lxml,配置所要爬取网站的url,再通过浏览器(推荐使用Chrome)中f12(开发者工具)查看标头下的User-Agent信息,在代码中配置(如果找不到网络下的网页文件,刷新一下就能看到了)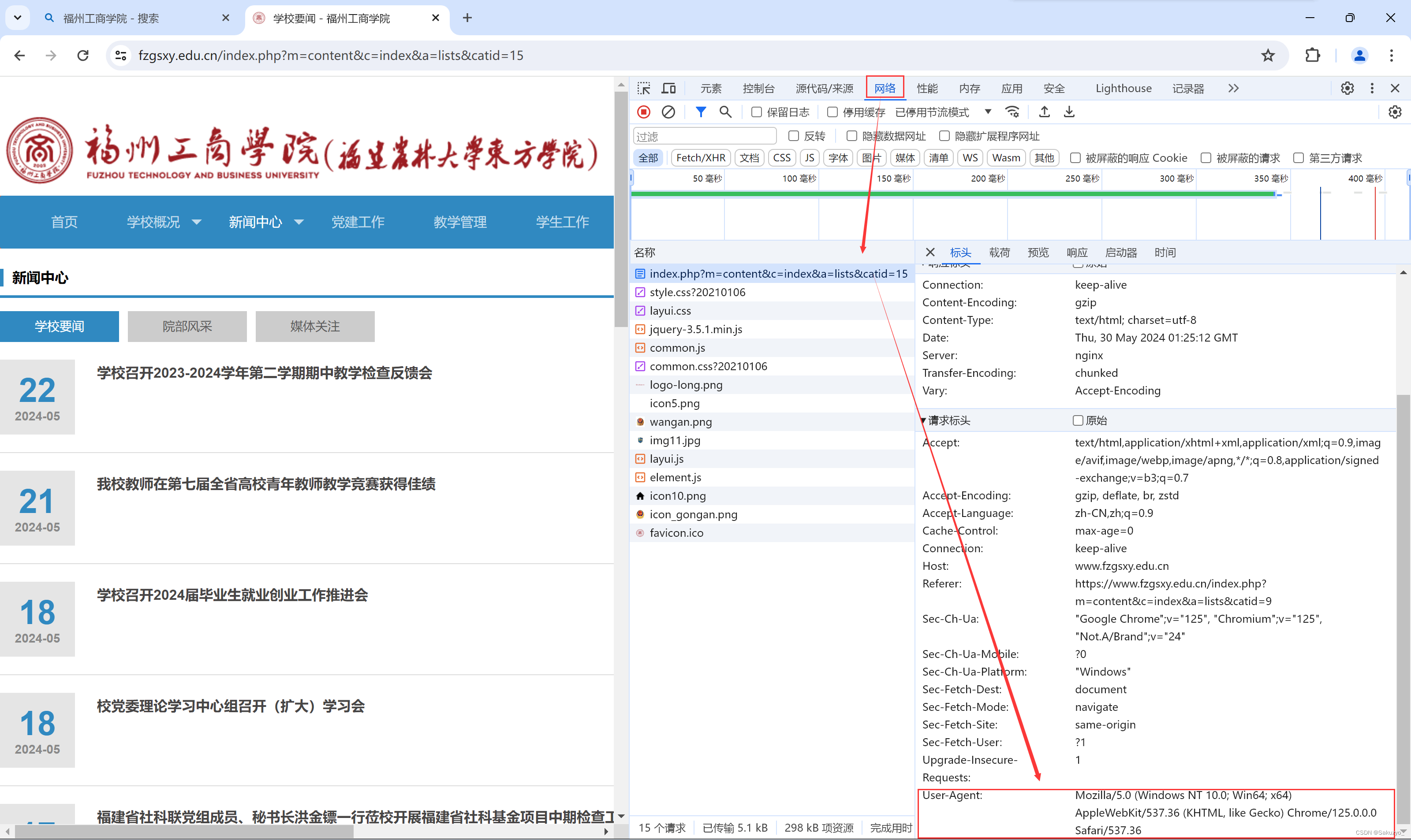 通过requests发送请求,可以得到网页的html文档
通过requests发送请求,可以得到网页的html文档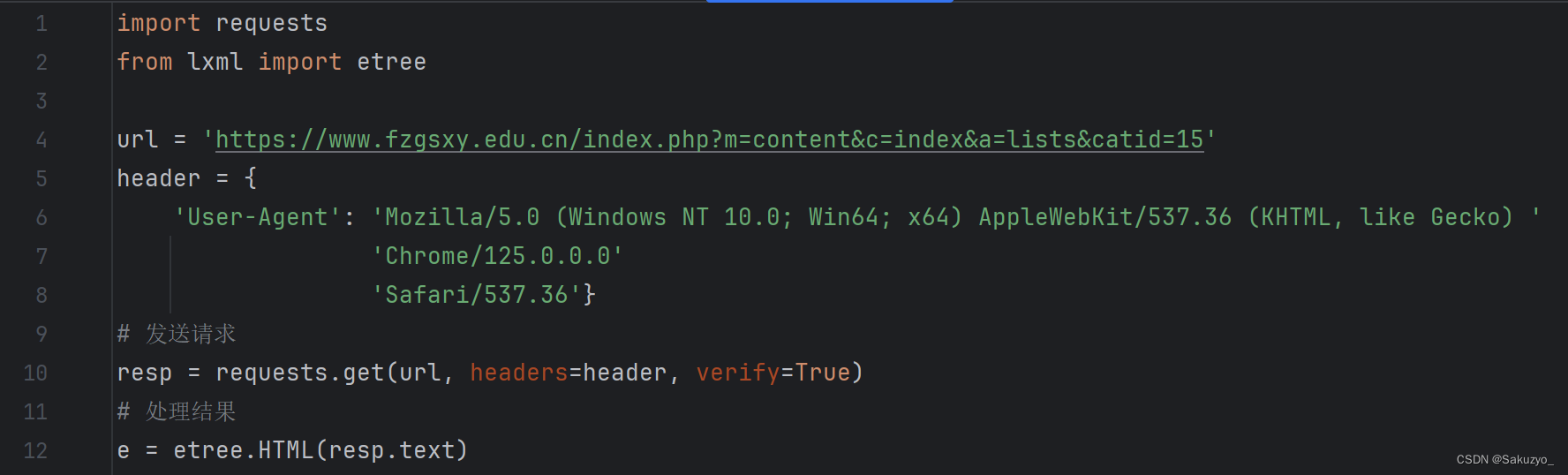
其次,再对网页中所需要获取的信息进行检查,利用XPath进行筛选信息
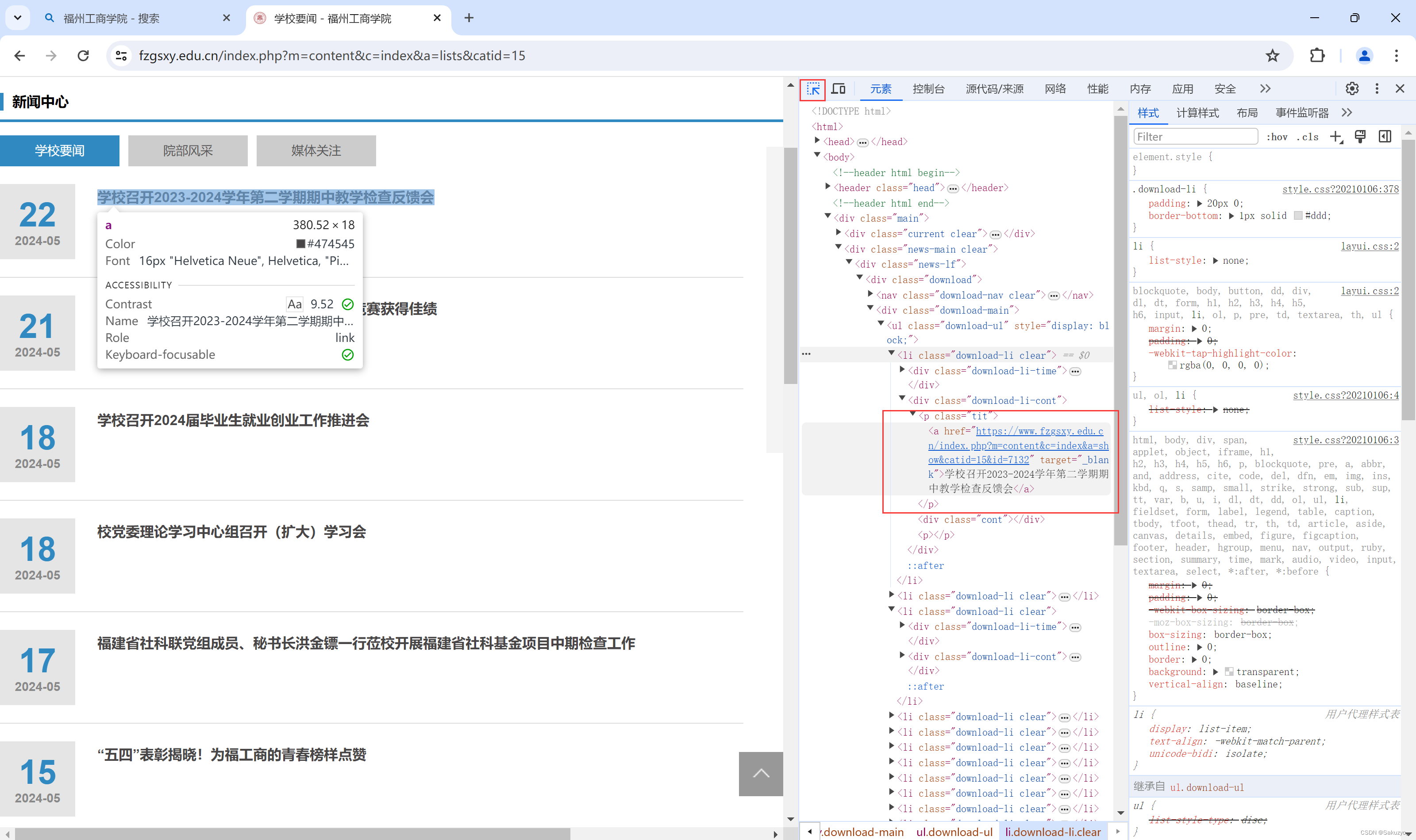
我们可以利用Chrome浏览器的XPath Helper扩展工具对地址进行查找
XPath下载:XPath Helper安装及使用-CSDN博客
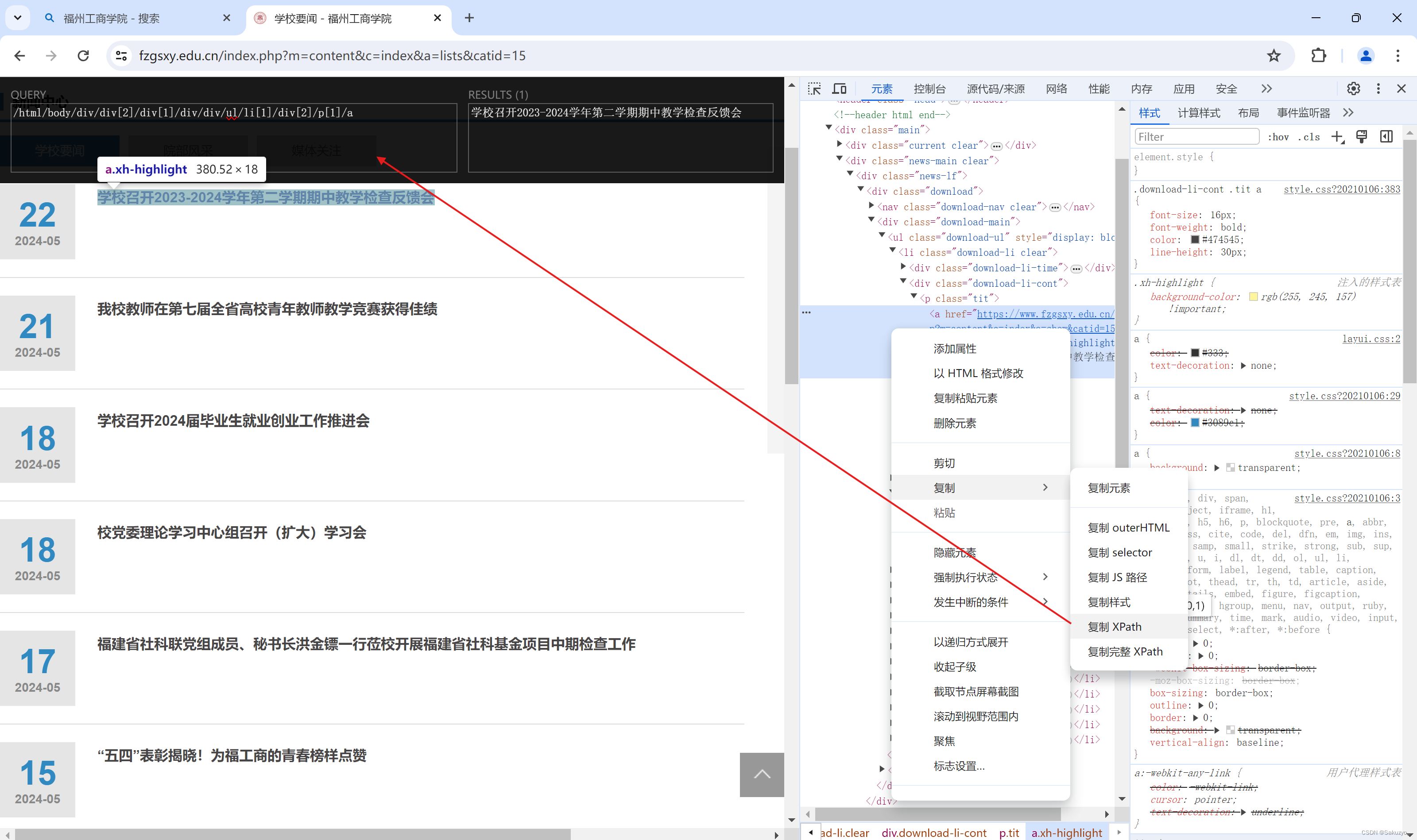
观察标签顺序,修改xpath可以得出所有新闻的标题
由于在新闻链接在a标签下的href属性中,因此我们可以通过在修改后的xpath尾部加上 /@href ,这样就可以获得当前页所有新闻链接啦

编写代码(注意这里title为文本类型,xpath后面需要加上 /text() )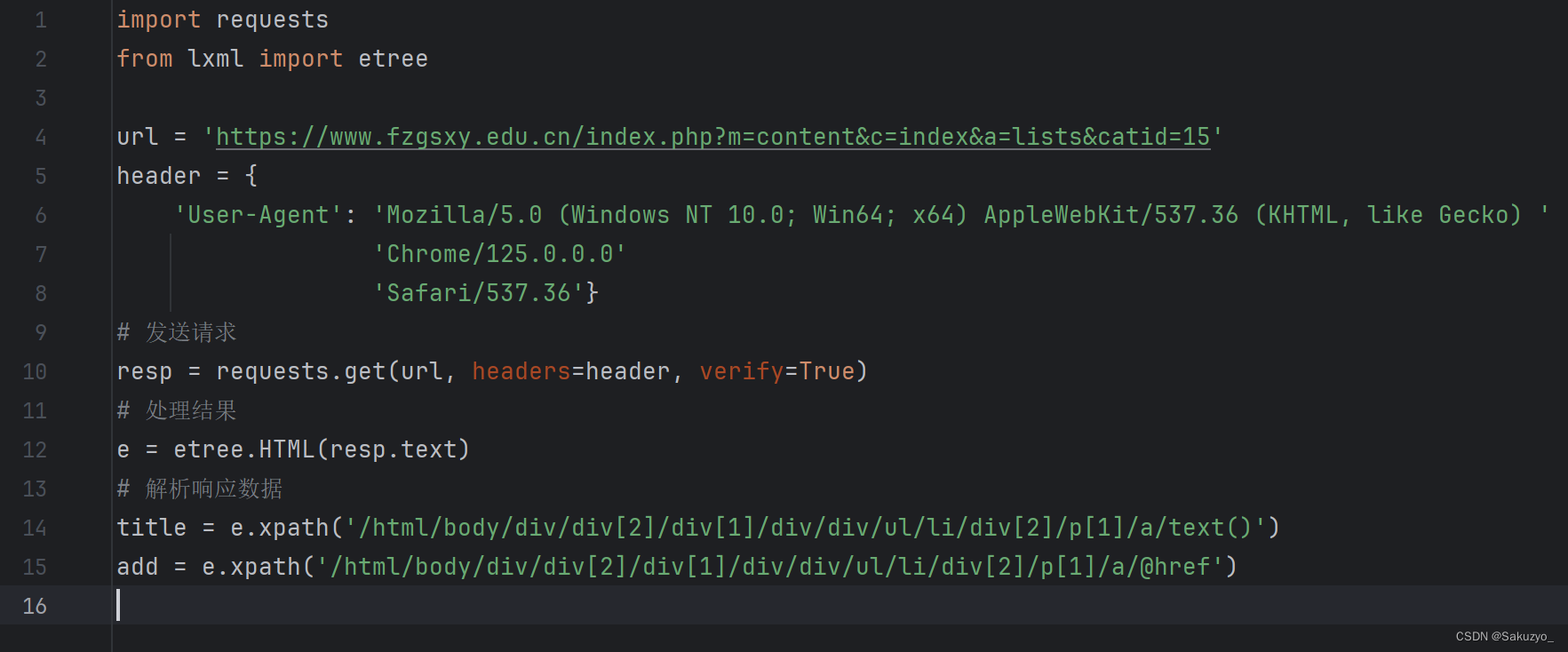
但是,在可以翻页的新闻栏下,如何获取多个页面的新闻数据?
通过点击进入其它页面,我们可以从链接的地址中发现规律
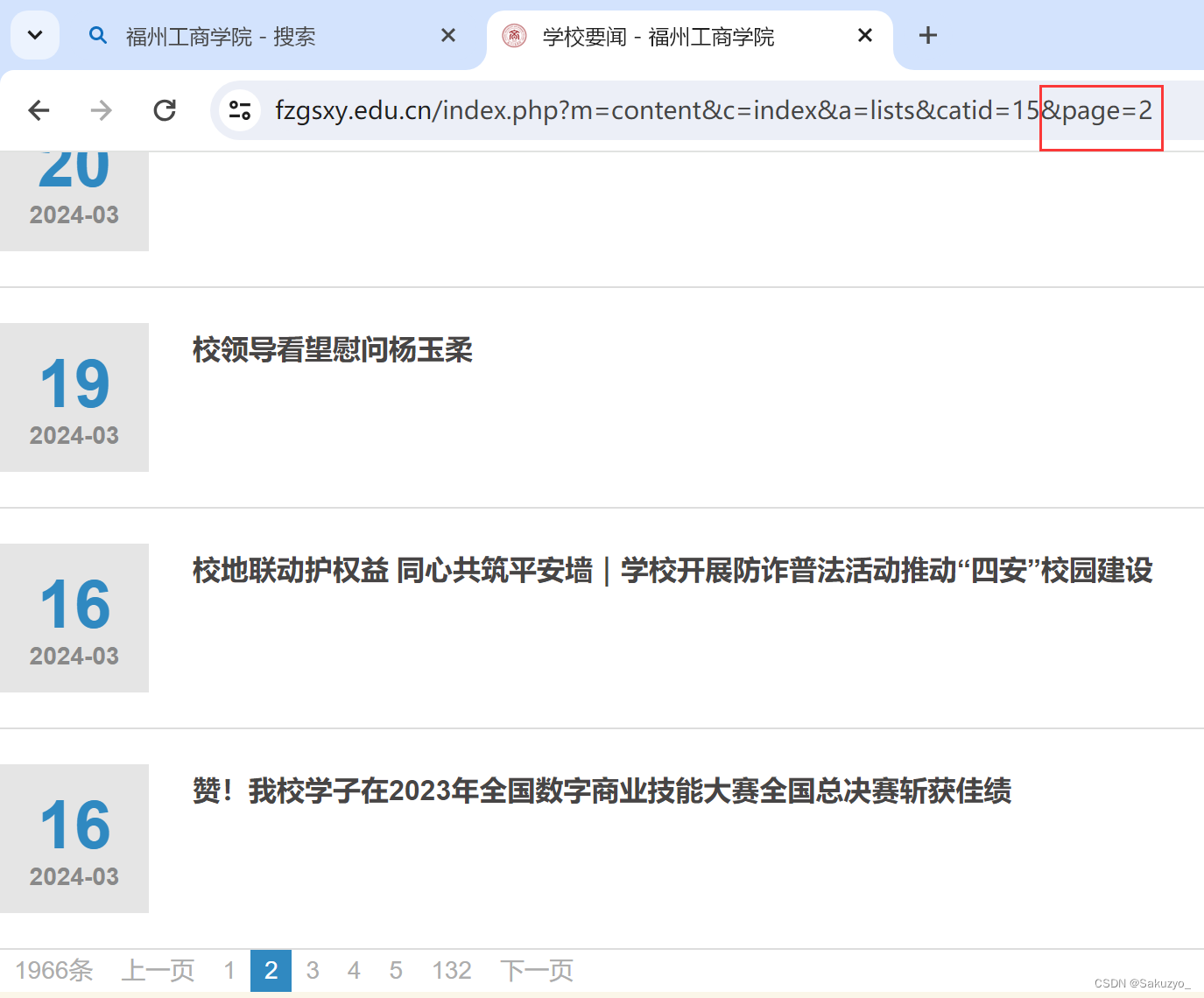
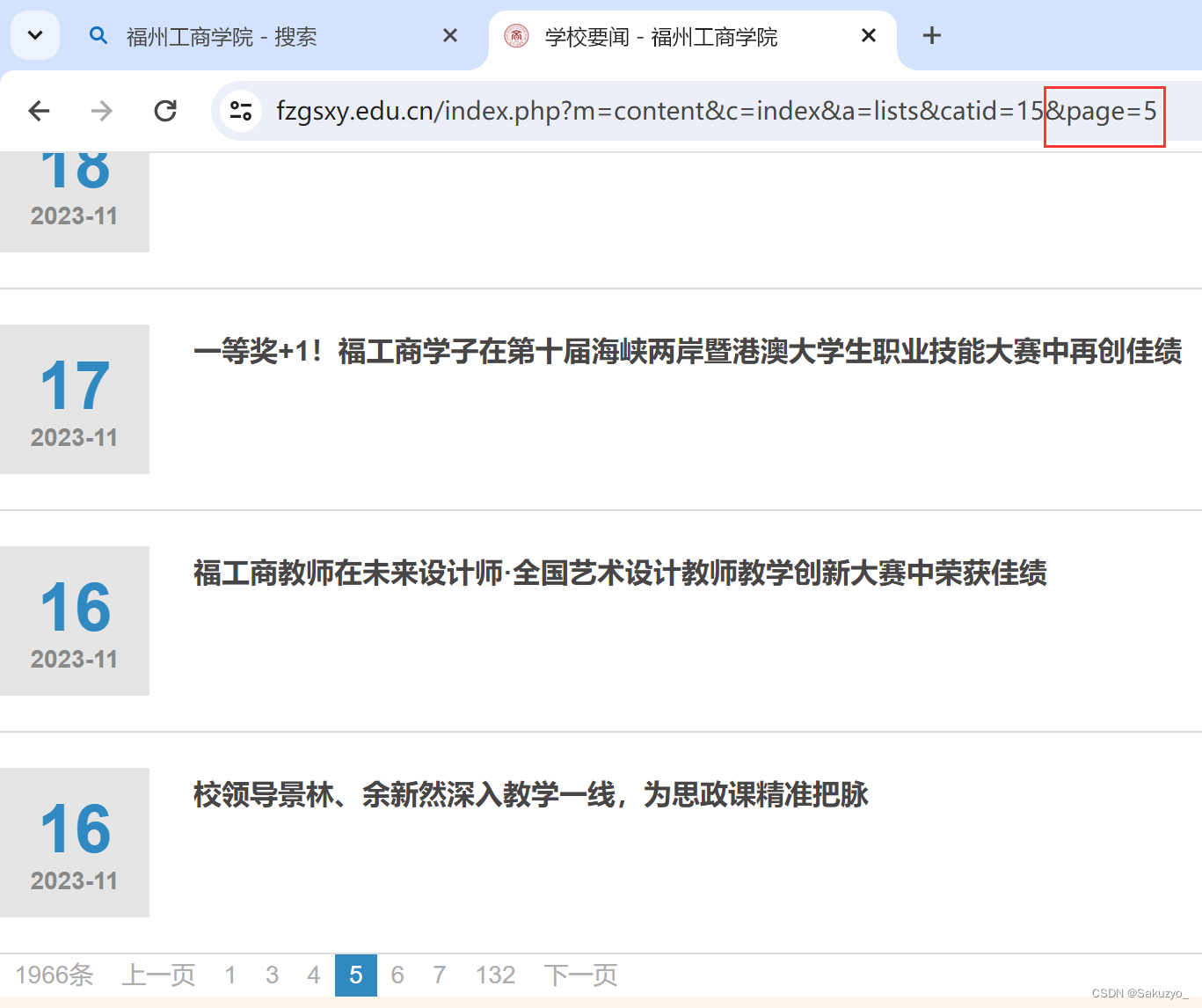
因此可以通过建立函数generate_docstring()进行遍历,然后通过字符串拼接的方式,不断的获取每一页的新闻数据
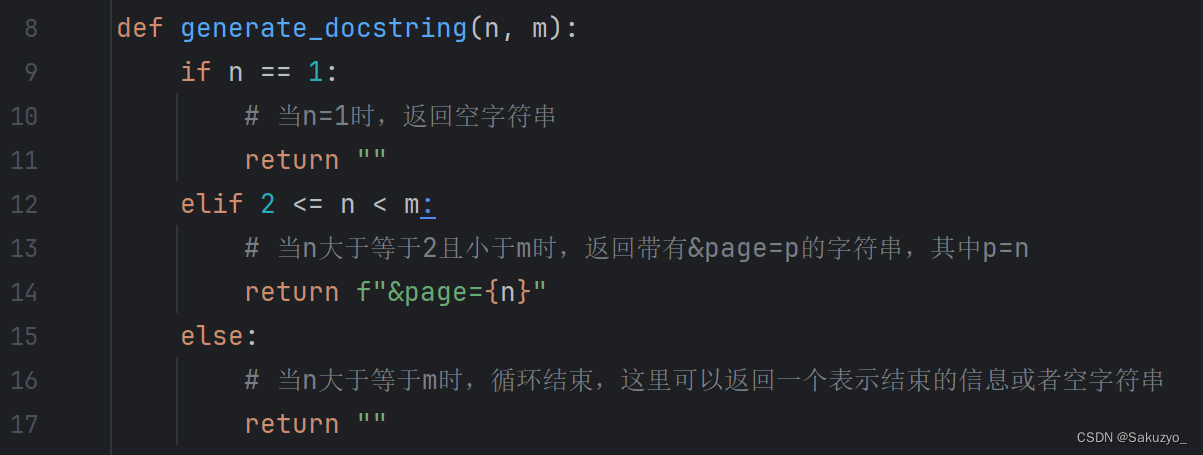
这里使用函数crawler_text(),通过接收遍历修改后的字符串后缀,进行拼接,然后返回title和add
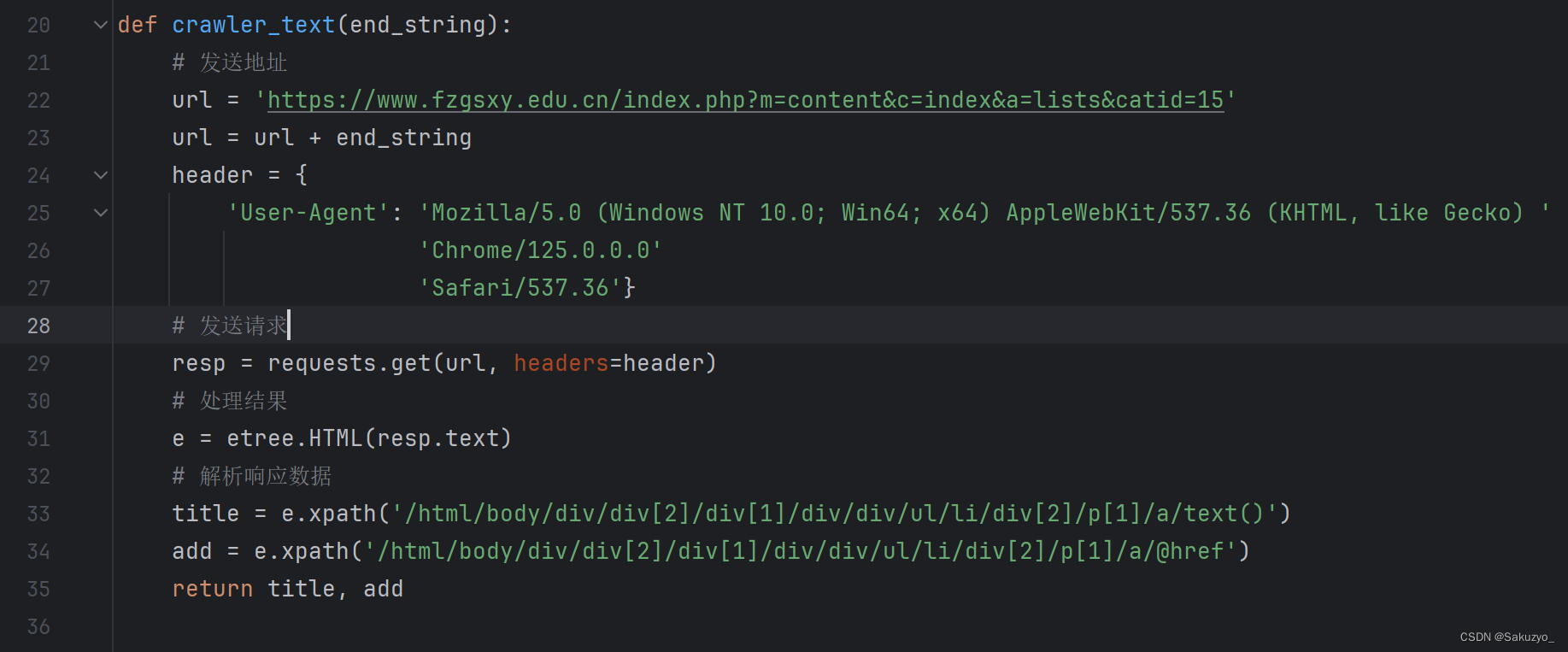
接着定义两个空列表,通过extend()方法对每一页爬取到存入列表的数据进行合并,最后整合为一张列表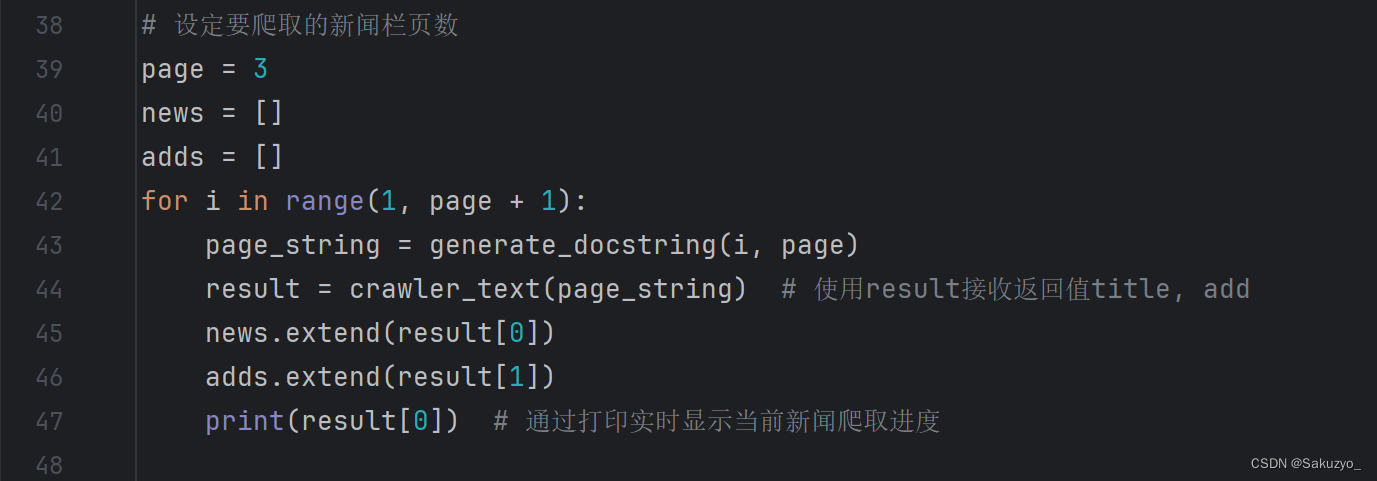
通过 import openpyxl 将数据进行导入excel中
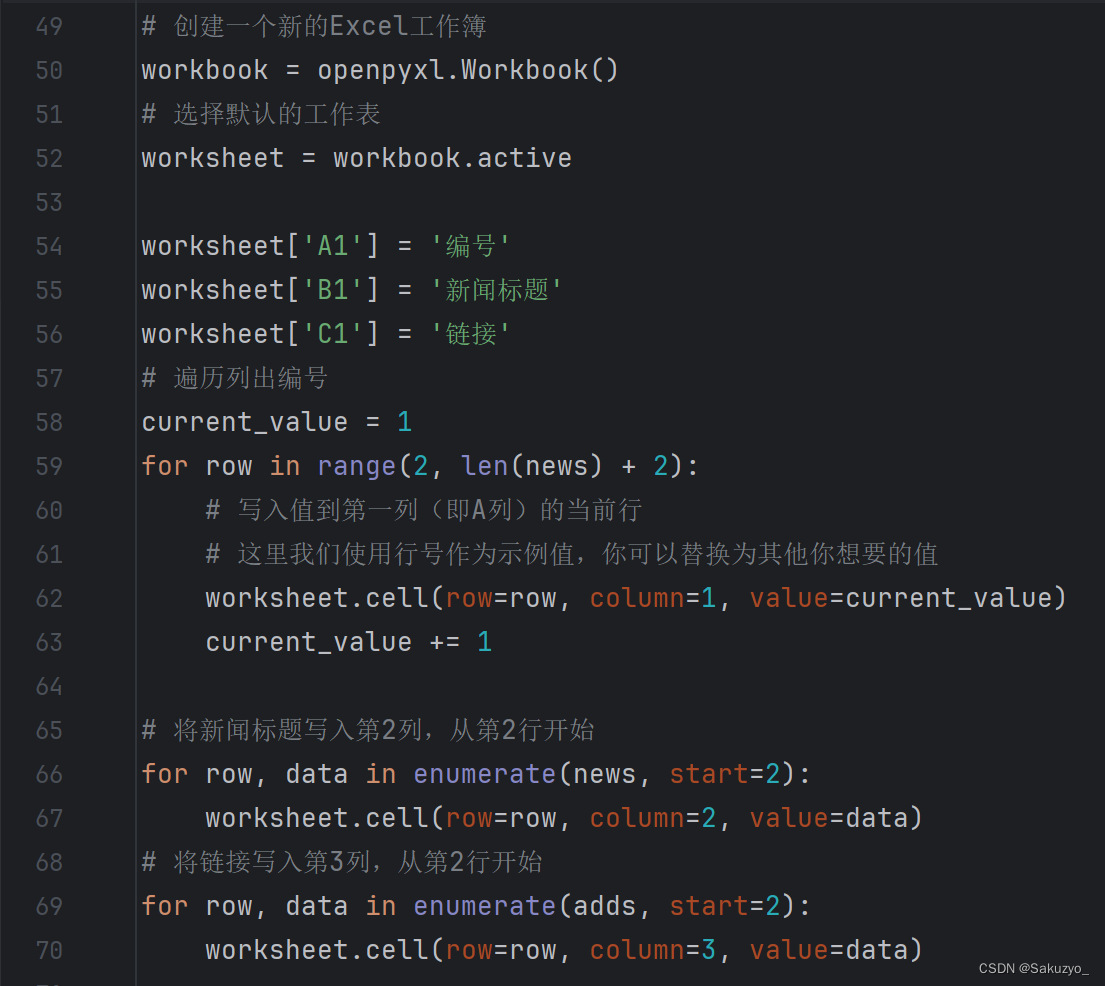
通过 from openpyxl.styles import Alignment 可以对excel内的行列格式进行操作修改
最后保存
代码如下:
# 获取福州工商学院官网新闻
import requests
import openpyxl
from lxml import etree
from openpyxl.styles import Alignment
def generate_docstring(n, m):
if n == 1:
# 当n=1时,返回空字符串
return ""
elif 2 <= n < m:
# 当n大于等于2且小于m时,返回带有&page=p的字符串,其中p=n
return f"&page={n}"
else:
# 当n大于等于m时,循环结束,这里可以返回一个表示结束的信息或者空字符串
return ""
def crawler_text(end_string):
# 发送地址
url = 'https://www.fzgsxy.edu.cn/index.php?m=content&c=index&a=lists&catid=15'
url = url + end_string
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/125.0.0.0'
'Safari/537.36'}
# 发送请求
resp = requests.get(url, headers=header, verify=True)
# 处理结果
e = etree.HTML(resp.text)
# 解析响应数据
title = e.xpath('/html/body/div/div[2]/div[1]/div/div/ul/li/div[2]/p[1]/a/text()')
add = e.xpath('/html/body/div/div[2]/div[1]/div/div/ul/li/div[2]/p[1]/a/@href')
return title, add
# 设定要爬取的新闻栏页数
page = 3
news = []
adds = []
for i in range(1, page + 1):
page_string = generate_docstring(i, page)
result = crawler_text(page_string) # 使用result接收返回值title, add
news.extend(result[0])
adds.extend(result[1])
print(result[0]) # 通过打印实时显示当前新闻爬取进度
# 创建一个新的Excel工作簿
workbook = openpyxl.Workbook()
# 选择默认的工作表
worksheet = workbook.active
worksheet['A1'] = '编号'
worksheet['B1'] = '新闻标题'
worksheet['C1'] = '链接'
# 遍历列出编号
current_value = 1
for row in range(2, len(news) + 2):
# 写入值到第一列(即A列)的当前行
# 这里我们使用行号作为示例值,你可以替换为其他你想要的值
worksheet.cell(row=row, column=1, value=current_value)
current_value += 1
# 将新闻标题写入第2列,从第2行开始
for row, data in enumerate(news, start=2):
worksheet.cell(row=row, column=2, value=data)
# 将链接写入第3列,从第2行开始
for row, data in enumerate(adds, start=2):
worksheet.cell(row=row, column=3, value=data)
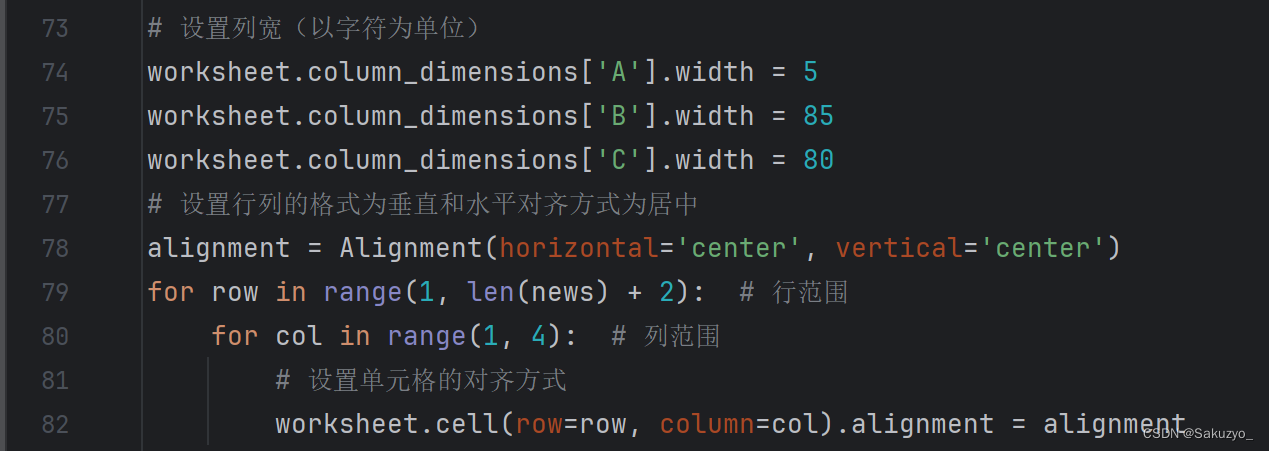
# 设置列宽(以字符为单位)
worksheet.column_dimensions['A'].width = 5
worksheet.column_dimensions['B'].width = 85
worksheet.column_dimensions['C'].width = 80
# 设置行列的格式为垂直和水平对齐方式为居中
alignment = Alignment(horizontal='center', vertical='center')
for row in range(1, len(news) + 2): # 行范围
for col in range(1, 4): # 列范围
# 设置单元格的对齐方式
worksheet.cell(row=row, column=col).alignment = alignment
# 保存Excel文件
workbook.save('fzgsxy_news.xlsx')
三、运行结果
这里通过打印接收的new来显示每一页添加进news的新闻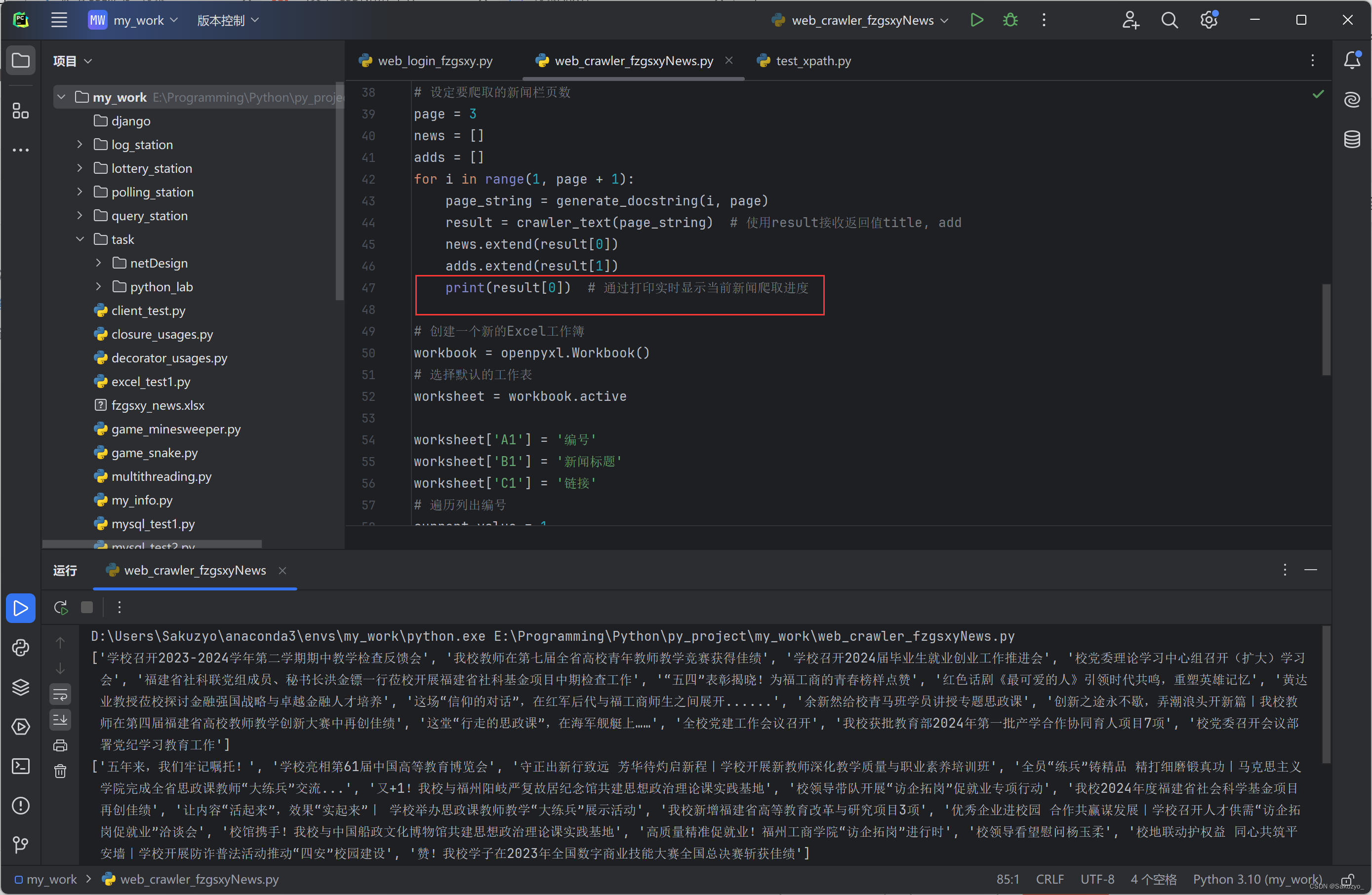
最终将news和adds保存到excel中,爬取到的新闻数据:















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









