






一、maven下载
maven官网:https://maven.apache.org/
maven下载地址:https://maven.apache.org/download.cgi

名词解释:归档(计算机和信息领域中指的是将文件、文档或数据集合打包成一个单一的文件或者容器,以便于存储、传输和备份)
其中
关于binary这种归档包含了预编译的二进制文件,即编译后的程序和库文件。可以直接安装与运行,不需要自己编译源代码。
关于source这种归档包含了软件的源代码,即程序的原始代码文件,用户需要使用编译器将这些源代码编译成可执行的二进制文件。
二、环境变量配置
在高级系统配置中,设置maven对应目录层级的路径
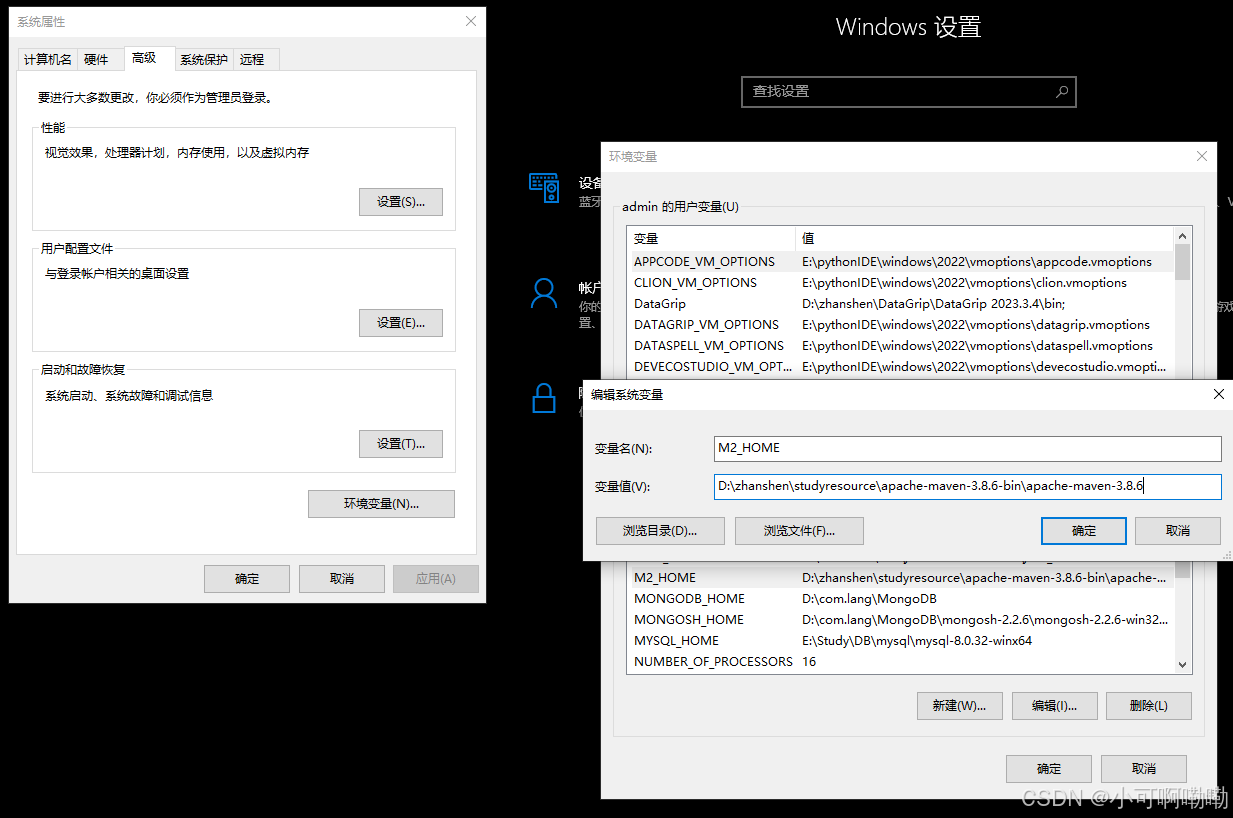
配置完成后打开cmd,输入mvn -v得到正确提示

三、配置repository源(可选)
配置repository的目的是为了让maven在下载依赖的时候能够更快、以及获得其他从官方下载依赖过程中的优点。
下面以配置阿里云镜像源为例
在maven解压路径下的创建repository目录
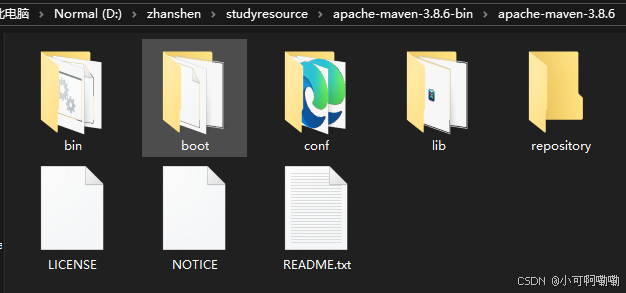
进入conf目录下的settings.xml文件进行编辑,在<mirror>标签中添加mirror子节点
添加内容:(阿里云镜像文件)
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>
再找到profiles节点,在其中并列添加子节点
添加内容:(需要根据自己的java的版本设置进行配置)
<!-- java版本 -->
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>
最后找到settings标签,找到节点localRepository,在注释处额外添加如下内容:
添加内容:(就是你repository文件夹的创建位置)
<localRepository>D:\maven1\apache-maven-3.8.6\repository</localRepository>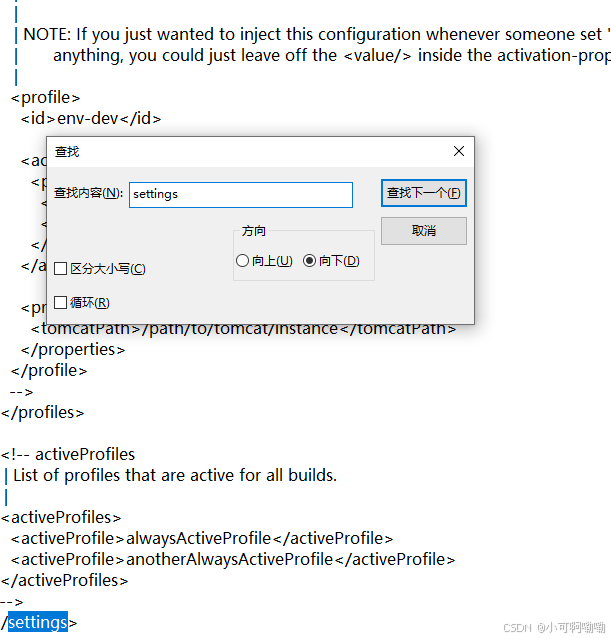
注意点:如果不配置阿里云的repository镜像的话,在进行maven项目加载依赖的时候,项目会从maven官网进行下载依赖。在通过官方依赖库进行下载的时候,可能会存在下载速度慢等等不利因素。
maven依赖官网仓库及其查询方式
查询maven依赖项:
maven项目依赖包查询网址:
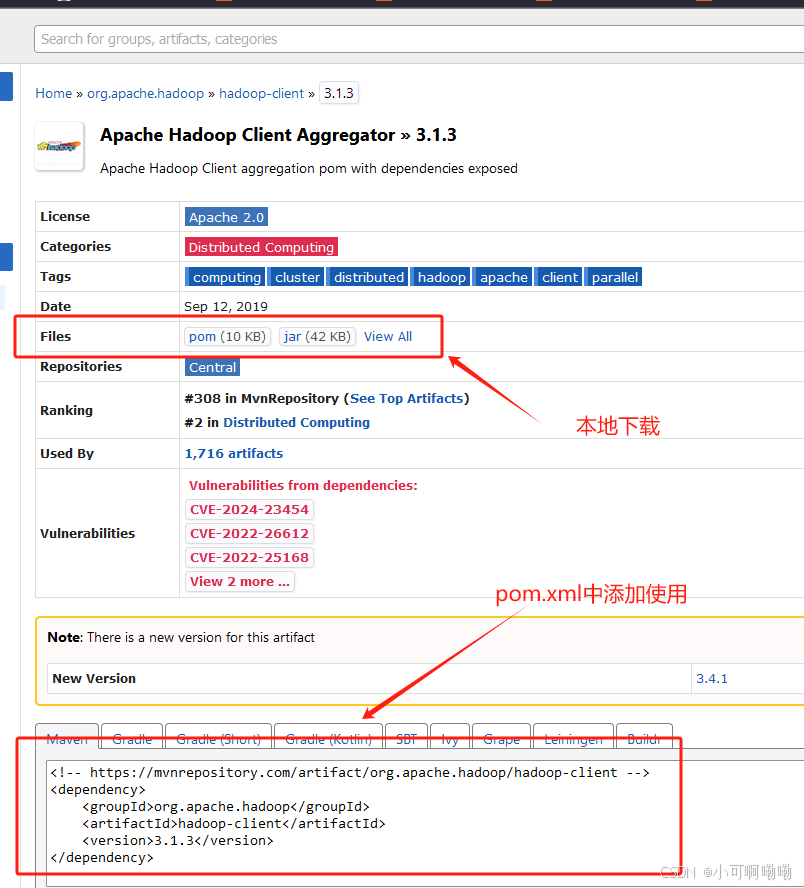
依赖包查询方式:
Pom.xml项目对象模型(project object model)
在maven依赖中,依赖项主要由groupid(依赖项组织唯一标识符)、artifactid(项目制品唯一标识符)、version(依赖项版本号)
在搜索栏中直接搜索组织唯一标识符
例:在项目中的依赖:
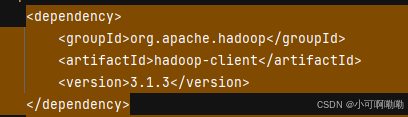
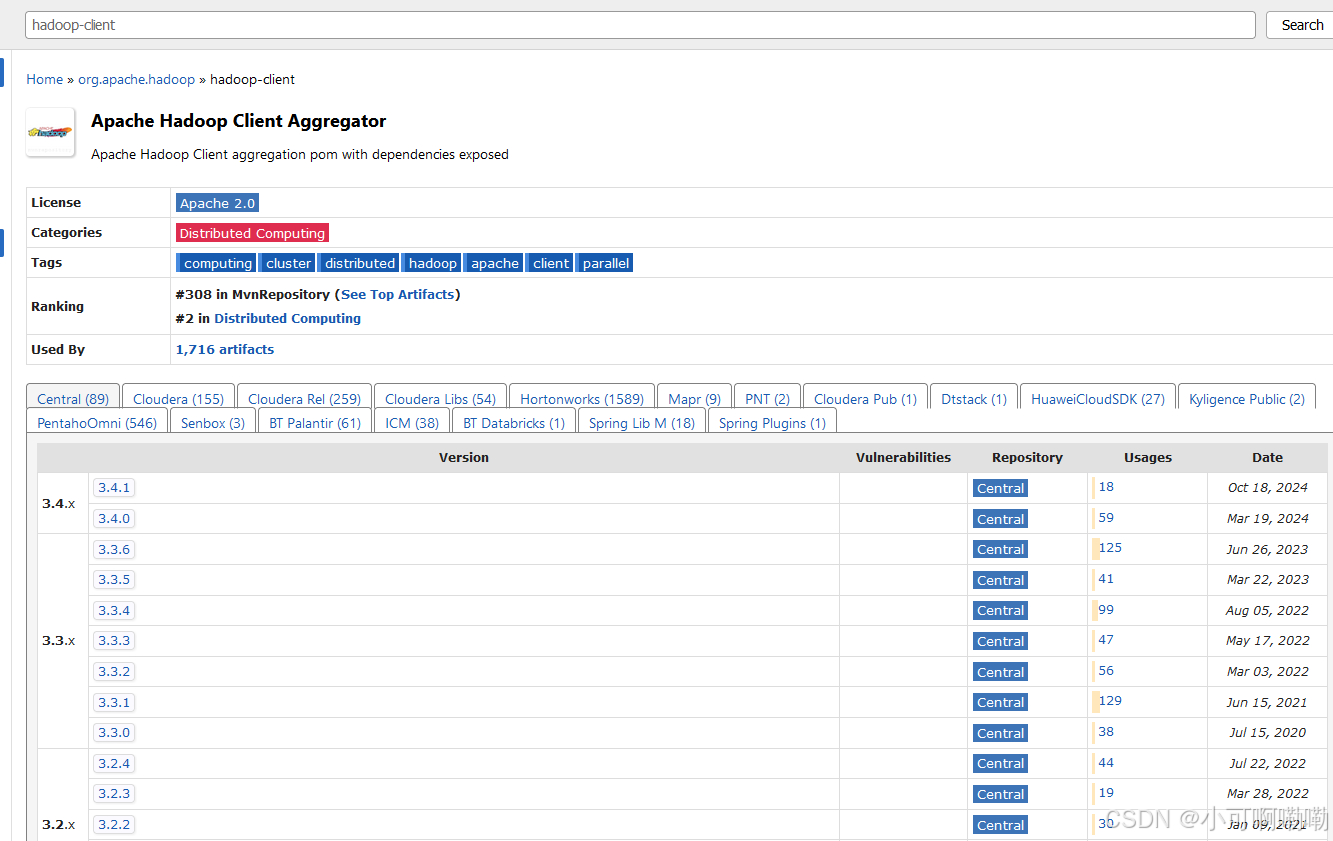
在maven官网中进行搜索,直接通过artifactid项目制品唯一标识符进行查询。
检查是否安装好了maven :mvn -v
四、在IDEA中配置maven项目
事先说明,IDEA中是自带maven环境的,我们需要做的就是加载依赖包就可以,如果需要自定义maven版本就需要自己按照上述步骤安装maven环境。
第一步,在IDEA中设置中央仓库的位置(即设定maven从哪里下载依赖)【路径不能有中文或者特殊符号】
打开settings——>build、execution、deployment——>build tools——>maven
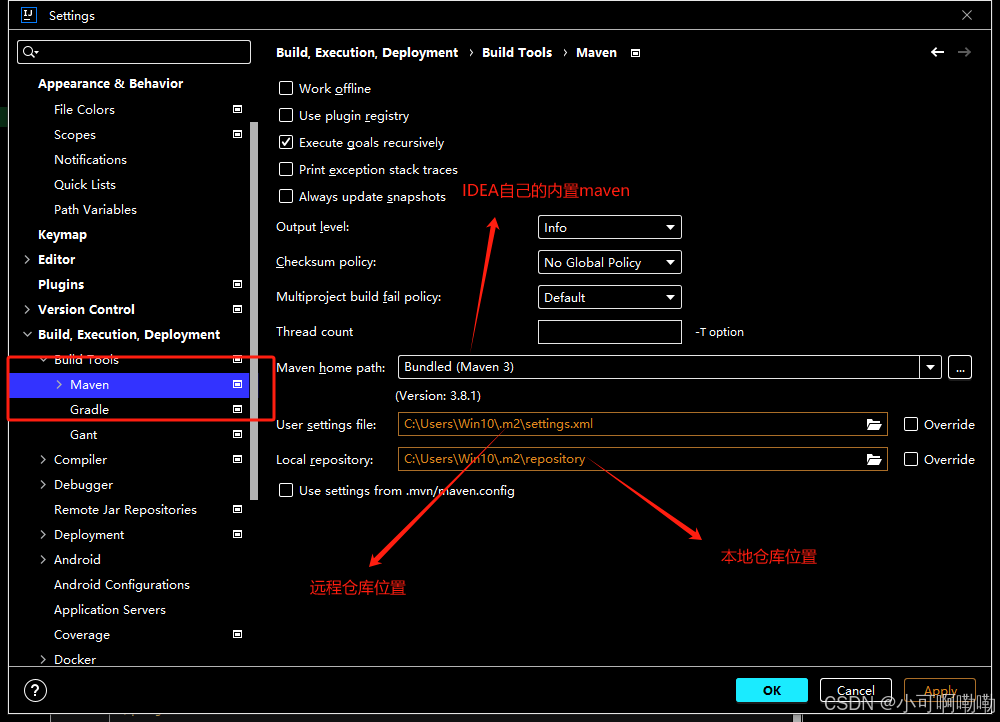
本地仓库:maven从中央仓库中下载的jar包到本地仓库,后面如果再使用同一个jar包,就不用再下载一次了
远程仓库:在settings.xml文件中设定了maven从哪里下载依赖的jar包,中央仓库有很多镜像,具体的配置可以看 第三步 配置repository源
创建maven项目
1.新建一个maven工程
选定项目工程名(Name)、项目制品唯一标识符(ArtifactID)、项目依赖组织唯一识(groupID),选择建立系统为maven(build system),选择合适的jdk
其中groupID项目依赖组织唯一标识符与artifactID项目制品唯一标识符,是将来程序上传到中央仓库时需要用到的,如果不需要上传那就默认值就行
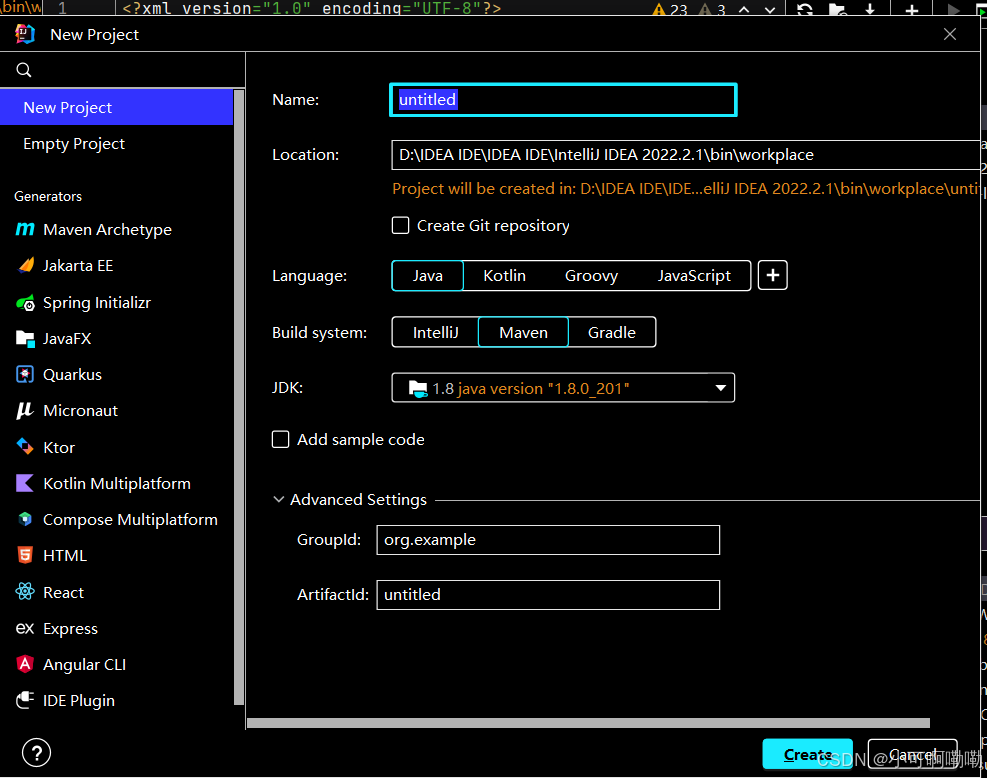
更改maven的默认使用路径与settings.xml配置文件路径

2.在maven工程中找到pom.xml导入相关的依赖包。
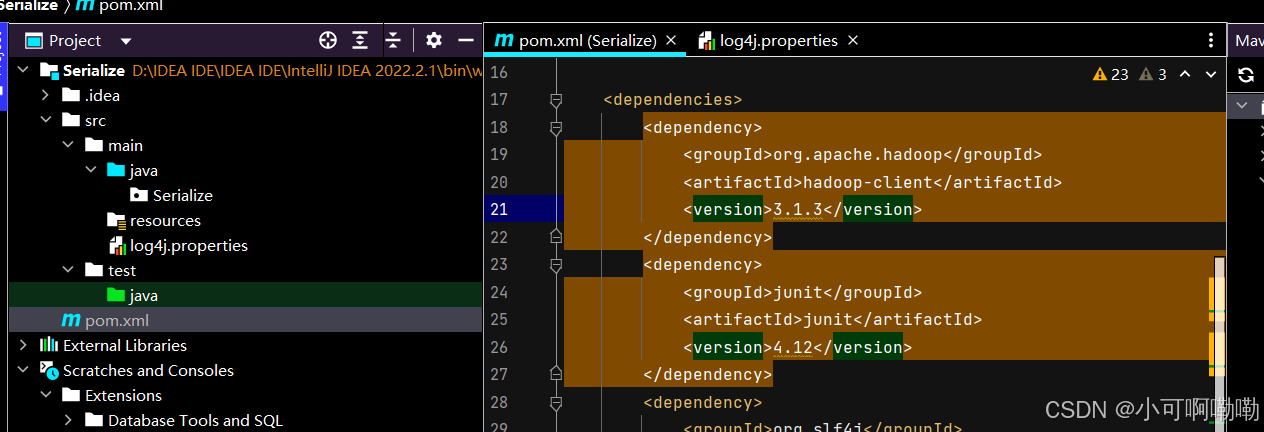
依赖包内容(注意要更改项目组标识与项目标识,单元测试类,控制日志级别类)
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>//单元测试(一个类)
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>//打印日志时,控制日志级别
<version>1.7.30</version>
</dependency>
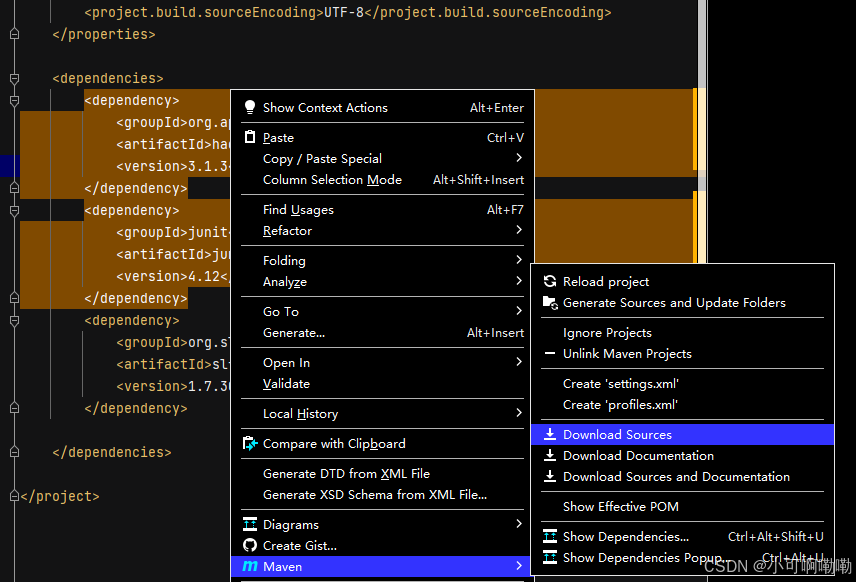
</dependencies>右键使用maven下载源就可以
3.在项目的/src/main/resources目录下新建一个log4j.properties控制日志级别类文件。
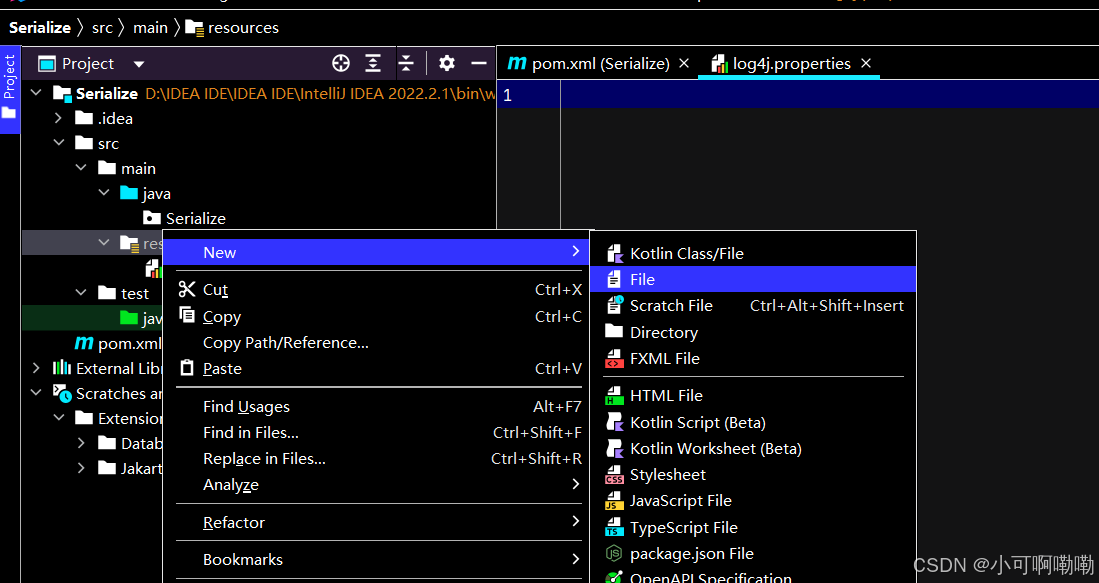
控制日志级别类文档:
log4j.rootLogger=INFO, stdout (控制打印级别为INFO级别)
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n五、maven项目打包
(1)用maven打jar包,需要添加的打包插件依赖(加入此插件会将jar代码运行时需要的package、扩展库等一并打进jar包中)
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>注意:如果工程上显示红叉。在项目上右键->maven->Reimport刷新即可
部分插件中存在红色内容是没关系的
(2)将程序打成jar包
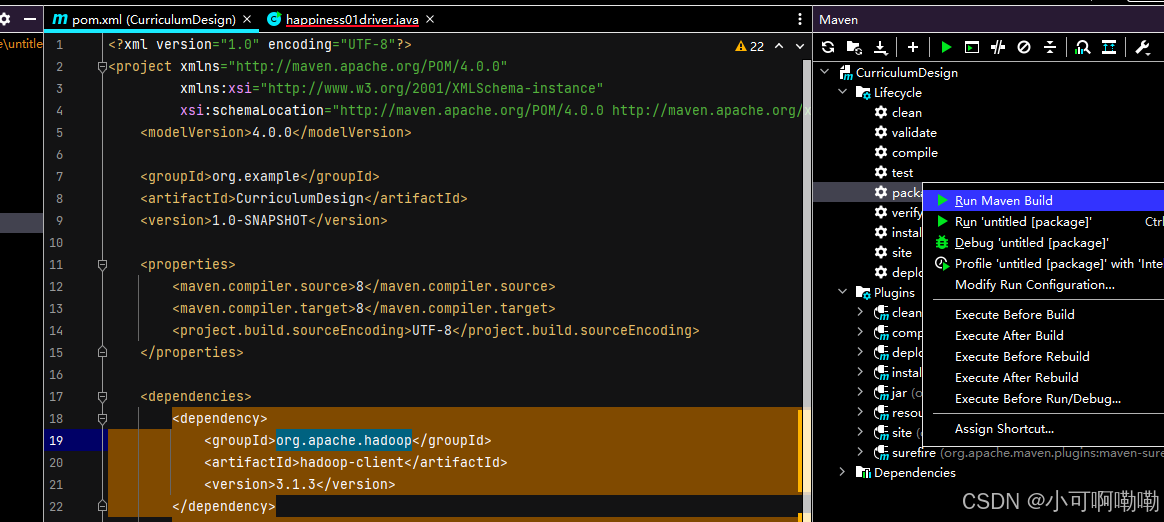
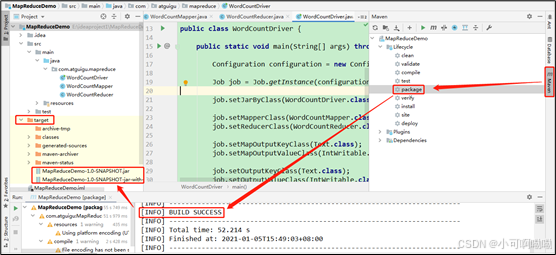
(3)修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群的/opt/module/hadoop-3.1.3路径(未来的执行路径)
(4)启动Hadoop集群
[atguigu@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(5)执行WordCount程序
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar
com.atguigu.mapreduce.wordcount.WordCountDriver /user/atguigu/input /user/atguigu/output(自己的代码需要进行全类名【driver类的】的输入)
获取全类名的方式:
右键需要进行运行的driver类
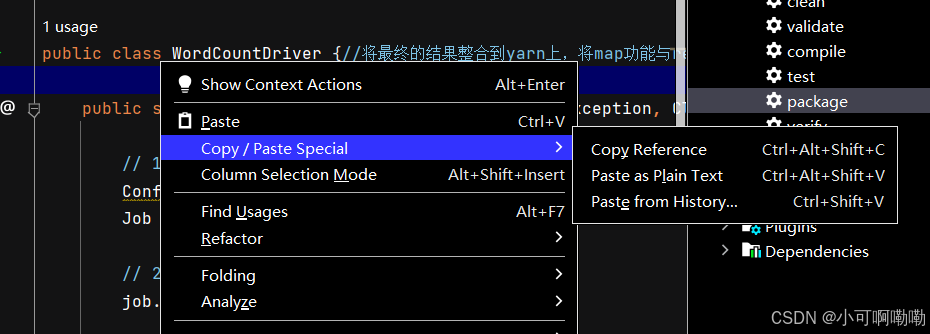
选择copy reference复制全类名,然后粘贴到代码中即可
(官方的wordcount案例)指定wordcount案例时的代码
| Hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output(官方的wordcount案例 | 不需要进行全类名的输入,因为它做了一个特殊的映射关系,直接输入案例名称即可) |

















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









