







函数对象
用函数调用操作符重载的类,其对象被称为函数对象,也叫仿函数;本质上:函数对象是一个类不是一个函数
函数对象的特点:
1、函数对象在使用时可以当作普通函数一样调用,可以有参数也可以有返回值
2、函数对象超出普通函数的概念,可以有自己的状态
3、函数对象可以作为参数传递
class Person
{
public:
Person()
{
this->count = 0;
}
int operator ()(int val1, int val2)
{
this->count ++;
return val1 + val2;
}
int count;
};
int main()
{
Person p; // 创建一个函数对象
p(10,10); // 可以作为普通函数调用, 可以有参数有返回值
cout << p.count << endl ; // 可以有自己的属性
cprintf(p,"test.txt"); // 作为函数参数
}谓词:返回bool类型的仿函数称为谓词
bool operator() 接收一个参数称为一元谓词;接收两个参数称为二元谓词
class cprintf
{
public:
bool opeator()(int val) // 一元谓词
{
return val > 20;
}
bool opeator()(int val, int vaw)//二元谓词
};内建函数对象
c++中提供了一些函数对象;称为内建函数对象;使用需要包含头文件 functional
算术仿函数

本质上是通过类模板来实现的;用法比较简单
negate<int> n ;// 创建了一个negate类型的仿函数对象n
cout << n(10) << endl; // 输出的是10, negate是一个取反的仿函数
plus<int> p;
cout << p(10,10) << endl; // 输出的是20,plus是一个加法仿函数
只有negate是一元运算,其它的都是二元运算
关系仿函数:实现关系对比

最常用的是greater 大于, 在sort算法中可以直接用来指定排序规则
vector<int> v;
v.push_back(10);
v.push_back(1);
v.push_back(20);
sort(v.begin(),v.end(),greater<int>()); // 创建greater仿函数匿名对象来指定排序类型
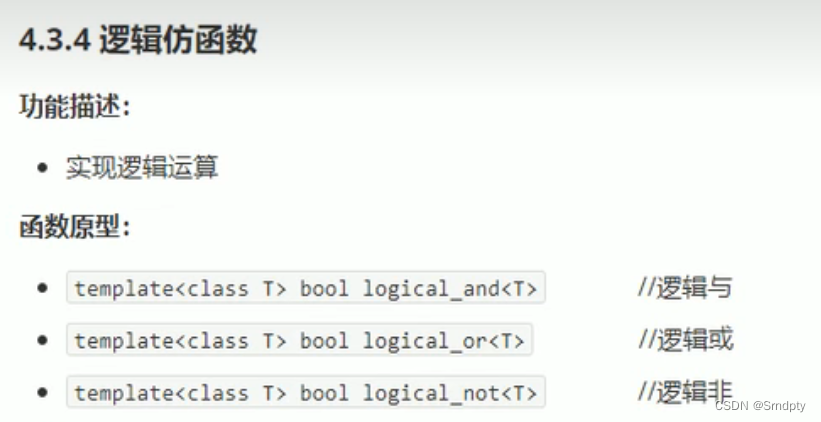
逻辑仿函数:实际开发中用的比较少了解一下即可
常用算法
算法主要由头文件#include<algorithm> 、 #include<functional> 、 #include<numeric>组成
<algorithm>是STL头文件中最大的一个:范围包括:比较、交换、查找、遍历等一般算法
<numeric>体积很小一般是数学运算的模板函数(accumulate和fill)算术生成算法
<functional>是定义了一些类模板,声明内建函数对象
常用遍历算法
for_each:遍历容器
语法:for_each(iterator begin(), iterator end(),func); func是定义仿函数或普通函数来指定遍历
#include<vector>
#include<algorithm>
vector<int> v;
v.push_back(10);
v.push_back(20);
v.push_back(30);
void mprintf(int val)
{
cout << val << " ";
}
//普通函数来指定遍历
for_each(v.begin(),v.end(),mprintf); //普通函数遍历只需把函数名放入
//仿函数指定遍历
for_each(v.begin(),v.end(),myprintf()); //仿函数遍历需要用到函数和对象,这里创建匿名函数对象
for_each用普通函数和用仿函数对象来指定排序规则的区别在于:普通函数只需放入函数名,而仿函数需要把函数对象加入, 一般用匿名函数对象指定,比较方便;
for_each用的非常普遍需要熟练掌握
transform:搬运容器到另一个容器
语法:transform(iterator begin1(),iterator end1(), iterator begin2(), _func); 第四个参数为仿函数,需要利用仿函数来实现元素的转移
#include<vector>
#include<algorithm>
class trans
{
public:
int operator ()(int val)
{
return val;
}
};
vector<int> v;
vector<int> v1;
v.push_back(10);
v.push_back(20);
v.push_back(30);
v1.resize(v.size());
transform(v.begin(),v.end(),v1.begin(),trans);//利用仿函数来搬用容器
常用的查找算法
find
查找指定元素返回元素迭代器,未找到返回结束迭代器end();
语法:find(iterator begin(), iterator end(), value); value为查找的元素值
查找自定义数据类型时,需要重载==号,让底层知道如何进行对比
find_if
与find类似, 不同之处在于按指定条件查找元素; 指定条件通过函数对象来实现
#include<vecctor>
#include<algorithm>
vector <int> v1;
for(int i = 0; i < 10; i++)
{
v1.push_back(i);
}
vector<int> :: iterator v1 = find(v1.begin(),v1.end(),2);
if(v1 != v1.end())
{
cout << "找到了" << *v1 << endl;
}
else
{
cout << "未找到" << endl;
}adjacent_find
查找相邻元素;返回相邻元素第一个元素的迭代器,未找到返回结束迭代器end();
函数原型:adjacent_find(iterator begin(), oterator end());
#include<algorithm>
#include<vector>
vector<int> v;
v.push_back(10);
v.push_back(10);
v.push_back(10);
v.push_back(1);
vector<int> :: iterator it = adjacent_find(v.begin(),v.end());
if(it == v.end())
{
cout << "未找到" << endl;
}
else
{
cout << "找到了相邻元素: " << *it << endl; // 返回的是第一个相邻的元素的迭代器
}binary_search
二分查找(折半查找),查找指定元素是否存在,只能在有序序列中查找,无序序列中不可使用
函数原型:bool binary_search(iterator begin(), iterator end(),3);
#include<algorithm>
#include<vector>
vector<int> v;
for(int i = 0; i < 10; i++)
{
v.push_back(i);
}
bool ret = binary_search(v.begin(),v.end(),3);
if(ret)
{
cout << "查找成功" << endl;
}
else
{
cout << "查找失败" << endl;
}二分查找的效率很高,无序序列不能使用
count
统计元素个数;语法:count(iterator begin(),iterator end(),value );
//自定义数据类型计数
class Person
{
public:
Person(string name ,int age)
{
this->m_Name = name;
this->m_Age = age;
}
bool operator == (const Person &p)
{
if(this->m_Age == p.m_Age)
{
return true;
}
else
{
return false;
}
}
string m_Name ;
int m_Age;
};
Person p1("zhang",10);
Person p2("wuwu",10);
Person p3("qq", 11);
vector<Person> v;
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
Person pp("oo",10);
int num = count(v.begin(),v.end(),pp); // 统计与pp年龄相同的人数 需要重载==号count_if
按条件统计元素个数; count_if(iterator begin(),iterator end(),_Pred ); _Pred谓词
#include<algoritnm>
#include<vector>
class mycompare
{
public:
bool operator == (int val)
{
return val > 20;
}
};
class Pcompare
{
public:
bool operator==( const Person &p)
{
return p.m_Age > 20; // 计算年龄大于20 的人的个数
}
};
int num = count_if(v.begin(),v.end(),Pcompare);统计自定义数据类型时,需要配合重载operator == 号
常用排序算法
sort
对容器内元素进行排序;函数原型sort(iterator begin(),iterator end(),_Pred); 利用谓词改变排序规则
vector<int> v;
class mycompare
{
public:
bool operator ()(int val1, int val2)
{
return val1 > val2; //降序排列
}
};
for(int i = 0 ; i < 10; i ++)
{
v.push_back(i);
}
sort(v.begin(),v.end()); //默认升序排列
sort(v.begin(),v.end(),mycompare()); //利用谓词来进行降序排列
random_shuffle
又名为:洗牌算法; 指定范围内随机调整次序
语法: random_shuffle(iterator begin(),iterator end()); 利用随机数种子 srand 是调整的次序更真实
vector<int> v;
srand((unsigned int)time(NULL)); //随机数种子使调整的次序更真实
for(int i = 0 ; i < 10; i++)
{
v.push_back(i);
}
random_shuffle(v.begin(),v.end());
merge
两个元素合并,并存储到另一个容器中
函数原型:merge(iterator begin1(),iterator end1(),iterator begin2(),iterator end2(),iterator dest); 注意: 两个容器必须是有序的序列,要给目标容器开辟空间 不然无法合并
vector<int> v1;
vector<int> v2;
for(int i = 0; i < 10; i ++)
{
v1.push_back(i);
v2.push_back(i+1);
}
vector<int> v3;
v3.resize(v1.size()+ v2.size());
merge(v1.begin(),v1.end(),v2.begin(),v2.end(),v3.begin());//合并到v3中reverse
将容器内元素进行反转;函数原型:reserve(iterator begin1(),iterator end());
vector<int> v;
for(int i = 0 ; i < 10; i++)
{
v.push_back(i);
}
reverse(v.begin(),v.end()); //将容器内元素进行反转
常用的拷贝和替换算法
copy
容器指定范围内元素复制到另一容器中,语法:copy(iterator begin(),iterator end(), iterator dest),copy算法知道用法即可,一般通过拷贝构造函数来进行赋值拷贝,在拷贝时,目标容器记得开辟空间
replace
将容器内指定元素改为新的元素,语法:replace(iterator begin1(),iterator end(),oldvalue,newvalue), 会将所有满足条件的元素进行替换
replace_if:将区间内满足条件的元素替换成指定元素
语法:replace_if(iterator begin(),iterator end(),_Pred,newvalue);
class greater10
{
public:
bool operator()(int val)
{
return val > 10;
}
};
vector<int> v;
v.push_back(10);
v.push_back(20);
v.push_back(20);
replace_if(v.begin(),v.end(),greater10(),200); swap:交换两个容器
语法:swap(v1,v2);
常用的算术生成算法
算术生成算法属于小型算法,需要包含头文件#include<numeric>,
accumulate
计算容器内元素累计之和;
#include<numeric>
vector<int> v;
for(int i = 0; i < 100; i++)
{
v.push_back(i);
}
//将容器中的元素累加起来
int tal = accumulate(v.begin(),v.end(),0); //第3个参数 是起始累加值,一般设为0
fill
向容器中填充指定元素;语法:fill(iterator begin(),iterator end(),value);
#include<numeric>
vector<int> v;
for(int i = 0; i ++ ; i < 10)
{
v.push_back(i);
}
fill(v.begin(),v.end(),222); //向容器中指定填充222
常用的集合算法
set_intersection (交集)、set_union(并集)、set_difference(差集)
set_intersection
求两个容器的交集;两个容器必须是有序的,返回的是最后一个相交元素的迭代器,给目标容器开辟空间时,需要考虑最特殊的情况:即一个容器包含另一个容器,这时只需要开辟最小的容器空间给目标容器
语法:set_intersection (iterator begin1(),iterator end1(),iterator begin2(),iterator end2(),interator begin3());
#include<algorithm>
vector<int> v1;
vector<int> v2;
for(int i =0 ;i < 10; i ++)
{
v1.push_back(i);
v2.push_back(i+5);
}
vector<int> v3;
v3.resize(min(v1.size(),v2.size()));
vector<int> :: iterator it = set_intersection(v1.begin(),v1.end(),v2.begin(),v2.end(),
v3.begin());
for_each(v3.begin(),it,myprintf); //遍历输出的时候用返回的迭代器作为结束迭代器,因为
返回的是最后一个相交元素的迭代器位置,我们只需要遍历出相交的元素set_union
求两个集合的并集,两个集合必须是有序序列
语法:set_union(iterator begin1(),iterator end1(),iterator begin2(),iterator end2(),interator begin3());
开辟目标容器的空间时需要考虑特殊情况:当两个元素完全不相交时,目标容器的大小为两个容器大小之和
#include<algorithm>
vector<int> v1;
vector<int> v2;
for(int i =0; i < 10; i++)
{
v1.push_back(i);
v2.push_back(i+5);
}
vector<int> v3;
v3.resize(v1.size() + v2.size());
vector<int> :: iterator it =set_union(v1.begin(),v1.end(),v2.begin(),v2.end(),v3.begin());
for_each(v3.begin(),it,myprintf);srt_difference
求两个集合的差集
语法:set_difference(iterator begin1(),iterator end1(),iterator begin2(),iterator end2(), iterator dest);
特殊情况:当两个容器不相交时,将较大的容器空间复制给目标容器
#include<algorithm>
vector<int >v1;
vector<int> v2;
for(int i = 0; i < 10; i++)
{
v1.push_back(i);
v2.push_back(i+5);
}
vector<int>v3;
v3.resize(max(v1.size(),v2.size()));
vector<int >:: iterator it = set_difference(v1.begin(),v1.end(),v2.begin(),v2.end(),
v3.begin());
这三个集合算法返回的都是满足条件的最后一个元素的迭代器位置,并且比较的容器必须是有序的
给目标容器开辟空间时,需要考虑它们各自的特殊情况;for_each遍历的时候,结束迭代器用返回的迭代器,这样遍历的元素都是满足条件的元素。















 1504
1504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









