






由于项目要用到解析PDF文件的工作,于是我去了解了一些支持PDF解析的Go库,常见的很多库
https://github.com/rsc/pdf
https://github.com/hhrutter/pdfcpu
https://github.com/ledongthuc/pdf
https://github.com/unidoc/unidoc
https://github.com/sajari/docconv
这些库里面,
ledongthuc/pdf 是我用着感觉最不错而且免费的库,可惜只能支持本地解析,不能通过io.Reader 的方式解析PDF文件。
unidoc/unidoc 这个库,需要收费,注册一个号后可以免费使用100次。
其他的库,都不太推荐。
在我一筹莫展的时候,一篇文章给予了我希望。在此附上这篇文章的链接,感谢这篇文章的作者让我实现了解析的工作
我看了博主的第二种方案,Tika + go client 思路是,在Docker 里 拉取 apache/tika 镜像,然后运行这个容器,然后在项目中引入go-tika 包,通过client给服务器的tika容器发处理请求。然后就可得到pdf的内容了。
以下是我的实现代码:
// 调用Tika库生成字符串
func ProcessTikaData(f io.Reader) (resumeContent string, err error) {
//模拟客户端
client := tika.NewClient(nil, "http://服务器ip地址:9998")
//转成str的html页面
context1, err := client.Parse(context.TODO(), f)
//正则匹配
reg := regexp.MustCompile(`(?s)<p>(.*?)</p>`)
//找到所有的成切片
res := reg.FindAllStringSubmatch(context1, -1)
//遍历添加到resumeContent
for _, match := range res {
resumeContent += match[1]
}
return resumeContent, err
}每一步我都加了注释,context1 得到的是字符串类型的HTML页面,控制台输出如下
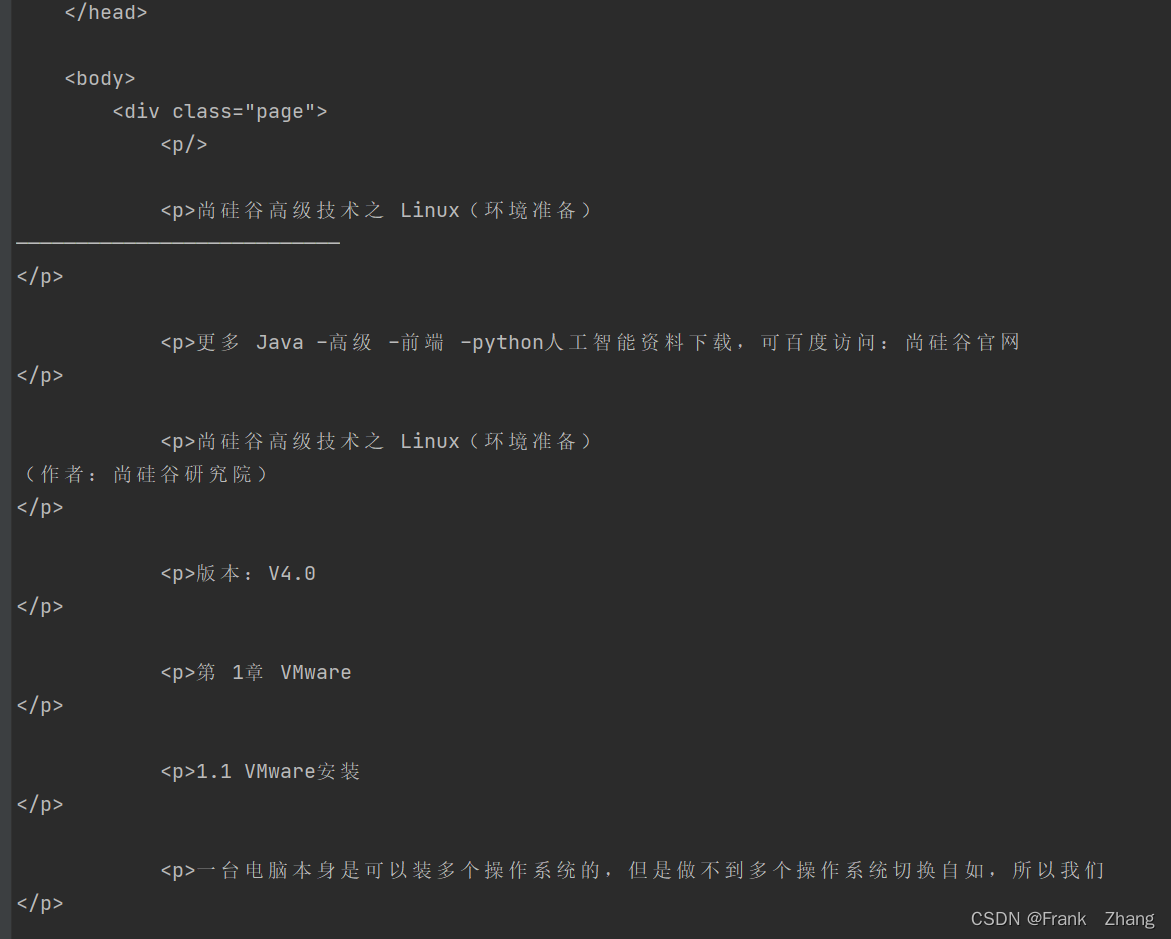
里面p标签的内容才是我想要的,因此我使用了正则匹配,检索到了p标签的内容。输出如下

在主函数中调用该方法:
func ParseHandler(c *gin.Context) {
//判断是否上传文件
_, header, err := c.Request.FormFile("file")
if err != nil {
zap.L().Error("文件没有上传", zap.Error(err))
ResponseError(c, CodeInvalidParams)
return
}
//判断文件是否接收成功
f, err := header.Open()
if err != nil {
zap.L().Error("接收文件失败", zap.Error(err))
ResponseErrorWithMsg(c, CodeServerBusy, "接收文件失败")
return
}
//接收返回的数据
resumeData, err := ProcessTikaData(f)
if err != nil {
zap.L().Error("", zap.Error(err))
ResponseErrorWithMsg(c, CodeServerBusy, "简历字符串生成失败")
return
}
fmt.Println(resumeData)
}这个主函数实现了非本地文件解析的功能,不是输入本地文件路径进行解析,而是获得到二进制文件流的形式,适用于前端客户上传文件的功能。
在Apifox中,传递的参数如下图所示:
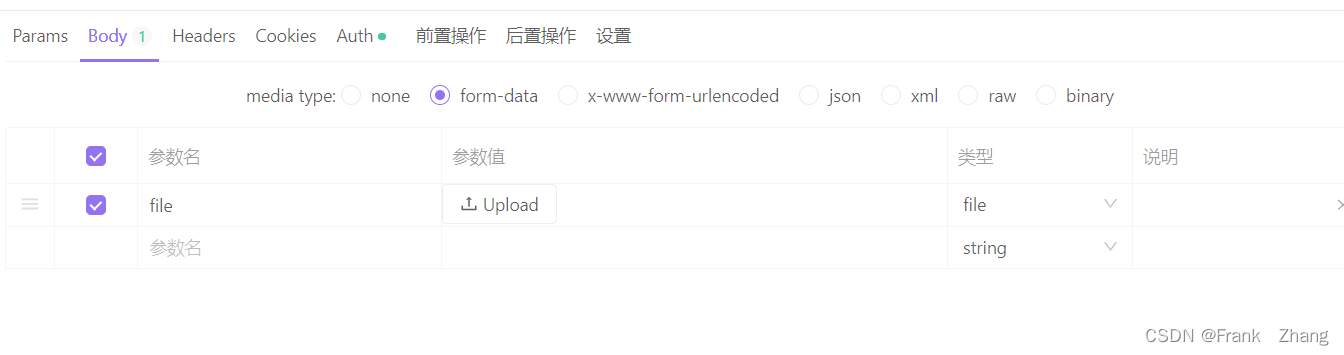
以上就是我的实现方案。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









