







我们今天继续来学习排序算法 —— 归并排序:
归并排序
归并排序(Merge Sort)是一种高效的、稳定的排序算法,它采用分治法(Divide and Conquer)的思想来实现。归并排序的基本工作原理如下:
- 分(Divide):将当前序列分成两个尽可能相等的子序列。如果当前序列只有一个元素或者为空,则不需要进一步划分,因为它本身就是有序的。
- 治(Conquer):递归地对两个子序列分别进行归并排序。这意味着每个子序列都要重复执行划分和递归排序的过程,直到子序列不能再分割为止(即子序列中只有一个元素)。
- 合(Combine):将两个已经排序好的子序列合并成一个有序序列。合并的过程是通过比较两个子序列中的元素,将较小的元素先放入一个新的序列中,直到一个子序列为空,然后再将另一个子序列中剩余的元素依次加入新序列中。这个过程保证了新序列的整体有序性。
归并排序的关键操作是合并步骤,这也是算法名称的由来。整个算法通过这种方式逐步构建出整个序列的排序结果,从最小的子序列开始,一步步合并出更大范围的有序序列,直到整个序列变得有序。
我们一步一步来看:
分
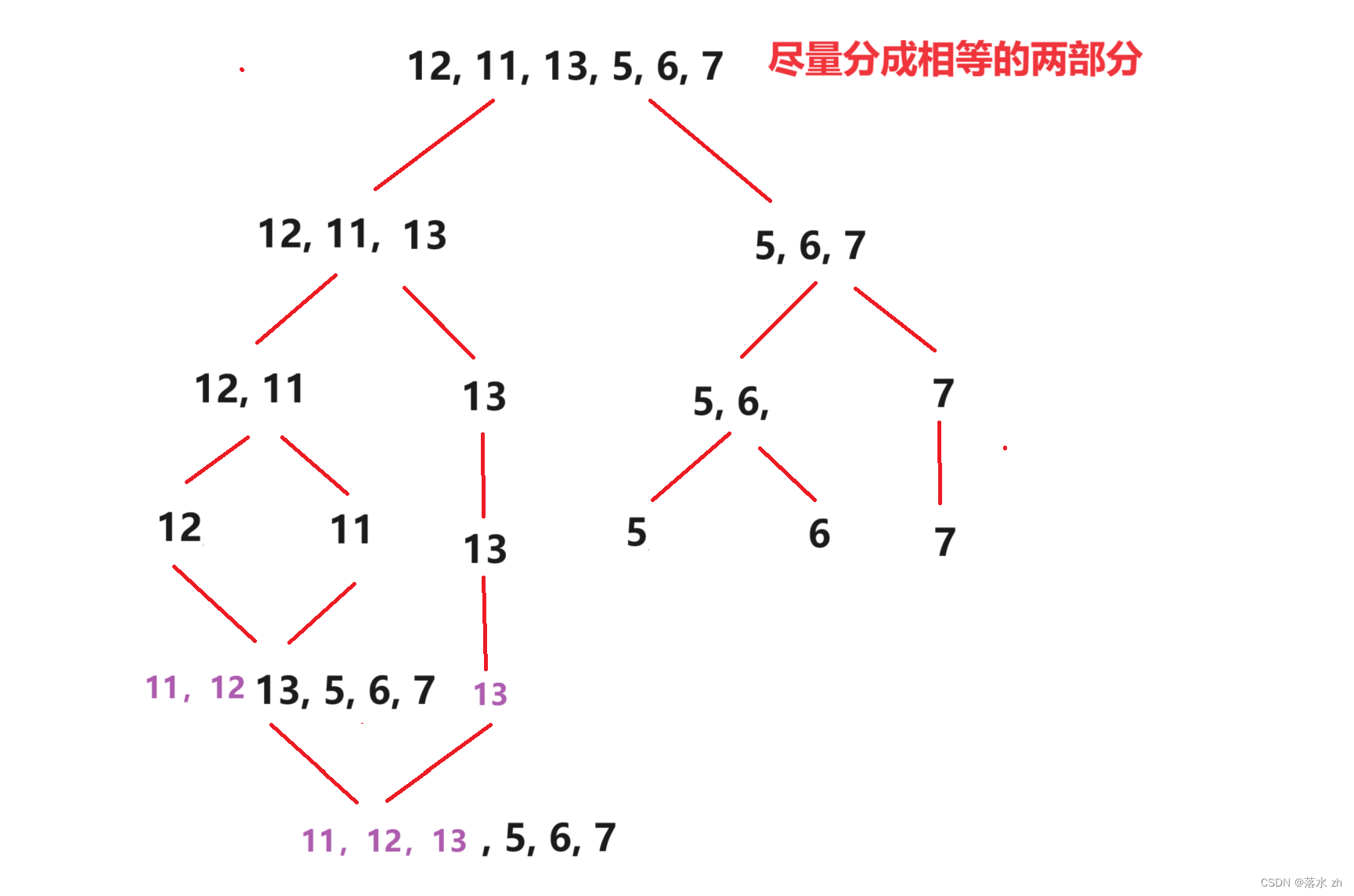
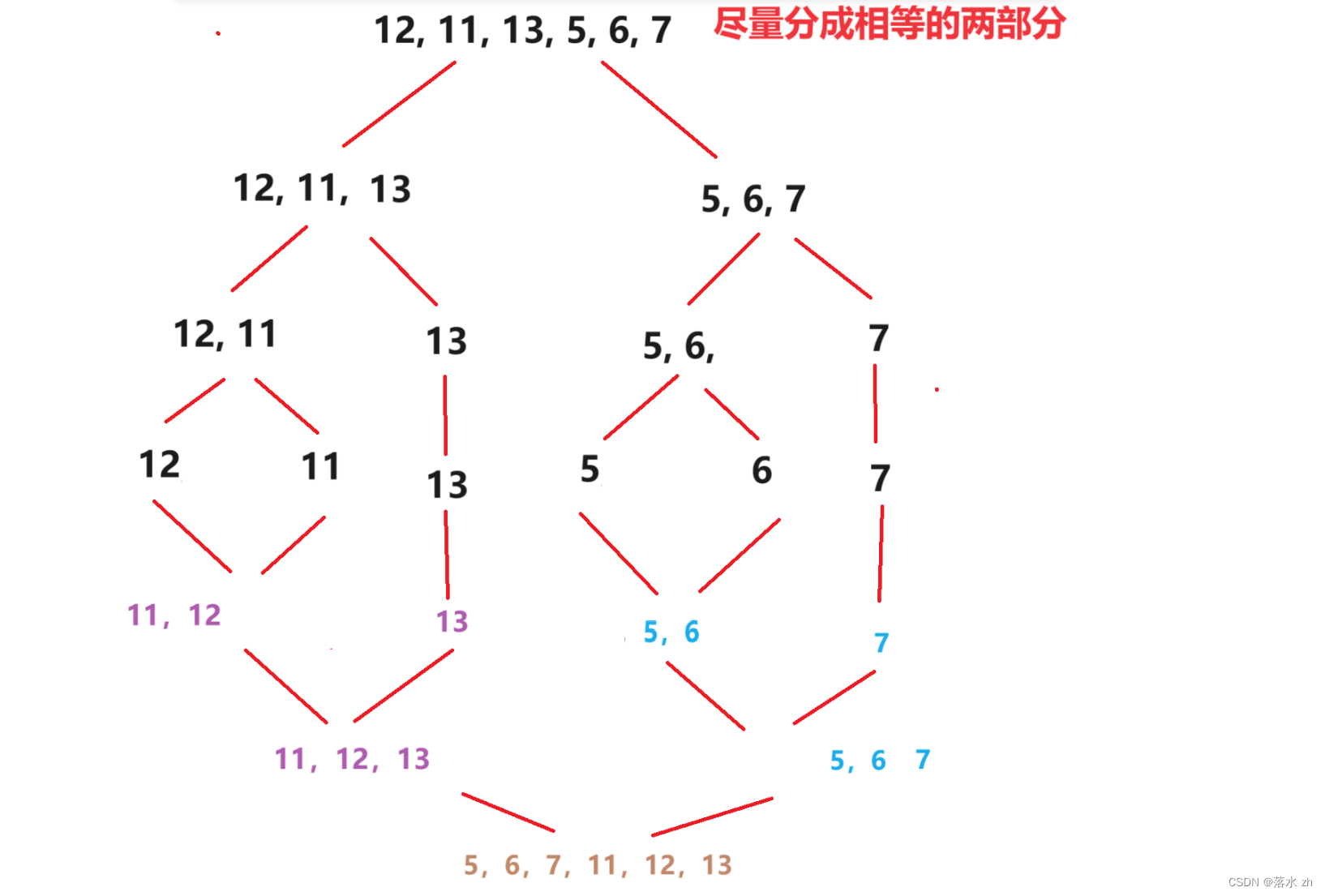
归并排序首先要分,将区间分成尽量相等的区间:
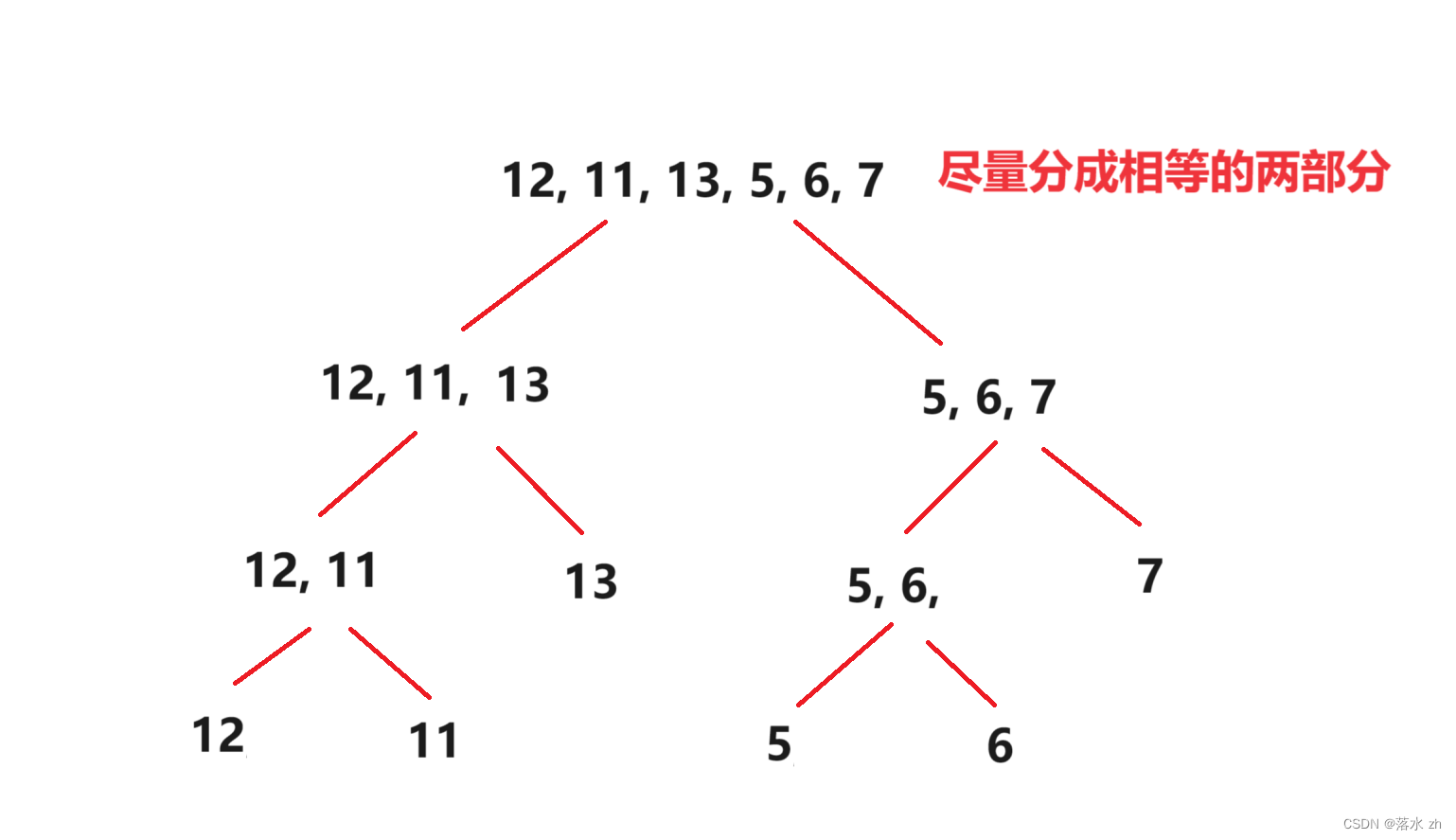
这里我们注意一下,我们一来对区间进行详尽的划分,中间并没有进行任何的其他操作。
我们可以用递归来一直模拟二分:
void merge_sort(std::vector<int>& array,
int left,int right,std::vector<int>& temp) //temp是辅助数组
{
if (left >= right)
return;
//分
int mid = left + (right - left) / 2;
merge_sort(array, left, mid, temp);
merge_sort(array, mid + 1, right, temp);
}
划分到不能再划分时,我们进行第二步:
治(排序)
我们划分到了最后,会有两个部分的数据:
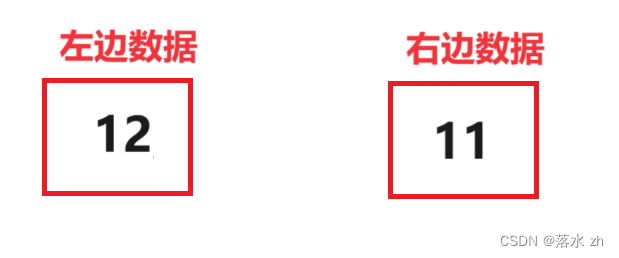
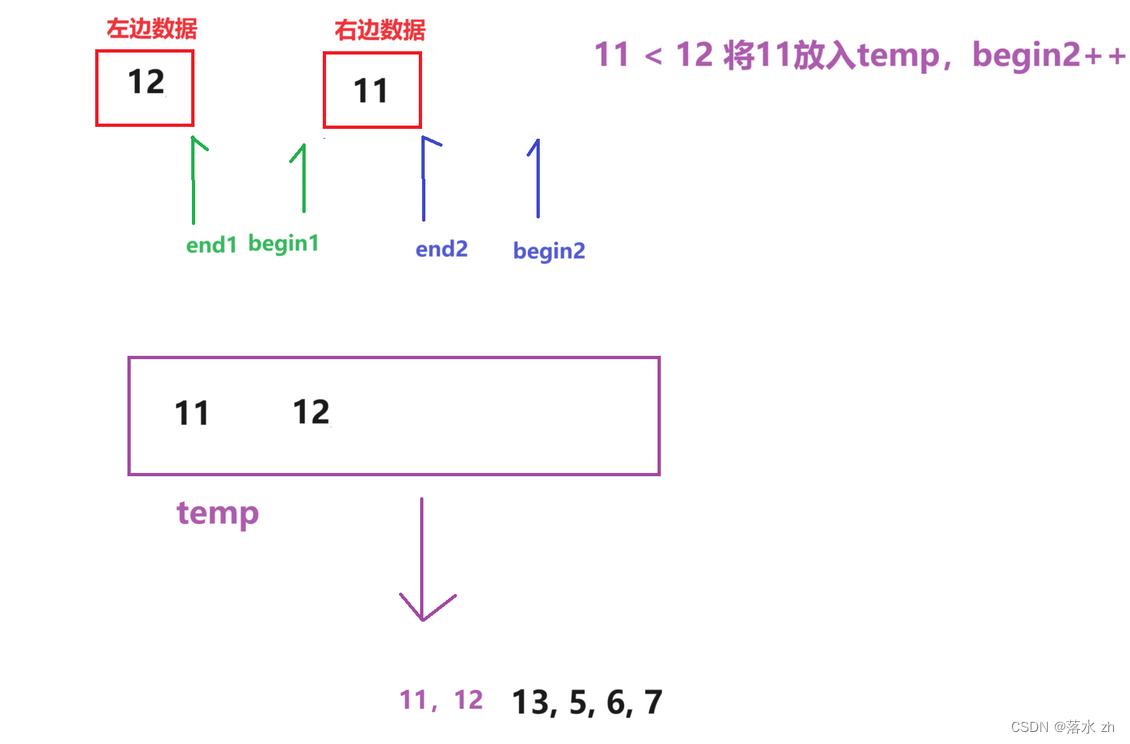
这个时候,我们要对两个部分数据进行排序,我们一边拿一进行比较:

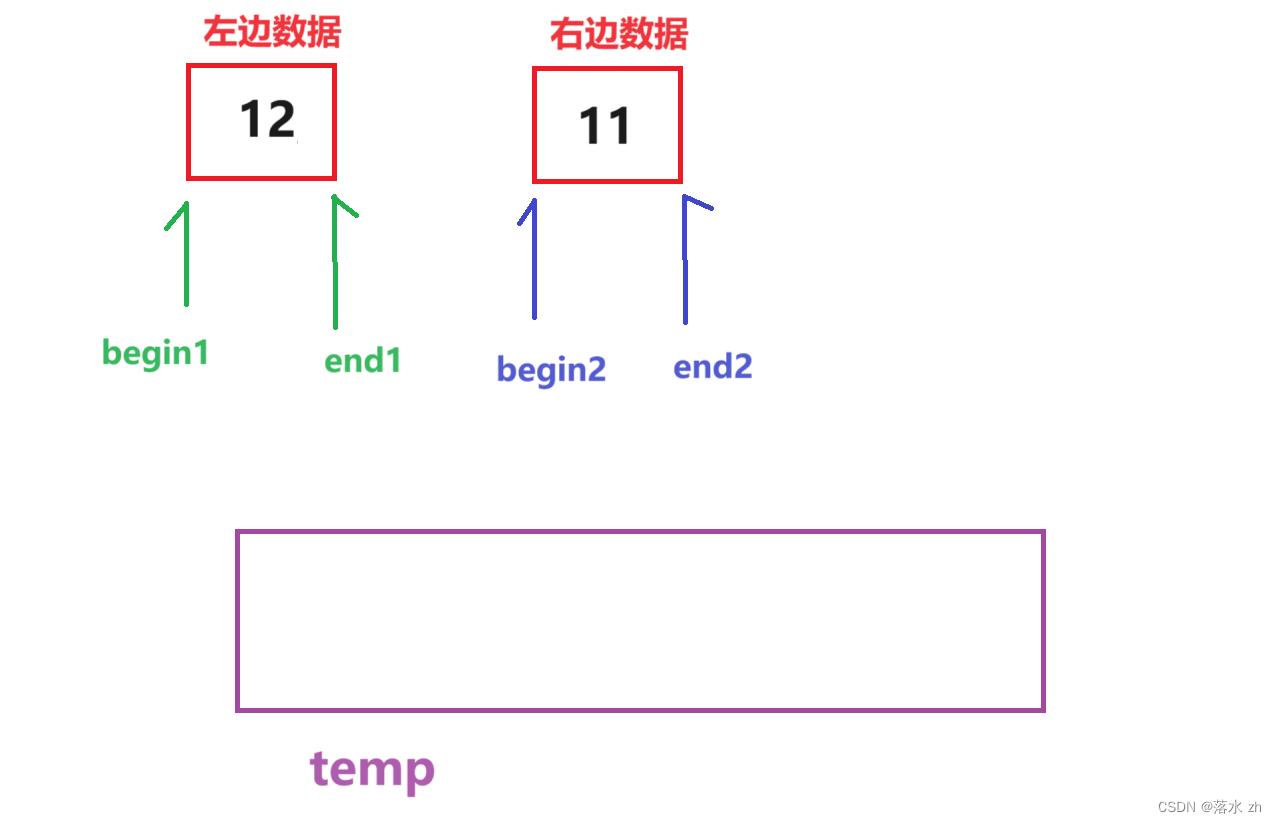
我们用一个临时数组,用来存放比较之后的数据:
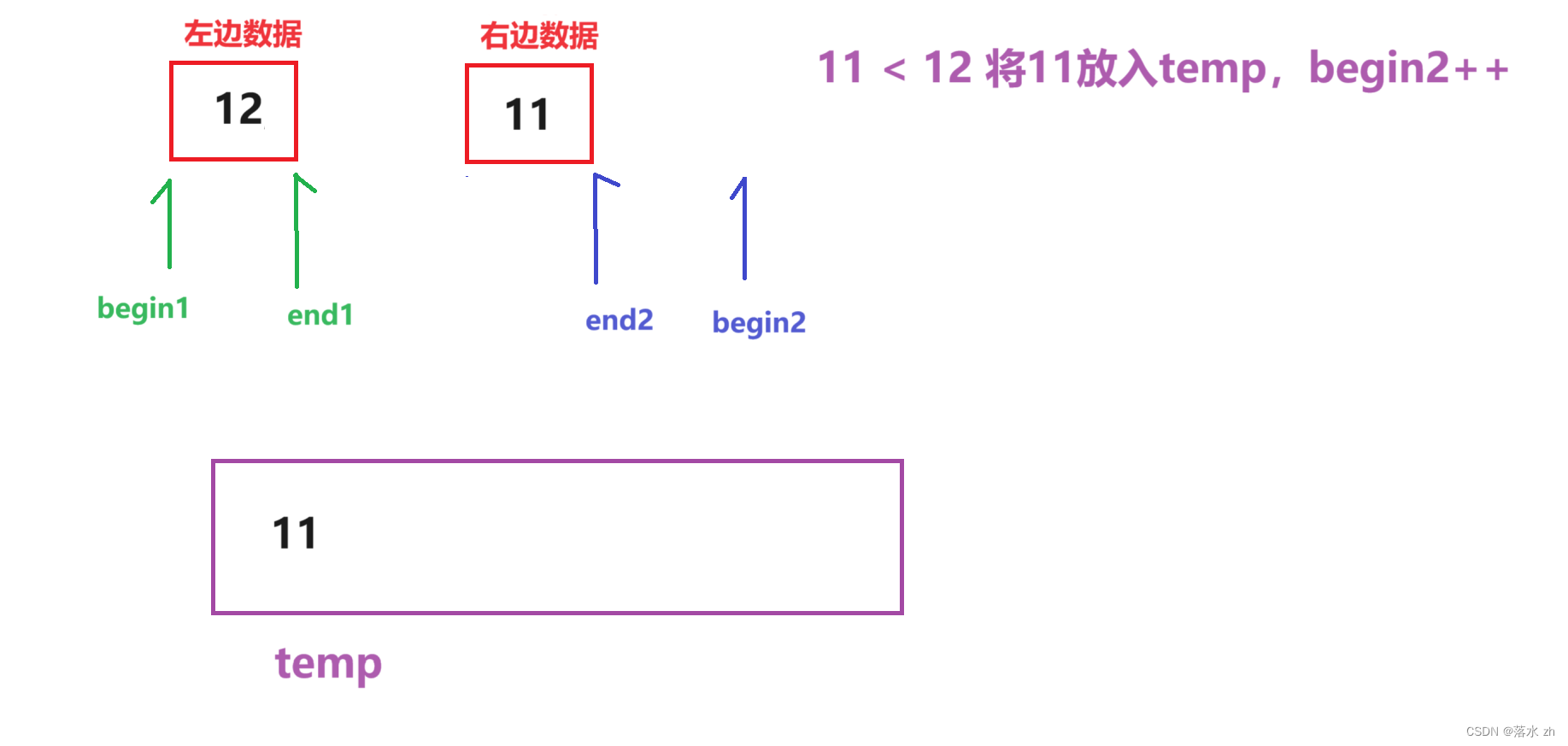
此时begin2越界,只需要将左边的数据放入temp:
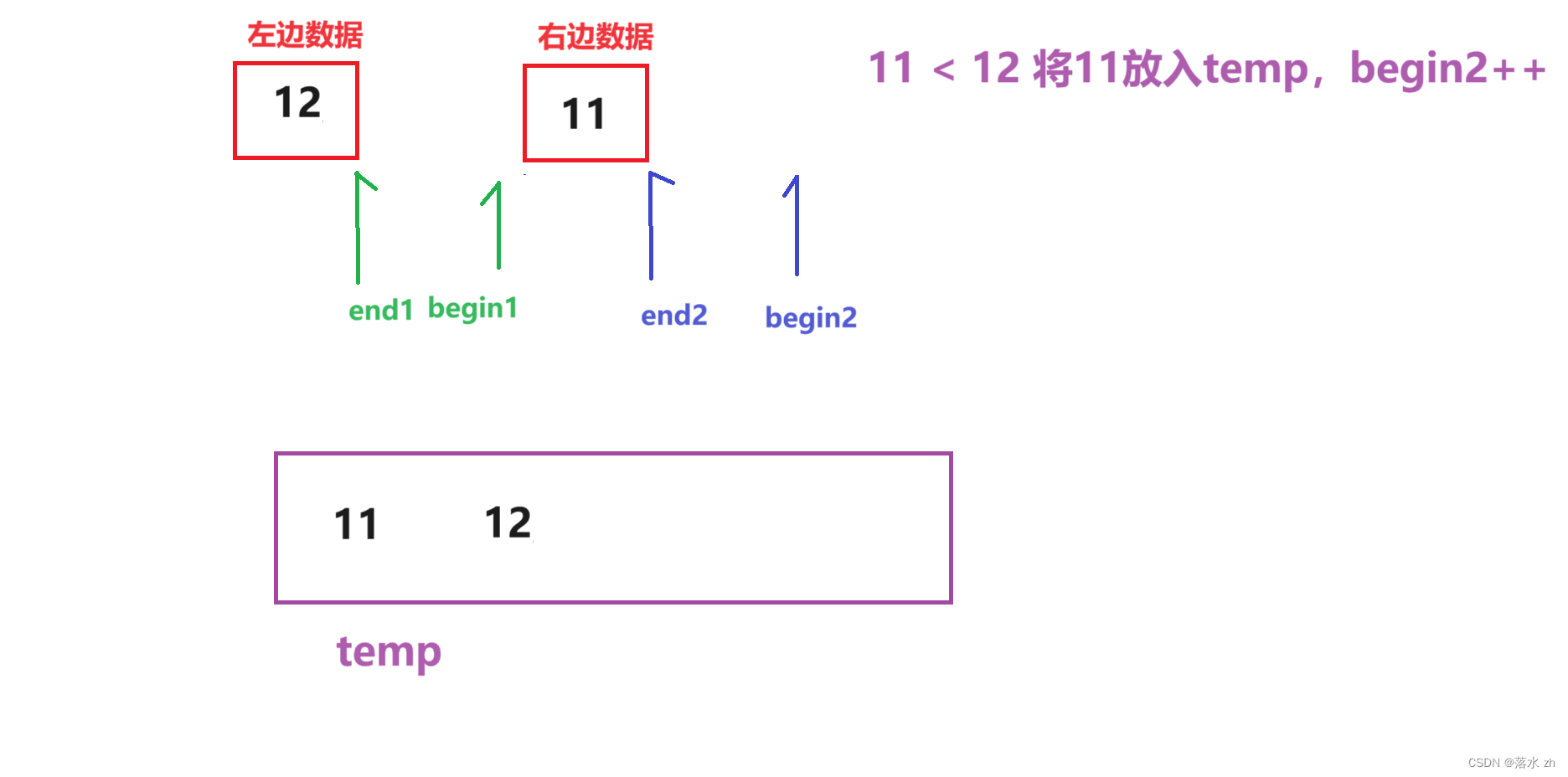
然后我们要放回原来的数组:
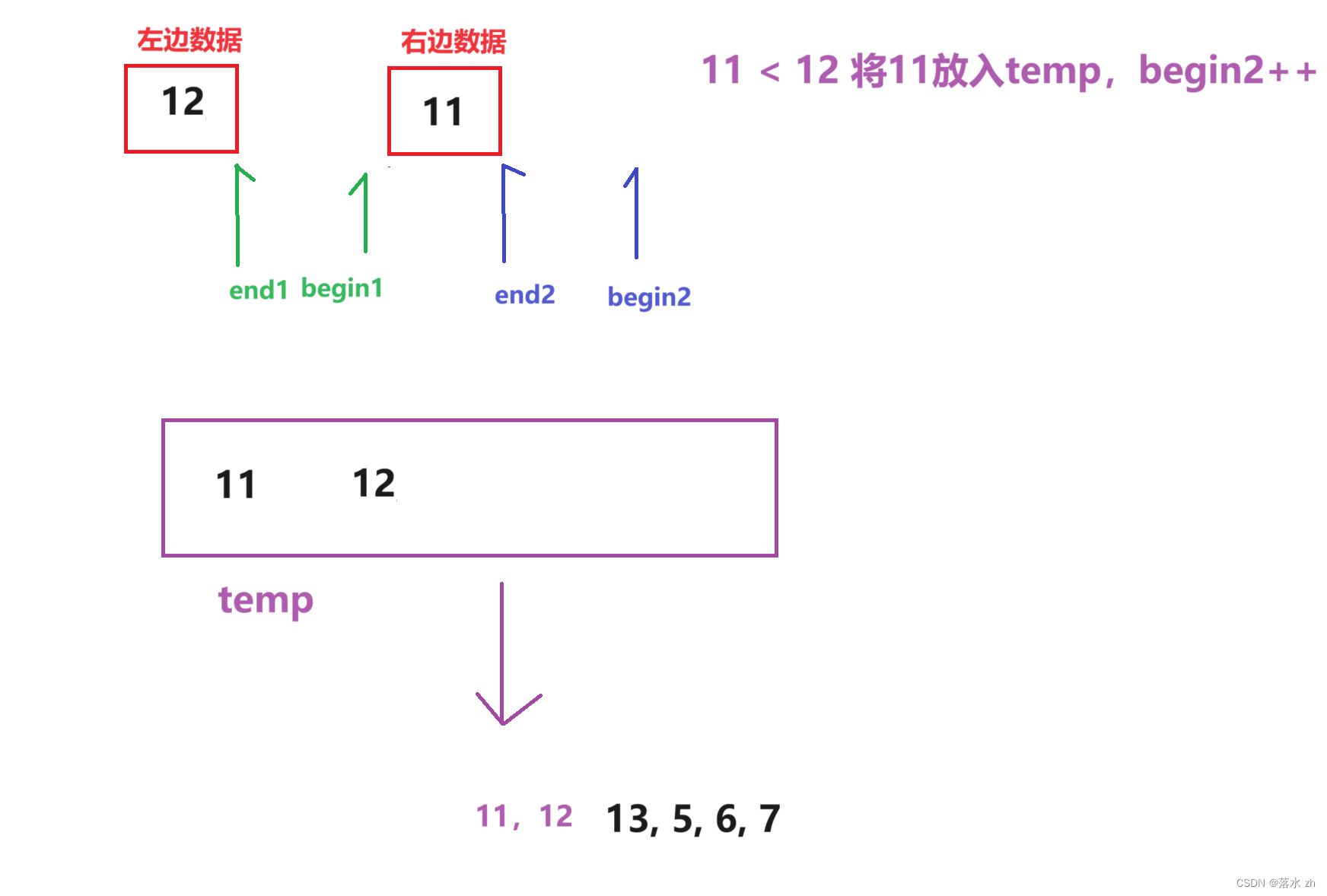 整体是这样的:
整体是这样的:
// 归并排序函数
void merge_sort(std::vector<int>& array, int left, int right, std::vector<int>& temp) {
// 基准情况:如果左边索引大于等于右边索引,说明区间内只有一个元素或无元素,不需要排序
if (left >= right) {
return;
}
// 分:找到中间索引,将当前区间分为两个子区间,递归地对它们进行排序
int mid = left + (right - left) / 2; // 防止大数相加导致溢出
merge_sort(array, left, mid, temp); // 对左半区间排序
merge_sort(array, mid + 1, right, temp); // 对右半区间排序
// 在合并之前清空temp,确保在一个干净的环境中进行合并操作
temp.clear();
// 合:将两个有序子区间合并成一个有序区间
int begin1 = left; // 左子区间的起始索引
int end1 = mid; // 左子区间的结束索引
int begin2 = mid + 1; // 右子区间的起始索引
int end2 = right; // 右子区间的结束索引
// 合并两个子区间
while (begin1 <= end1 && begin2 <= end2) {
// 如果左子区间当前元素大于右子区间当前元素,将右子区间元素加入temp
if (array[begin1] > array[begin2]) {
temp.push_back(array[begin2++]);
}
// 反之,将左子区间元素加入temp
else {
temp.push_back(array[begin1++]);
}
}
// 处理剩余的元素,如果左半边还有剩余,全部加入temp
while (begin1 <= end1) {
temp.push_back(array[begin1++]);
}
// 如果右半边还有剩余,全部加入temp
while (begin2 <= end2) {
temp.push_back(array[begin2++]);
}
}
合
这里的合就是拷贝回原数组的过程:
// 拷贝回原数组
// 注意:这里使用i - left是因为temp是从0开始的,而原数组的子区间是从left开始的
for (int i = left; i <= right; i++) {
array[i] = temp[i - left];
}
// 归并排序函数
void merge_sort(std::vector<int>& array, int left, int right, std::vector<int>& temp) {
// 基准情况:如果左边索引大于等于右边索引,说明区间内只有一个元素或无元素,不需要排序
if (left >= right) {
return;
}
// 分:找到中间索引,将当前区间分为两个子区间,递归地对它们进行排序
int mid = left + (right - left) / 2; // 防止大数相加导致溢出
merge_sort(array, left, mid, temp); // 对左半区间排序
merge_sort(array, mid + 1, right, temp); // 对右半区间排序
// 在合并之前清空temp,确保在一个干净的环境中进行合并操作
temp.clear();
// 合:将两个有序子区间合并成一个有序区间
int begin1 = left; // 左子区间的起始索引
int end1 = mid; // 左子区间的结束索引
int begin2 = mid + 1; // 右子区间的起始索引
int end2 = right; // 右子区间的结束索引
// 合并两个子区间
while (begin1 <= end1 && begin2 <= end2) {
// 如果左子区间当前元素大于右子区间当前元素,将右子区间元素加入temp
if (array[begin1] > array[begin2]) {
temp.push_back(array[begin2++]);
}
// 反之,将左子区间元素加入temp
else {
temp.push_back(array[begin1++]);
}
}
// 处理剩余的元素,如果左半边还有剩余,全部加入temp
while (begin1 <= end1) {
temp.push_back(array[begin1++]);
}
// 如果右半边还有剩余,全部加入temp
while (begin2 <= end2) {
temp.push_back(array[begin2++]);
}
// 拷贝回原数组
// 注意:这里使用i - left是因为temp是从0开始的,而原数组的子区间是从left开始的
for (int i = left; i <= right; i++) {
array[i] = temp[i - left];
}
}
这段代码实现了一个标准的归并排序算法流程,包括了递归划分区间、合并已排序区间,以及最终将排序结果拷贝回原数组的操作。通过这样的分治策略,归并排序能够高效地对整个数组进行排序。
归并排序的性能
归并排序(Merge Sort)在性能上的主要特点如下:
-
时间复杂度:
- 归并排序的时间复杂度在平均情况、最好情况以及最坏情况下均为O(n log n),其中n是数组中的元素数量。这是因为归并排序总是将数组分成两半处理,每一层递归深度为log n层,每层需要线性时间n来合并,故总时间为n * log n。
- 这种时间复杂度保证了归并排序对于大规模数据集来说是非常高效的,且性能稳定,不依赖于原始数据的排列状态。
-
空间复杂度:
- 归并排序的空间复杂度为O(n),主要原因是需要一个与原数组相同大小的临时数组来合并两个子数组。这是归并排序的一个缺点,尤其是在处理极大规模数据时,额外的空间需求可能成为一个限制因素。
- 不过,也有原地归并排序(In-place Merge Sort)的变体尝试减少空间复杂度,但它们通常比标准归并排序更复杂且可能牺牲一些性能。
- 稳定性:
- 归并排序是一种稳定的排序算法,即相等的元素在排序前后相对位置不变。这是因为合并过程中,当遇到两个相等的元素时,总是先取左边子数组的元素,保持了稳定性。
- 适用场景:
- 归并排序适合于数据量较大的排序场景,特别是对稳定性有要求的情况。它也是外部排序算法的基础,例如在处理磁盘文件排序时非常有用,因为可以将数据分块读入内存进行排序后再合并。
- 对于内存受限环境,归并排序可能不是最佳选择,此时空间效率更高的算法(如原地排序算法)可能更为合适。
- 比较与其他排序算法:
- 相较于快速排序,归并排序虽然两者的时间复杂度相同,但归并排序是稳定的且时间复杂度不会受输入数据的影响。而快速排序在最坏情况下可能退化到O(n^2),尽管通过随机化选取枢轴可以很大程度上避免这种情况。
- 与插入排序、冒泡排序等简单排序算法相比,归并排序的时间复杂度明显更低,尤其在处理大量数据时优势显著,但它们的空间复杂度更低,更适合小数据集或几乎已排序的数据。
综上所述,归并排序在时间效率上表现出色,尤其适合大规模数据集的排序,但在空间使用上较为奢侈,这是使用时需要考虑的主要权衡点。
一些小总结
我们抽离一下,看看这个代码的结构:
void merge_sort(std::vector<int>& array,
int left,int right,std::vector<int>& temp)
{
if (left >= right)
return;
//分
int mid = left + (right - left) / 2;
merge_sort(array, left, mid, temp);
merge_sort(array, mid + 1, right, temp);
temp.clear(); //保证是在一个干净的环境里进行工作
//合
int begin1 = left;
int end1 = mid;
int begin2 = mid + 1;
int end2 = right;
while (begin1 <= end1 && begin2 <= end2)
{
if (array[begin1] > array[begin2])
{
temp.push_back(array[begin2++]);
}
else
{
temp.push_back(array[begin1++]);
}
}
//剩下的多出来的也放进去
while (begin1 <= end1)
{
temp.push_back(array[begin1++]);
}
while (begin2 <= end2)
{
temp.push_back(array[begin2++]);
}
//铐回原来的数组
for (int i = left; i <= right; i++)
{
array[i] = temp[i - left];
}
}
我们可以得出这样的结构:
void merge_sort(std::vector<int>& array,
int left,int right,std::vector<int>& temp)
{
//终止条件
if (left >= right)
return;
//分
int mid = left + (right - left) / 2;
merge_sort(array, left, mid, temp);
merge_sort(array, mid + 1, right, temp);
//操作
递归在前,操作在后,这是一个标准的后序遍历,所以归并排序的思想基础是基于二叉树的后序遍历。
我们来看看快速排序:
```cpp
/**
* 快速排序函数
* @param array 待排序的整型数组指针
* @param begin 数组的起始索引
* @param end 数组的结束索引
*/
void quick_sort_part(int *array, int begin, int end) {
int left = begin; // 初始化左指针
int right = end; // 初始化右指针
// 当左指针小于右指针时继续排序
if (left >= right) {
return;
}
int stander = left; // 选择数组起始位置的元素作为基准值
// 外层循环:直到左右指针相遇
while (left < right) {
// 移动右指针,直到找到一个小于等于基准值的元素或右指针到达左指针
while (right > left && array[stander] <= array[right]) {
right--;
}
// 移动左指针,直到找到一个大于等于基准值的元素或左指针到达右指针
while (left < right && array[stander] >= array[left]) {
left++;
}
// 如果左右指针未相遇,则交换这两个元素的位置
if (left < right) {
swap(array[left], array[right]);
}
}
// 将基准值放到最终位置(左右指针相遇的位置)
swap(array[stander], array[left]);
// 对基准值左边的子数组进行快速排序
quick_sort_part(array, begin, left - 1);
// 对基准值右边的子数组进行快速排序
quick_sort_part(array, left + 1, end);
}
提出框架:
```cpp
/**
* 快速排序函数
* @param array 待排序的整型数组指针
* @param begin 数组的起始索引
* @param end 数组的结束索引
*/
void quick_sort_part(int *array, int begin, int end) {
//初始化操作
// 当左指针小于右指针时继续排序,停止条件
if (left >= right) {
return;
}
//中间操作
// 对基准值左边的子数组进行快速排序
quick_sort_part(array, begin, left - 1);
// 对基准值右边的子数组进行快速排序
quick_sort_part(array, left + 1, end);
}
发现了吗,快速排序基于二叉树前序遍历的思想。
如果刷题刷的多的话,会发现大部分的问题是基于二叉树,或者n叉树的框架来的,所以有意识的积累,对解题有帮助。

















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









