







1.创建scrapy命令
scrapy startproject 项目名称
2.创建爬虫文件
2.1:cd spider2022
2.2: scrapy genspider 爬虫文件名 爬的网站域名

3.通过PyCharm软件打开爬虫项目
4.爬取 https://movie.douban.com/top250 25页数据
4.1:在蜘蛛文件里爬取内容 spiders.douban.py下
import scrapy
from scrapy import Selector
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
sel=Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
for list_item in list_items:
list_item.css('span.title::text').extract_first()
list_item.css('span.rating_num::text').extract_first()
list_item.css('span.inq::text').extract_first()4.2:在items.py创建爬取的对象 (设置爬取的字段名称) 就是组装数据
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
# 爬虫获取到的数据需要封装成item对象
class MovieItem(scrapy.Item):
title =scrapy.Field()
rank= scrapy.Field()
subject=scrapy.Field()修改douban.py文件
import scrapy
from scrapy import Selector
from spider2022.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
sel=Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
for list_item in list_items:
move_item=MovieItem()
move_item['title']=list_item.css('span.title::text').extract_first()
move_item['rank']=list_item.css('span.rating_num::text').extract_first()
move_item['subject']=list_item.css('span.inq::text').extract_first()
yield move_item5.伪装自己为浏览器
打开setting.py打开 USER_AGENT改成 这里可以直接复制network里的useagent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.27'
5.1:里面还有设置并发数量(爬取多个网页)
# 下载延迟
DOWNLOAD_DELAY = 3
# 下载随机数
RANDOMIZE_DOWNLOAD_DELAY = True# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 326.现在就可以爬虫了 文件格式:json,csv...
scrapy crawl 爬虫文件名称 -o 设置文件格式
scrapy crawl douban -o douban.csv7.爬取成功
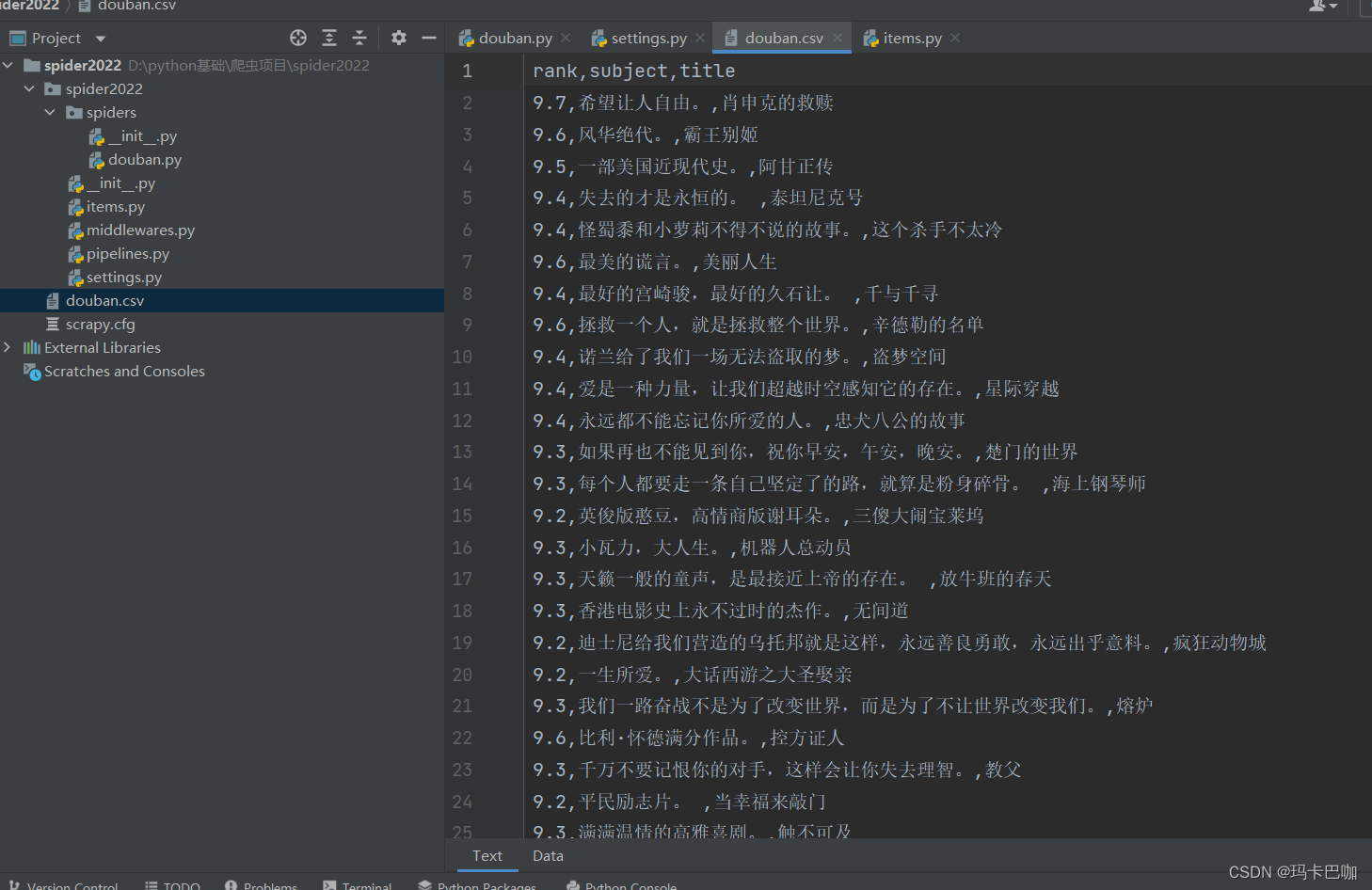
8.查询多页数据
import scrapy
from scrapy import Selector,Request
from scrapy.http import HtmlResponse
from spider2022.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
def start_requests(self):
for page in range(10):
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response: HtmlResponse):
sel=Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
for list_item in list_items:
move_item=MovieItem()
move_item['title']=list_item.css('span.title::text').extract_first()
move_item['rank']=list_item.css('span.rating_num::text').extract_first()
move_item['subject']=list_item.css('span.inq::text').extract_first()
yield move_item9.生成xlsx文件,通过管道,在pipelines.py中
import openpyxl
# 处理数据管道
class Spider2022Pipeline:
def __init__(self):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.title="TOP250"
self.ws.append(('标题','评分','主题'))
def close_spider(self,spider):
self.wb.save('电影数据.xlsx')
def process_item(self, item, spider):
title =item.get('title','')
rank=item.get('rank','')
subject=item.get('subject','')
self.ws.append((title,rank,subject))
return item
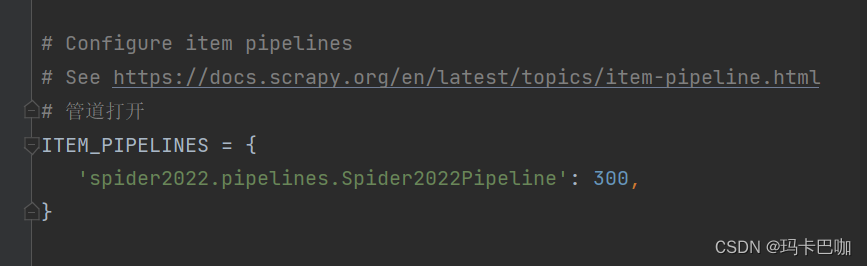
在setting中把一下设置打开,管道符打开
10,爬进mysql数据库
10.1:在管道符再创建一个作用于mysql的类
# 自动导入连接数据库的三方库
import pymysql
from itemadapter import ItemAdapter
import openpyxl
# 导入数据库
class DbPipeline:
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='5771323', database='spider', charset='utf8')
self.cursor=self.conn.cursor()
def close_spider(self,spider):
self.conn.commit()
self.conn.close()
def process_item(self,item,spider):
title = item.get('title', '')
rank = item.get('rank', 0)
subject = item.get('subject', '')
self.cursor.execute(
'insert into douban_movie (title,rating,subject) values (%s, %s, %s)',
(title, rank, subject)
)
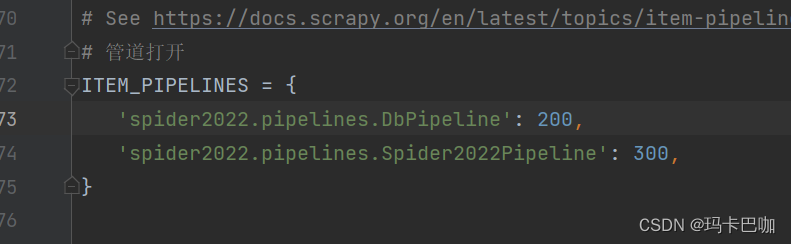
return item10.2:再setting中新加这个类
导入数据库注意的问题:
1.写查询语句时要写对语法,不要写出数据库的名字。
2.注意逗号不要忘记,特别是后面的%s之间要加逗号。
3.别忘了开通新的管道符
4.每次要提交commit()不能忘,否则就insert不进去。
5.这个方法有三个参数 def process_item(self,item,spider): 不要写错
11.优化数据库的批量操作:
本质就是创建一个容器给他每次追加数据,然后判断多少次提交,最后关闭时还要判断一次提交就ok。
import pymysql
from itemadapter import ItemAdapter
import openpyxl
# 导入数据库
class DbPipeline:
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='5771323', database='spider', charset='utf8mb4')
self.cursor = self.conn.cursor()
self.data=[]
def close_spider(self, spider):
if len(self.data) > 0:
# 调用方法
self._write_todb()
self.conn.close()
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', 0)
subject = item.get('subject', '')
self.data.append((title, rank, subject))
if len(self.data) == 100:
# 调用方法
self._write_todb()
self.data.clear()
return item
# 封装这个方法,来实现插入库操作
def _write_todb(self):
self.cursor.executemany(
'insert into douban_movie (title, rating, subject) values (%s, %s, %s)',
self.data
)
self.conn.commit()11.2:数据代理,防止被封ip
在蜘蛛文件中设置即可
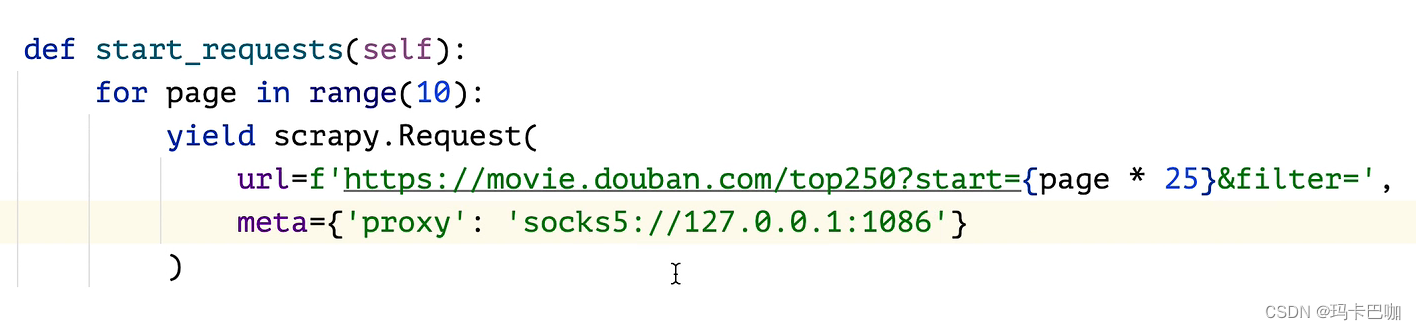
12.查询多个页面:
12.1:修改爬虫文件
import scrapy
from scrapy import Selector,Request
from scrapy.http import HtmlResponse
from spider2022.items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
def start_requests(self):
for page in range(10):
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response: HtmlResponse):
sel=Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
for list_item in list_items:
detail_url = list_item.css('div.info > div.hd > a::attr(href)').extract_first()
move_item=MovieItem()
move_item['title']=list_item.css('span.title::text').extract_first()
move_item['rank']=list_item.css('span.rating_num::text').extract_first()
move_item['subject']=list_item.css('span.inq::text').extract_first()
yield Request(
url=detail_url,
callback=self.parse_detail,
cb_kwargs={'item': move_item}
)
def parse_detail(self, response, **kwargs):
movie_item = kwargs['item']
sel = Selector(response)
movie_item['duration'] = sel.css('span[property="v:runtime"]::attr(content)').extract()
movie_item['intro'] = sel.css('span[property="v:summary"]::text').extract_first() or ''
yield movie_item12.2:增加元素:后两个是新增的

12.3:管道符也要修改:以爬入数据库为例
import pymysql
from itemadapter import ItemAdapter
import openpyxl
# 导入数据库
class DbPipeline:
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='5771323', database='spider', charset='utf8mb4')
self.cursor = self.conn.cursor()
self.data=[]
def close_spider(self, spider):
if len(self.data) > 0:
# 调用方法
self._write_todb()
self.conn.close()
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', 0)
subject = item.get('subject', '')
duration = item.get('duration', '')
intro = item.get('intro', '')
self.data.append((title, rank, subject, duration, intro))
if len(self.data) == 100:
# 调用方法
self._write_todb()
self.data.clear()
return item
# 封装这个方法,来实现插入库操作
def _write_todb(self):
self.cursor.executemany(
'insert into douban_movie (title, rating, subject, duration, intro) '
'values (%s, %s, %s, %s, %s)',
self.data
)
self.conn.commit()














 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









