







为什么使用Elasticsearch
在海量数据中执行搜索功能时,如果使用MySQL,效率太低。
如果关键字输入的不准确,一样可以搜索到想要的数据。
将搜索关键字,以红色的字体展示。
es介绍
ES
是⼀个使⽤
Java
语⾔并且基于
Lucene
编写的搜索引擎框架,他提供了分
布式的全⽂搜索功能,提供了⼀个统⼀的基于
RESTful
⻛格的
WEB
接⼝,官
⽅客户端也对多种语⾔都提供了相应的
API
。
Lucene
:
Lucene
本身就是⼀个搜索引擎的底层。
分布式:
ES
主要是为了突出他的横向扩展能⼒。
全⽂检索:将⼀段词语进⾏分词,并且将分出的单个词语统⼀的放到⼀个
分词库中,在搜索时,根据关键字去分词库中检索,找到匹配的内容。
(倒排索引)
RESTful
⻛格的
WEB
接⼝:操作
ES
很简单,只需要发送⼀个
HTTP
请求,并
且根据请求⽅式的不同,携带参数的同,执⾏相应的功能。
应⽤⼴泛:
Github.com
,
WIKI
,
Gold Man
⽤
ES
每天维护将近
10TB
的数
据。
倒排索引
将存放的数据,以⼀定的⽅式进⾏分词,并且将分词的内容存放到⼀个单独的
分词库中。
当⽤户去查询数据时,会将⽤户的查询关键字进⾏分词。
然后去分词库中匹配内容,最终得到数据的
id
标识。
根据
id
标识去存放数据的位置拉取到指定的数据。
docker安装ES
安装ES&Kibana
[root@localhost ~]# cd /opt/
[root@localhost opt]# ls
containerd
[root@localhost opt]# mkdir docker_es
[root@localhost opt]# ls
containerd docker_es
[root@localhost opt]# cd docker_es/\
>
[root@localhost docker_es]# vi docker-compose.yml
复制粘贴保存并退出
version: "3.1"
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:6.5.4
restart: always
container_name: elasticsearch
ports:
- 9200:9200
kibana:
image: daocloud.io/library/kibana:6.5.4
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.42.129:9200
depends_on:
- elasticsearch
docker compose up -d等待下载完毕
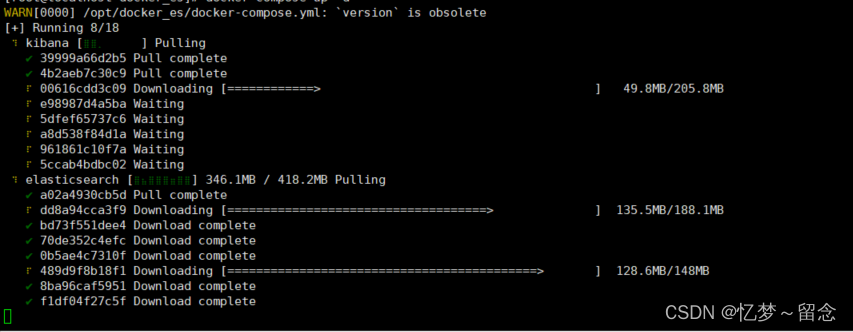
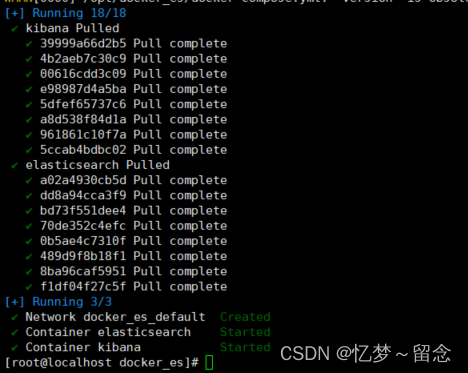
访问elasticsearch
浏览器访问http://192.168.42.129:9200/
如果无反应
#
修改⽂件
[root@localhost docker_es]# vim /etc/sysctl.conf
#
设置
ES
最⼤虚拟内存⼤⼩
#设置ES最⼤虚拟内存⼤⼩
vm.max_map_count=655360#让设置⽣效
[root@localhost docker_es]# sysctl -p
vm.max_map_count = 655360
再次运行访问
docker compose up -d

访问 kibana
浏览器访http://192.168.42.129:5601
安装ik分词器

[root@localhost docker_es]# docker exec -it 93 bash
[root@933df86f337b elasticsearch]# 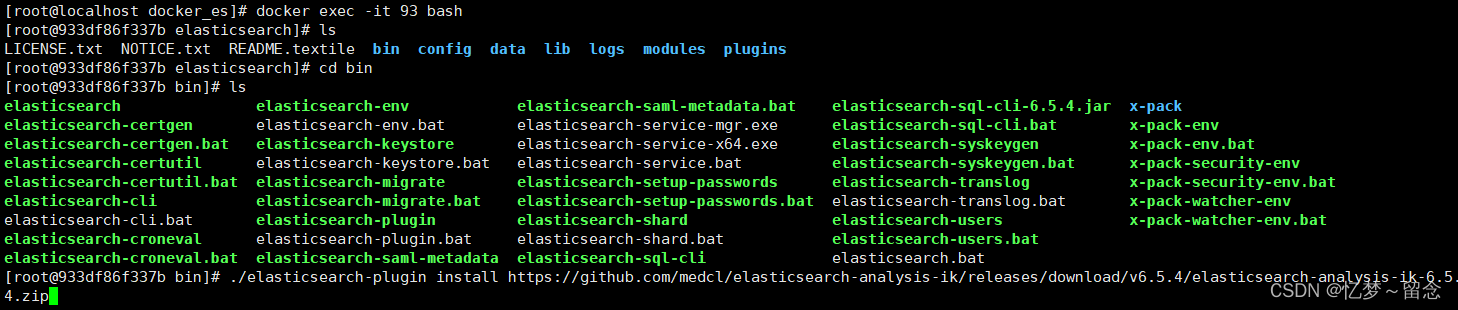
# ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
 浏览器访问http://192.168.42.129:5601/
浏览器访问http://192.168.42.129:5601/
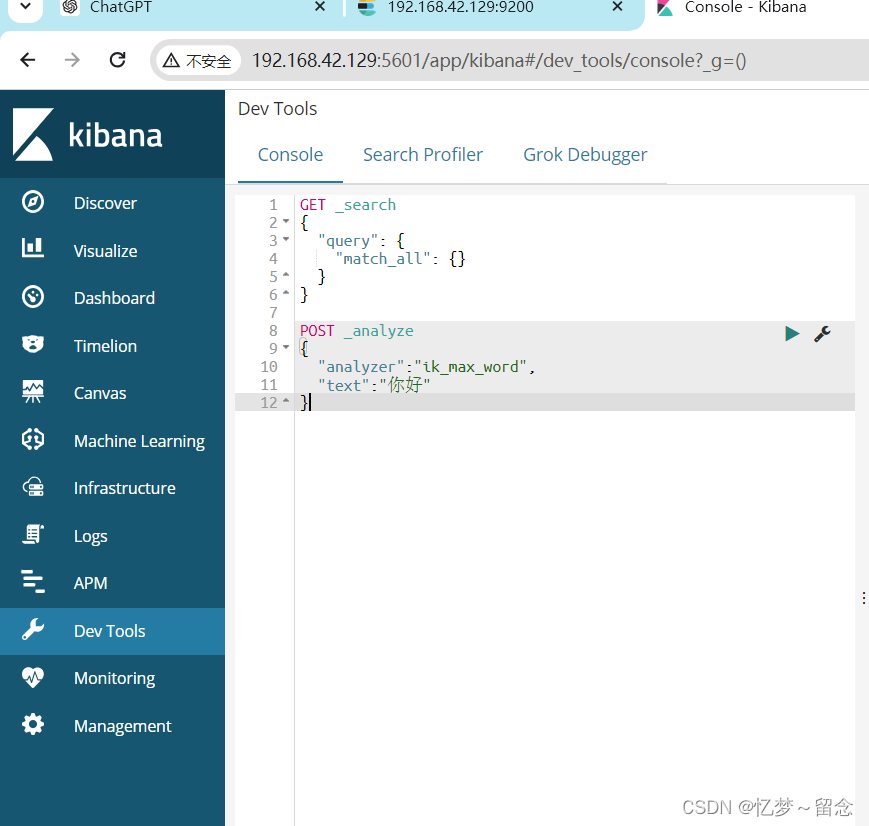
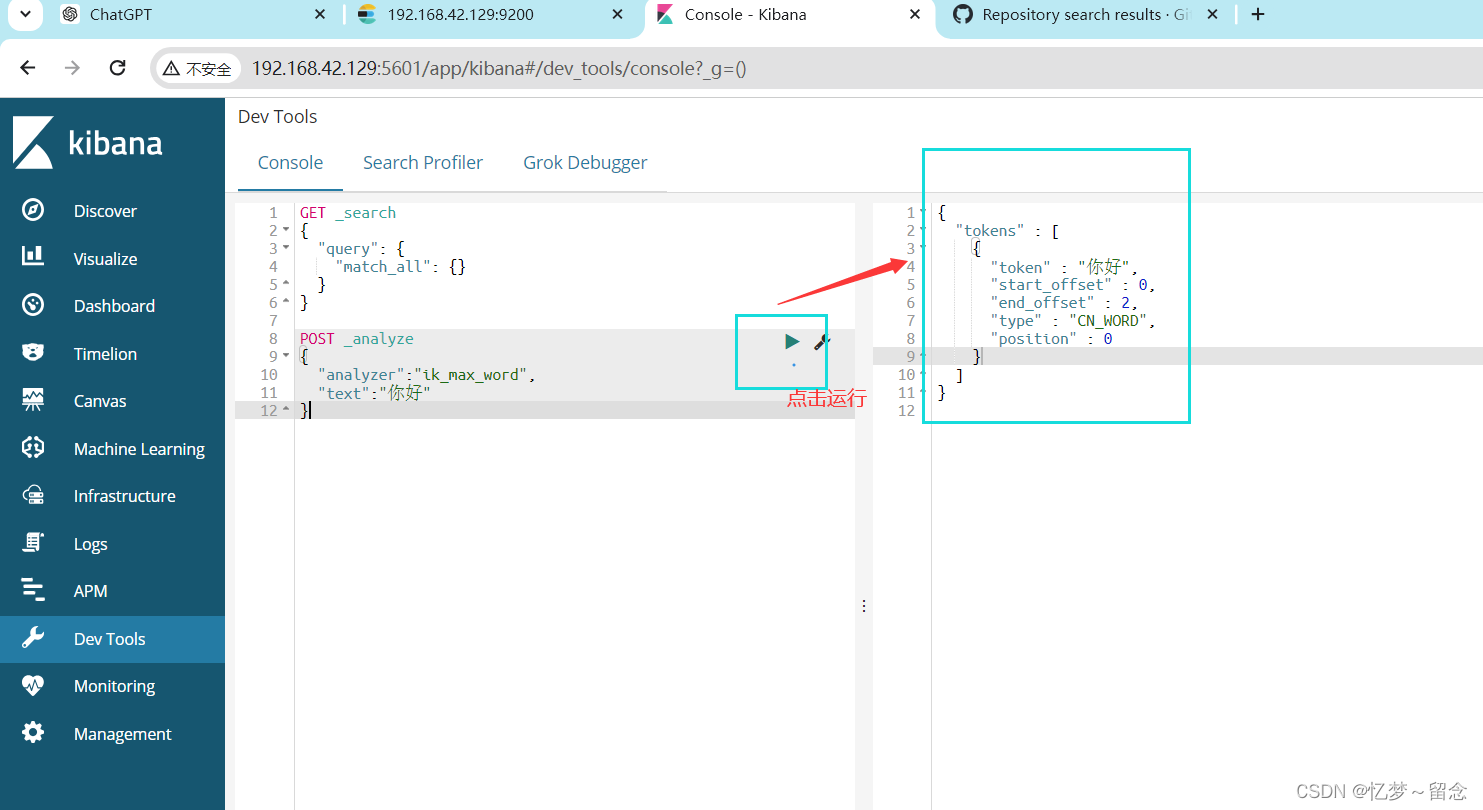
POST _analyze
{
"analyzer":"ik_max_word",
"text":"你好"
}运行
索引Index,分⽚和备份
ES
的服务中,可以创建多个索引。
每⼀个索引默认被分成
5
⽚存储。
每⼀个主分⽚都会存在⾄少⼀个备份分⽚。
备份分⽚默认不会帮助检索数据,当
ES
检索压⼒特别⼤的时候,备份分⽚
才会帮助检索数据。
备份的分⽚必须放在不同的服务器中。

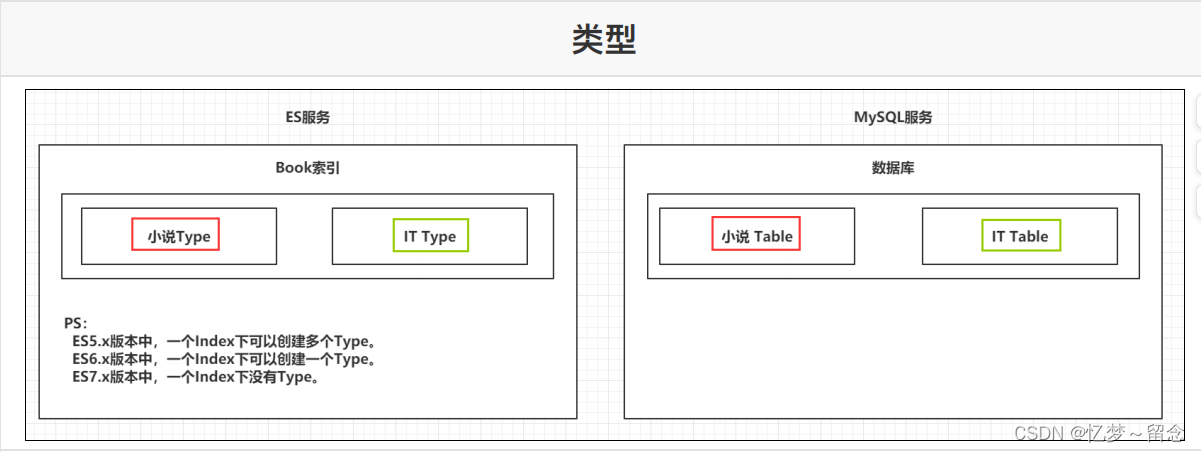
类型 Type
⼀个索引下,可以创建多个类型。
Ps:根据版本不同,类型的创建也不同。
语法
GET
请求:
http://ip:port/index
:查询索引信息
http://ip:port/index/type/doc_id
:查询指定的⽂档信息
POST
请求:
http://ip:port/index/type/_search
:查询⽂档,可以在请求体中添加
json
字符串来代表查询条件
http://ip:port/index/type/doc_id/_update
:修改⽂档,在请求体中指
定
json
字符串代表修改的具体信息
PUT
请求:
http://ip:port/index
:创建⼀个索引,需要在请求体中指定索引的信
息,类型,结构
http://ip:port/index/type/_mappings
:代表创建索引时,指定索引⽂
档存储的属性的信息
DELETE
请求:
http://ip:port/index
:删除索引
http://ip:port/index/type/doc_id
:删除指定的⽂档
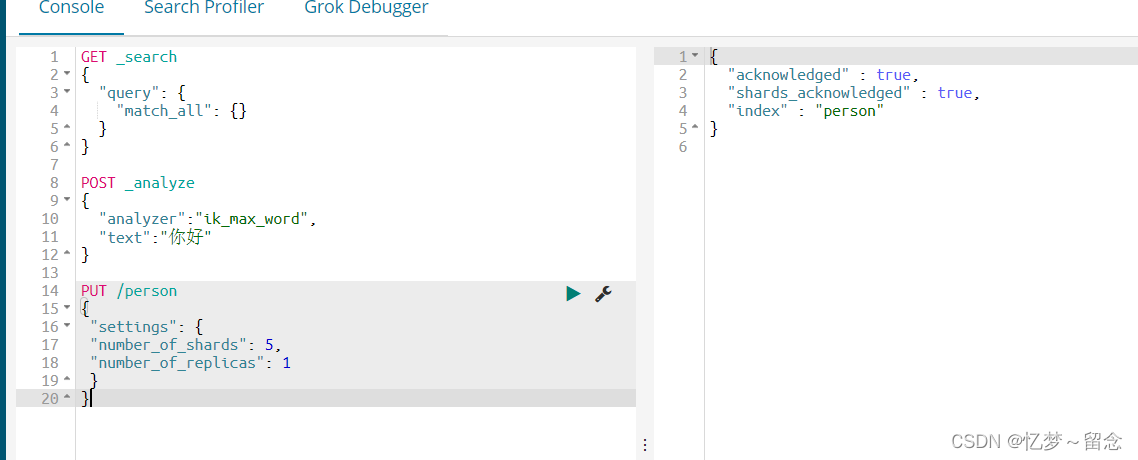
# 创建⼀个索引, person是索引名字, shards主分⽚是5⽚, replicas是备份分
⽚1⽚
PUT /person
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}
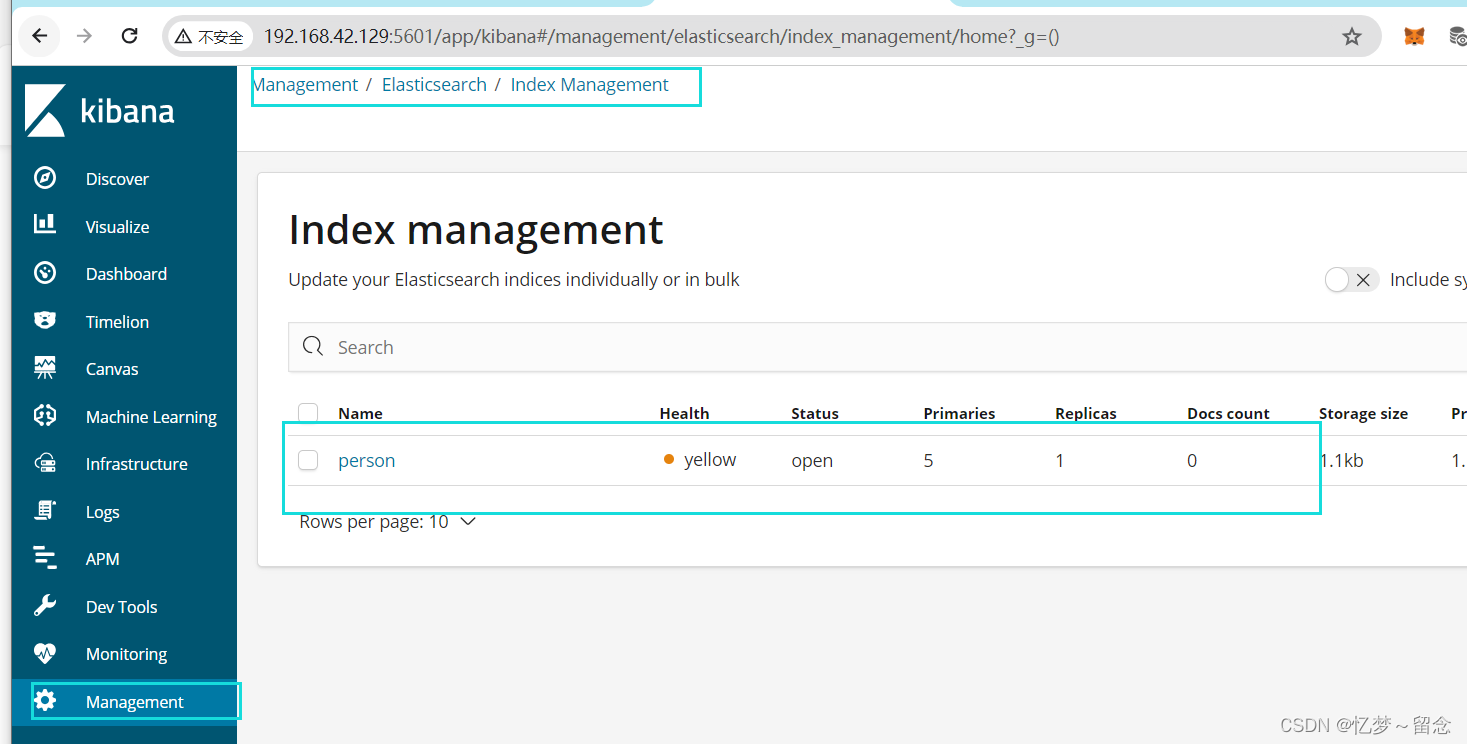
# 查看索引信息
GET /person
# 删除索引
DELETE /person
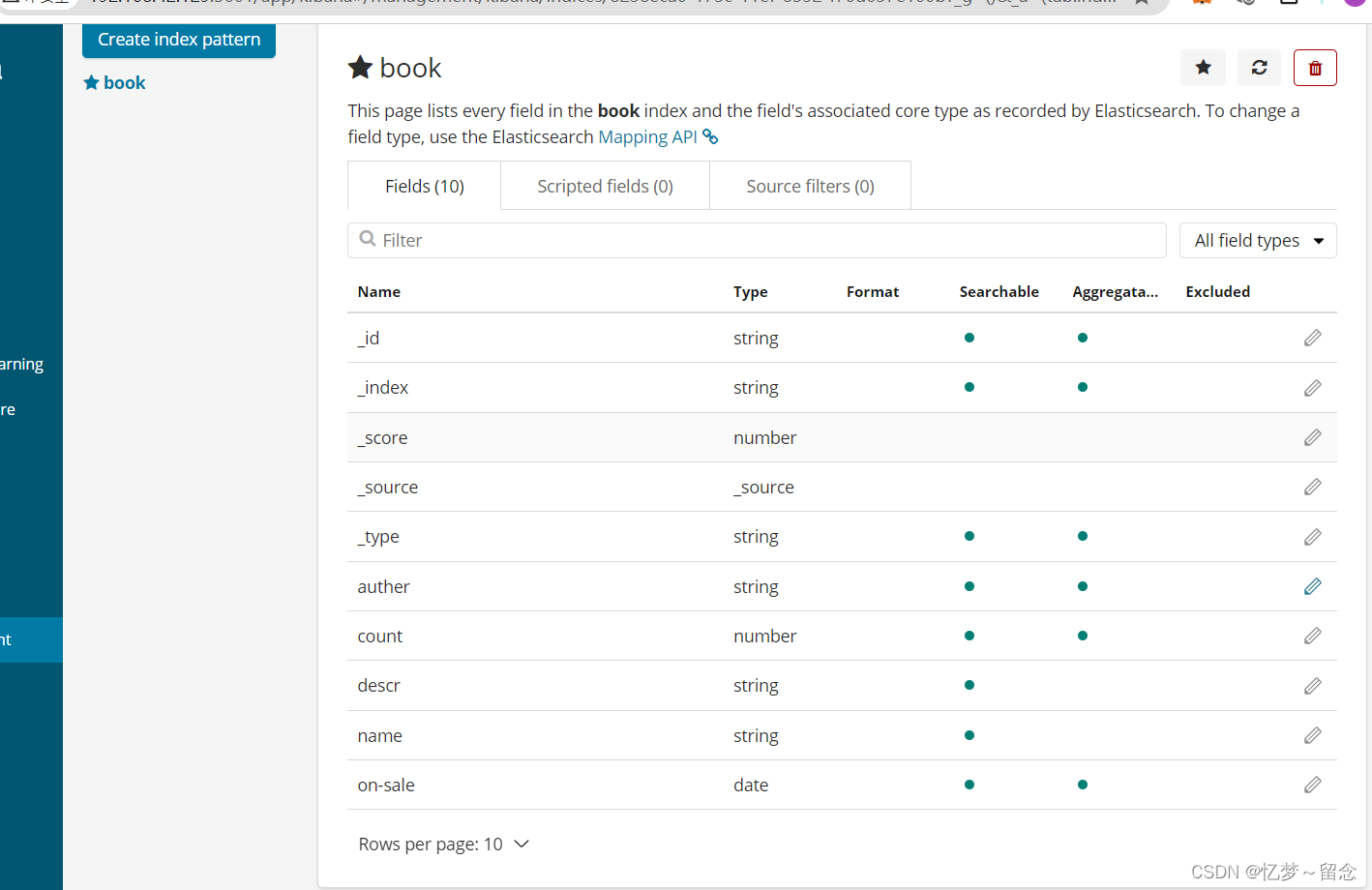
ES中Field可以指定的类型
字符串类型:
text:⼀般被⽤于全⽂检索。 将当前Field进⾏分词。
keyword:当前Field不会被分词。
数值类型:
long:取值范围
为-9223372036854774808~922337203685477480(-2的63次⽅到2的
63次⽅-1),占⽤8个字节
integer:取值范围为-2147483648~2147483647(-2的31次⽅到2的31
次⽅-1),占⽤4个字节
short:取值范围为-32768~32767(-2的15次⽅到2的15次⽅-1),占⽤2
个字节
byte:取值范围为-128~127(-2的7次⽅到2的7次⽅-1),占⽤1个字节
double:1.797693e+308~ 4.9000000e-324 (e+308表示是乘以10的
308次⽅,e-324表示乘以10的负324次⽅)占⽤8个字节
float:3.402823e+38 ~ 1.401298e-45(e+38表示是乘以10的38次⽅,
e-45表示乘以10的负45次⽅),占⽤4个字节
half_float:精度⽐float⼩⼀半。
scaled_float:根据⼀个long和scaled来表达⼀个浮点型,long-345,
scaled-100 -> 3.45
时间类型:
date类型,针对时间类型指定具体的格式
布尔类型:
boolean类型,表达true和false
# 删除索引
DELETE /person
⼆进制类型:
binary类型暂时⽀持Base64 encode string
范围类型:
long_range:赋值时,⽆需指定具体的内容,只需要存储⼀个范围即
可,指定gt,lt,gte,lte
integer_range:同上
double_range:同上
float_range:同上
date_range:同上
ip_range:同上
经纬度类型:
geo_point:⽤来存储经纬度的
ip类型:
ip:可以存储IPV4或者IPV6
常⽤需要记住的内容如下 :
字符串类型:
keyword
:不能被分词
text
:可以被分词
数值类型:
整形:
byte
,
short
,
integer
,
long
浮点型:
float
,
double
时间类型:
date
:可以给
date
类型指定
format
格式化,⽀持时间戳以及年⽉⽇等格式
IP
类型:
存储
ip
GEO_POINT
类型:
存储经纬度
Ps
官⽹⽂档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/ma
pping-types.html
kibana操作es
创建索引并指定数据结构
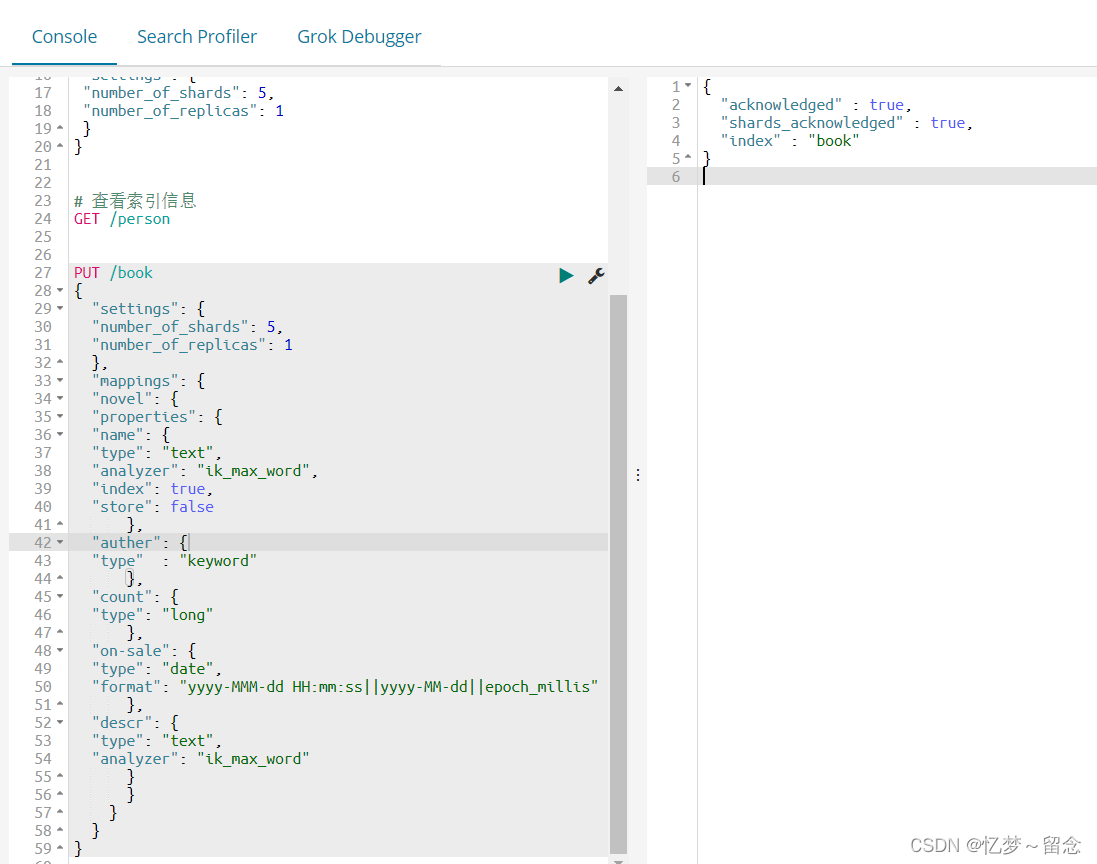
PUT /book
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings" : {
"novel" : {
"properties": {
"name" : {
"type" : "text",
"analyzer" : "ik_max_word",
"index" : true,
"store" : false
},
"auther": {
"type": "keyword"
},
"count": {
"type": "long"
},
"on-sale": {
"type" : "date",
"format" : "yyyy-MMM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"descr": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
# 创建索引,指定数据结构
PUT /book
{
"settings": {
# 分⽚数
"number_of_shards": 5,
# 备份数
"number_of_replicas": 1
},
# 指定数据结构
"mappings": {
# 类型 Type, 我们是7.x版本, 所以没有这个novel, 直接写下⾯
properties数据就可以。
"novel": {
# ⽂档存储的Field
"properties": {
# Field属性名
"name": {
# 类型
"type": "text",
# 指定分词器
"analyzer": "ik_max_word",
# 指定当前Field可以被作为查询的条件
"index": true ,
# 是否需要额外存储
"store": false
},
"auth": {
"type": "keyword"
},
"count": {
"type": "long"
},
"createtime": {
"type": "date",
# 时间类型的格式化⽅式
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MMdd||epoch_millis"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
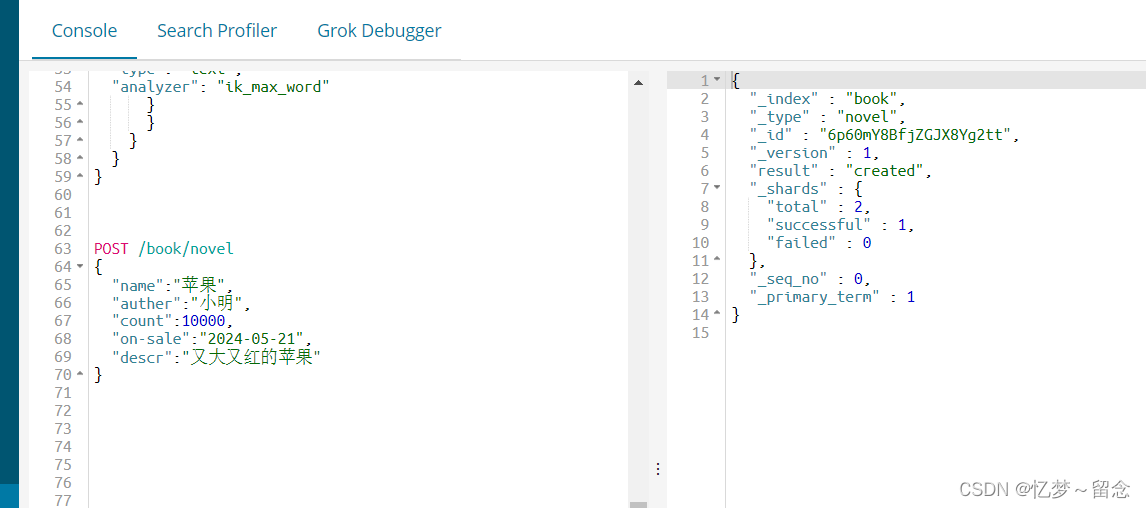
}自动生成id
POST /book/novel
{
"name":"苹果",
"auther":"小明",
"count":10000,
"on-sale":"2024-05-21",
"descr":"又大又红的苹果"
}
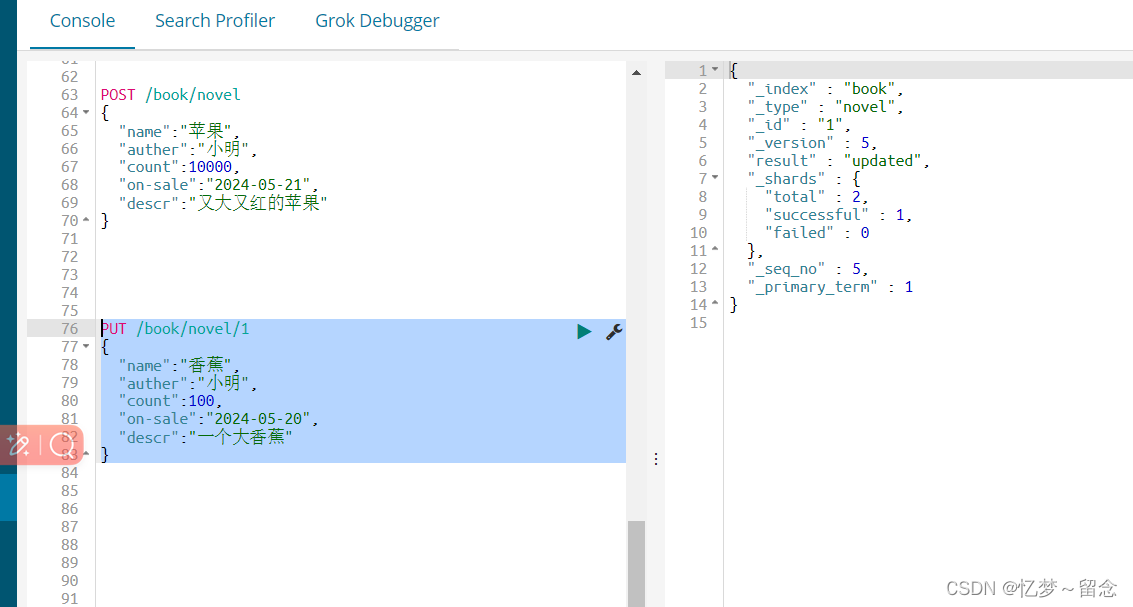
手动生成id
PUT /book/novel/1
{
"name":"香蕉",
"auther":"小明",
"count":100,
"on-sale":"2024-05-20",
"descr":"一个大香蕉"
}
修改文档
覆盖式修改
POST /book/novel/1
{
"name":"香蕉",
"auther":"小王",
"count":10000,
"on-sale":"2024-05-20",
"descr":"一个大香蕉"
}doc修改方式
POST /book/novel/1/_update
{
"doc":{
"descr":"香蕉并不大"
}
}
查看内容

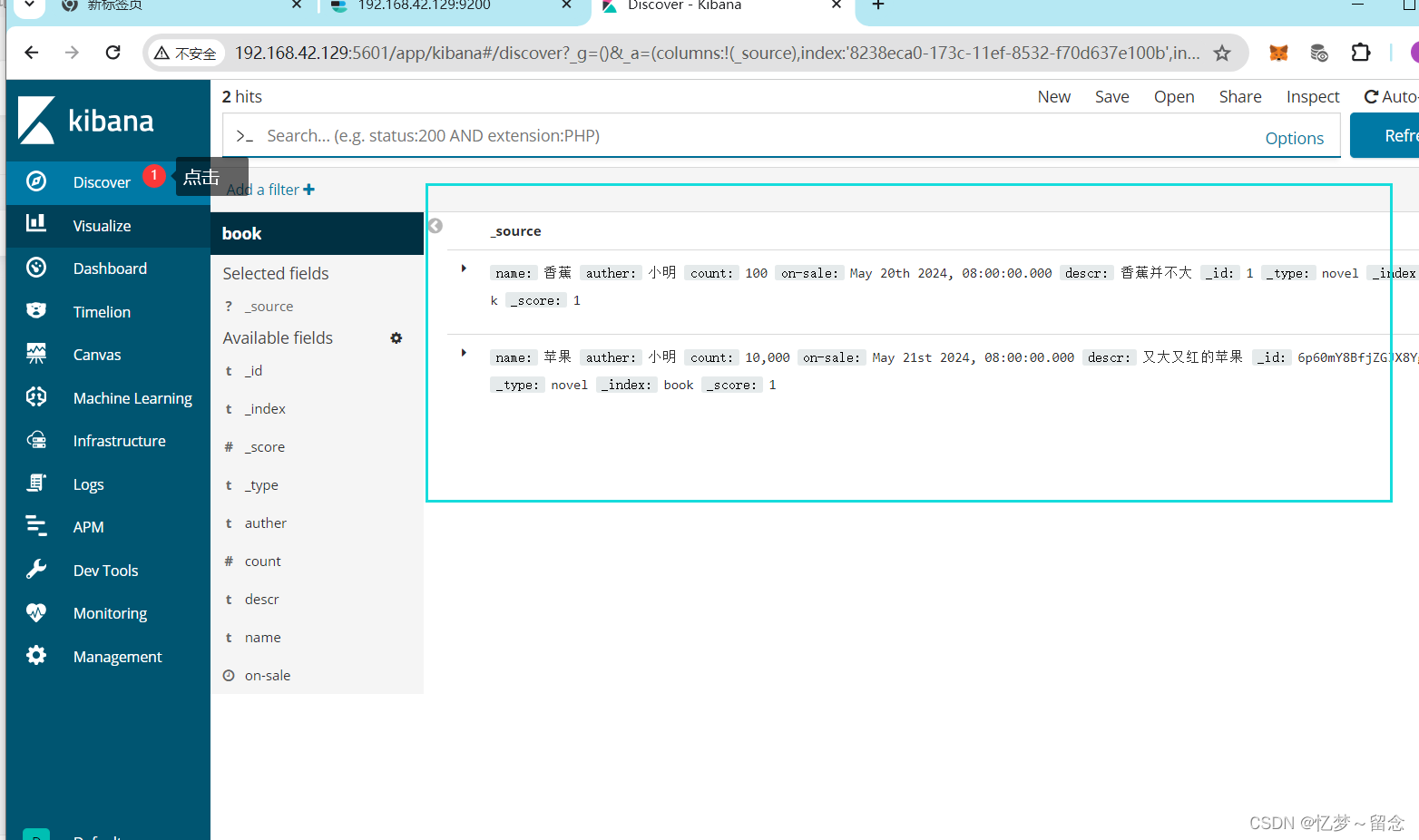
根据id删除
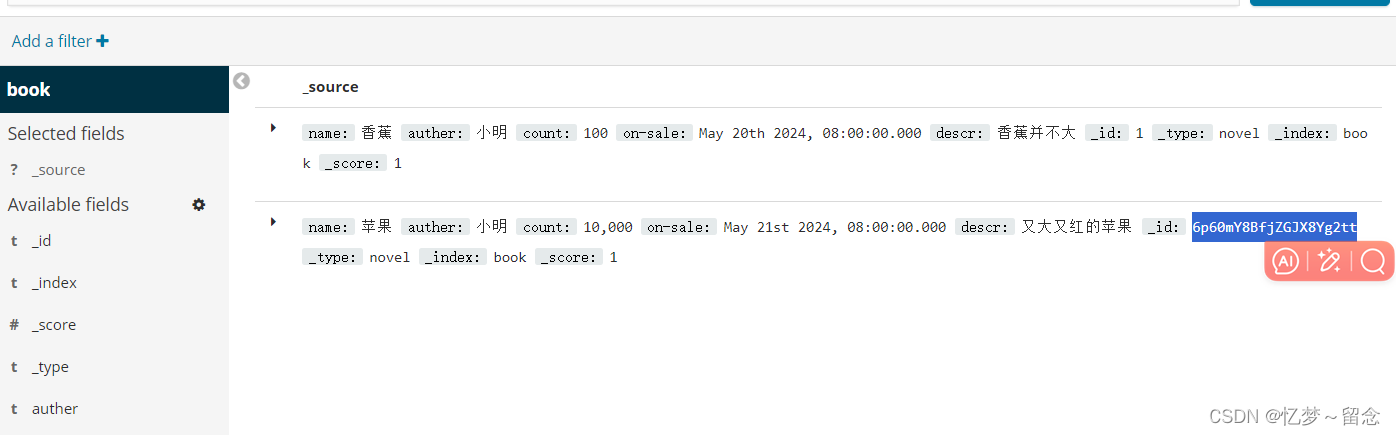
# 根据id删除⽂档
DELETE /book/novel/6p60mY8BfjZGJX8Yg2tt 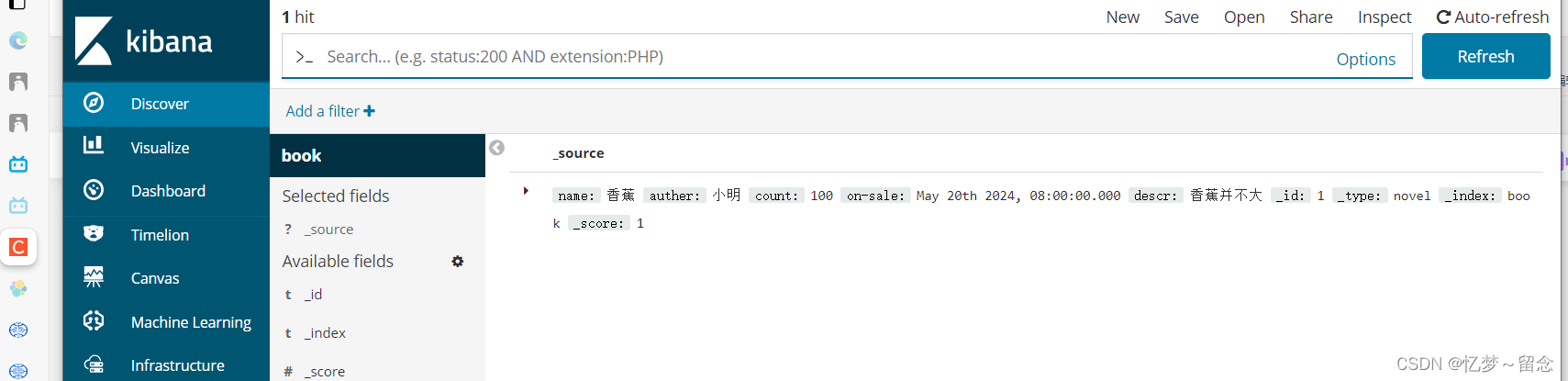
java操作索引
创建maven工程

导入依赖
<!--elasticsearch-->
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.5.4</version>
</dependency>
<!--elasticsearch高级api-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.5.4</version>
</dependency>
<!--unit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.22</version>
</dependency>创建连接客户端
public class ESClient {
public static RestHighLevelClient getClient() {
// 创建httpHost对象
HttpHost http = new HttpHost("192.168.42.129", 9200, "http");
// 创建RestClientBuilder
RestClientBuilder clientBuilder = RestClient.builder(http);
// 创建ES客户端 RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(clientBuilder);
ret 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









