







字典
是一种存储键值树的结构。
键值树:把键(key)和值(value)进行一个一对一的映射,然后就可以根据键快速的找到值。
例:每个学生都有自己的学号,知道学号就可以确定这个同学,此处的学号就是“键”,这个同学就是“值”。
字典的任何操作都是针对key进行的。
创建字典
创建一个空的字典,使用()表示字典。
a = { }
b = dict()
print(type(a))
print(type(b))
也可以在创建的同时指定初始值。
键值对之间使用,分割最后一个逗号间隔可有可无,键和值之间用:分割。(冒号后推荐加一个空格),要求键不可重复。
使用print 来打印字典内容。
student = {'id':20704,'name':"zhangsan"}
print(student)查找key
使用 in 或者not in可以判断key是否在字典中存在,返回布尔值。
a = {
1: 3,
4: 76,
56: 90
}
print(56 in a) #True
print("student" in a) #False使用[ ] 通过类似于取下标的方式获取到元素的值,只不过此处的下标为key(可能是整数,也可能是字符串等其他类型)。
a = {
"name":"wangtignting",
"year": 2001,
"sex": "nan"
}
print(a["sex"]) #nan
print(a["name"]) #wangtignting如果key在字典中不存在,则会抛出异常。

对于字典来说,使用 in 或者[ ] 来获取value,都是比较高效的操作。
对于列表来说,使用 in 比较低效的,而使用 [ ]是比较高效的。
字典的新增、修改元素
使用 [ ]可以根据key 来新增/修改value。
如果key不存在,对取下标操作赋值,即为新增键值对。
student = {
"id" : 11,
"name": "zhangsan",
}
student["score"] = 90
print(student)
#运行结果为:{'id': 11, 'name': 'zhangsan', 'score': 90}如果key值已经存在,对取下标操作赋值,即为修改键值对的值。
student = {
"id" : 11,
"name": "zhangsan",
"score": 80,
}
student["score"] = 90 #修改键值对的值
print(student)
#运行结果为:{'id': 11, 'name': 'zhangsan', 'score': 90}删除元素
使用pop 方法根据key删除对应的键值对。
a = {
"name": "zhangsan",
"id": 34,
"sex": "nan"
}
print(a)
a.pop("id")
print(a)
#运行结果:{'name': 'zhangsan', 'id': 34, 'sex': 'nan'}
#{'name': 'zhangsan', 'sex': 'nan'}字典的遍历
字典是哈希表,进行增删改查(常数级)操作都是高效的,遍历效率较差
a = {
'id':1,
'name':'zhangsan',
'score':90
}
for key in a:
print(key,a[key])
for key,values in a.items():
print(key,values)
在c++或Java中,哈希表里面的键值对存储的顺序是无序的。
在python中,能够保证遍历出来的顺序和插入顺序一致。
keys 获取到字典中的所有的key;values 获取到字典中的所有 value;items 获取到字典中的所有键值对。得到的结果首先是一个列表一样的结构,里面每个元素又是一个元组,元组里面包含了键和值。
a = {
'id':1,
'name':'zhangsan',
'score':90
}
print(a.keys())
print(a.values())
print(a.items() ) 
合法分key类型
不是所有的类型都可以作为字典的key,字典本质上是一个哈希表,哈希表的key要求是”可哈希的“,也就是可以计算出一个哈希值。可以使用 hash 函数计算某个对象的哈希值,但凡能够计算出哈希值的类型,都可以作为字典的key。
列表和字典是不可哈希的,无法计算出其哈希值,而整数、浮点数、字符串、元组都是可哈希的。
不可变的对象,一般就是可哈希的。可变的对象,一般就是不可哈希的。
print(hash(2))
print(hash(3.14))
print(hash("hello"))

文件
打开文件
用open 打开文件,第一个参数为文件路劲,第二个参数为查看方式。当文件不存在的时候尝试按照读方式打开,就抛出了文件没找到异常。
open 的返回值是一个文件对象,文件的内容是在硬盘上的,此处的文件对象则是内存上的一个变量,后续读写文件操作,,都是拿着这个文件对象来进行操作的,此处的文件对象就像一个“遥控器”,通过这个“遥控器”来控制硬盘。
计算机中,把这种远程操控的“遥控器”称为“句柄”(handler)。
#使用 open 打开一个文件
f = open('D:/代码学习/python学习/python/wenjian/test.txt','r')
print(f)
print(type(f))
关闭文件
使用close 关闭文件。文件在打开后,使用结束后一定要关闭。打开文件是在申请一定的系统资源,不再使用文件的时候,资源就应该及时释放,否则就可能造成文件资源泄露,进一步导致其他部分的代码无法顺利打开文件。
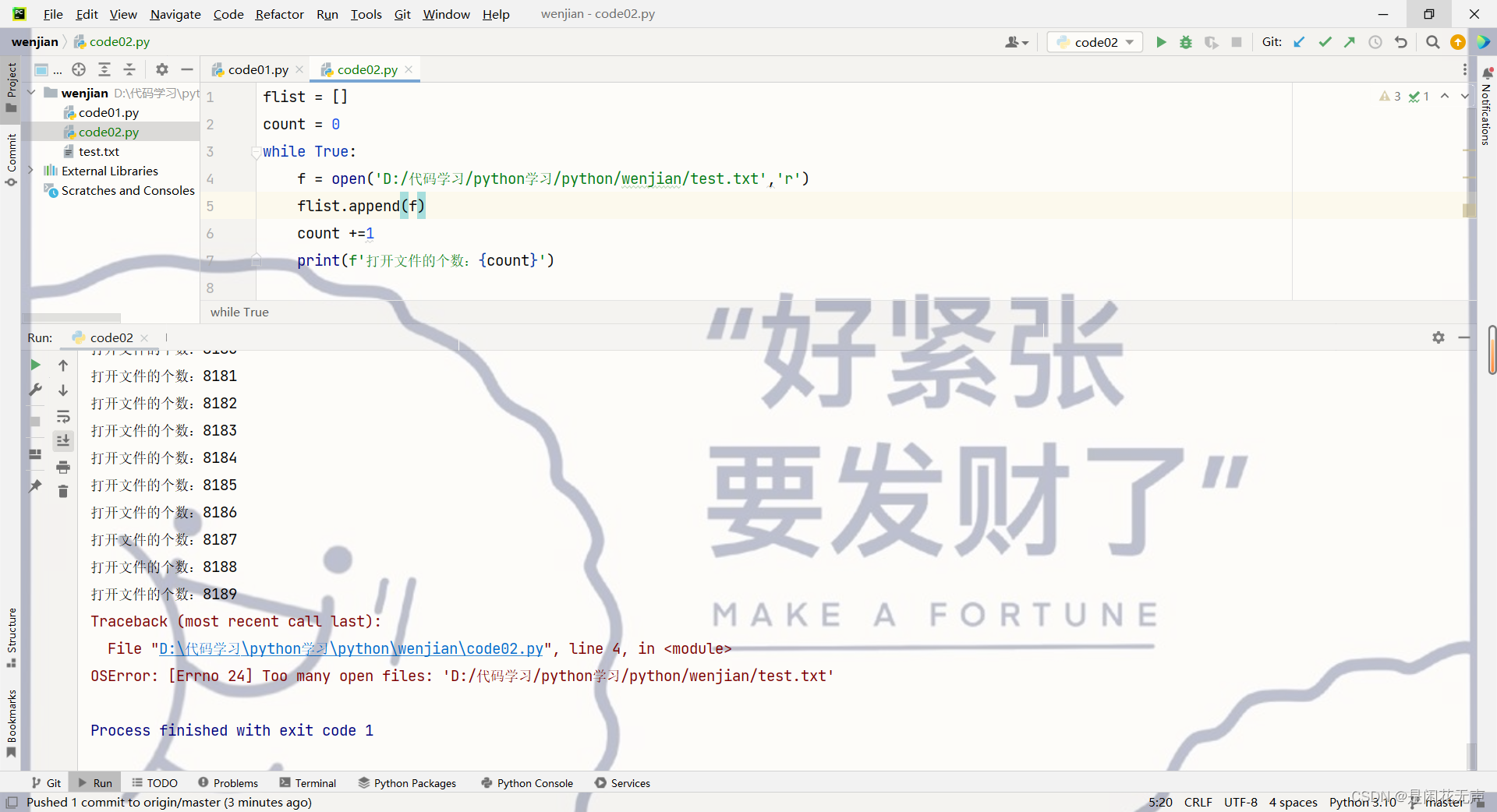
写文件
文件打开后就可以写文件了。写文件要使用写方式打开,open第二个参数设为”w“,使用write方法写入文件。使用‘r’方式写文件会报错。
f = open('D:/代码学习/python学习/python/wenjian/test.txt', 'w')
f.write('hello')
f.close()
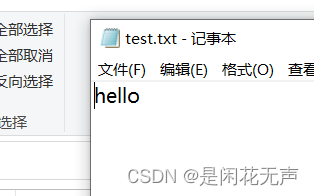
使用’w'一旦打开文件成功,就会清空文件原有的数据。使用‘a'实现”追加写“,此时原有内容不变,写入的内容会存在于之前文件内容的末尾。
f = open('D:/代码学习/python学习/python/wenjian/test.txt', 'w')
f.write('hello')#加上\n可以换行
f.close()
f = open('D:/代码学习/python学习/python/wenjian/test.txt', 'a')
f.write('word')
f.close()
读文件
①、读文件内容需要使用”r“的方式打开文件,使用read方法完成读操作,参数表示”读取几个字符“
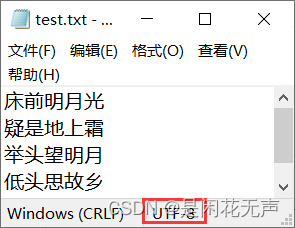
文档中是按照UTF8编码的格式,所以在代码操作读取文件中也要使用UTF8的编码格式,而编译器中默认使用GBK,在打开文件的时候加上参数指定编码格式与文档编码格式一致即可。
f = open('D:/代码学习/python学习/python/wenjian/test.txt', 'r',encoding = 'utf8')
result = f.read(2)
print(result)
f.close()
②、更常见的读操作是按行读取,最简单方法直接用for循环。
f = open('D:/代码学习/python学习/python/wenjian/test.txt', 'r',encoding='utf8')
for line in f:
print(f'line={line}')
f.close()

上述代码执行结果,会在每一行末尾存在两个空行,一个是因为文件读到的文件内容(此行末尾就带有\n),此处使用print来打印,又会自动加上一个换行符。
解决空行的方法:可以给print再多设定一个参数,修改print自动添加换行行为。
print(f'line={line}',end = ' ')
此处所加的end通常表示在每次打印的末尾添加的东西,默认是\n,修改为空字符串后就显示未添加任何其他符号,依旧为按行读取。
③、可以使用readlines方法,直接把整个文件所有内容全部都读出来,按照行组织到一个列表里。相较于前面方法而言,更为高效。一次读完。
f = open('D:/代码学习/python学习/python/wenjian/test.txt', 'r',encoding='utf8')
lines=f.readlines()
print(lines)
f.close()
上下文管理器
为了防止写代码时打开文件后忘记关闭。当with对应的代码块执行结束,就会自动执行f的close。
def func():
with open('D:/代码学习/python学习/python/wenjian/test.txt', 'r',encoding='utf8') as f :
lines = f.readlines()
print(lines)















 2481
2481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









