







目录
案例一、计算平均值案例
计算生产车间每天早中晚三个时间点三台机器的平均值
l z(早) w(中) y(晚) L_1 393 430 276 L_2 388 560 333 L_3 450 600 321 期望结果 L_1 **** L_2 **** L_3 ****
package CountAvg;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* l z w y
* L_1 393 430 276
* L_2 388 560 333
* L_3 450 600 321
*/
public class AvgDemo {
public static class MyMapper extends Mapper<LongWritable, Text, Text, FloatWritable> {
public static Text k = new Text();
public static FloatWritable v = new FloatWritable();
//map执行之前执行一次
@Override
protected void setup(Mapper<LongWritable, Text, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
context.write(new Text("生产线 生产线平均值"), new FloatWritable());
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
//获取每一个文件中的每一行的数据
String line = value.toString();
//对每一行数据进行切分
String[] words = line.split("\t");
//按照业务处理
String lineName = words[0];
int z = Integer.parseInt(words[1]);
int w = Integer.parseInt(words[2]);
int y = Integer.parseInt(words[3]);
k.set(lineName);
float avg = (float) (z + w + y) / (words.length - 1);
v.set(avg);
context.write(k, v);
}
//整个map执行之后执行一次
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}
public static class MyReducer extends Reducer<Text, FloatWritable, Text, FloatWritable> {
@Override
protected void setup(Reducer<Text, FloatWritable, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
context.write(new Text("生产线 生产线平均值"),new FloatWritable());
}
@Override
protected void reduce(Text key, Iterable<FloatWritable> values, Reducer<Text, FloatWritable, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
context.write(key, new FloatWritable(values.iterator().next().get()));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//配置对象信息
Configuration conf = new Configuration();
//获取job对象
Job job = Job.getInstance(conf, "AvgDemo");
//设置job运行主类
job.setJarByClass(AvgDemo.class);
//对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
//对reduce阶段进行设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交并退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
案例二:倒排索引
数据:
1.html :
hadoop hadoop hadoop is better
2.html:
hadoop hbase hbase hbase is nice
3 .html:
hadoop hbase spark spark spark is better
输出结果:
hadoop 1.html:3;2.html:1;3.html:1
is 1.html:1;2.html:1;3.html:1
hbase 2.html:2;3.html:1
better 1.html:1;3.html:1
nice 2.html:1
spark 3.html:3
CountAvg.DescIndexDemo
package CountAvg;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* l z w y
* L_1 393 430 276
* L_2 388 560 333
* L_3 450 600 321
*/
/****
* 倒排索引
*/
public class DescIndexDemo {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
//获取文件名字
InputSplit inputSplit = context.getInputSplit();
String fileName = ((FileSplit) inputSplit).getPath().getName();
//获取每一个文件中的每一行的数据
String line = value.toString();
//对每一行数据进行切分
String[] words = line.split(" ");
for (String s :
words) {
context.write(new Text(s + "_" + fileName), new Text(1 + ""));
}
}
//整个map执行之后执行一次
}
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String str = "";
for (Text t :
values) {
str += t.toString() + ";";
}
context.write(key, new Text(str.substring(0, str.length() - 1)));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//配置对象信息
Configuration conf = new Configuration();
//获取job对象
Job job = Job.getInstance(conf, "DescIndexDemo");
//设置job运行主类
job.setJarByClass(DescIndexDemo.class);
//对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
//设置Combiner
job.setCombinerClass(MyCombiner.class);
//对reduce阶段进行设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交并退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}CountAvg.MyCombiner
package CountAvg;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyCombiner extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String str [] = key.toString().split("_");
int counter = 0;
for (Text t :
values) {
counter += Integer.parseInt(t.toString());
}
context.write(new Text(str[0]),new Text(str[1]+":"+counter));
}
}
ieda打包jar方法都是相同的都是相同的
首先点击File-->Project Structure
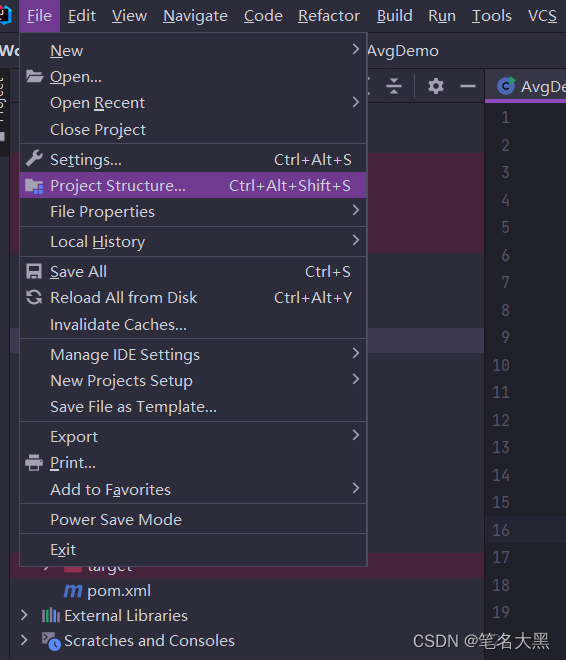
然后点击Artifacts 点击+号
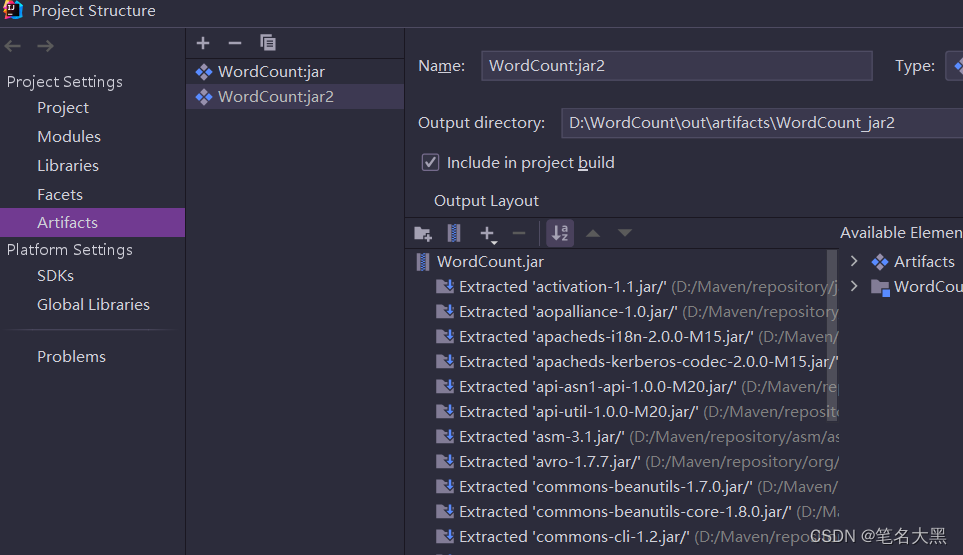
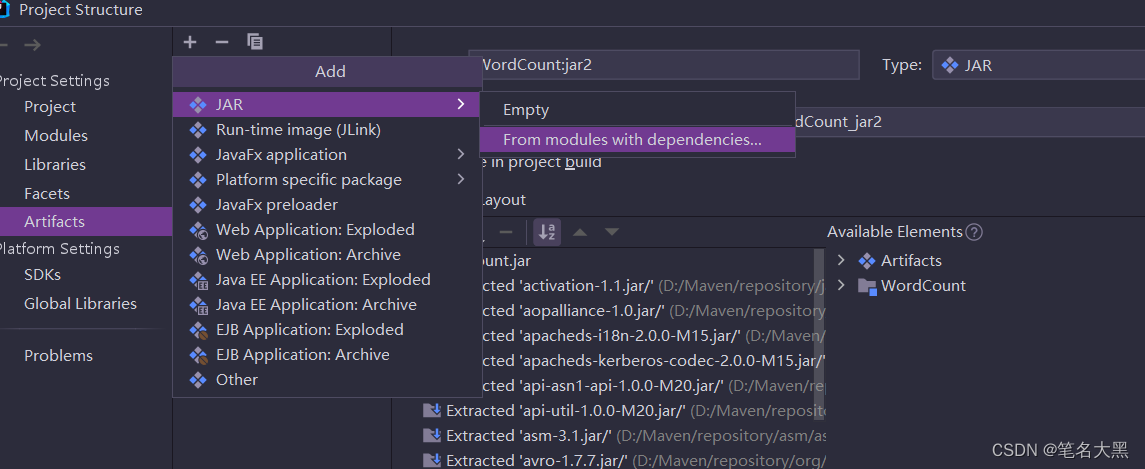
选择要打成jar包的运行的主类
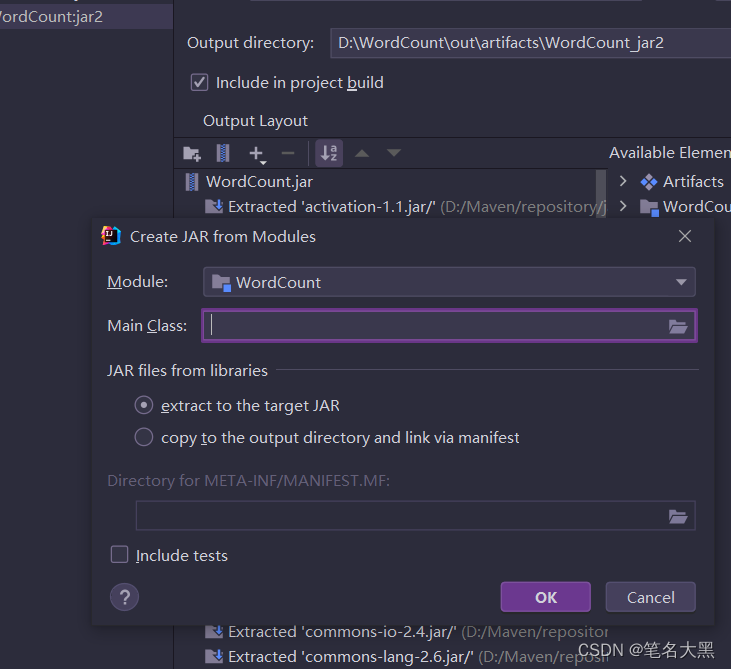
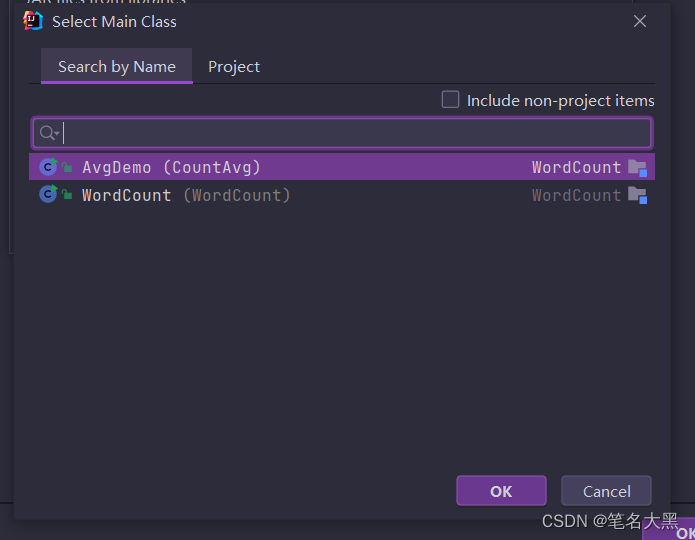
点击ok
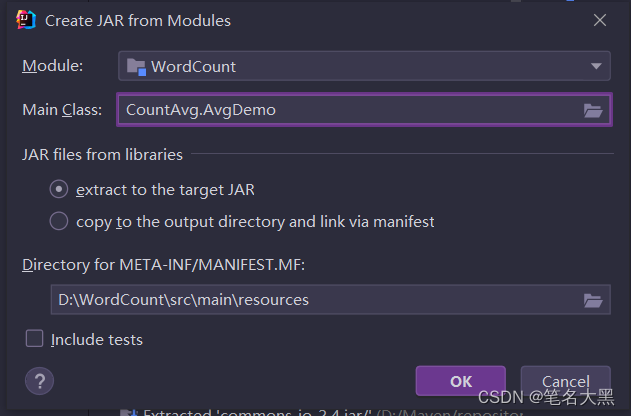
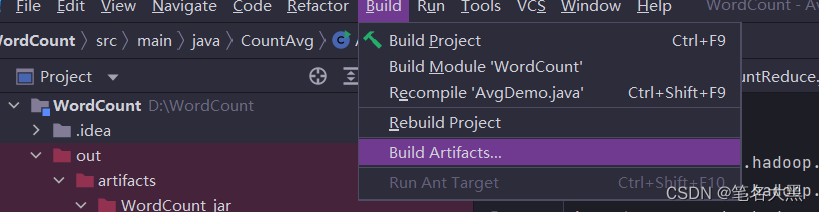
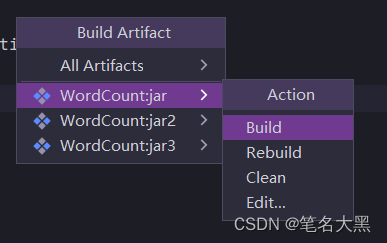
选择build即可
然后右击out->artifacts-WordCount_jar
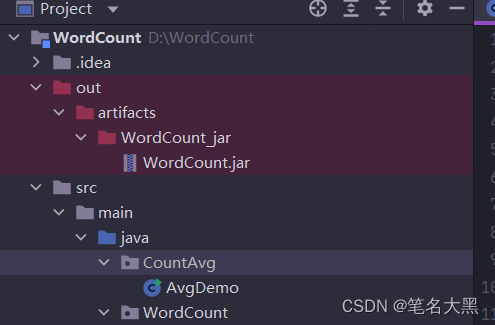
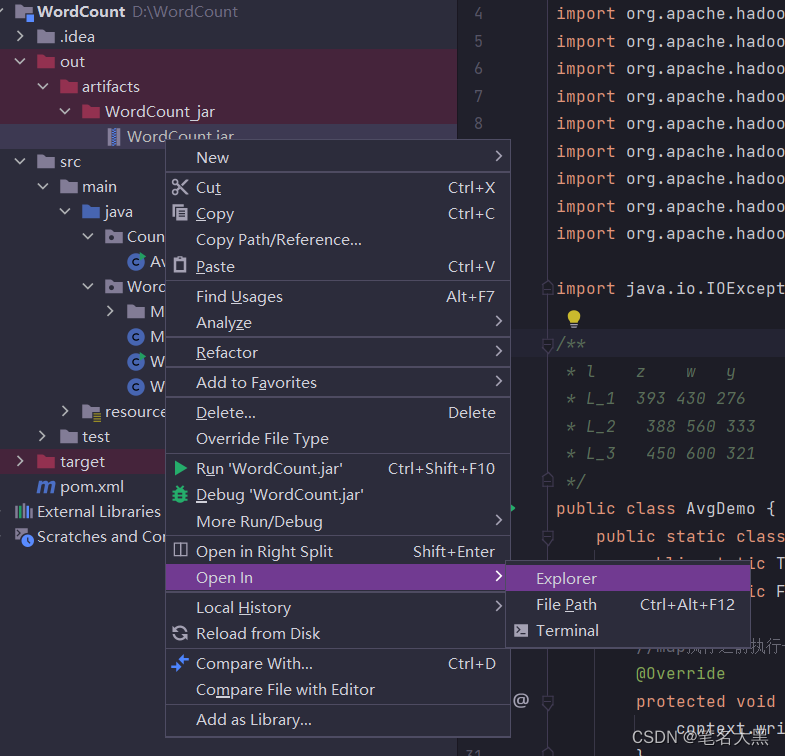
导出jar包所在的目录
利用WinScp远程拷贝到hadoop集群目录下
hadoop命令操作jar包
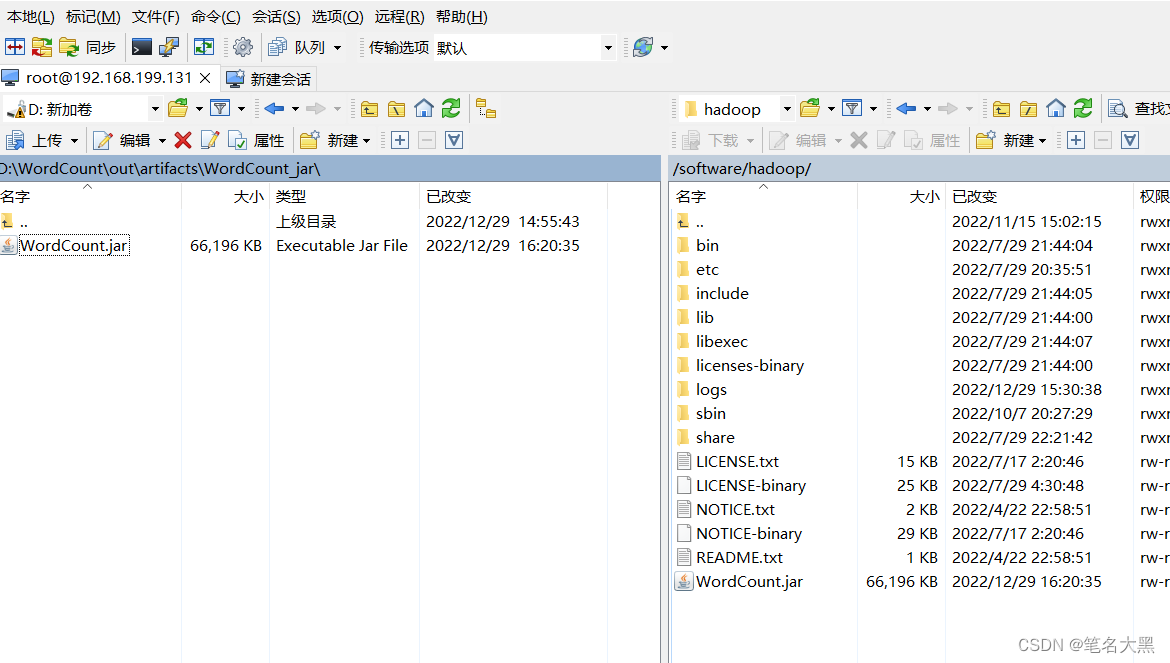
在home目录下创建avg文件
并把数据拷贝到avg中
![]()
利用hdfs dfs -put /home/avg /avg
源文件 目标文件
![]()
启动jar文件执行mapreduce操作
yarn jar xxx.jar 目标文件路径 输出文件路径 (命令)
yarn jar WordCount.jar /avg /out/04 (jar包输入首字母按Tab自动补全)
![]()
hdfs dfs -cat xxx 查看命令
注:输出文件默认文part-r-00000 如果存在则自动加1
例如:part-r-00001
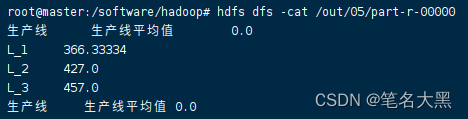
完结撒花
















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









