






标题目录
数据类型
数字类型
INT 型
- INT 是一种整数类型,用于存储整数值
- INT 类型可以存储有符号的整数值范围为 -2147483648 到 2147483647
- 有符号的整数类型,占据4个字节(32位)的存储空间
- 无符号的整数范围为 0 到 4294967295
- INT UNSIGNED:无符号的整数类型,也占据4个字节(32位)的存储空间
- INT(m)
- m 为一个整数,表示数字宽度(位数)
- 不指定 m 时,默认宽度为11
- INT UNSIGNED 默认长度为10
创建一个表
CREATE TABLE person1(
id INT,
age INT UNSIGNED -- 无符号
);
- 插入小数时只能保存整数部分,小数部分舍弃时会进行四舍五入
INSERT INTO person1(id) VALUES(3.6); -- 4
INSERT INTO person1(age) VALUES(2.1); -- 2
- 不能向无符号数字的字段插入负数
INSERT INTO person1(id) VALUES(-1);
INSERT INTO person1(age) VALUES(-1); -- 报错
BIGINT 型
- BIGINT 是整数类型,用于存储较大范围的整数值
- BIGINT 类型可以存储有符号的整数值范围为 -9223372036854775808 到 9223372036854775807
- 占据8字节(64位)的存储空间
- BIGINT UNSIGNER 是无符号的整数类型
DOUBLE 类型
- FLOAT 和 DOUBLE 都是浮点类型
- FLOAT 占4个字节,数字宽度最大24位
- FOUBLE 占8个字节,数字宽度最大53位
- 指定长度:FLOAT(m,n)或DOUBLE(m,n)
- m 表示宽度,数字位数,最大24位,超过时自动转换为DOUBLE类型
- n 表示精度,小数点后的位数
- m 包含 n,即 DOUBLE(5,2) 表示一共5位数字,其中2位是小数(整数3位)
创建一个表
CREATE TABLE person2(
age INT(3), -- 最大值999
salary DOUBLE(7,2) -- 最大值99999.99
);
- 精度超过范围时会进行四舍五入,四舍五入后若超过数字宽度会报错
INSERT INTO person2(salary) VALUES(99999.99);
INSERT INTO person2(salary) VALUES(999999); -- 超出范围,报错
INSERT INTO person2(salary) VALUES(1234.567); -- 1234.57
INSERT INTO person2(salary) VALUES(12345.678); -- 12345.68
INSERT INTO person2(salary) VALUES(123456.789); -- 超出范围,报错
INSERT INTO person2(salary) VALUES(99999.997); -- 由于四舍五入导致超出范围,报错
字符类型
定长字符串
- CHAR 类型
- CHAR 类型是一种固定长度的字符串类型
- 存储从0到255个字符(默认为1个字符)
- 如果存储的字符串长度小于指定长度,会自动在末尾填充空格字符
- 如果字符串长度大于指定长度,会进行截断处理
- 优点:在磁盘上开辟的空间是确定的,固定长度带来了更好的检索性能
- 缺点:浪费磁盘空间
- CHAR(m)
- m 表示字符长度
- TEXT 类型
- TEXT 类型是一种定长字符串类型
- TEXT 无需指定长度,最高可保存64KB的字符数据
- MEDIUMTEXT 可以达到16MB
- LONGTEXT 可以达到4GB
变长字符串
- VARCHAR 类型是变长字符串,实际占用磁盘空间的大小由数据决定
- VARCHAR(m),m 是一个数字,表示字符长度,最大值为65535
- 实际占用磁盘空间由数据决定
- 例如:VARCHAR(50)
- name 字段保存的字符最多占用50个字符
- 如果 name 保存字符串 ’ 张三 ’ , ’ 张三 ’ 在UTF-8编码中占6个字节,该字段值实际在磁盘上就占6个字节
- 例如:VARCHAR(50)
- 优点:磁盘空间没有浪费
- 缺点:每条记录该字段长度不一致,会导致查询性能差一些
日期类型
- DATE:可以保存年,月,日
- TIME:可以保存时,分,秒
- DATETIME:可以保存年月日时分秒
- TIMESTAMP:时间戳,保存UTC时间,可以精确到毫秒
创建一张表
CREATE TABLE userinfo(
id INT,
name VARCHAR(36),
gender CHAR(1),
birth DATETIME,
salary DOUBLE(7,2)
)
- 插入日期类型时,DATETIME类型字段为例:
可以以字符串形式插入,该字符串格式为:’ yy-MM-dd hh:mm:ss ’
INSERT INTO userinfo(id,name,gender,birth,salary) VALUES(1,'张三','男','1992-08-02 20:55:33',5000.19)
- DATETIME 类型插入数据时,可以忽略时分秒,忽略后默认值为00:00:00
INSERT INTO userinfo(id,name,gender,birth,salary) VALUES(2,'李四','女','1997-05-16',7000)
- 不可以忽略年月日
# 忽略年月日会报错
INSERT INTO userinfo(id,name,gender,birth,salary) VALUES(3,'王五','男','13:24:57',8000)
约束
- 数据库约束是用于限制数据库表中数据的一组规则或条件
- 它们定义了某些列或表中数据的完整性、准确性和一致性要求,以确保数据库中的数据符合预期的规范
数据库约束分类
- 主键约束
- 非空约束
- 唯一性约束
- 检查约束
- 外键约束(不常用)
主键约束
- PRIMARY KEY
- 主键约束要求该字段的值用来唯一表示该表中的一条记录
- 可以作为主键的值的要求:非空且唯一
- 非空:在表中每条记录都要有该值
- 唯一:表中每条记录该字段的值不可以重复
- 一张表中只能有一个字段为主键约束,通常主键字段的字段名为 " ID "
创建一张表,并为id字段添加主键约束
CREATE TABLE user1(
id INT PRIMARY KEY,
name VARCHAR(30),
age INT(3)
);
INSERT INTO user1(id,name,age) VALUES(1,'张三',22),(2,'李四',33);
- 主键字段不可以插入重复的值
INSERT INTO user1(id,name,age) VALUES(1,'王五',22); -- 报错
- 主键字段不可以插入NULL值
INSERT INTO user1(id,name,age) VALUES(NULL,'王五',22); -- 报错
- 插入记录时不可以忽略主键字段,除非主键字段有默认的生成方式(比如自增)
INSERT INTO user1(name,age) VALUES('王五',22); -- 报错
- 更新数据也不能违反约束要求
UPDATE user1 SET id=1 WHERE name='李四'; -- 报错
自增
- 主键字段的值不会进行更新,通常插入数据时应由系统生成
- 最常见的方式就是使用自增:AUTO_INCREMENT
- 由于自动生成唯一递增整数值的特性,它通常用于定义表的主键列,以确保每次插入新行时,都会自动为该列生成一个唯一的递增值
将id列定义为主键,并且使用AUTO_INCREMENT关键字,在每次插入新行时,会自动为id列分配一个唯一的递增值
CREATE TABLE user2(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30),
age INT(3)
)
- 修改表时,也可以为字段添加自增
ALTER TABLE user1 CHANGE id id INT AUTO_INCREMENT;
- 由于主键具有自增,因此我们插入数据时可以忽略ID字段
INSERT INTO user2(name,age) VALUES('张三',22),('李四',33);
- 插入时,可以显式的插入NULL,此时还是会使用自增,并非将NULL值插入
INSERT INTO user2(id,name,age)VALUES(NULL,'王五',44);
虽然可以这样写,但是不推荐这样的写法,会出现语义不明确的问题(id会自增为3)
非空约束
- NUT NULL:非空约束
- 当字段施加非空约束后,字段的值任何时候都不允许为NULL
- 插入数据时不可以将NULL值插入到该字段上
- 更新数据时也不可以将数据更新为NULL值
- 一张表中可以有多个字段添加非空约束
创建表时为字段指定非空约束
CREATE TABLE user3(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30) NOT NULL,
age INT(3)
)
- 修改表时也可以为字段添加非空约束
ALTER TABLE user2 CHANGE name name VARCHAR(30) NOT NULL
- 插入数据和更新数据时,不能将NULL存入具有非空约束的字段中
INSERT INTO user3(name,age) VALUES(NULL,22); -- 报错
- 插入数据时也不可以忽略具有非空约束的字段
INSERT INTO user3(age) VALUES(22); -- 报错
唯一性约束
- UNIQUE 唯一性约束
- 约束要求对应字段在整张表中的值是不可以重复的
创建一张表,为字段添加唯一性约束
CREATE TABLE user4(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30) UNIQUE,
age INT
)
- 修改表时可以为字段添加唯一性约束
- 注意:如果该字段具有非空约束,若仅修改为唯一性约束时,会将非空约束取消
ALTER TABLE user3 CHANGE name name VARCHAR(30) UNIQUE; -- 会取消掉非空约束仅保留唯一性约束
ALTER TABLE user3 CHANGE name name VARCHAR(30) NOT NULL UNIQUE; -- 同时具有非空约束和唯一性约束
- 插入数据时不能将重复的值插入到具有唯一性约束的字段上
INSERT INTO user4(name,age) VALUES('张三',22),('李四',33);
INSERT INTO user4(name,age) VALUES('张三',55); -- 报错
- NULL值可以插入到具有唯一性约束的字段上,并且多条记录都可以是NULL
INSERT INTO user4(name,age) VALUES(NULL,55);
INSERT INTO user4(name,age) VALUES(NULL,66);
- 更新数据也不能将重复的值更新到具有唯一性约束的字段上,NULL除外
UPDATE user4 SET name='张三' WHERE id=4; -- 报错
检查约束
- CHECK 约束,该约束允许我们自定义约束条件,此时仅允许满足该条件的操作进行
创建一张表时为字段添加CHECK约束
CREATE TABLE user5(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30),
age INT(3) CHECK(age>0 AND age<120)
)
- 插入数据时,值不能违背CHECK约束要求
INSERT INTO user5(name,age) VALUES('张三',22);
INSERT INTO user5(name,age) VALUES('李四',0); -- 报错
INSERT INTO user5(name,age) VALUES('王五',300); -- 报错
- 更新数据时也不能违背CHECK约束要求
UPDATE user5 SET age=130 WHERE id=1; -- 报错
外键约束
- 外键约束开发中不常用
- 后面再介绍(关联查询时介绍)
DQL 语言
- 数据查询语言(DQL):Data Query Language
- 用于从数据库中检索数据
- DQL 语言使用检索表中记录的语言
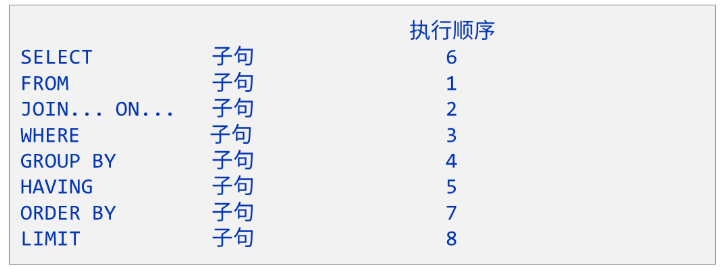
- 语法
- SELECT 字段1,字段2,… FROM 表1,表2,…
- SELECT * FROM 表1,表2,…
- SELECT 子句用于指明检索表中哪些字段
- FROM 子句用于指明数据来自哪些表
- 尽量避免使用“ SELECT * FROM 表 ”
- 库首先要查询内部的数据字典了解表中的字段情况后才可以进行查询工作
- 查询如果频繁进行则会降低查询效率
查看所有学生的名字,年龄,性别
SELECT name,age,gender,birth FROM student
WHERE 子句
- WHERE 子句用于添加过滤条件,在DQL语句中仅将满足过滤条件的记录查询出来
查看除了‘刘苍松’以外的所有老师的名字,工资,奖金,职位
SELECT name,salary,comm,title FROM teacher WHERE name<>'刘苍松'
查看年龄在30岁以上(含)的老师的名字,职称,工资,奖金
SELECT name,title,salary,comm,age FROM teacher WHERE age>30
连接多个条件
- 当WHERE 子句有多个过滤条件时,可以使用逻辑运算
- AND:" 与 ",都为真时才为真
- OR:" 或 ",都为假时才为假
查看7岁的“大队长”都有谁,列出这些学生的名字,年龄,性别和职位
SELECT name,age,gender,job FROM student where age=7 AND job='大队长'
查看所有一级讲师和三级讲师的名字,职称,工资
SELECT name,title,salary FROM teacher WHERE title='一级讲师' or title='三级讲师'
- AND 的优先级是高于 OR 的,若要提高 OR 的优先级,需要使用"()"括起来
查看班级编号在6(含)以下的所有大队长,中队长的名字,年龄,性别,职位
SELECT name,age,gender,job FROM student
WHERE class_id<=6 AND(job='大队长'OR job='中队长')
IN (列表)
IN (列表) 表示字段的值在列表之中
查看所有大队长,中队长,小队长的名字,性别,年龄和职位
SELECT name,age,gender,job FROM student
WHERE job IN('大队长','中队长','小队长')
NOT IN (列表)
NOT IN (列表) 表示字段值不在列表中,不能等于列表中任何一项
查看除一级讲师和二级讲师之外的所有老师的名字,职称,工资
SELECT name,title,salary FROM teacher
WHERE title NOT IN('一级讲师','二级讲师')
BETWEEN…AND…
- BETWEEN m AND n 用于判断字段值在两者区间
- 逻辑:>=m AND <=n,m 是下限,n 是上限
查看工资在2000到5000之间的老师的名字,性别,年龄,工资
SELECT name,gender,age,salary FROM teacher
WHERE salary BETWEEN 2000 AND 5000
DISTINCT
- DISTINCT用在SELECT子句中,并且需要紧跟在SELECT关键字之后
- 可以将结果集中指定字段重复的记录去除
查看老师都有哪些职称
SELECT DISTINCT title FROM teacher
多字段去重
- DISTINCT后面可以指定多个字段
- 去重规则:这几个字段的组合重复的将被去除
查看各年龄段的学生都有哪些职位
SELECT DISTINCT age,job FROM student
模糊查询
- 比较操作符LIKE用来做模糊查询
- 当用户在执行查询时,不能完全确定某些信息的查询条件,或者只知道信息的一部分你可以借助LIKE来实现
- LIKE需要借助两个通配符:
- %:表示0到多个字符
- _:表示单个字符
- 这两个通配符可以配合使用,构造灵活的匹配条件
示例:

查看名字中含有’晶’的老师都有谁
SELECT name FROM teacher WHERE name LIKE '%晶%'
查看姓张的学生都有谁
SELECT name FROM student WHERE name LIKE '张%'
NULL 值判断
- 在数据库中,所有字段默认值都是NULL
- NULL表示不存在,空的
- NULL不能算作一个值,应该是一种状态
- 判断字段值是否为空:
- IS NULL 字段的值是空的
- IS NOT NULL 字段的值非空
- 不可以使用 = 或 <> 判断NULL
哪些老师没有奖金(奖金为NULL)
SELECT name FROM teacher WHERE comm IS NULL
哪些老师的奖金不为空
SELECT name FROM teacher WHERE comm IS NOT NULL
排序(ORDER BY)
- ORDER BY 子句可以将结果集按照指定的字段值升序或降序排序
- ORDER BY 字段 ASC:按照指定字段值升序将结果集排序
- ORDER BY 字段 DESC:按照指定字段值升序将结果集排序
- 不指定排序方法时,默认为升序
查看老师的工资,工资从多到少(降序)
SELECT name,salary FROM teacher ORDER BY salary DESC
查看老师的奖金排名,奖金从少到多(升序)
SELECT name,comm FROM teacher ORDER BY comm ASC -- ASC可以不写
- 排序日期类型字段时,日期类型按照 " 近大远小 " 原则
- 距离现在越远的日期越小,越近的日期越大
- 例如:2020-12-05比1993-9-30大
查看学生的生日,按照从远到近(从小到大,升序)
SELECT name,birth FROM student ORDER BY birth
多字段排序
- ORDER BY 子句后面可以指定多个字段,字段之间用","隔开
- 首先将结果集按照第一个字段排序,当第一个字段有重复值时,按第二个字段排序,以此类推
- 每个字段都需要单独指定排序方式,不指定默认为ASC
- ORDER BY 字段1[ASC|DESC],字段2[ASC|DESC],…
查看老师的工资和奖金,首先按照奖金升序,再按照工资降序
SELECT name,comm,salary FROM teacher ORDER BY comm ASC,salary DESC
分页查询
- 分页查询是一种将大量查询结果拆分为多个页面的技术
- 它允许你通过设置每页显示的记录数量和要显示的页数,以便在用户界面上逐步加载和浏览大型数据集
- 当一条DQL语句查询的结果集记录数过多时,就应当使用分页查询
- 优点:占用资源少,减少了网络传输的数据量,提高了传输效率
- 分页查询是方言,在SQL92标准中没有涉及到分页的语法定义
- 不同的数据库SQL写法完全不同
- MySQL和MariaDB中的分页是使用LIMIT子句实现的
语法:
- SELECT…FROM…ORDER BY…LIMIT M,N
- M,N是两个整数
- M 表示跳过结果集 M 条记录
- N 表示从跳过的记录开始查询出 N 条记录
计算公式:
- 分页中常见的参数
- 当前的页数
- 每页显示多少条记录
- 分页公式
- M:跳过结果集中条目数,计算方式:(当前页数-1)*每页显示的条目数
- N:每页显示多少条
查看老师工资的前5名
SELECT name,salary FROM teacher ORDER BY salary DESC LIMIT 0,5
查看老师奖金信息,按照降序排序后,每页显示3条,显示第5页
SELECT name,comm FROM teacher ORDER BY comm DESC LIMIT 12,3
函数和表达式
查看老师的工资和年薪分别是多少
SELECT name,salary,salary*12 FROM teacher
- IFNULL 函数
- IFNULL(arg1,arg2)
- 如果arg1不为NULL,函数返回arg1
- 如果arg1为NULL,函数返回arg2
- 该函数的作用可以将一个NULL值替换为一个非NULL值
查看每个老师的工资和奖金以及总收入(工资加奖金)
SELECT name,salary,comm,salary+IFNULL(comm,0) FROM teacher
查看哪些老师年薪高于60000,并按照工资从高到低
SELECT name,salary*12 FROM teacher WHERE salary*12>60000 ORDER BY salary DESC
- 在数据库中任何数字和NULL运行结果都是NULL
查看哪些老师的奖金少于3000
SELECT name,comm FROM teacher WHERE IFNULL(comm,0)<3000
- NULL 不仅不能作等值判断,>,>=,<,<= 都不能进行判断,都得不到正确结果
别名
- 在SQL语句中可以为字段,表等取别名
- 语法
- 字段 [AS] 别名
- 字段 [AS] ‘别名’
- 字段 [AS] “别名”
- AS 可以省略不写,只打一个空格
查看老师的工资和年薪
SELECT name,salary,salary*12 annusal FROM teacher
- 当别名中含有空格时,需要使用引号
SELECT name,salary,salary*12 'annu sal' FROM teacher
- 当别名中含有SQL关键字或中文时,需要使用引号
SELECT name,salary,salary*12 'from' FROM teacher
聚合函数
- 聚合函数又称为多行函数,分组函数
- 聚合函数是将多条记录指定的字段进行统计并得到一个结果的函数
- 对值的统计:
- MIN:统计指定字段值的最小值
- MAX:统计指定字段值的最大值
- AVG:统计指定字段值的平均值
- SUM:统计指定字段值的总和
- 对记录数的统计
- COUNT:统计指定字段不为NULL的记录总数
查看老师的最高工资,最低工资,平均工资和工资总和
SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary) FROM teacher
查看一共多少位老师
SELECT COUNT(name) FROM teacher
- 聚合函数不统计NULL值的记录
- 要将NULL替换为非NULL值才能得到准确结果
查看老师的平均奖金
SELECT AVG(IFNULL(comm,0)) FROM teacher
- COUNT(*)
- 计算表中的行数(包括NULL值行)
查看一共多少位老师
SELECT COUNT(*) FROM teacher
分组 (GROUP BY)
- GROUP BY 子句用于对结果集按照指定字段值相同的记录分组
- GROUP BY 子句一定是配合聚合函数使用的,对结果集分组后统计结果
- SELECT 子句中出现聚合函数时,不在聚合函数中的字段应当在 GROUP BY 子句中
按照单字段分组
查看每种职位的老师的平均工资分别是多少
SELECT title,AVG(salary) FROM teacher GROUP BY title
查看每个班级各有多少人
SELECT COUNT(*),class_id FROM student GROUP BY class_id
查看学生每种职位各多少人,以及最大生日和最小生日
SELECT COUNT(*) '人数',
MIN(birth) '最大生日',
MAX(birth) '最小生日',
job
FROM student GROUP BY job
按照多字段分组
- GROUP BY 可以按照多字段分组,这些字段值都相同的记录分为一组
查看同班级同性别的学生分别多少人
SELECT class_id,gender,COUNT(*) '人数' FROM student GROUP BY class_id,gender
查看每个班每个职位有多少人
SELECT class_id,job,COUNT(*) '人数' FROM student GROUP BY class_id,job
按照聚合函数的统计结果进行排序
SELECT AVG(salary) avg_sal,subject_id
FROM teacher
GROUP BY subject_id
ORDER BY avg_sal DESC
HAVING 子句
查看每个科目老师的平均工资,但是仅查看平均工资高于6000的那些
SELECT AVG(salary),subject_id
FROM teacher
WHERE AVG(salary)>6000 -- 报错,WHERE子句中不能使用聚合函数作为过滤条件
GROUP BY subject_id;
- WHERE子句中不能使用聚合函数的原因是过滤时机错误
- WHERE子句是在检索表中记录时进行的过滤,最终将满足条件的记录生成结果集
- 而聚合函数的作用是统计,统计是建立在结果集基础上才能进行的
- HAVING子句
- HAVING子句仅跟在GROUP BY子句后
- HAVING用于在GROUP BY对结果集分组后,添加过滤条件筛选符合的分组
查看每个科目老师的平均工资,但是仅查看平均工资高于6000的那些
SELECT AVG(salary),subject_id
FROM teacher
GROUP BY subject_id
HAVING AVG(salary)>6000
- HAVING可以使用聚合函数作为过滤条件
- GROUP BY确定了分组,HAVING通过聚合函数对分组进行过滤
查询每个科目老师的平均工资,前提是该科老师的最高工资要超过9000
SELECT AVG(salary),subject_id
FROM teacher
GROUP BY subject_id
HAVING MAX(salary)>9000
WHERE 和 HAVING 的区别
- 过滤时机不同
- WHERE 在检索表中记录时过滤(先)
- HAVING 在产生查询结果集并根据GOROUP BY确定分组后过滤(后)
- 功能不同
- WHERE 用于确定结果集数据(将满足条件的数据查询出来)
- HAVING 用于确定分组(将满足条件的分组保留)
- 聚合函数过滤
- WHERE 不能使用聚合函数作为过滤条件
- HAVING 可以使用聚合函数作为过滤条件


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









