







前言
啊哈大家好啊,这篇文章我将带着大家来写一道题,这道题就是二叉树得前序遍历:
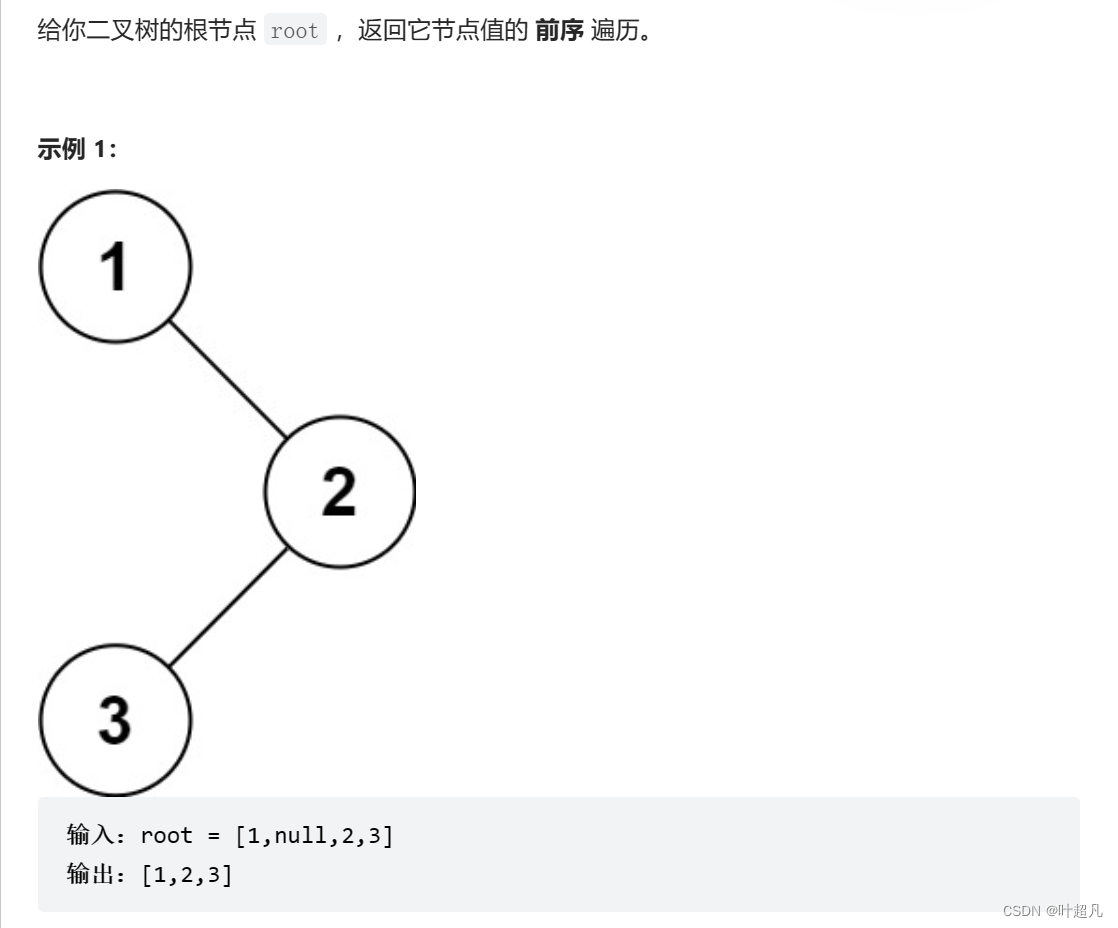
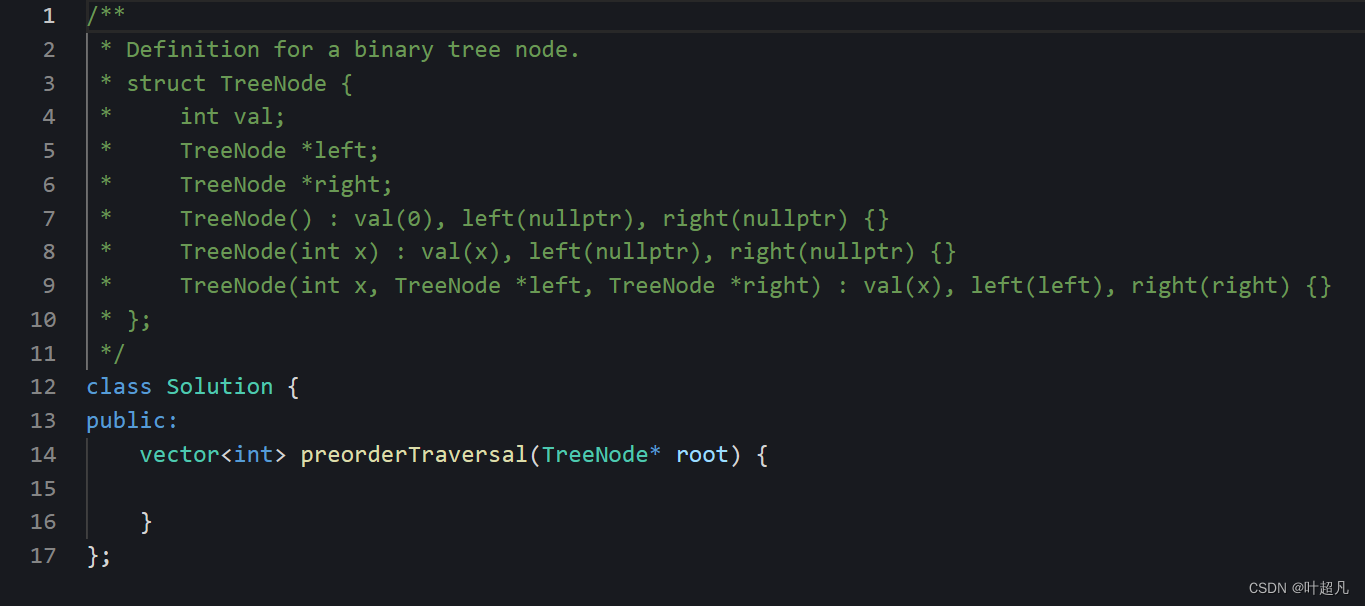
那么这里我就要带着大家用c++语言来学会这道题得解法,如果大家学会以后可以点击下方的链接来自行的查看以下这个题的做法:
点击此处来尝试写题
那么我们话不多说开始这篇文章的重点内容。
递归方式来完成这道题
对于二叉树的遍历问题我们最先想到的方法就是通过递归的方式来依次访问二叉树的每个节点,然后我们知道二叉树的遍历分为三个不同的情况:前序遍历,中序遍历,后续遍历,这三个遍历的方式分是为:
前序遍历:先访问根节点再访问左子树的节点最后访问右子树的节点。
中序遍历:先访问右子树的节点再访问根节点最后访问右子树的节点。
后序遍历:先访问左子树的节点再访问右子树的节点最后访问根节点。
题目给的形式是这样的:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
}
};
所以我们干的第一件事应该就是创建一个vector容器,又因为我们是要递归实现二叉树的遍历,而题目给的这个函数的返回值是一个vector容器,所以这里我们得再创建一个函数用于递归,因为二叉树的遍历需要改变我们创建的vector变量,所以这个函数的参数为:TreeNode*root和vector<int>& v1并且这个函数是没有返回值的,那么当前的代码就如下:
class Solution {
public:
void prev_tree(TreeNode*root,vector<int>& v1)
{
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> v;
prev_tree(root,v);
}
};
接下来要实现的就是二叉树的递归遍历,递归要干的第一件事就是写出来递归的结束条件,我们知道二叉树的子节点如果没有内容的话会是一个空指针,所以这里我们就可以根据这个空指针来判断递归的结束:
void prev_tree(TreeNode*root,vector<int>& v1)
{
if(root==NULL)
{
return;
}
}
前序遍历是先访问根节点再访问左右子树,所以在往下进行递归的时候我们得先将数据放到外面创建的容器里面再进入下面的递归:
void prev_tree(TreeNode*root,vector<int>& v1)
{
if(root==NULL)
{
return;
}
v1.push_back(root->val);
}
递归是先访问左子树,再访问右子树,所以在函数里面我们就调用两次本函数,第一个函数传的参数是root->left,第二个函数的参数就是root->right,那么这里完整的代码就如下:
class Solution {
public:
void prev_tree(TreeNode*root,vector<int>& v1)
{
if(root==NULL)
{
return;
}
v1.push_back(root->val);
prev_tree(root->left,v1);
prev_tree(root->right,v1);
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> v;
prev_tree(root,v);
return v;
}
};
我们运行以下上面的代码就可以看到这里通过了测试:
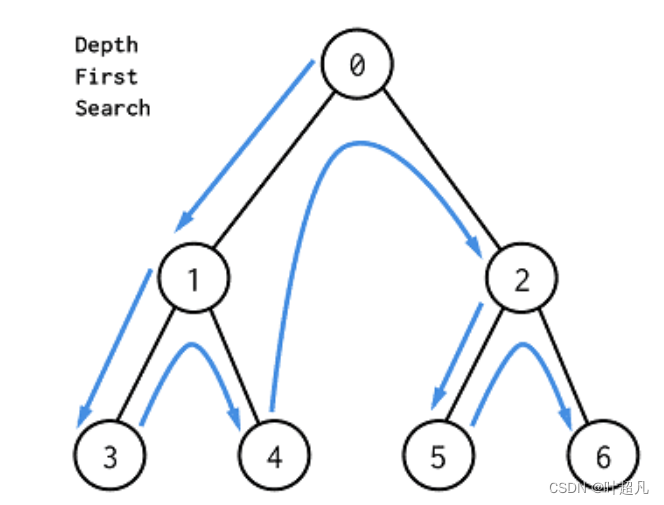
这里如果有小伙伴不清楚这里的递归是如何进行的话,可以看看下面的这张图片然后自己结合代码画画图来理解理解。
那么这是前序遍历,如果我们想要实现中序和后续遍历的话,我们在前序遍历的基础上修改一下顺序就行,在上面写的代码当中根节点的访问是依靠这段代码实现的:v1.push_back(root->val); 访问左子树的功能是靠这段代码实现: prev_tree(root->left,v1)访问右子树的功能是靠这段代码实现:prev_tree(root->right,v1),如果说前序中序后序是读取顺序的不同的话,那么这个不同对应在代码上就是这三段代码排列顺序不同,前序遍历的主要代码是这样的:
v1.push_back(root->val);//访问数据
prev_tree(root->left,v1);//访问左子树
prev_tree(root->right,v1);//访问右子树
那么中序遍历的主要代码就是这样的:
prev_tree(root->left,v1);//访问左子树
v1.push_back(root->val);//访问数据
prev_tree(root->right,v1);//访问右子树
后序遍历的主要代码就是这样:
prev_tree(root->left,v1);//访问左子树
prev_tree(root->right,v1);//访问右子树
v1.push_back(root->val);//访问数据
所以中序遍历的完整代码就是这样:
void Mid_tree(TreeNode*root,vector<int>& v1)
{
if(root==NULL)
{
return;
}
prev_tree(root->left,v1);//访问左子树
v1.push_back(root->val);//访问数据
prev_tree(root->right,v1);//访问右子树
}
所以后序遍历的完整代码就是这样:
void Post_tree(TreeNode*root,vector<int>& v1)
{
if(root==NULL)
{
return;
}
prev_tree(root->left,v1);//访问左子树
prev_tree(root->right,v1);//访问右子树
v1.push_back(root->val);//访问数据
那么上述就是递归方式实现遍历的讲解,希望大家可以理解。
迭代的方式实现前序遍历
我们上面是通过递归的方式来实现二叉树的遍历,除了递归的方法,我们这里还有个迭代的方法,由递归转向迭代我们最常用的方式就是创建一个栈,因为栈具有一个特性就是后进先出,而递归的规律也是最后被调用的函数先被处理完,所以由递归转向迭代我们常用的方法是使用栈来处理数据,前序遍历是先访问根节点再访问左子树和右子树,所以这里我们先创建一个栈,因为前序遍历最先处理的是根节点,所以创建栈以后我们就将二叉树的根节点放入栈中,因为我们要使用栈不停的处理节点的数据,所以我们得创建一个while循环来不停的处理数据,这里处理数据的方式就是不停的入栈出栈并对数据进行分析,所以该循环结束的条件就是:栈中没有数据时结束循环,那么我们当前的代码实现就如下:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
s1.push(root);
while(!s1.empty())
{
}
}
};
因为进入循环的时候栈中本来就存在数据,所以在循环里面干的第一件事情就是将栈中的数据进行出栈,因为每次循环只会处理一个数据,所以在循环里面我们出栈就只出一个数据,将数据出栈之后就要对其进行处理,首先肯定得执行的操作就是将这个数据存入vector容器里面,并且有数据出栈那么就肯定得有数据入栈,这里前序遍历是先处理完根节点之后再处理左子树和右子树,所以这里我们入栈就应该入左子树和右子树的根节点,那么这里就会存在几个问题:在一次循环里面入栈入几个元素?如果是一个元素的话是左子树的根节点还是右子树的根节点?如果是两个元素的话我们先入左子树的根节点还是右子树的根节点。好!看了这几个问题我们先来假设一下每次只入一个节点会是一个什么情况,我们的二叉树长这样:
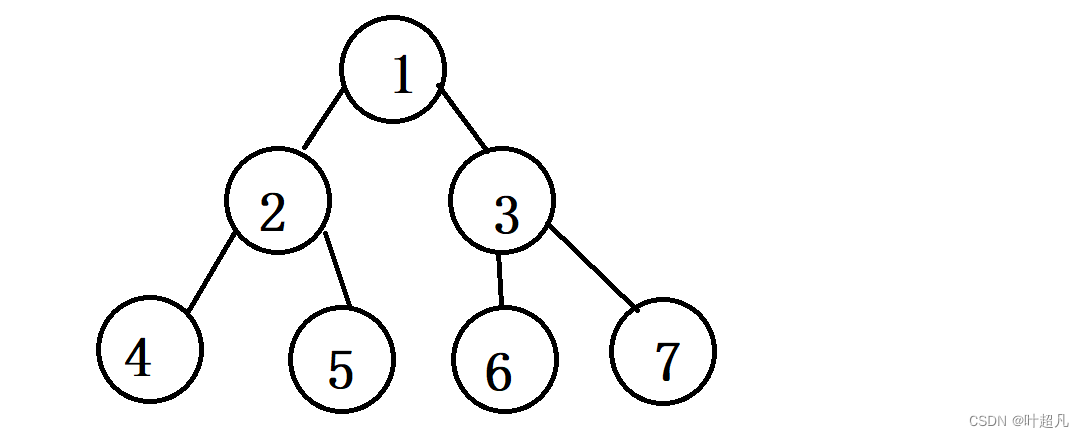
第一个入栈的节点是1然后我们将其进行出栈并处理,这时入的元素便是节点1的两个子节点,因为这里假设每次只入一个节点而且前序遍历处理完根节点后再处理的节点是左子树的根节点,所以这时入栈的元素就是2,2入栈后便出栈进行处理然后再入节点4,4入栈后便出栈进行了处理然后我们发现4的左右子节点都是NULL,不用进行入栈处理,而且这里采用的元素入栈的方法是创建一个临时变量的方法,比如说下面的代码:
while(!s1.empty())
{
TreeNode*tmp=s1.top();
s1.pop();
v1.push_back(tmp->val);
if(tmp->left!=nullptr)
{
s1.push(tmp->left);
}
}
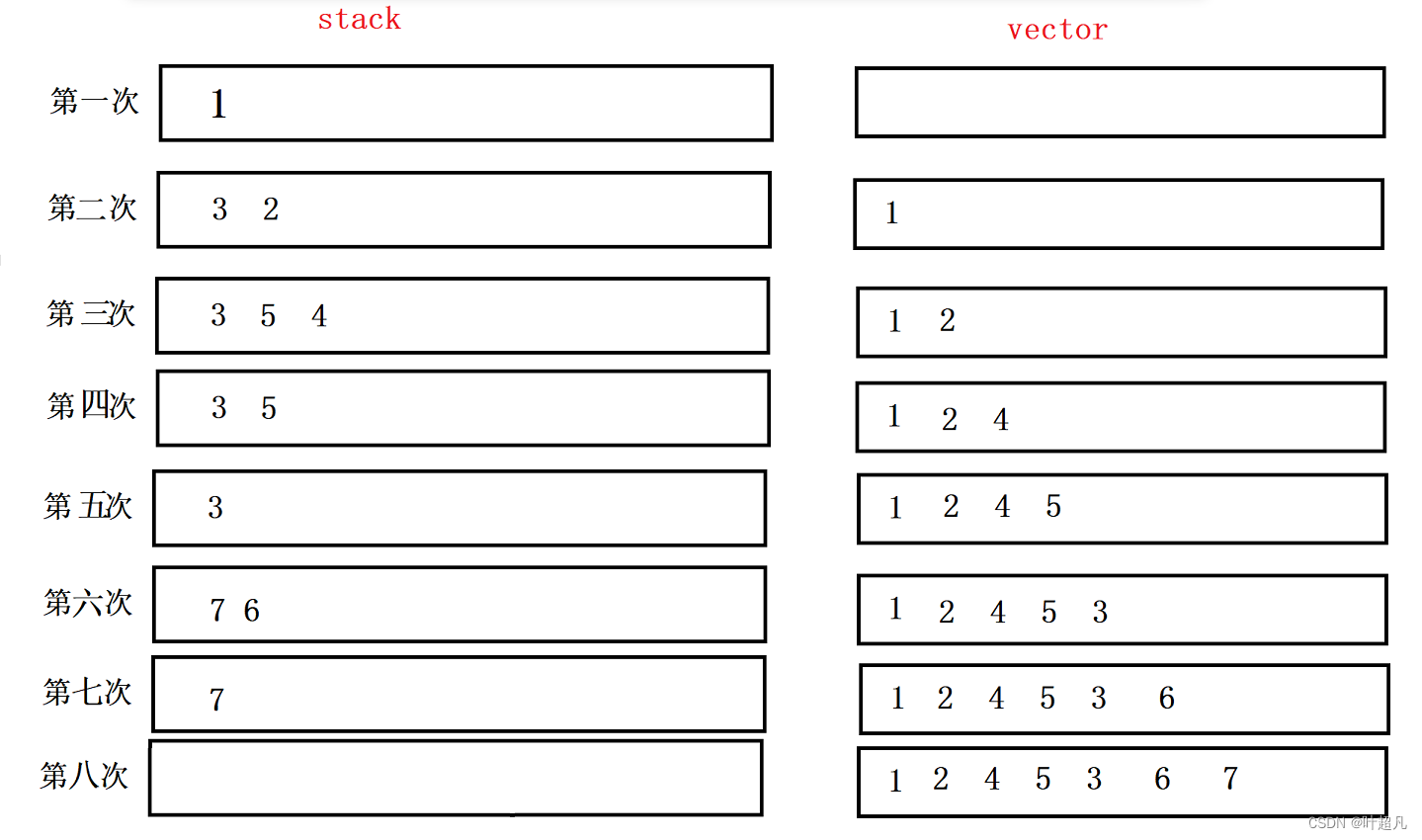
这创建了一个临时变量tmp来判断是否要入栈,所以当程序处理到节点4之后,没有元素入栈了,我们也就没有办法回头处理节点5了,所以每次循环自如一个节点肯定是行不通的,所以每次循环我们得将节点的左右子节点全部都入栈,那么我们先入哪个节点呢?我们知道栈的处理规则是后入栈的元素先出栈,又因为前序遍历是先访问左子树再访问右子树,所以这里我们得先入右子树的节点,再入左子树的节点,这样在处理完所有的右节点之后栈中还有左子树的节点可供我们处理,我们来看看下面的图解:
那么看到这里前序遍历的大致思路我们就差不多想好了,那么这里大家还要注意的一点就是可能一开始给的树就是一个空树,所以我们在一开始入根节点的时候就得加个if语句判断一下,如果为空节点的话我们就直接返回一个空容器:
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)
{
return v1;
}
s1.push(root);
那么我们这里完整的代码就如下:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)//判断是否为空树
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode*tmp=s1.top();//创建一个临时变量来记录要处理的节点
s1.pop();//将要处理的节点踢出栈
v1.push_back(tmp->val);//将处理掉的节点放入容器中
if(tmp->right!=nullptr)//先处理右节点并判断一下如果右节点为空就不处理了
{
s1.push(tmp->right);
}
if(tmp->left!=nullptr)
{
s1.push(tmp->left);
}
}
return v1;
}
};
我们提交一下就可以看到我们的代码是没有问题的。
迭代的方式实现中序遍历
前序遍历是先处理根节点再处理左子树和右子树,但是中序遍历是先访问左子树再访问根节点,就比如说下面的二叉树:
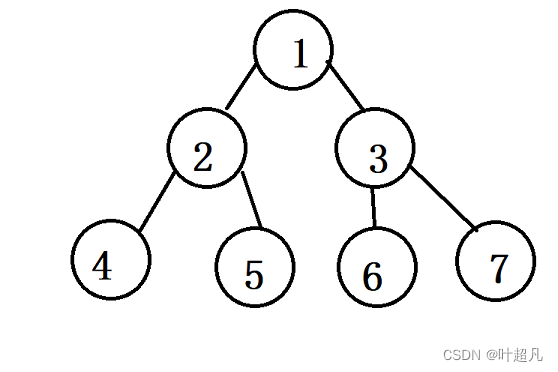
前序遍历第一个打印的节点是1,但是中序遍历第一个打印的节点是4,所以在用迭代的方法实现中序遍历的时候不能采用简单的换位置的方式,而是得再想个办法使得我们能够第一个处理的节点是4号节点,因为这里还是迭代的方式来完成遍历所以根据往常的经验来说我们这里还是得创建一个栈来实现这里的功能,我们把上面的二叉树补充一下,在4号节点的下面应该还存在着两个节点只不过这两个节点的内容为空:
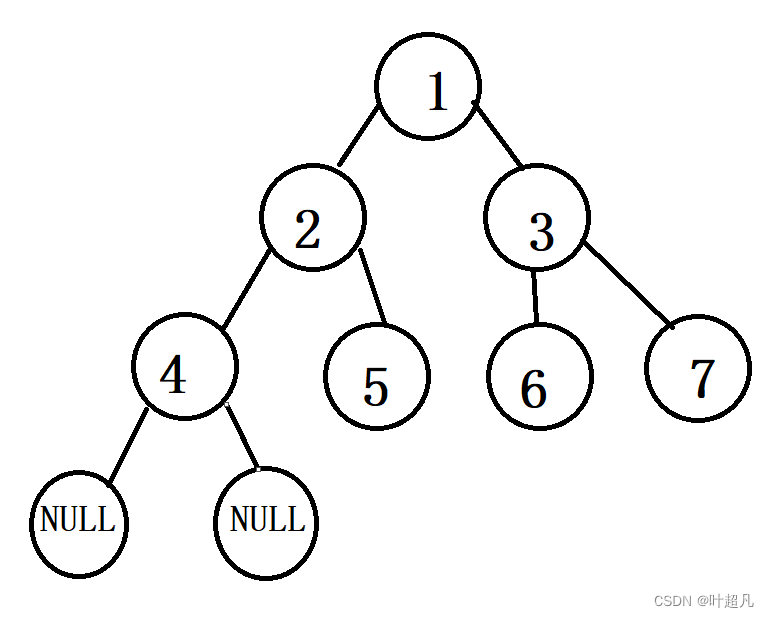
所以按照道理来说我们处理的第一个节点应该是4号节点的左子节点,但是这个节点为空所以不用对其进行处理,然后处理的才是4号节点,当4号节点处理完之后要处理的就是4号节点的右子节点,但是这个节点也是空的不用对其进行处理,所以这个时候我们处理的就是4号节点的父节点也就是2号节点,所以大家根据这个规律能不能发现一个现象:我们先处理4号节点(忽略了4空节点),然后才处理的是4号节点的父节点,而且这里处理节点的工具是栈,所以这里入栈的顺序应该是1 2 3 4 NULL,当入栈的时候发现是NULL的话我们就不入栈,而是将栈顶的元素出栈进行处理,并将这个节点的右节点入栈并对这个节点进行处理,处理的方式为:如果这个节点为空的话就再让栈顶的元素出栈并对其进行处理,如果这个节点不为空的话,我们是不是得再将这个节点的左子树不停的入栈直到遇到空节点位置,那么看到这里想必大家应该能够知道这里实现的大致逻辑,我们首先来想一个问题:如何来不停的将节点入栈,并判断是否为空节点?那么这个问题可以很好的解决,我们可以创建一个指针和while循环通过if else语句来判断是否为空节点,那么这里的准备工作如下:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> v1;
if(root==NULL)
{
return v1;
}
TreeNode*cur=root;
stack<TreeNode*> s1;
while(!s1.empty())
{
if(cur!=nullptr)
{
}
else
{
}
}
}
};
如果不为空节点的话我们就将当前的元素入栈并更新指针cur的值让其指向左子树的节点,然后我们就不用干任何事情这时候就可以接着执行下一次循环:
while(!s1.empty())
{
if(cur!=nullptr)
{
s1.push_back(cur);
cur=cur->left;
}
else
{
}
}
如果cur指向的当前节点是空节点的话,我们就得分两种情况进行讨论,第一个是左子树的节点为空,第二个是右子树的节点为空,对于第一种情况,左子树的节点为空的话我们接下来要处理的就是根节点比如说4号节点的左节点为空,那么这个节点就不用进行处理紧接着要处理的就是4号节点,而4号节点当前所在的位置刚好就是栈顶,所以我们直接出栈并入容器就行,然后要处理的就是右子树的根节点,所以我们得更新一下cur的值,所以第一种情况的代码就是这样:
while(!s1.empty())
{
if(cur!=nullptr)
{
s1.push_back(cur);
cur=cur->left;
}
else
{
cur=s1.top();
v1.push_back(cur->val);
s1.pop();
cur=cur->right;
}
}
当这次循环结束之后第二次循环就会开始处理右子树的节点,如果右子树不为空的话就会入栈,并开始下一段循环处理右子树的左子树的节点。对于第二种情况:如果右子树的节点为空的话,说明我们以及把当前的根节点,和根节点的右子树全部都处理了,如果当前的右子树为空的话,我们就得处理父节点的父节点,比如说4号节点的右子树为空,如果我们处理到右子树的话说明4号节点的左子树和4号节点本身都处理完了,所以这个时候要处理的就是4号节点的父节点2号节点,而2号节点比4号节点先入栈,我们处理4号节点的时候就已经把4号节点给出栈了,所以如果右子树为空的话,我们要干的就是让当前栈顶的元素出栈,将其放入容器里面,当2号节点处理完了就要处理2号节点的右节点,所以这个时候我们就得改变cur的值让其指向根节点的右子树节点,那么这里的代码实现和第一种情况是一摸一样的,所以完整的代码就如下:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> v1;
if(root==NULL)
{
return v1;
}
TreeNode*cur=root;
stack<TreeNode*> s1;
while(!s1.empty())
{
if(cur!=nullptr)
{
s1.push(cur);
cur=cur->left;
}
else
{
cur=s1.top();
v1.push_back(cur->val);
s1.pop();
cur=cur->right;
}
}
return v1;
}
};
但是我们将这个代码提交一下就发现这里出现了问题:
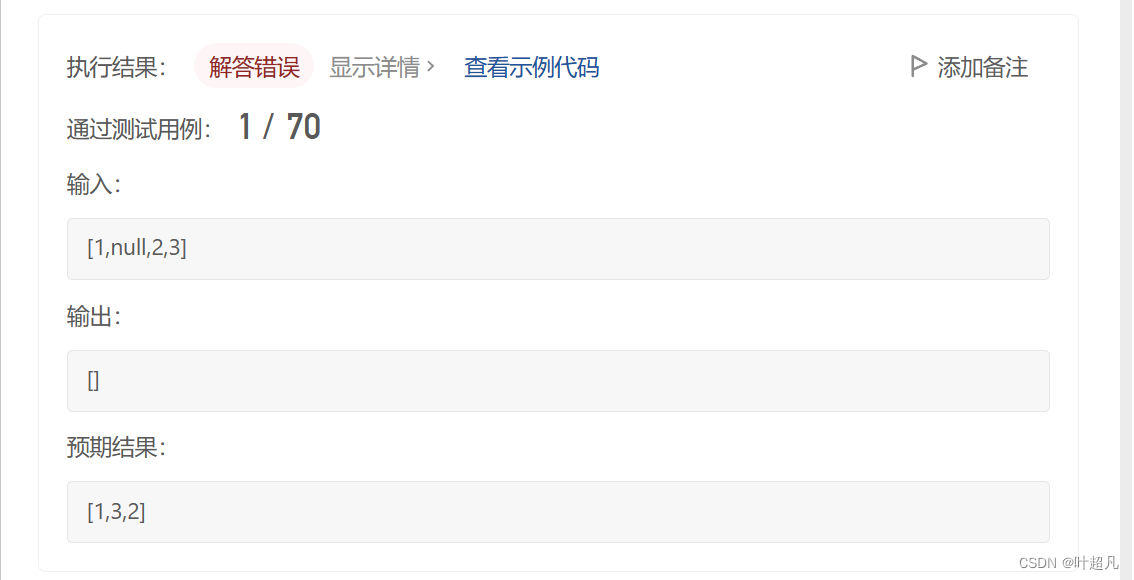
一个参数都没有跑过,那这是为什么呢?原因很简单问题出现在了循环上面,我们是根据栈是否为空来判断循环是否结束,当我们把整个树的根节点加上左子树全部都处理完之后当前的容器就变为空了,cur指向了右子树的根节点,但是这个时候循环就结束了,所以运行不成功,所以我们得把循环条件改一下改成下面这样,就可以运行成功:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> v1;
if(root==NULL)
{
return v1;
}
TreeNode*cur=root;
stack<TreeNode*> s1;
while(!s1.empty())
{
if(cur!=nullptr)
{
s1.push(cur);
cur=cur->left;
}
else
{
cur=s1.top();
v1.push_back(cur->val);
s1.pop();
cur=cur->right;
}
}
return v1;
}
};
我们点击一下运行就可以看到编译成功了:
迭代的方式实现后序遍历
前序遍历是先先处理根节点再处理左子树最后处理右子树,而后序遍历是先处理左子树再处理右子树最后处理根节点,我们来看看前序遍历的代码:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)//判断是否为空树
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode*tmp=s1.top();//创建一个临时变量来记录要处理的节点
s1.pop();//将要处理的节点踢出栈
v1.push_back(tmp->val);//将处理掉的节点放入容器中
if(tmp->right!=nullptr)//先处理右节点并判断一下如果右节点为空就不处理了
{
s1.push(tmp->right);
}
if(tmp->left!=nullptr)
{
s1.push(tmp->left);
}
}
return v1;
}
};
我们发现这里是可以更改处理节点的顺序的,我们将里面的代码块进行一下更改:
while(!s1.empty())
{
TreeNode*tmp=s1.top();//创建一个临时变量来记录要处理的节点
s1.pop();//将要处理的节点踢出栈
v1.push_back(tmp->val);//将处理掉的节点放入容器中
if(tmp->left!=nullptr)//先处理左节点并判断一下如果右节点为空就不处理了
{
s1.push(tmp->left);
}
if(tmp->right!=nullptr)
{
s1.push(tmp->right);
}
}
这样我们的代码就变成了先处理根节点再处理右子树最后处理左子树,也就是变成了中右左,而后序遍历是左右中,那这不就反过来了吗?也就是说我们将上述更改后的前序遍历的结果进行一下反转就得到了后序遍历,反转的功能可以通过reserve函数来实现,所以后序遍历的代码就可以写成这样:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)//判断是否为空树
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode*tmp=s1.top();//创建一个临时变量来记录要处理的节点
s1.pop();//将要处理的节点踢出栈
v1.push_back(tmp->val);//将处理掉的节点放入容器中
if(tmp->left!=nullptr)//先处理左节点并判断一下如果右节点为空就不处理了
{
s1.push(tmp->left);
}
if(tmp->right!=nullptr)
{
s1.push(tmp->right);
}
}
return v1;
}
};
我们放到上面测试一下就可以看到这段代码是没有问题的。
二叉树前中后迭代方式统一写法
看到这里大家有没有发现我们上面写的代码有一个问题:我们用递归的方式实现遍历的时候可以通过交换几段代码方式来实现遍历形式的替换,但是我们使用迭代的方式实现遍历的话就不能通过交换几段代码的顺序来实现功能替换,如果非说有关联的话这里的前序和后序存在一点点的关联,但是中序和前序实现的方法确实完全不相同,那这是为什么呢?原因很简单,前序和中序的节点访问和处理的顺序不一样对于前序来说根节点是刚访问就处理,将所有的右节点都存着,而中序遍历是将所有的左节点都存着等访问到空节点的时候再访问左节点,左节点访问完之后再访问右节点并立即处理右节点,所以这就是访问顺序的不同以及处理的顺序不同而导致的两者实现的方式不同,那这里就有个想法我们能不能以一个统一的写法来使得能够以一个统一的写发来实现前中后序遍历呢?就是更改几段代码的顺序就可以实现遍历的替换,那么答案是可以的,我们之前的后序遍历是根据二叉树的空节点来判断是否要处理节点,前序遍历是根据是否遇到左子树的节点来判断是否要处理右子树,那这里就有个共同的特点:都是根据空节点来判断是否要处理已经入栈的节点,那我们能不能根据这个特点来写一个统一的写法呢?我们上面的写法都是根据二叉树的空节点来实现的,为了以一个统一的方法来实现我们这里就得换一个角度,当我们在栈中看到了空节点我们就要处理这个节点将其入栈,那这里有小伙伴可能会感到很疑惑啊,为什么栈中会出现空节点呢?原因也很简单这个空节点是我们自己加的,他是一个标记的作用,之前我们是根据二叉树的空节点来判断是否要处理节点,那么这里我们就是根据栈中的头部是否出现空节点来判断是否要处理这个空节点后面的节点,既然这样地话我们就来先实现一个中序遍历,跟上面一样我们先创建一个栈和容器并且判断根节点是否为空来判断是否要进行下面地循环,如果不为空的话我们就先将根节点载入栈中,下面就是一个while循环,因为这里元素的处理在栈中所以这个循环结束的条件就是当栈为空时解释循环,在循环里面有一个if else语句,这个语句就是判断当前的头部是否为空,如果为空的话我们要干什么,如果不为空的话我们又要干什么?那么这里大致的代码就如下:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode* node =s1.top();
if(node!=NULL)
{
}
else
{
}
}
return v1;
}
};
我们上面说在栈中的null是要处理节点的标志,所以当node为空的时候表明我们这里要处理节点,当前的头部是空节点,所以我们将空节点删除,再将当前的节点删除并放到容器里面,那么这里的代码就如下:
while(!s1.empty())
{
TreeNode* node =s1.top();
if(node!=NULL)
{
}
else
{
s1.pop();
node=s1.top();
s1.pop();
v1.push_back(node->val);
}
}
如果栈中的第一个元素不为空的话,我们这里就得继续往栈中插入元素,我们首先得将栈顶的元素删除,因为这个元素已经被访问了所以我们得在这个元素的后面加入空元素,又因为有不同的访问方式,所以这里就将当前的根节点放入到不同的地方,我们这里实现的是中序遍历,先访问左子树,再访问节点,最后访问右子树,因为这里的容器为栈,所以我们得先入右子树,再入节点,再入左子树,因为此时的节点已经被访问过一次了,再次访问的话就应该被处理掉,所以我们得在根节点的后面再插入一个空节点,因为栈中的空节点是判断是否需要被处理的,所以当我们在二叉树中遇到空节点的时候不要将其入栈,那么这里的代码如下:
while(!s1.empty())
{
TreeNode* node =s1.top();
if(node!=NULL)
{
s1.pop();
if(node->right!=NULL)
{
s1.push(node->right);
}
s1.push(node);
s1.push(NULL);
if(node->left!=NULL)
{
s1.push(node->left);
}
}
else
{
s1.pop();
node=s1.top();
s1.pop();
v1.push_back(node->val);
}
}
那么这里完整的代码就如下:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode* node =s1.top(); //更新node使其每次指向头部判断是要处理还是插入数据
if(node!=NULL)//如果不为空的话就要插入数据
{
s1.pop();//将栈顶的元素删除因为要改变他的位置
if(node->right!=NULL)
{
s1.push(node->right);
//因为为前序遍历所以要先插入右子树这样他就最后被访问
}
s1.push(node);
//根节点是第二个访问的所以在这个位置
s1.push(NULL);
//因为根节点已经被访问了一次,所以再次访问他就要被删除所以加个NULL
if(node->left!=NULL)
{
s1.push(node->left);
}
}
else//如果为空的话就要处理数据
{
s1.pop();//先删除空元素
node=s1.top();
s1.pop();//再删除要处理的元素
v1.push_back(node->val);//将处理的元素放入容器中
}
}
return v1;
}
};
我们将这段代码运行一下就可以看到这里的运行通过了:
上面是中序遍历的代码,对于前序遍历来说我们这里要干的就是将这个if语句中的代码顺序改一下,因为前序遍历是先处理根节点所以我们将
s1.push(node);
s1.push(NULL);
这段代码放到最后,将下面的代码放到最前:
if(node->right!=NULL)
{
s1.push(node->right);
}
所以完整的代码就如下:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode* node =s1.top(); //更新node使其每次指向头部判断是要处理还是插入数据
if(node!=NULL)//如果不为空的话就要插入数据
{
s1.pop();//将栈顶的元素删除因为要改变他的位置
if(node->right!=NULL)
{
s1.push(node->right);
}
if(node->left!=NULL)
{
s1.push(node->left);
}
s1.push(node);
s1.push(NULL);
}
else//如果为空的话就要处理数据
{
s1.pop();//先删除空元素
node=s1.top();
s1.pop();//再删除要处理的元素
v1.push_back(node->val);//将处理的元素放入容器中
}
}
return v1;
}
};
将其测试一下就可以发现这里的实现是真确的:
同样的道理后序的完整代码就如下:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> s1;
vector<int> v1;
if(root==NULL)
{
return v1;
}
s1.push(root);
while(!s1.empty())
{
TreeNode* node =s1.top(); //更新node使其每次指向头部判断是要处理还是插入数据
if(node!=NULL)//如果不为空的话就要插入数据
{
s1.pop();//将栈顶的元素删除因为要改变他的位置
s1.push(node);
s1.push(NULL);
if(node->right!=NULL)
{
s1.push(node->right);
}
if(node->left!=NULL)
{
s1.push(node->left);
}
}
else//如果为空的话就要处理数据
{
s1.pop();//先删除空元素
node=s1.top();
s1.pop();//再删除要处理的元素
v1.push_back(node->val);//将处理的元素放入容器中
}
}
return v1;
}
};
测试一下运行的结果也是对的,所以我们这里的代码实现也是真确的,那么以上就是我们的全部内容希望大家可以理解。
















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











