







目录
一、缓冲区
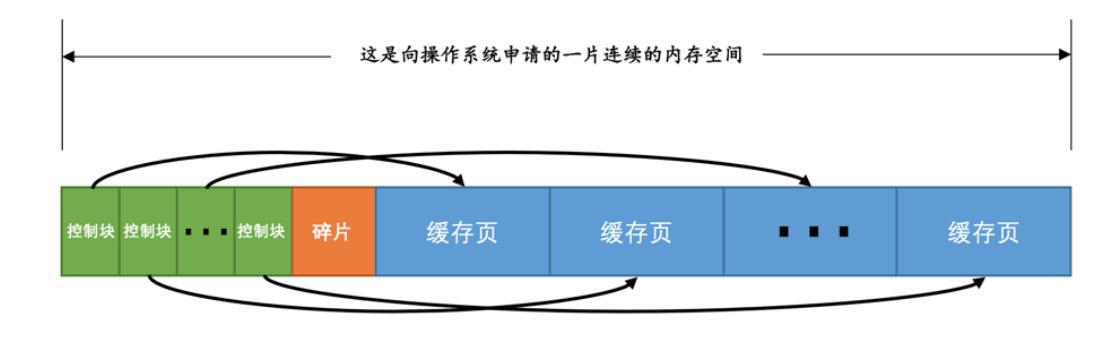
1.1 缓冲区是内存的一块存储空间
缓冲区是内存中一块连续的存储空间!
1.2 缓冲区的作用
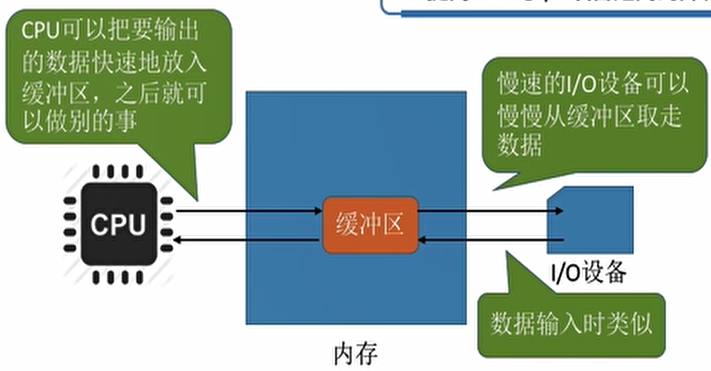
缓冲区相当于我们日常寄快递的顺丰服务,我们将我们的数据拷贝至我们的缓冲区,缓冲区将我们的数据进行IO读写!这样可以缓解CPU压力,提高进程运行效率!
1.3 C式缓冲区
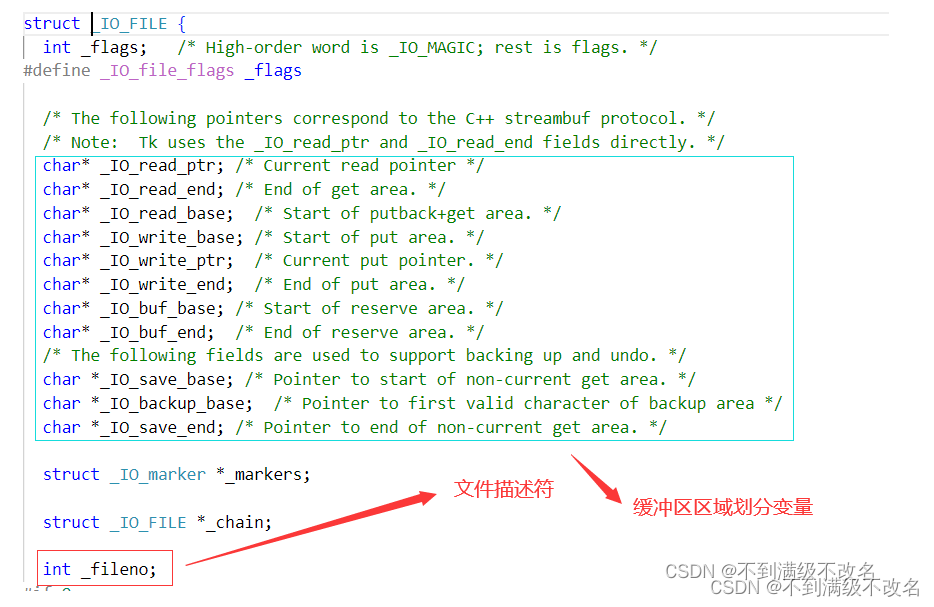
1.3.1 C语言的FILE结构体
C语言的FILE结构体内成员不仅有文件描述符,还有缓冲区区域划分的变量!这个缓冲区我们称为C式缓冲区,默认式行缓冲,C式缓冲区不在内核中而是在用户级别中!
1.3.2 C式缓冲区刷新策略
1.立刻刷新(fflush)
2.行缓冲(每次换行刷新)
3.全缓冲(缓冲区内存空间存满)
二、OS与内核缓冲区
2.1 数据从缓冲区到磁盘
C式缓冲区是用户级别的缓冲区,C式接口将数据先拷贝至C式缓冲区,然后最后将C式缓冲区数据拷贝至内核缓冲区,最后从内核缓冲区写入文件中(这个阶段由OS完成)!

2.2 fsync() 数据免缓冲直接到磁盘文件

2.3 检验用户与内核缓冲区
下面代码一次用fork,一次不同:
#include<stdio.h>
#include<unistd.h>// write fork
#include<string.h>
int main()
{
//C式接口
printf("Hello Linux!\n");
fprintf(stdout,"Welcome to Linux!\n");
//系统接口
const char* buffer="Nice to meet you!\n";
write(1,buffer,strlen(buffer));
fork();
return 0;
}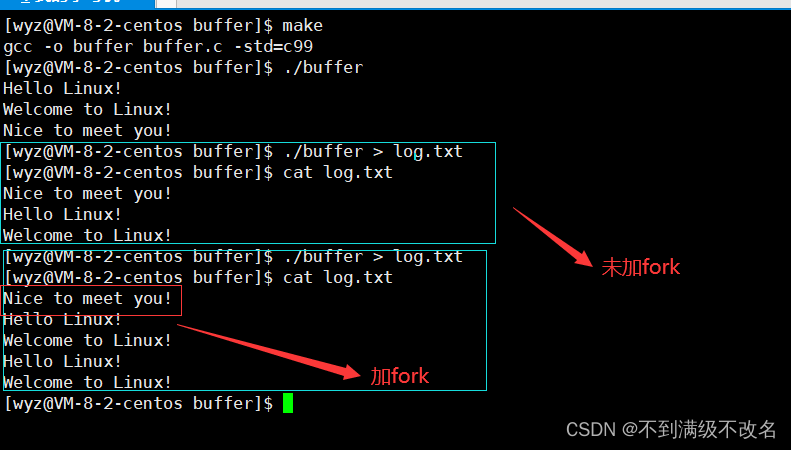
fork以后,为什么C式接口函数会打印两次?
创建子进程代码解释:创建子进程前,父进程的数据从默认的显示器重定向到指定文件,C式接口函数(显示器)默认是行缓冲!但是重定向到文件,变成了全缓冲!所以数据依旧在缓冲区没有被刷新,创建子进程后,程序退出,子进程退出后刷新缓冲区,缓冲区数据被写入文件中,刷新代表着修改共享数据!于是父进程进行写时拷贝缓冲区数据,然后退出再次刷新新的缓冲区!
为什么write内容只打印一次呢?
write没有FILE*,也就没有C式缓冲区!而是直接写入内核缓冲区!
三、文件系统
3.1 磁盘
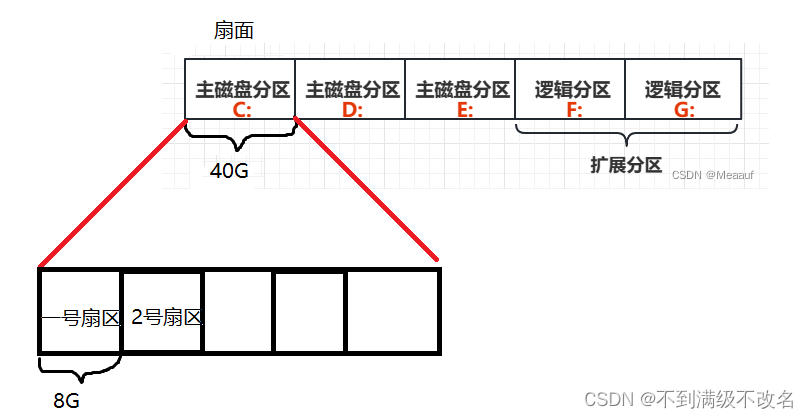
3.1.1 磁盘物理结构


盘片
一个磁盘(如一个 1T 的机械硬盘)由多个盘片叠加而成。盘片的表面涂有磁性物质,这些磁性物质用来记录二进制数据。因为正反两面都可涂上磁性物质,故一个盘片可能会有两个盘面。
磁道、扇区
每个盘片被划分为一个个磁道,每个磁道又划分为一个个扇区。其中,最内侧磁道上的扇区面积最小,因此数据密度最大。
柱面
每个盘面对应一个磁头。所有的磁头都是连在同一个磁臂上的,因此所有磁头只能“共进退”。所有盘面中相对位置相同的磁道组成柱面
3.1.2 磁盘存储结构
磁盘查找数据顺序:定位磁道(柱面)-->定位磁盘-->定位扇区 (CHS法)
查找过程中,每个面的磁头都会在每个面的磁道寻找



3.1.3 磁盘逻辑结构

卷起来磁带扯出来就是一条长带,是一种线性结构!
我们可以联想将我们圆形的磁盘磁道拉成一条磁带,这样磁道就可以抽象成是一种线性的结构!磁盘由多条磁带组成!
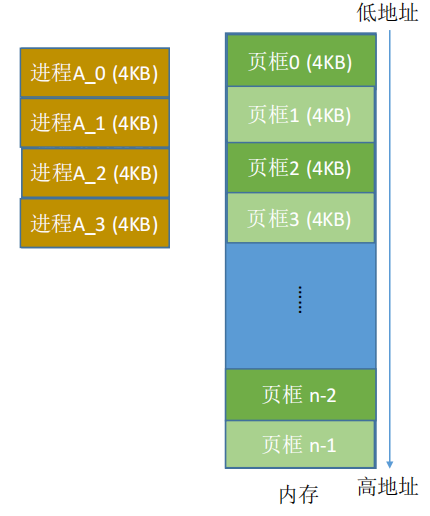
磁盘基本存储单位是扇区的512字节,但是依旧很小!OS内的文件系统定制的进行多个扇区的读取,这样可以一次读取1/2/KB,4KB为主的基本单位!也就是说,哪怕只要读取/修改1bit,也必须将4KB加载到内存!
内存是被划分成了4KB大小的空间--页框
磁盘的文件尤其是可执行文件--按照4KB大小划分好的块--页帧
3.1.4 磁盘分区分组管理
类比我们国家划省管理,计算机同样分区管理!这些区就是我们现在的C/D/E盘...在区中,我们还分组管理,所有组管理方式一样!

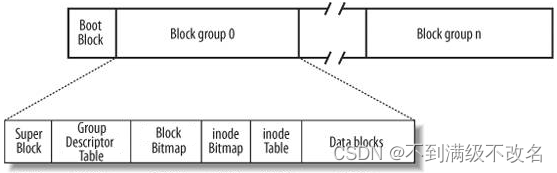
文件=内容+属性
文件inode存放文件的属性(没有文件名),Data blocks存放文件内容!一个文件,一个inode!查找文件通过inode编号!
查看inode方法 ls -i 选项!

Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
GDT,Group Descriptor Table:块组描述符,描述块组属性信息,有兴趣的同学可以在了解一下
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。inode table:存放已用和未用的inode!
i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
数据区(Data blocks):以数据块的形式存放文件内容
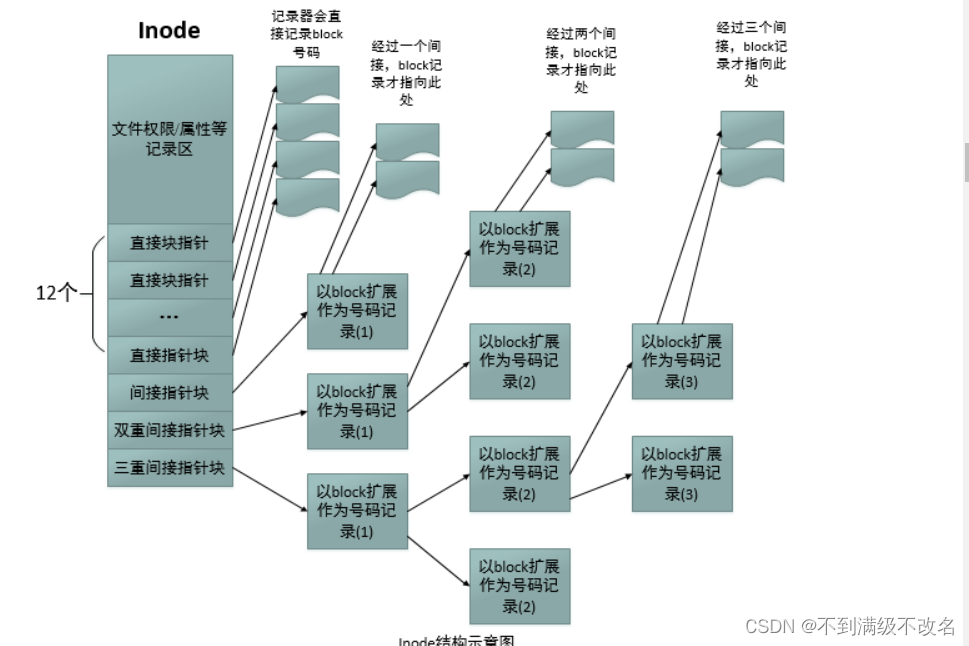
数据区如何存储文件内容?
数据区以一个个数据块为基本单位存储数据!不同数据块大小并不一定相同!有些特殊数据块不存数据而是存储数据块索引,即该数据块可以指向其他数据块!我们称之为多级索引!
如何找到我们需要读取/修改的文件内容?
我们的inode结构体内有一个数组,存储数据块的数据块编号!通过编号找到具体数据块!
如何通过文件名找到对应的文件内容?
我们之前是通过inode找到数据块,但是我们用的都是文件名啊,inode中没有文件名!文件名怎么找到自己的inode?我们需要两者的索引关系!那就是我们的目录!目录也是一个文件,该文件中存放着我们目录下文件名与inode的映射,这样我们就可以通过文件名拿到文件的indoe,继而找到我们数据块文件内容!所以为什么我们读文件首先一定要拥有目录的读权限,这样我们才能读取目录的数据块
3.2 软硬链接
3.2.1 建立软连接与硬链接
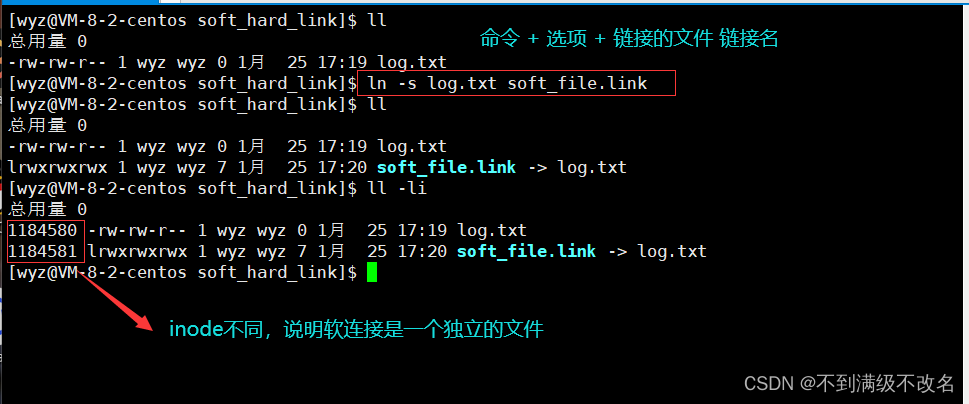
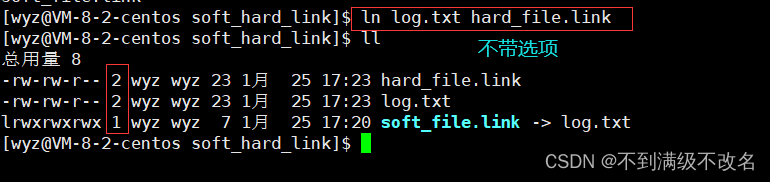

上面的数字意义是同一个inode有多少文件名与它有映射关系!
软链接文件是独立的文件,它的数据块内存放对应链接文件的路径,而硬链接相当于引用!所以为什么我们可以看到 log.txt 变成了有两个不同文件名称映射同一个inode!
下面我们来测试一下软硬链接的区别:
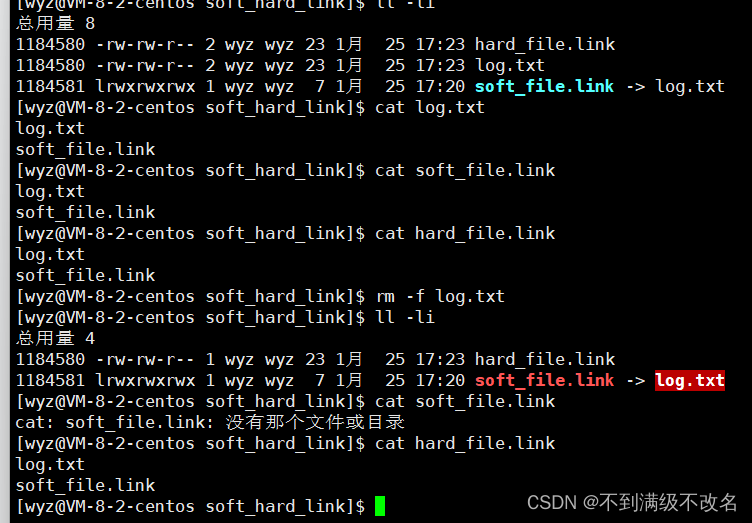
解除软链接:

3.2.2 目录的硬链接
目录文件内有该目录路径以及上机目录路径的硬链接!
一个点表示当前目录,两个点表示上级目录的硬链接!
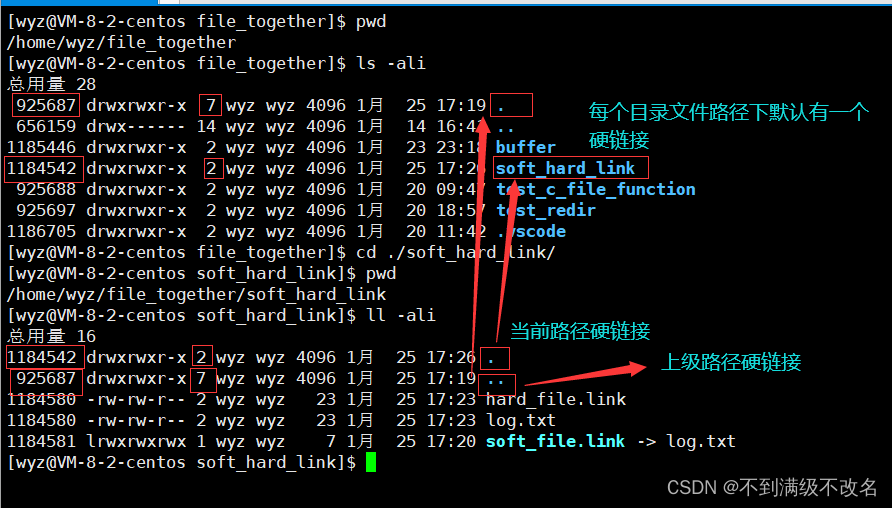
这样我们可以在任何路径下,建立路径文件的软硬链接!但是我们用户不能给路径建立硬链接!
3.2.3 软链接应用
软链接相当于我们Windows中的快捷方式!软链接可以让我们在很深的路径下找到上级路径的文件!















 1345
1345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









