






1.解决问题:获取评论数组,数组中每个对象为一级评论,一级评论包含了一个数组,该数组为一级评论下的每个评论
2.预期结果:
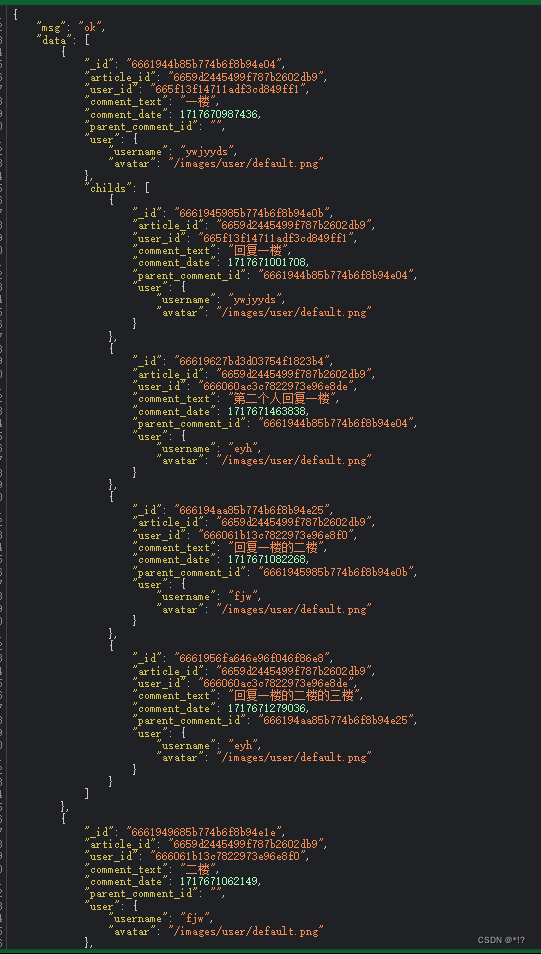
3.代码
find_discuss: async (id) => {
//id:'文章'分类的id
//temp用于存储一级评论
let temp = []
//deeplist:递归函数,parent_comment_id:传入上一级评论id,idx顶级评论当前索引值
async function deeplist(parent_comment_id, idx = 0) {
//aggregate集合管道,
const comments = await Discuss_Model.aggregate([
{
// 匹配一级评论
$match: { parent_comment_id: parent_comment_id, article_id: id }
},
{
/**
* 将$user_id转化为ObjectId对象,并添加为新字段:userIdObject,
* 此文档字段user_id为字符串类型与_id(ObjectId)类型进行匹配时需要转化,否则没有结果
*/
$addFields: {
// 将 userId 转换为 ObjectId 类型
userIdObject: { $toObjectId: "$user_id" }
}
},
//联表查询,评论表和用户表
{
$lookup: {
//联表查询的目标
from: "commonusers",
//当前表中需要进行关联的字段,
localField: "userIdObject",
//要被关联的表中的字段
foreignField: '_id',
//给结果数组字段取个名称
as: "user"
}
},
{// 展开数组,获取第一个匹配的用户信息
$unwind: '$user'
},
{
//最后返回前需要保留的字段,1保存,
$project: {
_id: 1,
article_id: 1,
user_id: 1,
comment_text: 1,
comment_date: 1,
parent_comment_id: 1,
'user.username': 1,
'user.avatar': 1
}
}
])
//如果parent_comment_id=''表示为一级评论
if (parent_comment_id === '') {
//拿到所有一级评论,存储给temp并为每个一级评论对象添加childs属性,并为[],用于存储子评论
temp = comments
for (let i = 0; i < temp.length; i++) {
temp[i].childs = []
}
return
}
//如果comments.length===0,该评论下已没有子评论,返回空数组
if (comments.length === 0) {
return []
}
//根据传入的idx,确保为当前一级评论,再对返回的评论数组进行合并
temp[idx].childs = temp[idx].childs.concat(comments)
for (let i = 0; i < comments.length; i++) {
//确保合并数组之后,再根据当前返回的结果数组进行遍历,依次递归,找到以下所有评论
await deeplist(comments[i]._id.toString(), idx)
}
//返回当前查询到的评论数组
return comments
}
//先调用一次获取一级评论
await deeplist('')
//再遍历一级评论,传入一级评论_id和当前索引
for (let i = 0; i < temp.length; i++) {
await deeplist(temp[i]._id.toString(), i)
}
//返回最终的结果
return temp
},














 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









