






摘要:物联网(IoT)设备通过网络接口、网络 VPN 以及其他基于网络的服务提供便利,所有这些服务都依赖于 HTTP 协议。然而,这些暴露在外部的 HTTP 服务存在显著的安全风险。尽管模糊测试在识别物联网 HTTP 服务漏洞方面已显示出一定的有效性,但大多数现有的工具仍然依赖于随机变异策略,导致难以准确理解 HTTP 协议结构并生成许多无效的测试用例。此外,这些模糊测试工具依赖有限的初始种子集进行测试。虽然这种方法可以启动测试,但种子数量和多样性的有限性限制了对物联网 HTTP 服务复杂场景的全面覆盖。
在本文中,我们研究发现大语言模型(LLM)在解析 HTTP 协议数据和分析代码逻辑方面表现出色。基于这些发现,我们提出了一种新颖的基于 LLM 指导的物联网 HTTP 模糊测试方法——ChatHTTPFuzz,它能够自动解析协议字段并分析服务代码逻辑以生成符合协议的测试用例。具体来说,我们使用 LLM 对 HTTP 协议数据中的字段进行标记,创建种子模板。其次,LLM 分析服务代码以指导生成与代码逻辑一致的额外数据包,丰富种子模板及其字段值。最后,我们设计了一种基于探索平衡因子和变异潜力因子的增强型汤普森采样算法来调度种子模板。我们在 14 种不同的真实物联网设备上对 ChatHTTPFuzz 进行了评估,它发现的漏洞比 SNIPUZZ、BOOFUZZ 和 MUTINY 更多。ChatHTTPFuzz 共发现 103 个漏洞,其中 68 个是独特的,23 个已被分配 CVE 编号。
关键词:物联网,物联网模糊测试,大语言模型,漏洞,HTTP 协议
1 引言
物联网(IoT)技术正在迅速发展,以前所未有的方式改变着人们的生活和工作环境(Ezechina 等,2015)。截至 2024 年,全球有 170.2 亿台物联网连接设备,预计到 2030 年将达到约 300 亿台(Lionel Sujay,2024)。然而,物联网设备的这种指数级增长带来了显著的安全挑战。为了便于用户管理和使用,这些相互连接的设备提供了多种交互方式,其中最常见的是网络接口(Kumar 等,2016)。尽管网络服务提供了便利,但它们也引入了显著的安全风险。许多物联网设备在这一领域存在设计缺陷,隐藏着大量安全漏洞(Pourrahmani 等,2023;Lindsey O’Donnell,2020)。利用这些接口中的漏洞可能导致未经授权的访问、数据盗窃或远程代码执行(RCE)攻击(Noman 和 Abu-Sharkh,2023;Siwakoti 等,2023)。
对于这些物联网设备的安全分析,有许多研究方法。常用的安全漏洞检测技术包括静态分析、动态分析、二进制比较和模糊测试(Cui 等,2022)。随着软件规模和复杂性的增加,模糊测试在其他漏洞检测技术中展现出无与伦比的优势(Liang 等,2018)。
模糊测试作为一种有效的漏洞检测技术,在物联网设备的安全测试中发挥着关键作用。然而,由于 HTTP 协议的复杂性和物联网设备独特的软硬件特性,现有的模糊测试工具和方法在实际应用中仍面临诸多限制和挑战。HTTP 协议严格的结构要求模糊测试工具生成符合协议规范的测试数据。然而,许多现有的模糊测试工具在处理 HTTP 协议数据包时效率低下。例如,FirmAFL(Zheng 等,2019)和 Mutiny(Cisco,2017)等工具采用字节级变异方法,随机变异 HTTP 数据包的字节。尽管这种方法简单,但它会生成许多不符合协议标准的无效种子,无法从服务器获得有效响应,从而降低模糊测试的效率。Boofuzz(Jtpereyda,最后更新于 2024 年)和 Peach(peach,2011)等工具利用结构化的种子模板来规范变异过程,确保生成的数据更接近 HTTP 协议的要求。然而,这些工具严重依赖手动创建的种子模板,需要手动定义变异字段和类型。这种依赖经验的方法耗时且劳动密集,显著限制了在处理复杂或不熟悉协议时的自动化和适用性。此外,尽管 SNIPUZZ(Feng 等,2021)尝试通过结合响应信息推断测试用例的消息结构来提高字节级变异的效率,但这种方法在协议结构感知方面仍然效率低下。
针对物联网设备的先进黑盒和灰盒模糊测试工具主要集中在利用有限的反馈信息来指导模糊测试过程(Zheng 等,2019;Feng 等,2021),而对初始种子的获取和质量关注不足。例如,TriforceAFL(NCC-Group,2017)和 Firm-AFL 等工具专注于模拟或重新托管物联网固件以获取更多测试信息,提高模糊测试的效率和漏洞检测能力。Labrador(Liu 等,2024)在物联网设备的黑盒模糊测试中收集反馈信息,如代码覆盖率和距离,以指导测试过程。然而,如果初始种子集不足或缺乏代表性,即使有高效的反馈机制和优化策略,全面检测漏洞仍然具有挑战性。因此,获取和优化初始种子需要在先进的模糊测试方法中进行进一步研究。
在本文中,我们对大语言模型(LLM)(Minaee 等,2024)的能力进行了研究,发现 LLM 在解析 HTTP 协议字段时错误率为 0%,假阴性率仅为 4.74%。此外,在分析代码逻辑时,它们覆盖了 98.58% 的数据包字段。这些结果表明,LLM 具备出色的自动化解析能力,能够在无需人工干预的情况下实现协议感知的字段注释和后端代码分析。因此,我们提出了一种基于LLM的HTTP模糊测试方法。首先,利用 LLM 的协议解析能力识别 HTTP 协议数据中的合适变异点。其次,利用 LLM 的代码分析和协议生成能力生成与代码逻辑一致的数据包,从而提高种子的数量和质量。最后,我们设计了一种增强型汤普森采样算法,结合双重因素增益(探索平衡因子和变异潜力因子),高效地调度种子模板。具体来说,ChatHTTPFuzz 采用以下三种核心技术来解决物联网 HTTP 协议模糊测试的挑战:
LLM 指导的 HTTP 协议变量注释(LVA)技术:该技术用于克服协议结构分析的局限性。该方法使用预设的提示指令驱动大语言模型(LLM)准确注释 HTTP 协议数据中的变量。通过引入种子模板的概念,我们提高了种子质量并增加了变异的合法性,同时根据变量类型属性定义变异数据类型。在第 3.1 节的实验中,我们测试了 140 个构建的参数传递数据包。结果表明,LLM 在识别各种参数格式(包括 XML、JSON 和键值对)方面实现了零假阴性率。该技术有效地指导了模糊测试中的注释任务,显著提高了测试的准确性和效率。
LLM 指导的种子模板丰富(LSTE)算法:该算法用于解决获取初始种子来源有限的问题。该算法使用两种方法改进种子模板库:数据包扩展和字段值丰富。数据包扩展方法通过使用 LLM 解释静态分析的后端代码来生成新数据包,以应对没有相应路由代码的情况。字段值丰富方法通过分析后端代码中的字段处理逻辑(基于现有数据包和种子模板)提取变量字段的潜在值集。这两种方法使 ChatHTTPFuzz 能够基于代码语义创建更有效的种子模板,显著提高了种子质量。LSTE 算法不仅扩展了测试覆盖范围,还提高了模糊测试的效率和准确性,为发现潜在安全漏洞提供了更可靠的基础。
基于强化学习的双重因素增益种子模板调度算法(STSA):该算法用于解决种子调度的挑战。该算法通过引入变异潜力因子(Mfactor)和探索平衡因子(Efactor)增强了传统的汤普森抽样(Karamcheti等,2018),从而结合了启发式信息。Mfactor评估模板的潜在变异能力,使算法能够主动考虑模板在未来迭代中的价值。Efactor基于模板的使用历史,确保在决策过程中有效平衡探索和利用。这两个因素的结合考虑了历史性能,并平衡了对未来潜力和全局权衡的评估,从而实现了一种更高效、更平衡的选择策略。
我们实现了原型系统ChatHTTPFuzz,并在14种物联网(IoT)设备模型上进行了全面评估。实验结果表明,ChatHTTPFuzz显著优于三种先进的漏洞检测工具:Boofuzz(Jtpereyda,最后更新于2024年),一种基于模板的变异模糊测试工具;Snipuzz(Feng等,2021年),一种针对物联网的黑盒模糊测试工具;以及Mutiny(Cisco,2017年),一种高效的网络协议模糊测试工具。对比实验表明,ChatHTTPFuzz成功识别出14种IoT设备中的103个安全漏洞,是Boofuzz、Snipuzz和Mutiny检测到的漏洞数量的13倍。在这些漏洞中,68个是之前未公开的,其中23个获得了官方CVE编号。总的来说,本文做出了以下贡献:
- 我们提出了一种基于大语言模型的新型HTTP协议数据感知方法,用于自动标注协议变量数据、生成种子模板以及指导种子变异。相应地,我们还引入了一种用于丰富种子模板库的算法,以提高种子的质量和数量。
- 我们设计了一种创新的双重增益增强型汤普森采样算法(基于探索平衡因子和变异潜力因子),利用种子模板的信息来调度种子模板。
- 我们在14种不同的真实世界IoT设备上对ChatHTTPFuzz进行了评估。它识别出的漏洞数量超过了基线方法,发现了103个漏洞,其中59个是独特的,23个被分配了CVE编号。
本文的结构如下是:第2节深入探讨了HTTP协议和模糊测试技术,分析了LLM在模糊测试中的潜在应用和优势。第3节通过实验评估了LLM解析和生成HTTP协议的能力,展示了其在处理HTTP数据和解释服务器端代码方面的性能。基于这些实验结果,在第4节设计了ChatHTTPFuzz系统,利用LLM进行动态HTTP模糊测试,增强了数据解析、种子生成和调度优化的能力。第5节详细讨论了关键实现模块,重点关注系统的核心功能和架构设计。最后,在第6节中,对系统进行了全面的性能评估,通过多个指标(效率和漏洞检测)与最先进的解决方案进行了比较。
2 背景
首先介绍在物联网(IoT)环境中HTTP协议模糊测试的技术,并阐述与这种方法相关的关键挑战。随后,探讨了LLM的技术能力以及其应对这些挑战的动机。
2.1 HTTP协议模糊测试
在物联网设备的设计和实现中,由于其简单性和兼容性,开源的HTTP协议通常被用作网络服务接口。根据RFC 2616(《超文本传输协议》,1995年),HTTP协议在一份长达176页的文档中被严格定义(Kallus等,2024年)。HTTP协议模糊测试是一种通过向目标应用程序发送大量随机或格式错误的数据来发现漏洞和安全问题的技术。HTTP协议模糊测试要求模糊测试工具在生成测试数据时严格符合协议规范。对协议固定字段进行变异可能会导致许多无法解析的无效数据包,从而降低模糊测试的效率(Tsai等,2021年)。此外,如果初始种子的数量不足或与目标代码的预期字段不匹配,将难以测试服务中的更多功能和代码分支。
2.2 大语言模型
大语言模型(LLM)是基于深度学习的模型,通过海量数据和强大的计算资源进行训练。它们能够捕捉复杂的语言模式和结构,并在自然语言处理任务和文本生成方面表现出色(Brown等,2020年)。近年来,LLM的潜力已超出传统的语言处理领域,越来越多地应用于协议解析和代码分析等领域(Fan等,2023年;Jain等,2022年)。网络协议通常由RFC(征求意见稿)等标准文档定义,这些文档使用自然语言描述协议的各种细节。由于LLM是在海量自然语言数据上进行训练的,它们能够理解这些文档的语言和内容,并根据标准生成相关的协议内容,或解析协议中的复杂结构。此外,LLM可以通过自然语言提示理解代码意图,并自动生成代码片段(Du等,2024年)。LLM的高度自动化和智能化使其能够高效地处理复杂任务,还可以通过自然语言提示理解和执行各种任务。这些能力有可能解决物联网HTTP模糊测试中的开放性挑战。
2.3 LLM在模糊测试中的应用
一些现有工作已经将LLM应用于模糊测试。例如,GPTFuzzer使用人工编写的模板作为初始输入,并利用LLM通过变异生成新的模板。ChatAFL(Meng等,2024年)利用LLM解析RTSP协议,标记变量字段,指导变异过程,并预测协议序列。mGPTFuzz(Ma等,2024年)依赖LLM将超过千页的规范文档转换为机器可读格式,执行协议状态分析和生成。Fuzz4All(Xia等,2024年)利用LLM的代码分析能力,增强对“被测系统”(如编译器、运行时引擎、约束求解器和软件库)的模糊测试能力。这些模型帮助完成了许多传统上需要人类专业知识的复杂任务,并在相关研究中取得了显著成果,为解决物联网HTTP模糊测试中的挑战提供了新方法。在本文中,我们采取提示调整方法(Prompt Tuning,Chen等,2024年)来利用LLM指导HTTP协议模糊测试。
3 能力评估:大语言模型对HTTP协议模糊测试的影响
本研究开展了两项实验,以评估LLM在解析和生成HTTP协议方面的能力。第一个实验基于RFC HTTP 1.1协议规范,构建符合标准的HTTP数据包,并使用GPT-4o API(OpenAI,2024年)和预设提示进行解析和生成。专家手动审查生成结果,以评估其是否符合协议规范以及整体有效性。第二个实验聚焦于后端代码分析,使用GPT-4o API对目标系统的代码进行深入分析,并基于此分析生成新的HTTP数据包。这些生成的数据包随后被发送到目标网络服务,以验证参数解析的有效性。上述实验旨在系统性地评估大语言模型在HTTP协议解析和生成中的准确性和适应性。具体的提示序列和引导模糊测试的方法将在第4.1节和第4.2节中讨论。
3.1 字段识别:全面且精确的标注
本实验系统地考虑了HTTP协议的各种参数传输方法和类型。通过深入研究RFC 2616规范,我们精心设计并构建了140个具有代表性的参数传输数据包。为了确保准确性和多样性,研究团队投入了大量时间和精力验证每种传输方法和参数类型的正确性。
这些数据包根据传输方法被分为五大类:路径参数、查询字符串参数、请求体参数、头部参数和Cookie参数。此外,这些数据包还根据参数类型的差异被系统地划分为14个不同的子类别,如表1所示。在构建的140个参数数据包中,涵盖了14种最常遇到的传输方法。除了标准数据结构外,还引入了几种非标准的自定义数据结构,以确保测试过程的全面性和多样性。数据类型详细列于表2中。其中,类型1、2和3代表标准数据结构,类型5、6和7是自定义数据结构,类型8、9和10是复合数据结构。

表1:数据包中参数的类型

表2:不同数据结构的示例
本研究通过实验评估系统地分析了140个精心设计的参数传输数据包,采用定量分析方法,记录并比较了三个关键指标:每个数据包的原始参数数量、LLM成功解析的参数数量以及误识别的参数数量,还基于这些数据进一步计算了假阴性和假阳性率。这种多维度分析为评估GPT-4o API在HTTP协议解析中的性能提供了依据。
表3中的实验数据显示,GPT-4 API在HTTP参数解析方面表现出色。值得注意的是,在处理URL路径参数、键值对参数和JSON参数时,API达到了完美的准确性,假阴性和假阳性率均为0%。然而,在解析复杂的多部分表单数据时,API表现出一定的局限性,假阳性率分别为15.38%、18.87%和15.38%。这表明在处理高度结构化的表单数据时,API可能会错误地将非参数数据识别为变量。
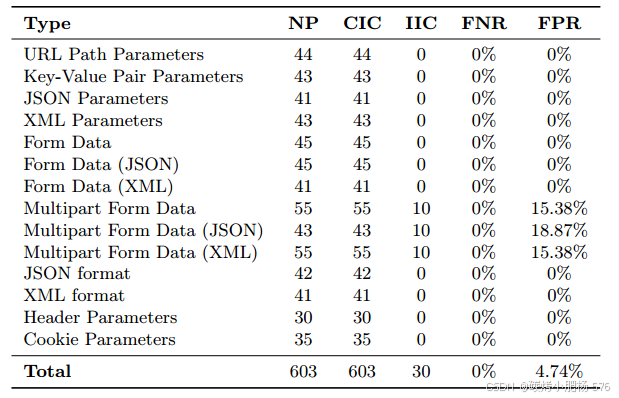
表3:参数识别和错误率(NP:参数的数量,CIC:正确识别的计数,IIC:错误识别的计数,FNR:假负率,FPR:假阳性率)
重要的是,GPT-4o API在处理自定义格式的参数方面表现出色,突显了其适应非标准数据结构的潜力。尽管在某些复杂场景中仍有改进空间,但GPT-4o API在HTTP参数识别和解析方面表现出色,具有出色的适应性。
3.2 数据包扩展:解析与生成
LLM的核心优势之一在于其卓越的代码处理能力,这源于其在训练过程中对海量代码的学习(Tufano等,2021年)。为了将LLM的代码解析和生成能力应用于HTTP协议模糊测试,本研究提出了两种扩展现有种子模板库的方法。第一种方法依赖于给定的代码片段及其对应的数据包,LLM通过分析代码的逻辑和字段名称生成数据包的扩展版本(称为类型0)。如果没有对应的数据包,第二种方法则利用提供的代码片段,让LLM生成完全符合代码逻辑的全新协议数据包(称为类型1)。

图1:LLM辅助数据包生成(图的上部包含数据包和代码,而下部仅包含代码,绿色部分中的代码是确定分支方向的关键)
如图1所示,第1部分展示了在给定数据包的情况下,LLM通过分析后端代码生成新数据包的过程。在传统模糊测试技术中,仅依赖数据变异无法将数据包中的动作字段设置为“del”,主要原因有两个:首先,原始数据包中不包含该字段;其次,模糊测试本身无法预测值“del”可能触发新的代码分支。然而,通过解析后端代码,LLM能够智能地识别关键输入参数,并预测不同参数值如何影响后端逻辑。因此,LLM可以生成针对性的数据包,例如动作为del,以触发删除操作的代码分支。第二部分展示了在只有代码的情况下,LLM通过分析字段解析和代码分支结构生成符合代码逻辑的一组数据包。LLM能够识别只能通过多个连续条件评估才能到达的深层逻辑分支。在这种情况下,LLM生成满足单一条件的数据包,并构建一系列输入值,以触发隐藏在复杂逻辑结构背后的代码执行路径。例如,在这段代码中,当v1=ST ATIC且v2=0时,需要进一步解析wizardstep4才能触发命令执行。
针对上述两种场景,我们为三种物联网(IoT)设备设计了以下实验。为每种设备选择了十个带有现有数据包的服务代码和十个没有数据包的服务代码。为了评估生成数据包的有效性,将生成的数据发送到相应的设备,并利用动态调试(gdb,最后更新于2024年)分析发送数据包中的变量值是否在代码级别被分配给相应的参数,这种方法能够帮助我们确定数据包生成的有效性。基于对三种设备的60个数据包的评估,表4中的实验结果显示,这些设备的平均字段识别率达到98.58%。
总之,本研究系统性地评估了LLM在HTTP协议解析、代码分析和协议生成方面的能力。通过测试涵盖各种参数传递方法和参数类型的140个数据包,结果表明LLM在识别和解析常见和自定义数据结构方面具有高准确性。此外,实验还证实了LLM在代码分析和协议数据生成方面的潜力。通过生成符合给定代码逻辑的数据包,LLM能够有效地扩展现有的种子库,提高模糊测试的效率并增加代码覆盖率。这些发现表明,LLM在网络协议测试和代码分析应用中具有很大的潜力。基于这些优势,我们的下一步是设计和实现一个名为ChatHTTPFuzz的系统,利用LLM进一步提升物联网HTTP协议模糊测试的智能化和自动化水平。
4 ChatHTTPFuzz的设计
在上述实验中,LLM展现出了卓越的协议解析和生成能力。为了应对IoT环境中HTTP服务模糊测试的挑战,本文提出了一种基于LLM技术指导的新型物联网设备HTTP协议模糊测试方法,即ChatHTTPFuzz。ChatHTTPFuzz通过利用先进的LLM能力,有效解决了字段识别和种子生成等关键问题。图2详细展示了ChatHTTPFuzz的工作流程。
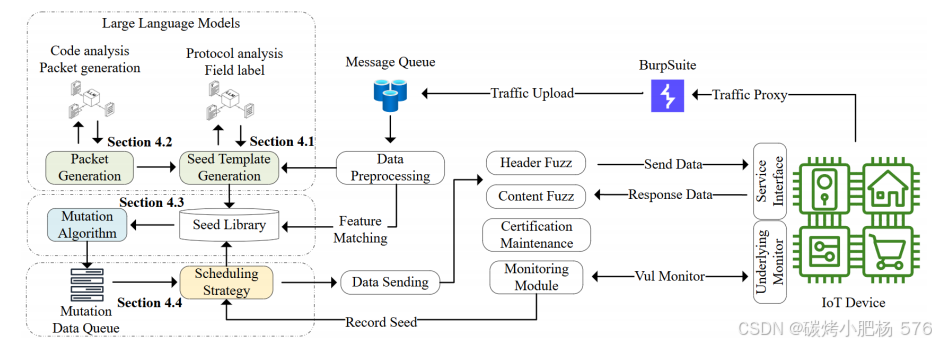
图2:ChatHTTPFuzz工作流程
为了将LLM应用于HTTP协议模糊测试,首先提出了一种利用LLM理解HTTP协议结构的方法(第4.1节)。还设计了一系列特定的提示,用于HTTP协议解析(第4.1.1节),以提高LLM在解析和标注任务中的准确性。此外,开发了一种种子模板结构,用于存储关键信息并指导变异过程(第4.1.2节)。利用LLM的代码解析和协议生成能力,结合静态代码分析和相关数据包,生成了更多符合后端代码逻辑的初始种子(第4.2节)。基于字段类型和变异空间(字段值集合),ChatHTTPFuzz变异种子模板以生成测试种子(第4.3节)。最后,通过分析服务器返回的有限响应内容,设计了一种基于双重增益的改进型汤普森采样种子模板调度算法,以平衡种子模板之间的探索和利用(第4.4节)。
4.1 基于LLM的HTTP协议结构感知
在本节中,我们将使用提示调整方法(Prompt Tuning),利用LLM标注请求数据中的模糊测试变量,并理解协议数据结构,从而更有效地指导变异过程。
4.1.1 基于LLM的HTTP协议变量标注
完整的HTTP协议由两个主要部分组成:请求头和请求体。虽然请求头不涉及复杂的数据结构,但它包含各种字段,使用现有规则准确识别和处理这些字段存在挑战。作为数据传输的核心,请求体通常包含复杂的数据结构和自定义格式的数据,增加了识别和解析的难度。为了提高LLM在协议中变量识别的准确性,我们采用以下方法增强LLM的能力。
在LLM中,“温度”参数调节生成文本的随机性。较高的温度会产生更具创造性和多样性的输出,而较低的温度则会产生更精确和稳定的结果。为了确保从事件中准确提取信息,我们通常将温度设置为0(Renze和Guven,2024年)。
为了提高任务的特定性和准确性,我们将完整的HTTP数据包分为两部分:请求头(Header)和请求体(Content)。针对每个部分的独特特性,设计了不同的提示,以指导LLM理解语法结构并产生期望的输出。图3展示了用于标记Header和Content的两个提示。Header提示引导模型关注超出协议格式的变量字段,而Content提示则专注于数据结构内变量的值。
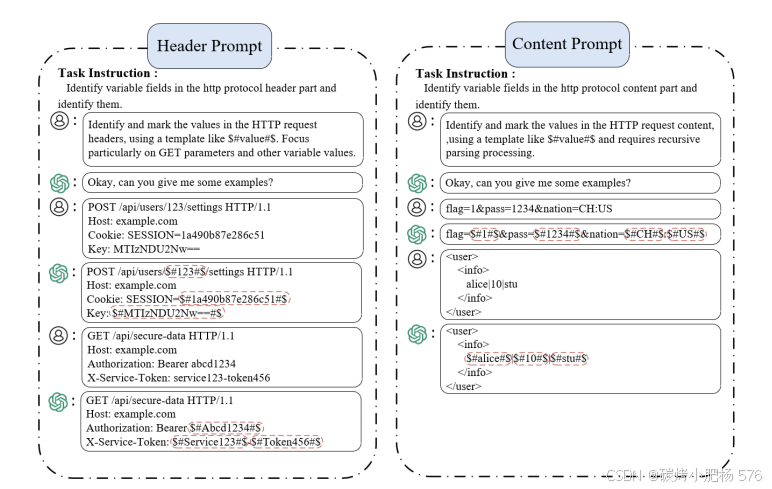
图3:数据包标记提示
为了进一步确保准确性和一致性,采用少量样本学习方法,使用多个问答示例,而不是依赖单个实例来澄清任务要求。这些示例指定了哪些字段符合标记条件,以及哪些是协议和数据结构中必须保持不变的基本组成部分。在提示和示例中,$##$符号标记了变量元素,作为生成种子模板的数据来源。
4.1.2 种子模板结构
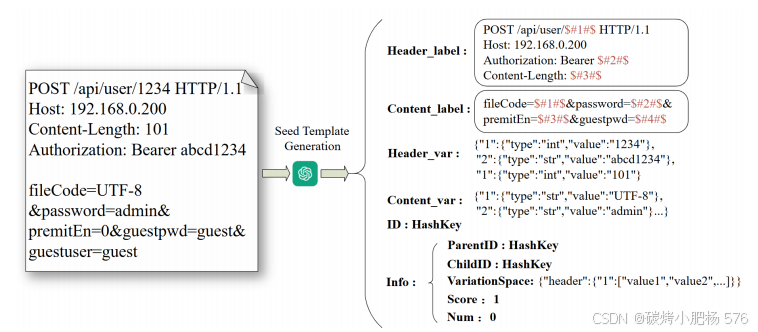
图4:种子模板构图
我们使用LLM解析的包信息生成种子模板。如图4所示,种子模板保留了HTTP协议的结构,同时提取了所有变量参数值。这些模板记录了与种子变异相关的信息,能够更有效地指导种子调度和变异过程。该结构主要存储以下信息:
头部和内容标注:在头部和内容数据中识别并标注变量,使用符号$##$将标注数据与原始HTTP数据分开。这种标注方法记录了模板中变量的确切位置,确保在变异过程中进行准确替换。
字段集:为了在变异过程中进行更有针对性的操作,字段集集中管理所有变量参数,指定每个字段的类型,如整数(int)、字符串(str)和特殊字符编码类型(例如Base32、Base64、URL编码)。
变异空间:为了充分利用LLM在模糊测试中的代码分析能力,我们为每个已识别的字段引入了一个变异空间,存储LLM推断出的潜在值分配。此结构将在第4.2.3节中用于扩展字段值,并在第4.3.2节中指导模糊测试器执行上下文感知的智能变异。
变异评分:通过记录每轮种子的评分,并根据响应内容和变异空间定期计算评分(第4.4节讨论),优先调度触发更多代码分支且评分更高的种子。
调用次数:跟踪每个种子模板的调用次数,以确保调用次数较少的模板获得更多测试机会。
4.2 基于LLM的种子模板扩展
在本节中,我们专注于通过两种主要方法扩展现有的种子模板库:丰富数据包和扩展字段值。利用静态分析和精心设计的提示分析关键代码片段和部分请求内容,以生成更多有效的种子模板和字段值。
4.2.1 静态分析预处理
在运行ChatHTTPFuzz之前,可以根据种子信息在运行时执行静态分析预处理和异步代码分析。具体来说,分析重点关注路由代码与后端代码之间的对应关系,这可以分为两种模式:
第一种模式是基于表的路由。这种方法使用一个集中的路由表或配置文件来管理所有路由信息。在这种结构中,每个URL路径都明确映射到一个特定的处理函数或控制器。例如,在以下代码中,Tenda设备使用add url函数统一注册全局路由信息。通过引用路由注册函数,可以确定与数据包对应的服务代码。

第二种模式是基于文件的路由。在这种方法中,文件系统的结构通常决定了URL路由。每个URL路径对应一个特定的文件,通常是CGI脚本或其他可执行文件。例如,Dlink-DNS使用基于文件的路由,代码根据其功能角色封装在不同文件中,每个路由对应一个CGI文件。

一旦确定了路由方法,使用IDA Python(Gergely Erdelyi,2004年)提取与路由信息相关的处理函数。然后将反编译后的代码以ChatHTTPFuzz配置的指定格式保存在配置文件夹中,完成静态分析预处理。
4.2.2 基于LLM的数据包生成
最初的捕获流量方法是通过实时页面访问来拦截数据包。尽管这种方法能够确保实时获取流量,但由于后端架构的复杂性,某些与特定后端服务相关的数据包可能无法通过前端直接访问。我们利用在第4.2.1节中提取的路由信息和代码来解决这些问题。借助LLM,生成新的请求数据包,并采用协议感知技术来解析协议,从而促进新种子模板的创建。
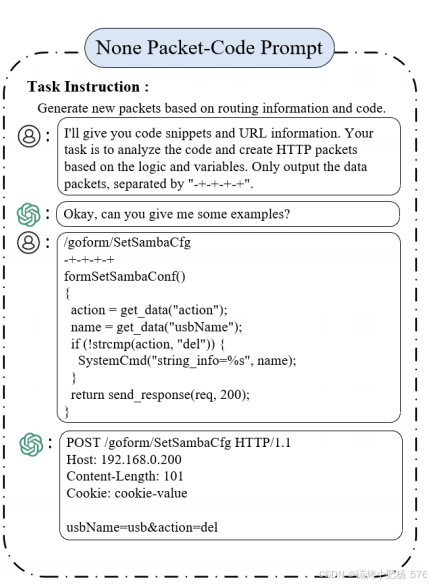
图5:数据包代码提示
图5描述了指导过程,该过程利用一系列提示,指导LLM按照指定格式解析URL和代码片段,使用“-+-+-+-+”作为分隔符以确保清晰和一致性。后端逻辑通常依赖于分配给不同字段的值,这些值触发特定的代码块,并需要特定的组合来激活更复杂的逻辑路径。为了全面覆盖各种执行路径,提示序列提供了精确的指令,使LLM能够生成多个符合代码逻辑的数据包。这种方法确保生成的数据包对应于系统的多样化逻辑分支,为后续测试和分析提供了广泛的支持。
4.2.3 基于LLM的字段扩展
对于包含请求数据包的路由,利用LLM确保字段值的多样性和准确性。这种方法能够生成符合代码逻辑的额外字段集合,称为“变异空间”,旨在评估未来种子变异的潜力。通过以下两种方法实现字段的扩展:
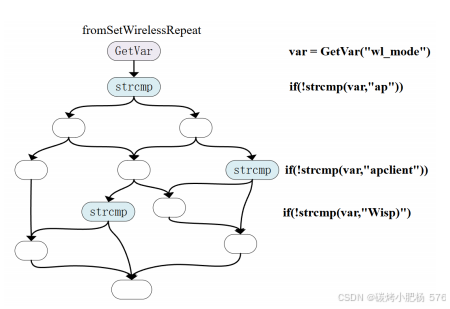
图6:物联网代码块
第一种方法是识别变量的可分配值集合。如图6所示,这段物联网设备的后端代码块使用GetVar函数从HTTP数据包中检索POST参数。这些参数通过strcmp(或类似函数)进行比较,代码根据结果分支。这种比较函数定义了参数的有效范围或可接受值。通过分析代码逻辑,LLM可以识别这些函数并提取相应的有效字符串集合。这一过程明确了可能的参数值,并生成符合逻辑的数据包,以确保测试数据触发预期的执行路径。我们分析了四种类型的设备,评估了30个后端代码样本中参数的潜在值集合。根据表5中呈现的结果,LLM在识别这些参数值集合方面的准确率达到97.17%。这一发现表明,LLM能够准确解释参数值的有效范围,为生成测试数据提供有效指导,确保变量赋值符合逻辑要求并成功触发预期的执行路径。

表5:不同物联网设备的现场价值识别率
第二种方法专注于确定特定的格式要求。LLM可以用于识别和扩展请求数据包中字段的格式要求。除了确保字段被赋予有效值外,某些参数在生成数据包时还必须严格遵循格式标准。这种格式识别和自动生成能力使ChatHTTPFuzz能够创建其他最先进的工具难以构建的复杂字段值,为发现零日漏洞提供了可能性。在本研究中,我们分析了几种设备的路由器代码,发现格式要求对于生成测试数据包至关重要。例如,以下代码片段展示了某些字段的严格格式约束:

如上述代码所示,变量v24、v25和v26是整数,必须遵循“%d”格式要求。同时,v22是一个字符数组,最大长度为80,需要“%s”格式说明。这些参数需要用冒号“:”分隔。此外,LLM可以识别和扩展特殊编码格式,如Base64、日期格式和IP地址格式,从而生成更符合现实世界标准的测试数据包。
ChatHTTPFuzz利用SeedTemplate结构存储通过上述方法获得的扩展字段集合,从而为种子变异提供更丰富、更精确的选择。例如,在Tenda物联网设备的fromSetWirelessRepeat函数中,字段扩展过程可以通过算法1实现。首先,GetSeedTemplate函数检索与特定URL相关联的种子模板对象。然后,通过迭代PotentialValues结构,调用SeedTemplate的add函数,将参数值添加到SeedTemplate结构中VariationSpace变量对应的变异列表中。

使用这种字段扩展算法,在fromSetWirelessRepeat函数中处理后,wl_mode参数支持多个值,包括ap、apclient和wips。
4.3 基于LLM的种子变异
随意变异HTTP协议的任意部分通常会导致生成大量格式错误的数据包。为了提高变异效率,我们在最初的设计阶段就整合了种子模板。种子模板识别并标记了HTTP数据包中可变的部分。ChatHTTPFuzz首先确定标记内容的类型,然后对不同字段应用针对性的变异。此外,它还结合了通过LLM从后端代码中提取的字段值进行进一步变异(详细内容见第4.4.2节)。我们还参考了Offutt提出的常见变异方法(Offutt等,1996年)。标记的字段会使用Radamsa工具进行额外的变异,引入更大的随机性和不可预测性,从而进一步多样化生成的种子数据。
4.3.1 基于类型的变异
对于数值数据类型的字段,变异操作符将值修改为边界或极端情况(例如,0、-1或极大的数字),以评估系统在极端条件下的行为。
对于使用特殊编码格式(如Base32、Base64或URL编码)的字段,本研究采用解码、变异然后再编码的过程。这种方法确保在测试过程中,无论编码格式如何,数据的完整性和准确性都能得到维护。
4.3.2 结合上下文内容的智能变异
ChatHTTPFuzz利用LLM和SeedTemplate结构智能地变异字段值,以实现更精确的测试并提高代码覆盖率。在这个过程中,LLM首先分析与HTTP数据包相关的后端代码,提取字段的实际使用情况和值集合(第4.2.3节)。然后,ChatHTTPFuzz基于VariationSpace变量进行针对性变异,该变量包含可能的后端字段值列表。
4.3.3 其他变异
处理特殊字符:在测试过程中,会替换常见编码格式(例如ASCII、Unicode、UTF-8、GBK)中的特殊字符,以及空字节(\0)、换行符(\n)、回车符(\r)和制表符(\t)。这些特殊字符可能会导致解析器出现意外行为,从而可能暴露隐藏的漏洞。
变异字典:为了提高测试效率,可以提前设置一个变异字典。该字典包含已知的利用载荷,这些载荷可以在变异测试期间随机选择。例如,可以包括针对命令注入、缓冲区溢出和整数溢出的载荷,以针对性地检测特定漏洞。
基于Radamsa的程序变异:Radamsa是一个强大的模糊测试工具,它以多种方式变异输入数据以生成测试用例。这些测试用例覆盖了广泛的边界条件和异常输入。
4.4 种子调度:基于双重增益的汤普森采样方法
种子调度是模糊测试中的一项关键技术,旨在通过智能选择和管理输入种子来优化测试结果,提高效率和代码覆盖率。在生成大量种子模板后,高效调度这些种子至关重要,以平衡“探索”和“利用”。这种平衡确保了种子更有可能触发新的代码分支,并且未测试的种子更有可能被选中。“探索”指的是测试尚未完全评估的种子模板,以收集更多信息并发现可能有效的模板。而“利用”则侧重于根据现有数据选择表现最佳的种子模板,以最大化即时收益。这种权衡反映了强化学习中多臂老虎机问题的核心挑战(Slivkins,2024年),其目标是优化探索和利用之间的平衡。
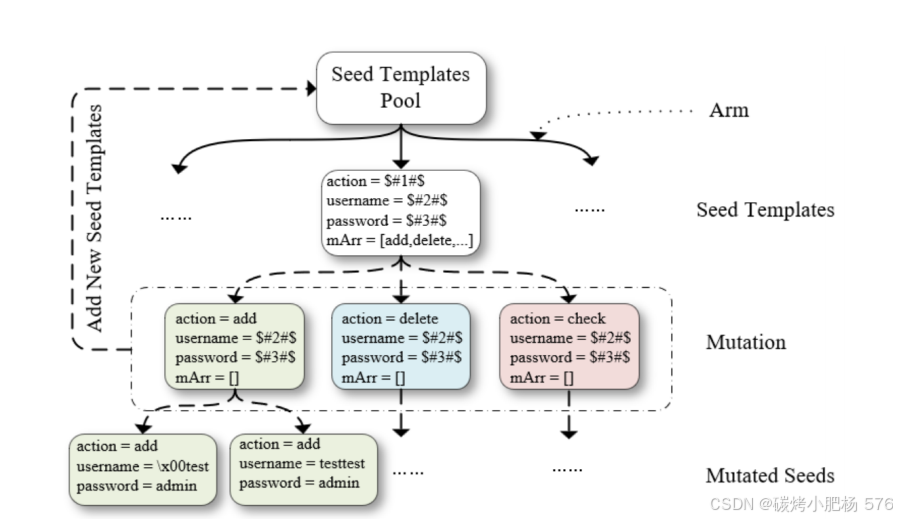
图7:种子模板关系结构
图7展示了种子模板的结构关系,种子模板库位于顶层。在每次使用时,系统利用模板调度算法从库中选择需要变异的模板,变异过程基于字段类型及其对应的变异空间进行,新生成的响应模板被存储回种子模板库。随着库中模板数量的增加,我们开发了一种针对种子模板结构量身定制的种子调度算法。该算法旨在提高模板选择的效率和逻辑性,确保随着库的增长实现最优利用。
本研究通过引入第4.2.3节中基于LLM指导的字段扩展技术生成的字段变异空间,对汤普森采样算法进行了创新性扩展。基于这种方法,我们提出了一种新颖的种子调度算法,旨在优化种子模板的利用。该算法通过多维度评估和动态平衡策略,实现对各种种子模板的改进管理和高效调度。
我们的方法优先考虑三类具有特殊价值的种子模板,以最大化它们的影响,并确保在调度过程中保持逻辑连贯性和系统性能的最优性。
- 历史上成功的变异模板:这些模板之前已经生成了有效的测试用例,成功触发了新的程序行为或发现了潜在漏洞,优先选择这些模板可以显著提高测试效率并增加漏洞检测率。
- 低频调用模板:这一类别包括由于各种原因在多次选择轮次中被忽视的模板,以及新添加到模板池中的模板,关注这些模板有助于保持测试的多样性和全面性。
- 丰富的变异空间模板:这些模板包含多个可变字段或复杂结构,提供了更广泛的探索可能性,优先选择这类模板可以扩大测试的覆盖范围和深度。
对于第一类,我们采用基于汤普森采样的种子选择算法。这种方法根据历史表现更新贝叶斯后验概率,平衡探索新的模板和利用之前成功的模板。对于第二类,我们使用探索平衡因子来针对调用频率较低的模板。这确保了系统不会忽视这些模板,尤其是新添加的模板。对于第三类,我们引入了变异潜力因子,该因子预测模板的未来表现潜力,增强测试的创新性和发现复杂漏洞的能力。
4.4.1 基于汤普森采样的种子选择算法
为了有效利用历史数据,我们采用了汤普森采样方法。这种方法通过动态更新贝叶斯后验分布来平衡探索与利用之间的权衡,从而提高决策的效率和准确性。假设N个种子模板的先验分布表示为πi![]() 。在第k轮中,模糊测试器收集反馈信息,表示为Infok = (s0k, s1k)
。在第k轮中,模糊测试器收集反馈信息,表示为Infok = (s0k, s1k)![]() ,其中s0k
,其中s0k![]() 表示尝试次数为0的奖励次数,s1k
表示尝试次数为0的奖励次数,s1k![]() 表示尝试次数为1的奖励次数(奖励表示成功触发新分支或发现漏洞)。根据每个模板在前k轮的表现,后验分布更新为π(θi | Infok)i∈(1,N)
表示尝试次数为1的奖励次数(奖励表示成功触发新分支或发现漏洞)。根据每个模板在前k轮的表现,后验分布更新为π(θi | Infok)i∈(1,N)![]() ,用于预测θi
,用于预测θi![]() 在下一轮的表现。
在下一轮的表现。
4.4.2 探索平衡因子
在种子模板选择过程中保持探索与利用之间的平衡对于确保模糊测试的有效性至关重要。为此,我们提出了一种新颖的探索平衡因子(EBF),以优化模板选择策略。该因子的核心理念是在优先选择调用频率较低的模板的同时,防止测试过程完全被极少使用的模板所主导。我们定义EBF如下:
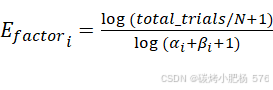 (1)
(1)其中,![]() 表示所有模板的总调用次数,N是模板总数,
表示所有模板的总调用次数,N是模板总数,![]() 和
和![]() 分别表示模板i的成功和失败调用次数。这种设计考虑了几个关键因素:首先,通过将模板调用次数
分别表示模板i的成功和失败调用次数。这种设计考虑了几个关键因素:首先,通过将模板调用次数![]() 放在分母中,建立了
放在分母中,建立了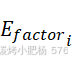 与调用频率之间的反比关系,从而优先选择较少使用的模板。其次,使用对数函数可以有效平滑极端值,防止调用次数极低的模板过度主导选择过程。最后,分子中引入的
与调用频率之间的反比关系,从而优先选择较少使用的模板。其次,使用对数函数可以有效平滑极端值,防止调用次数极低的模板过度主导选择过程。最后,分子中引入的![]() 允许该因子随着测试过程的进展动态调整。通过引入这一因子,我们的算法为调用次数较少的模板分配了更高的选择概率,从而促进了对未充分测试区域的探索。
允许该因子随着测试过程的进展动态调整。通过引入这一因子,我们的算法为调用次数较少的模板分配了更高的选择概率,从而促进了对未充分测试区域的探索。
4.4.3 变异潜力因子
变异潜力因子是我们算法中评估种子模板潜在可变性的关键指标。该因子通过比较当前模板每个字段的可能值集合的对数比与所有模板的最大值集合来衡量模板的潜在变异空间。计算公式如下:
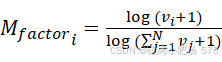 (2)
(2)分子表示当前模板的变异潜力,而分母表示所有模板中的最大潜力。![]() 表示当前模板i的变量字段集合的大小,
表示当前模板i的变量字段集合的大小,![]() 表示所有模板的变量字段集合的总和。
表示所有模板的变量字段集合的总和。
使用对数比可以防止字段较多的模板主导选择过程(例如,一个模板可能有数百个可能值,而另一个模板只有几个)。![]() 表示模板在未来测试中可能贡献的潜在价值。较高的
表示模板在未来测试中可能贡献的潜在价值。较高的![]() 值表明,尽管当前模板的奖励可能不是最高的,但与其他模板相比,它仍有很大的改进空间和潜在价值。特别是在长期模糊测试过程中,变异潜力因子有助于算法避免陷入局部最优,并继续探索可能导致突破性发现的模板。
值表明,尽管当前模板的奖励可能不是最高的,但与其他模板相比,它仍有很大的改进空间和潜在价值。特别是在长期模糊测试过程中,变异潜力因子有助于算法避免陷入局部最优,并继续探索可能导致突破性发现的模板。
4.4.4 集成
在本研究中,我们提出了一种新颖的双重增益汤普森采样方法,以优化种子模板的选择和调度过程。通过引入变异潜力因子(![]() )和探索平衡因子(
)和探索平衡因子(![]() ),该方法在保留传统汤普森采样固有优势的同时,增强了启发式信息的利用,从而形成了一种更高效、更平衡的模板选择策略。
),该方法在保留传统汤普森采样固有优势的同时,增强了启发式信息的利用,从而形成了一种更高效、更平衡的模板选择策略。
我们的核心创新在于动态增益机制的设计,该机制利用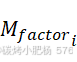 和
和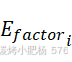 调整和放大传统的汤普森采样结果(
调整和放大传统的汤普森采样结果(![]() ),从而扩展了决策过程中考虑的维度。具体来说,
),从而扩展了决策过程中考虑的维度。具体来说,![]() 评估模板的潜在变异能力,使算法能够主动考虑某些模板在未来迭代中的潜在价值。而
评估模板的潜在变异能力,使算法能够主动考虑某些模板在未来迭代中的潜在价值。而![]() 则基于模板的历史使用情况,在决策过程中确保探索与利用之间的有效平衡。这两个因素的综合效应使得决策过程能够考虑历史表现(由
则基于模板的历史使用情况,在决策过程中确保探索与利用之间的有效平衡。这两个因素的综合效应使得决策过程能够考虑历史表现(由![]() 表示),并兼顾未来潜力和全局平衡。
表示),并兼顾未来潜力和全局平衡。
具体的集成方法如下:
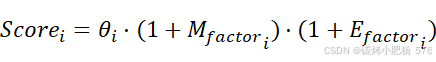 (3)
(3)
我们在设计增益机制时选择将这些因素与乘法而不是加法结合。这种选择创建了一个非线性增益机制,能够更准确地捕捉因素之间的复杂相互作用,特别是在极端情况下。例如,当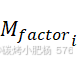 或
或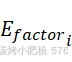 的值较高时,它们会放大
的值较高时,它们会放大![]() 的影响,增加某些模板的选择概率。相反,当这些因素接近零时,它们对原始汤普森采样结果的影响最小,确保了算法的基本稳定性。
的影响,增加某些模板的选择概率。相反,当这些因素接近零时,它们对原始汤普森采样结果的影响最小,确保了算法的基本稳定性。
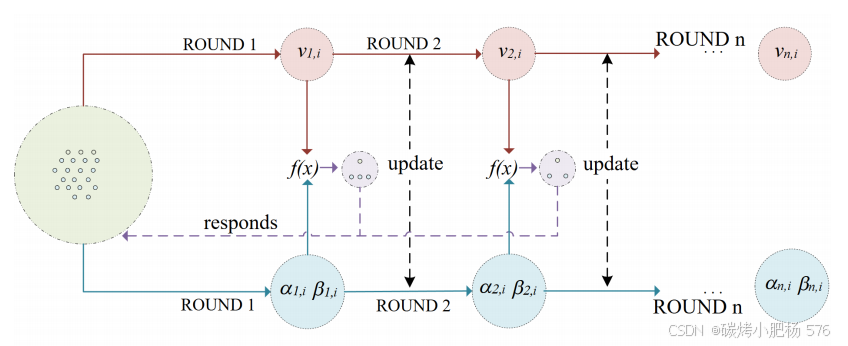
图8:两因素增益种子选择算法

实施过程如图8和算法2所示。在每次迭代中,首先计算每个种子模板的关键指标,包括字段值集合的大小(v)、正反馈次数(α)和负反馈次数(β)。这些指标通过设计的评分公式为每个模板生成一个综合评分。然后,算法从种子池中选择评分较高的模板进行进一步变异,并将这些变异后的模板用于测试。在测试过程中,触发的新响应和发现的潜在漏洞等反馈信息会更新到种子池中,以优化下一次迭代的决策,形成一个动态的闭环优化系统。
5 实现
我们开发了ChatHTTPFuzz的原型系统,包含大约2000行Python代码,并辅以超过100行Java代码用于Burp Suite插件。为了提高处理效率和系统可扩展性,我们在模型设计中实现了异步架构。这种架构允许系统模块独立执行其功能,优化整体性能和响应时间。高速消息队列促进模块间的数据传输,确保数据处理的专注性和高效性。此外,系统架构分为以下核心模块,以支持高效的数据处理和任务执行:
流量捕获与分析:在流量获取的初始阶段,使用Burp Suite插件拦截并上传所有访问物联网设备网页的流量到消息队列,确保实时数据捕获。该模块分析流量特征,以确定是否需要生成新的种子模板。
基于LLM的协议感知与种子模板生成:LLM用于解析HTTP协议结构,识别并标记协议中的关键变量,生成具有明确定义的变量结构和类型的种子模板。这些基于LLM感知的种子模板在模板编译器模块中至关重要,能够更有效地指导种子调度和变异。
基于LLM的种子模板扩展:ChatHTTPFuzz对后端服务代码进行静态分析,提取路由信息和请求参数名称,这是为不同路由扩展现有数据包和字段值的基础。这种方法遵循后端服务代码的逻辑分支,生成更多能够触发特定行为的种子模板,从而增强模糊测试的广度和深度。
模板变异器:变异器基于种子模板执行变异,结合随机和基于规则的方法,根据变量的类型和上下文内容进行变异。变异策略详细内容见第4.4节。
基于反馈的调度策略:该策略利用种子的响应内容来判断是否触发了新的代码路径,并采用强化学习算法平衡探索和利用。在探索阶段,重点关注未充分测试的种子模板,而在利用阶段,优先选择表现最佳的模板。该策略动态更新每个种子模板变异的成功和失败次数,并使用Beta分布分数量化其有效性,优化信息利用并指导后续调度决策。
认证维护:由于大多数物联网设备代码需要认证才能访问,ChatHTTPFuzz持续监控会话令牌的有效性,并在必要时更新,以确保会话保持活跃,最大化后端服务代码的测试覆盖率。
异常监控:为了检测各种异常,如命令注入和缓冲区溢出,ChatHTTPFuzz为每种类型实现了专门的检测策略。对于命令注入,每个变异的数据包将一个唯一的种子模板标识符嵌入到要执行的命令中。物联网设备的检测代码将执行的命令与种子模板相关联。对于缓冲区溢出检测,每个测试连接捕获“连接重置”异常,这通常表明内存损坏漏洞导致服务中断,服务器断开连接时出现该异常。
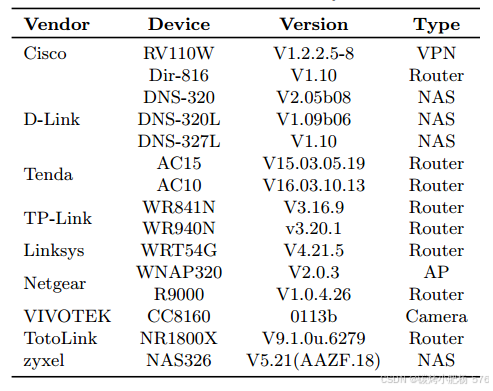
表6:供应商的设备信息
6 实验与评估
在本节中,我们通过在物联网设备上进行实际测试,从多个指标评估ChatHTTPFuzz的性能,并与其他工具进行对比分析。
6.1 实验设置
主机和设备配置:ChatHTTPFuzz部署在Ubuntu 22.04操作系统上,配备Intel Core i9-12900KF 3.20 GHz CPU和8GB内存。
物联网设备:我们在多个主流品牌上进行测试,包括Cisco、D-Link、TP-Link、Linksys、VIVOTEK和Netgear,重点关注它们的路由器、网络存储设备、VPN和防火墙(具体测试产品列表见表6)。选择这些设备的标准包括品牌的市场影响力、设备的使用数量以及其网络服务功能的多样性和覆盖范围。为了确保测试的全面性和代表性,我们选择了8款来自知名品牌的商用级设备(如Cisco、TP-Link、D-Link和Netgear),主要涉及与网络和安全服务相关的路由器、防火墙、VPN和摄像头。
工具对比:我们对ChatHTTPFuzz与其他黑盒模糊测试工具(如Boofuzz、Snipfuzz和Mutiny)进行了性能对比实验。这些工具各有其独特优势,具体的选型原因和对比实验细节见第6.3节。
LLM配置:本研究中使用的LLM基于GPT-4o API。与其他LLM相比,GPT-4o在文本生成性能方面通常表现出色,尤其是在生成质量和上下文理解方面。GPT模型中的模板参数对生成文本的创造性有显著影响。我们通常将温度参数设置为零,以确保从事件中提取信息的准确性。这种配置有助于最小化噪声干扰,提高信息提取的精确性。
手动配置:为了确保会话保持活跃,每种类型和版本的设备都必须获取会话验证数据包和登录数据包。为了高效利用LSTE(基于LLM的种子模板扩展)功能,需要使用IDA Python脚本对后端程序进行逆向工程,以获取代码和路由信息,然后将其提供给LSTE接口。
6.2 ChatHTTPFuzz测试
从上述15种不同的物联网设备型号中,我们随机选择了4种设备,并提前准备了针对每种设备的请求数据包进行测试。为了评估在ChatHTTPFuzz中引入LLM以指导种子模板生成和扩展技术(LSTE)以及种子模板调度策略(STSA)对漏洞发现效果和效率的影响,我们开发了三种对比实验模型:ChatHTTPFuzz-NoLSTE、ChatHTTPFuzz-NoSTSA和ChatHTTPFuzz-NoLSTE-NoSTSA。所有这些模型都保留了LLM的感知能力,因为没有生成种子模板的能力就无法进行测试。
对漏洞发现的影响:通过利用LLM扩展种子模板库,ChatHTTPFuzz系统增强了对后端代码逻辑的理解,能够生成更多符合逻辑的种子模板,从而发现更多漏洞。如图9所示,ChatHTTPFuzz与ChatHTTPFuzz-NoLSTE在各种物联网设备上发现的漏洞总数存在显著差异。具体来说,在四种设备上,ChatHTTPFuzz平均发现的漏洞数量是ChatHTTPFuzz-NoLSTE的2.38倍(57个漏洞对比24个漏洞)。
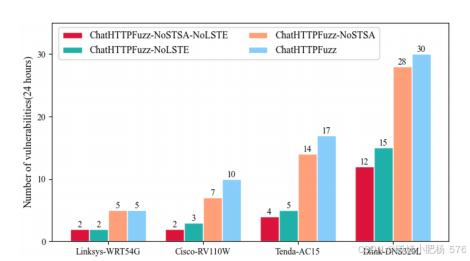
图9:由不同版本的ChatHTTPFuzz检测到的漏洞数量
种子模板调度技术对ChatHTTPFuzz系统的漏洞检测能力影响相对较小。如图9所示,ChatHTTPFuzz-NoSTSA与ChatHTTPFuzz发现的漏洞数量没有显著差异。尽管种子调度技术在优先选择种子模板方面发挥着关键作用,但随着时间的推移,其对发现漏洞数量的影响逐渐减弱,最终变得可以忽略不计。
在实际测试中,我们观察到种子模板的数量对漏洞检测效率有显著影响。为了进一步验证这一观察结果,我们设计了一个实验,重点关注两种设备:Tenda-AC15和Linksys-WRT54G。在24小时的测试期间,我们每4小时应用一次LSTE技术来扩展现有的种子模板库,同时持续监测触发的漏洞数量。实验结果如图10所示。
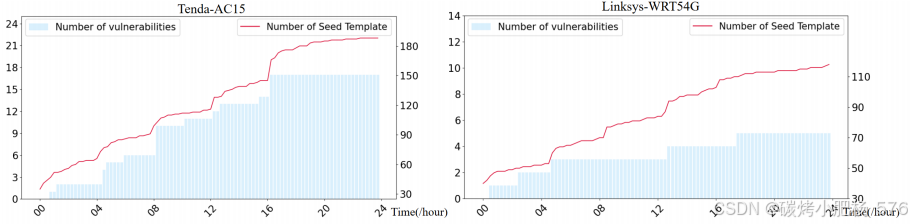
图10:种子模板和漏洞在24小时内计算统计
图10所示的实验结果表明,每次应用LSTE技术都会显著增加种子模板的数量,并伴随着检测到的漏洞数量的快速上升。
对漏洞检测效率的影响:通过比较ChatHTTPFuzz-NoSTSA和ChatHTTPFuzz在24小时内的漏洞检测时间,结果表明引入STSA技术显著提高了检测效率,并在一定程度上增加了检测到的漏洞数量。我们在实验中最初使用了LSTE技术来扩展现有的种子模板库。在随后的模糊测试阶段,我们没有使用LSTE技术,以防止其对实验结果产生潜在干扰。
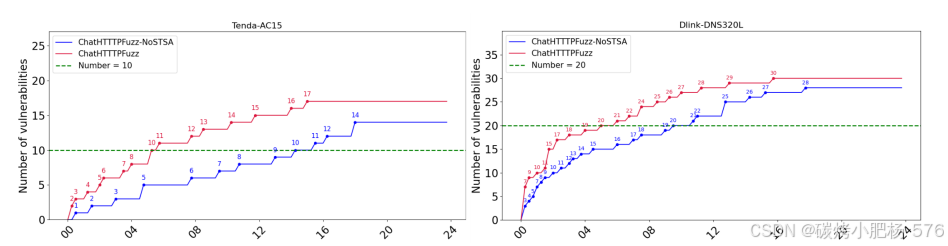
图11:STSA对漏洞检测效率的影响
图11所示的实验结果表明,与ChatHTTPFuzz-NoSTSA相比,ChatHTTPFuzz将发现相同数量漏洞的时间缩短了一半。这一改进归功于STSA技术,它提高了种子模板调度和选择的效率。
6.3 与其他工具的对比
目前,用于物联网设备的模糊测试工具种类繁多,包括近期的研究成果如mGPTFuzz、LABRADOR和Snipuzz,以及早期的基准工具如Boofuzz和Mutiny。其中,mGPTFuzz专门用于测试物联网设备中的Matter协议,该协议用于连接智能家居系统(Zegeye等,2023年)。由于LABRADOR尚未开源,因此未包含在本研究中。最终选择用于实验的工具如下:
Boofuzz:作为著名的Sulley模糊测试框架的分支和继承者,Boofuzz专门用于协议模糊测试,提供了强大的支持,并在实际应用中展示了其识别各种漏洞的有效性。
Snipuzz:这是一款为物联网设备量身定制的黑盒模糊测试工具。通过分析测试响应来优化消息变异,显著提高了错误检测效率。与传统的Doona Marcussen(2024年)和IoTFuzzer(Chen等,2018年)等工具相比,Snipuzz在实际测试中表现出色,突显了其在安全漏洞检测方面的优势。
Mutiny:由Cisco研究人员开发的开源模糊测试工具,采用基于变异的方法进行测试。它通过重放网络流量来执行变异模糊测试,极大地简化了测试过程,提高了便捷性和效率。此外,Mutiny的设计使其成为进行复杂网络协议测试的理想选择,能够有效支持广泛的模糊测试应用。
为了展示LLM在理解协议格式和选择变异点方面的性能差异,我们比较了Mutiny和Snipuzz等工具的变异有效性。我们设计了一组具有各种参数格式的HTTP数据包作为测试基础。实验分为两组:第1组使用ChatHTTPFuzz进行1000次变异测试,评估变异点的选择和有效性;第2组使用Mutiny和Snipuzz等工具对相同的数据包进行1000次测试,以便进行对比分析。

图12:突变位置统计
实验结果如图12所示,每个代码块代表模糊测试工具在HTTP数据包中选择的变异点。块的颜色深浅反映了变异频率——颜色越深表示变异发生次数越多。结果表明,ChatHTTPFuzz在协议解析和变量识别方面具有明显优势。具体来说,与其他工具相比,ChatHTTPFuzz更准确地避免变异固定的协议元素(例如HTTP/1.1、\r\n),这些元素可能会破坏数据包的完整性并阻碍解析。此外,ChatHTTPFuzz在处理复杂变量结构方面优于Mutiny和Snipuzz等工具,通过智能识别变量边界和结构,实现更有针对性的变异,从而提高漏洞检测能力。
ChatHTTPFuzz与Boofuzz的对比:在比较ChatHTTPFuzz和Boofuzz时,我们的目标是评估LSTE(基于LLM的种子模板扩展)技术对其他工具漏洞发现能力的影响。为此,我们在Boofuzz实验中尽可能广泛地应用LSTE技术。LSTE通过利用LLM的能力,提高了种子生成的质量,生成更多符合业务逻辑的种子。传统的Boofuzz工具严重依赖手动标注需要变异的字段,并且无法根据反馈调度种子。在测试五种设备和七种固件模型时,它仅检测到六个公开披露的CVE漏洞。然而,增强LSTE技术的Boofuzz(即Boofuzz-LSTE)在漏洞发现方面表现出显著优势;使用标记的种子,发现的漏洞数量是传统Boofuzz的四倍多。尽管如此,由于Boofuzz缺乏针对命令注入的变异方法,它仍然未能发现Dlink DNS320L中的命令注入漏洞。
ChatHTTPFuzz与Snipuzz的对比:与主要通过推断消息片段并根据响应差异优化变异策略的Snipuzz不同,ChatHTTPFuzz利用响应变化和代码上下文信息更智能地指导变异过程和种子调度。作为一种黑盒模糊测试工具,Snipuzz缺乏对代码的深入理解,其在变异过程中逐字节确定字符串的方法通常会产生大量冗余数据。此外,Snipuzz在变异过程中未能充分考虑多种类型的漏洞,限制了其漏洞发现能力。表8展示了ChatHTTPFuzz和Snipuzz在漏洞发现能力方面的差异。

表8:不同物联网设备的发现漏洞时间比较
ChatHTTPFuzz与Mutiny的对比:Mutiny主要依赖Radamsa变异器。然而,作为通用变异器,Radamsa并未充分考虑输入数据的上下文和结构信息,这可能导致生成的测试用例缺乏针对性,最终降低模糊测试的效率。此外,Radamsa的随机变异策略通常会产生大量无效输入,这不仅增加了测试时间和成本,还阻碍了高质量测试用例的创建,从而限制了其对新漏洞发现的贡献。如表7所示,在相同的测试时间内,Mutiny与ChatHTTPFuzz在漏洞发现能力方面存在显著差距。
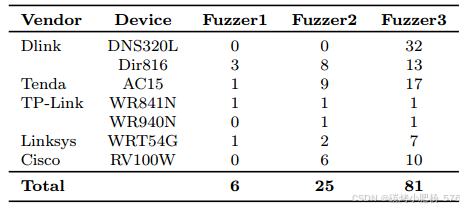
表7:不同物联网设备的模糊测试工具对比(Fuzzer1:Boofuzz,Fuzzer2:Boofuzz-LSTE,Fuzzer3:ChatHTTPFuzz)
以下是ChatHTTPFuzz只能发现部分漏洞的原因:
- 多种类型漏洞的检测:ChatHTTPFuzz配置了多种漏洞检测模块,包括缓冲区溢出、命令注入、文件读取以及Base64编码的变异机制。在测试过程中,它成功识别了CVE-2019-20760漏洞,这是其他工具未能检测到的。此外,在对D-Link DNS设备的测试中,ChatHTTPFuzz发现了30个类似的漏洞,包括CVE-2024-7922、CVE-2024-8130和CVE-2024-8131,这些漏洞同样未被其他工具检测到。
- 需要上下文信息的漏洞:某些漏洞只能在特定上下文条件下被利用。例如,Tenda AC15设备中的CVE-2024-2855漏洞只有在timeType值被手动设置时才会被触发。然而,timeType的初始值是sync,需要深入分析代码逻辑才能找到手动赋值的情况。同样,D-Link DNS-320L设备中的CVE-2024-7715漏洞只有在type参数被设置为photos时才会被触发。如果没有先进的LSTE技术的支持,这些漏洞很难被触发。
- 需要特殊变异机制的漏洞:为了应对变异分析中各种编码格式带来的挑战,ChatHTTPFuzz纳入了对常见编码格式(如十六进制、Base64和URL编码)的解析和封装机制。这一能力使其能够识别并针对这些编码格式内的内容进行模糊测试。ChatHTTPFuzz已成功利用这种方法识别了多个漏洞,包括CVE-2019-20760、CVE-2024-7439和CVE-2024-41281。
6.4 漏洞发现
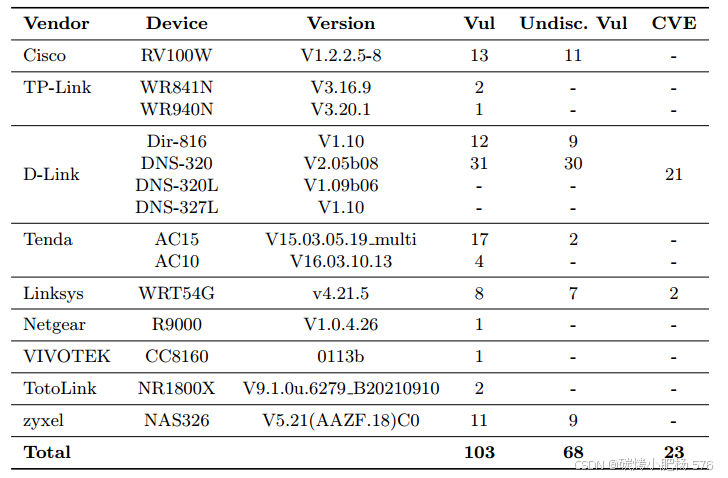
表9:不同物联网设备的漏洞发现统计
如表9所示,ChatHTTPFuzz成功识别了八种不同型号物联网设备中的92个安全漏洞,其中59个是之前未公开的。这些漏洞已向相关厂商报告并得到确认。目前,其中22个漏洞已被分配了官方CVE标识符。
ChatHTTPFuzz识别出的漏洞主要分为命令注入(CI)和内存损坏。命令注入是一种高风险的逻辑漏洞,可以通过特定的攻击技术导致远程代码执行(RCE)。与内存损坏漏洞相比,它通常更为稳定。ChatHTTPFuzz在测试的物联网设备中发现了31个命令注入漏洞,其中17个(包括CVE-2024-7828)根据CVSS V3标准被评为高危漏洞。
由于物联网设备通常计算能力有限,且通常简化了堆栈数据处理,内存损坏已成为这些设备中最常见的漏洞类型之一。我们在Cisco产品中发现了10个可能导致拒绝服务(DoS)或远程代码执行的栈溢出漏洞。然而,由于这些产品已处于生命周期末期(EOL),无法为其分配CVE标识符。此外,在Linksys产品中,我们发现了7个内存损坏漏洞,包括CVE-2024-41281,可能影响设备的稳定性和控制。总体而言,ChatHTTPFuzz在六种不同的物联网设备中发现了32个内存损坏漏洞。
总之,在22个已确认CVE的漏洞中,4.54%为中危,13.64%为高危,81.82%被归类为严重漏洞。结果如表10所示。
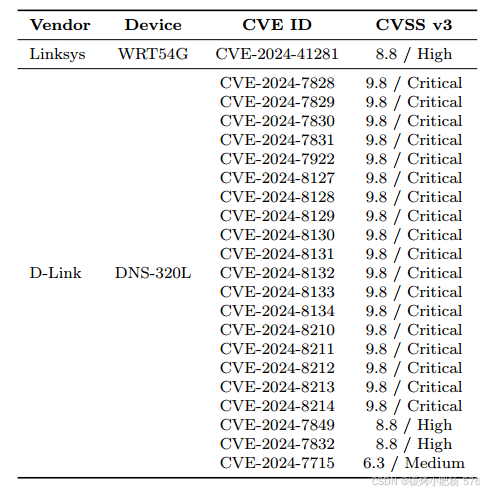
表10:CVE漏洞及其CVSS V3分数
7 相关工作
7.1 黑盒模糊测试
目前,黑盒模糊测试是检测物联网设备安全性的主要方法之一。然而,现有方法存在各种局限性。例如,Boofuzz依赖于经验生成的协议数据包模板,导致人力成本较高。Mutiny通过重放网络流量进行基于变异的模糊测试,减少了人工干预的需求,但也失去了识别协议字段的能力。Snipuzz通过分析响应内容推断请求数据的字段格式,提高了变异效率,但降低了数据理解的精确性,导致大量无效种子的产生。
总体而言,物联网中的黑盒模糊测试的局限性在于缺乏对协议格式的解析和对代码行为的深入理解,这使得种子的变异和选择不够有针对性。
7.2 灰盒模糊测试
在灰盒模糊测试中,代码覆盖率是指导种子选择和变异的关键因素。然而,物联网设备依赖多个硬件组件才能正常运行,这使得代码覆盖率的获取变得复杂。因此,许多先进的研究方向转向使用仿真和硬件支持技术来获取内部的覆盖率信息。
TriforceAFL利用QEMU(Bellard,2024年)的全系统仿真技术启动并运行固件,同时整合AFL算法收集并反馈代码覆盖率。然而,全系统仿真存在显著的性能瓶颈,严重影响模糊测试效率。为了解决这一问题,FIRM-AFL从TriforceAFL继承了全系统仿真概念,并通过整合Firmadyne(Tufano等,2021年)物联网仿真器与QEMU用户模式,实现了系统仿真和用户模式仿真之间的切换。这种混合仿真策略有效提高了运行效率,使FIRM-AFL成为一种高吞吐量的覆盖率引导模糊测试(CGF)工具。
ChatHTTPFuzz采用非侵入式方法,利用LLM深入理解协议结构和后端代码。这种理解指导种子的生成和变异,从而能够全面测试所有物联网设备的网络服务。
7.3 其他工作
随着LLM的兴起,模糊测试正在经历新一轮的变革。LLM在代码解析、协议分析和文本生成方面展现出令人印象深刻的优点,其在物联网和网络协议中的应用逐渐增加,并逐渐与传统模糊测试技术相结合。ChatAFL(Meng等,2024年)将LLM与传统的AFL(American Fuzzy Lop)模糊测试工具相结合,利用LLM生成更多样化的输入数据,从而提高覆盖率和漏洞发现效率。mGPTFuzz(Ma等,2024年)基于GPT模型,利用自然语言处理能力理解并生成测试数据,能够自动生成复杂协议的测试用例,显著减少人工干预对协议结构的需求。该工具还根据测试结果的反馈调整输入生成策略,显著提高测试效率和准确性。LLMIF(Wang等,2024年)利用大语言模型识别和理解网络协议中的关键字段,生成针对性的模糊测试输入,并为Zigbee协议(Ramya等,2011年)设计了高效的模糊测试模型。
ChatHTTPFuzz是专门为物联网(IoT)环境中的HTTP协议模糊测试而设计的专用工具。与先进技术类似,它利用LLM的强大能力来增强协议解析、种子生成和变异策略。通过全面理解协议的复杂性,ChatHTTPFuzz生成更精确的测试数据,提高了漏洞检测的效率,尤其是在复杂的HTTP协议环境中。
8 结论
在本研究中,我们提出了ChatHTTPFuzz,这是一个基于LLM的物联网设备HTTP协议模糊测试框架。它利用LLM标注数据字段、构建结构化的种子模板,并识别适合变异的位置。随后,它分析服务代码逻辑以生成匹配的数据包,提升种子的质量和数量,并扩展现有模板和字段值的变异空间。最后,引入了基于双重增益的模型,并与改进型汤普森采样算法相结合,实现种子模板的智能调度,显著提高了模糊测试的效率。
我们在市场上9家领先厂商的14种设备型号上进行了测试。结果表明,ChatHTTPFuzz在漏洞发现能力方面显著优于现有的最先进的工具,如Boofuzz、Snipuzz和Mutiny。ChatHTTPFuzz成功识别出6种不同设备型号中的68个零日漏洞,包括命令注入和内存损坏漏洞。其中,23个漏洞已被正式分配了CVE编号。
致谢
本研究得到了国家自然科学基金(项目编号62322202和62432006)、中国中央政府指导下的河北省地方科技发展基金(项目编号246Z0102G)、河北省自然科学基金(项目编号F2024210008)以及广东省基础与应用基础研究基金(项目编号2023B1515120020)的支持。
参考文献
[1]Bellard F (2024) qemu/qemu. Available at: GitHub - qemu/qemu: Official QEMU mirror. Please see https://www.qemu.org/contribute/ for how to submit changes to QEMU. Pull Requests are ignored. Please only use release tarballs from the QEMU website.
[2]Brown TB, Mann B, Ryder N, et al (2020) Language models are few-shot learners. In: Proceedings of the 34th International Conference on Neural Information Processing Systems.Curran Associates Inc., Red Hook, NY, USA, NIPS ’20, pp 1877–1901
[3]Chen B, Zhang Z, Langren´e N, et al (2024) Unleashing the potential of prompt engineering in large language models: a comprehensive review. [2310.14735] Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review , 2310.14735[cs]
[4]Chen J, Diao W, Zhao Q, et al (2018) IoTFuzzer: Discovering memory corruptions in IoT through app-based fuzzing. In: Proceedings 2018 Network and Distributed System Security Symposium. Internet Society, https://doi.org/10. 14722/ndss.2018.23159
[5]Cisco (2017) Cisco-talos/mutiny-fuzzer. GitHub - Cisco-Talos/mutiny-fuzzer
[6]Cui L, Cui J, Hao Z, et al (2022) An empirical study of vulnerability discovery methods over the past ten years. Computers & Security 120:102817. https://doi.org/10.1016/j.cose. 2022.102817
[7]Du X, Liu M, Wang K, et al (2024) Evaluating Large Language Models in Class-Level Code Generation. In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, ICSE ’24,pp 1–13
[8]Ezechina MA, Okwara KK, Ugboaja CAU (2015) The Internet of Things (Iot): A Scalable Approach to Connecting Everything. The Internet Of Things pp 9–12
[9]Fan Z, Gao X, Mirchev M, et al (2023) Automated Repair of Programs from Large Language Models. In: Proceedings of the 45th International Conference on Software Engineering. IEEE Press, Melbourne, Victoria, Australia,ICSE ’23, pp 1469–1481
[10]Feng X, Sun R, Zhu X, et al (2021) Snipuzz: Blackbox fuzzing of IoT firmware via message snippet inference
[11]gdb (Last updated 2024) GDB: The GNU project debugger. Available at: https://sourceware.org/gdb/
[12]Gergely Erdelyi EC (2004) Idapython.https://hex-rays.com//products/ida/support/ idapython_docs/
[13] Hypertext Transfer Protocol (1995) Hypertexttransfer protocol – HTTP/1.1. Available at: https://www.w3.org/Protocols/rfc2616/rfc2616.html
[14]Jain N, Vaidyanath S, Iyer A, et al (2022) Jigsaw: large language models meet program synthesis.
In: Proceedings of the 44th International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, ICSE ’22, pp 1219–1231
[15]Jtpereyda (Last updated 2024) jtpereyda/boofuzz: A fork and successor of the sulley fuzzing framework. https://github.com/jtpereyda/boofuzz
[16]Kallus B, Anantharaman P, Locasto M, et al (2024) The HTTP garden: Discovering parsing vulnerabilities in HTTP/1.1 implementations by differential fuzzing of request streams
[17]Karamcheti S, Mann G, Rosenberg D (2018) Adaptive Grey-Box Fuzz-Testing with Thompson Sampling. Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security pp 37–47
[18]Kumar K, Bose J, Tripathi S (2016) A unified web interface for the internet of things. In: 2016 IEEE Annual India Conference (INDICON), pp 1–6
[19]Liang H, Pei X, Jia X, et al (2018) Fuzzing: State of the art. IEEE Transactions on Reliability
67(3):1199–1218. https://doi.org/10.1109/TR.2018.2834476, conference Name: IEEE Transactions on Reliability
[20]Lindsey O’Donnell (2020) More Than Half of IoT Devices Vulnerable to Severe Attacks | Threatpost
[21]Lionel Sujay V (2024) Number of internet of things (IoT) connections worldwide from 2022 to 2023, with forecasts from 2024 to 2033. https://www.statista.com/statistics/1183457/iot-connected-devices-worldwide/
[22]Liu H, Gan S, Zhang C, et al (2024) Labrador: Response Guided Directed Fuzzing for Blackbox IoT Devices. In: 2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, pp 1920–1938
[23]Ma X, Luo L, Zeng Q (2024) From one thousand pages of specification to unveiling hidden bugs: Large language model assisted fuzzing of matter IoT devices. In: USENIX Security Symposium, pp 4783–4800
[24]Marcussen E (2024) wireghoul/doona. Available at: https://github.com/wireghoul/doona,original-date: 2012-05-01T04:10:01Z
[25]Meng R, Mirchev M, B¨ohme M, et al (2024) Large language model guided protocol fuzzing. In: Proceedings 2024 Network and Distributed System Security Symposium. Internet Society
[26]Minaee S, Mikolov T, Nikzad N, et al (2024) Large Language Models: A Survey
[27]NCC-Group (2017) Triforce. urlhttps://github.com/nccgroup/TriforceAFL
[28]Noman HA, Abu-Sharkh OMF (2023) Code Injection Attacks in Wireless-Based Internet of Things (IoT): A Comprehensive Review and Practical Implementations. Sensors (Basel, Switzerland) 23(13):6067. URL Code Injection Attacks in Wireless-Based Internet of Things (IoT): A Comprehensive Review and Practical Implementations - PMC
[29]Offutt J, Lee A, Rothermel G, et al (1996) An experimental determination of sufficient mutant operators. ACM Transactions on misc Engineering and Methodology 5. An experimental determination of sufficient mutant operators | ACM Transactions on Software Engineering and Methodology
[30]OpenAI (2024) Gpt-4 turbo: Enhanced capabilities and use cases. https://platform.openai.com/docs/models/gpt-4o, accessed: 28-Oct-2024
[31]peach (2011) Peach fuzzing platform. Peach Tech
[32]Pourrahmani H, Yavarinasab A, Monazzah AMH, et al (2023) A review of the security vulnerabilities and countermeasures in the internet of things solutions: A bright future for the blockchain. Internet of Things 23:100888
[33]Ramya CM, Shanmugaraj M, Prabakaran R (2011) Study on ZigBee technology. 2011 3rd International Conference on Electronics Computer Technology pp 297–301. https://doi.org/10.1109/ICECTECH.2011.5942102, conference Name: 2011 3rd International Conference on Electronics Computer Technology (ICECT) ISBN: 9781424486786 Place: Kanyakumari, India Publisher: IEEE
[34]Renze M, Guven E (2024) The Effect of Sampling Temperature on Problem Solving in Large Language Models
[35]Siwakoti YR, Bhurtel M, Rawat DB, et al (2023) Advances in IoT Security: Vulnerabilities, Enabled Criminal Services, Attacks, and Countermeasures. IEEE Internet of Things Journal 10(13):11224–11239. Advances in IoT Security: Vulnerabilities, Enabled Criminal Services, Attacks, and Countermeasures | IEEE Journals & Magazine | IEEE Xplore, URL https://ieeexplore.ieee.org/document/10059147/?arnumber=10059147, conference Name: IEEE Internet of Things Journal
[36]Slivkins A (2024) Introduction to multi-armed bandits. https://doi.org/10.48550/arXiv.1904.07272, 1904.07272[cs,stat]
[37]Tsai CH, Tsai SC, Huang SK (2021) REST API Fuzzing by Coverage Level Guided Blackbox Testing. In: 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS), pp 291–300, REST API Fuzzing by Coverage Level Guided Blackbox Testing | IEEE Conference Publication | IEEE Xplore ,URL https://ieeexplore.ieee.org/abstract/document/9724904, iSSN: 2693-9177
[38]Tufano R, Pascarella L, Tufano M, et al (2021) Towards automating code review activities.https://doi.org/10.48550/arXiv.2101.02518,2101.02518[cs]
[39]Wang J, Yu L, Luo X (2024) LLMIF: Augmented large language model for fuzzing IoT devices.In: Symposium on Security and Privacy (SP).IEEE Computer Society, pp 881–896, LLMIF: Augmented Large Language Model for Fuzzing IoT Devices | IEEE Conference Publication | IEEE Xplore
[40]Xia CS, Paltenghi M, Le Tian J, et al (2024) Fuzz4All: Universal Fuzzing with Large Language Models. In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, ICSE ’24,pp 1–13
[41]Zegeye W, Jemal A, Kornegay K (2023) Connected smart home over matter protocol. In:
2023 IEEE International Conference on Consumer Electronics (ICCE), pp 1–7, https://doi.org/10.1109/ICCE56470.2023.10043520, ISSN:2158-4001
[42]Zheng Y, Davanian A, Yin H, et al (2019) FIRMAFL: High-throughput greybox fuzzing of IoT firmware via augmented process emulation. In: USENIX Security Symposium, pp 1099–1114
翻译论文链接:https://arxiv.org/pdf/2411.11929或https://link.springer.com/article/10.1007/s13042-024-02527-3


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









