






目录
5、rpush/rpushx/rpop/rpoplpush命令
1、hset/hget/hdel/hexists/hlen/hsetnx命令
3、hgetall/hkeys/hvals/hmget/hmset命令
1、sadd/smembers/scard/sismemver命令
2、spop/srem/srandmember/smove命令
3、hgetall/hkeys/hvals/hmfet/hmset命令
1、sadd/smembers/scard/sismemver命令
2、spop/srem/srandmember/smove命令
1、zadd/zcard/zcount/zrem/zincrby/zscore/zrange/zrankm命令
2、zrangebtscore/zremrangebyrank/zremrangebyscore命令
3、zrevrange/zrevrangebyscore/zrevrank命令
一、String数据类型
String是 redis 最基本的类型,最大能存储 512MB 的数据,String类型是二进制安全的,即可以存储任何数据、比如数字、图片、序列化对象等
1、set/get/append/strlen命令
PS:APPEND
APPEND key value追加键值,并返回追加后的长度(若键不存在,则相当于创建)
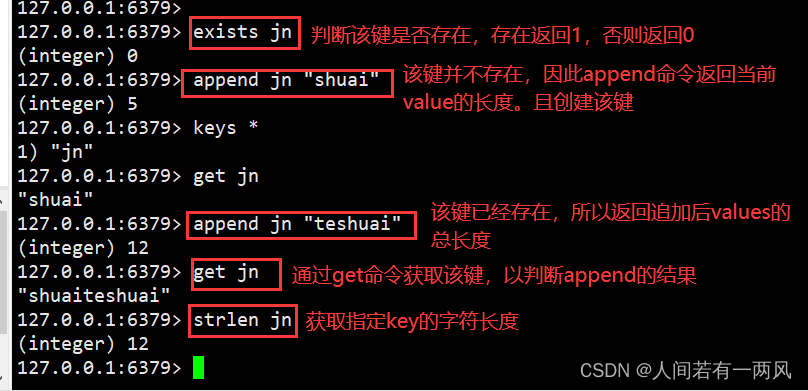
exists home
#判断该键是否存在,存在返回1,否则返回0
append home "cat"
#该键并不存在,因此append命令返回当前value的长度
append home "dog"
#该键已经存在,因此返回追加后的value的长度
get home
#通过get命令获取该键,以判断append的结果

2、incr/decr/incrby/decrby命令
INCR key:key值递增加1(key值必须为整数)
DECR key:key值递减1(key值必须为整数)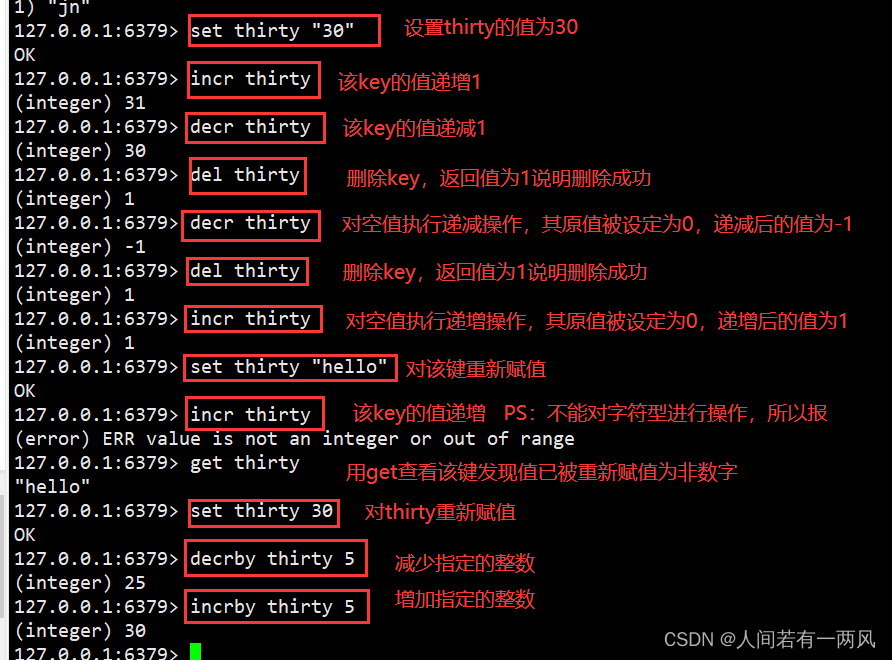
3、getset命令
GETSET key value:获取key值并返回,同时给key设置新值
redis 127.0.0.1:6379> incr mycounter #将计数器的值原子性的递增1
(integer) 1
redis 127.0.0.1:6379> getset mycounter 0 #在获取计数器原有值的同时,并将其设置为新值,这两个操作原子性的方式同时完成。
redis 127.0.0.1:6379> get mycounter #查看设置后的结果。
"0"

4、setex命令
setex key seconds value:设置指定key的过期时间为seconds127.0.0.1:6379> setex mykey 15 "hello" #设置指定Key的过期时间为15秒。
OK
127.0.0.1:6379> ttl mykey #通过tt1命令查看指定Key的剩余存活时间(秒数),0表示已经过期,-1表示永不过期。
(integer) 4
127.0.0.1:6379> get mykey #获取已过期的Key将返回nil
(nil)
127.0.0.1:6379> ttl mykey #该ttl命令的返回值显示,该Key已经过期。
(integer) -2

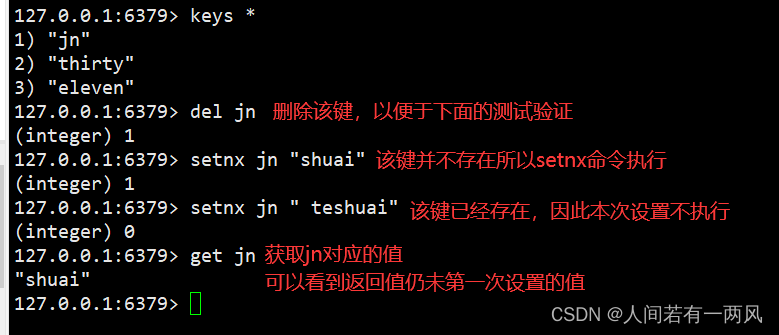
5、setnx
SETNX key value:不存在键的话执行set操作,存在的话不执行
6、mset/mget/msetnx
MSET key value [key value …]:批量设置键-值对
MGET key [key …]:批量获取键值对
MSETNX key value [key value …]:批量设置键-值对,都不存在就执行并返回1;只要有一个存在就不执行并返回0
127.0.0.1:6379> mset key1 "hello" key2 "world" #批量设置了key1和key2两个键。
OK
127.0.0.1:6379> mget key1 key2 #批量获取了key1和key2两个键的值。
1) "hello"
2) "world"
127.0.0.1:6379> msetnx key3 "zhang" key4 "san" #批量设置了key3和key4两个键,因为之前他们并不存在,所以msetnx命令执行成功并返回1。
(integer) 1
127.0.0.1:6379> mget key3 key4
1) "zhang"
2) "san"
127.0.0.1:6379> msetnx key3 "li" key4 "si" #批量设置了key3和key4两个键,但是key3和key4已经存在,所以msetnx命令执行失败并返回0。
(integer) 0
127.0.0.1:6379> mget key3 key4
1) "zhang"
2) "san"
127.0.0.1:6379> msetnx key3 "li" key5 "si" #批量设置了key3和key5两个键,但是key3已经存在,所以msetnx命令执行失败并返回0。
(integer) 0
127.0.0.1:6379> mget key3 key5 #批量获取key3和key5,由于key5没有设置成功,所以返回nil
1) "zhang"
2) (nil)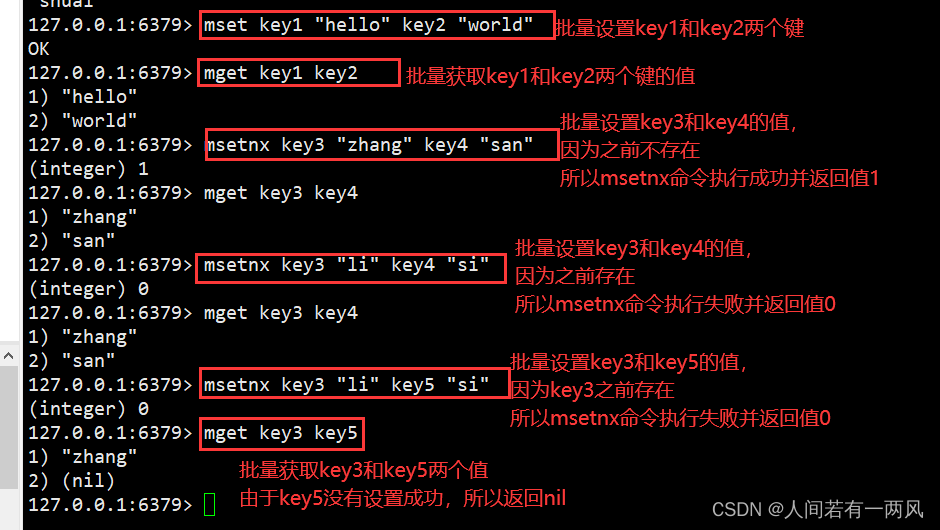
二、List数据类型
列表的元素类型为String,按照插入顺序完成,在列表的头部和尾部添加元素
1、lpush/lpushx/lrange命令
LPUSH key value [value …]在头部(左侧)依次插入列表元素
LPUSHX key value:键必须存在才能执行,在头部插入元素值并返回并返回列表元素数量
LRANGE key start stop:取从位置索引start到位置索引stop的所有元素(所以以0开始)
127.0.0.1:6379> mset key1 "hello" key2 "world" #批量设置了key1和key2两个键。
OK
127.0.0.1:6379> mget key1 key2 #批量获取了key1和key2两个键的值。
1) "hello"
2) "world"
127.0.0.1:6379> msetnx key3 "zhang" key4 "san" #批量设置了key3和key4两个键,因为之前他们并不存在,所以msetnx命令执行成功并返回1。
(integer) 1
127.0.0.1:6379> mget key3 key4
1) "zhang"
2) "san"
127.0.0.1:6379> msetnx key3 "li" key4 "si" #批量设置了key3和key4两个键,但是key3和key4已经存在,所以msetnx命令执行失败并返回0。
(integer) 0
127.0.0.1:6379> mget key3 key4
1) "zhang"
2) "san"
127.0.0.1:6379> msetnx key3 "li" key5 "si" #批量设置了key3和key5两个键,但是key3已经存在,所以msetnx命令执行失败并返回0。
(integer) 0
127.0.0.1:6379> mget key3 key5 #批量获取key3和key5,由于key5没有设置成功,所以返回nil
1) "zhang"
2) (nil)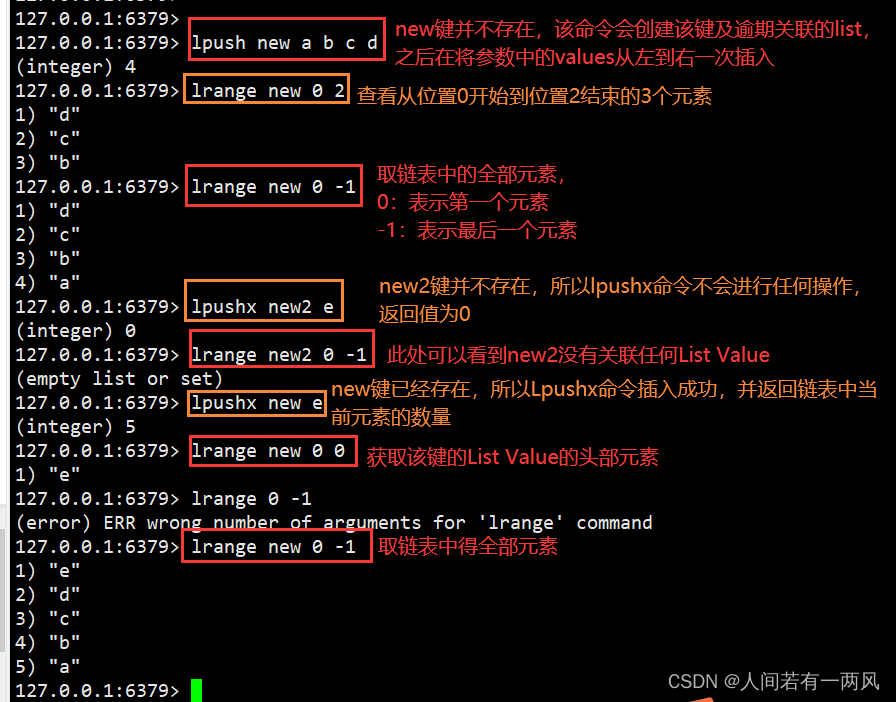
2、lpop/llen命令
127.0.0.1:6379> lpush mykey a b c d
(integer) 4
127.0.0.1:6379> lpop mykey #移除并返回mykey键的第一个元素,即从右往左第一个
"d"
127.0.0.1:6379> lpop mykey
"c"
127.0.0.1:6379> llen mykey #获取表中元素数量,在执行lpop命令两次后,链表头部的两个元素已经被弹出,此时链表中元素的数量是2
(integer) 2

3、lrem/lset/lindex/ltrim命令
LREM key count value:从头部开始删除count个值为value的元素,并返回实际删除数量
LSET key index value:将位置索引为index的元素设置新值value
LINDEX key index:获取索引为index的元素
LTRIM key start stop:仅保留从位置索引start到索引stop的元素
127.0.0.1:6379> mset key1 "hello" key2 "world" #批量设置了key1和key2两个键。
OK
127.0.0.1:6379> mget key1 key2 #批量获取了key1和key2两个键的值。
1) "hello"
2) "world"
127.0.0.1:6379> msetnx key3 "zhang" key4 "san" #批量设置了key3和key4两个键,因为之前他们并不存在,所以msetnx命令执行成功并返回1。
(integer) 1
127.0.0.1:6379> mget key3 key4
1) "zhang"
2) "san"
127.0.0.1:6379> msetnx key3 "li" key4 "si" #批量设置了key3和key4两个键,但是key3和key4已经存在,所以msetnx命令执行失败并返回0。
(integer) 0
127.0.0.1:6379> mget key3 key4
1) "zhang"
2) "san"
127.0.0.1:6379> msetnx key3 "li" key5 "si" #批量设置了key3和key5两个键,但是key3已经存在,所以msetnx命令执行失败并返回0。
(integer) 0
127.0.0.1:6379> mget key3 key5 #批量获取key3和key5,由于key5没有设置成功,所以返回nil
1) "zhang"
2) (nil)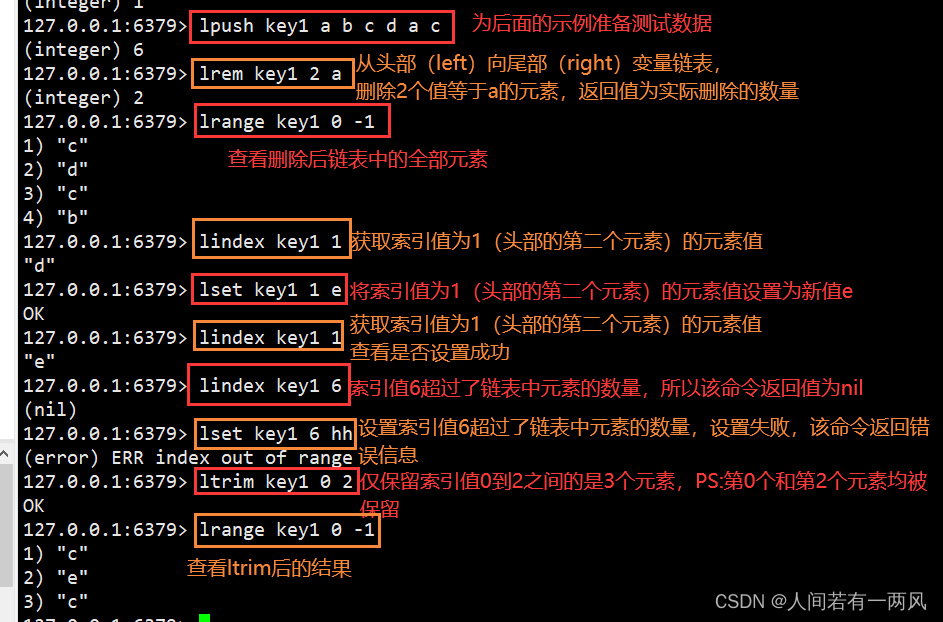
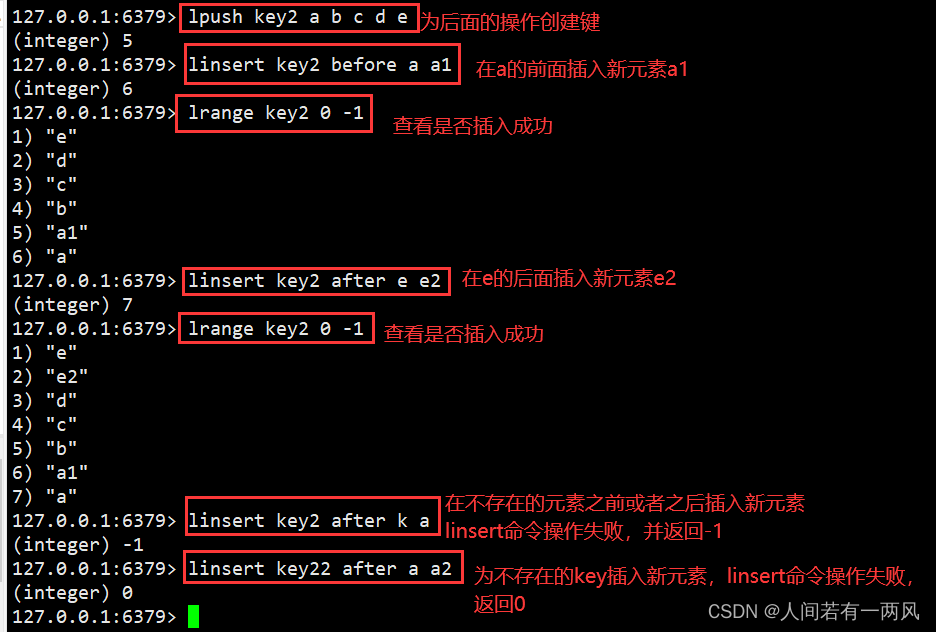
4、linsert命令
LINSERT key BEFORE|AFTER pivot value:在元素pivot的前面(做左)或后面(右)插入新元素value
127.0.0.1:6379> lpush mykey a b c d e #为后面的示例准备测试数据。
(integer) 5
127.0.0.1:6379> linsert mykey before a a1 #在a的前面插入新元素a1。
(integer) 6
127.0.0.1:6379> lrange mykey 0 -1 #查看是否插入成功,从结果看已经插入
1) "e"
2) "d"
3) "c"
4) "b"
5) "a1"
6) "a"
127.0.0.1:6379> linsert mykey after e e2 #在e的后面插入新元素e2,从返回结果看已经插入成功。
(integer) 7
127.0.0.1:6379> lrange mykey 0 -1 #再次查看是否插入成功。
1) "e"
2) "e2"
3) "d"
4) "c"
5) "b"
6) "a1"
7) "a"
127.0.0.1:6379> linsert mykey after k a #在不存在的元素之前或之后插入新元素,linsert 命令操作失败,并返回-1。
(integer) -1
127.0.0.1:6379> linsert mykey1 after a a2 #为不存在的Key插入新元素,linsert命 令操作失败,返回0。.
(integer) 0
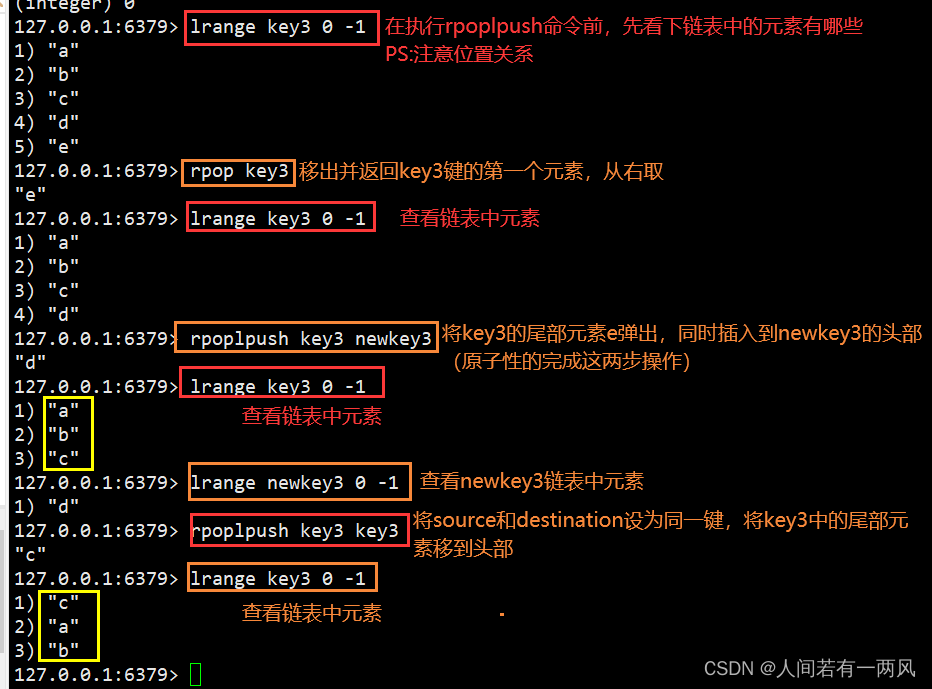
5、rpush/rpushx/rpop/rpoplpush命令
RPUSH key value [value …]在列表的尾部依次插入value
RPUSHX key value:key必须存在才可执行,将value从尾部插入,并返回所有元素数量
RPOP key:在尾部弹出(移除)一个元素,并返回该元素
RPOPLPUSH source destination:在key1的尾部弹出一个元素并返回,将它插入key2的头部
127.0.0.1:6379> rpush mykey a b c d #从链表的尾部插入参数中给出的values,插入顺序是从右到左依次插入。
(integer) 4
127.0.0.1:6379> lrange mykey 0 -1 #通过lrange命令可以获悉rpush在插入多值时的插入顺序。
1) "a"
2) "b"
3) "c"
4) "d"
127.0.0.1:6379> rpushx mykey e #该键已经存在并且包含4个元素,rpushx命令将执行成功,并将元素e插入到链表的尾部。
(integer) 5
127.0.0.1:6379> lindex mykey 4 #通过lindex命令可以看出之前的rpushx命令确实执行成功,因为索引值为4的元素已经是新元素了。
"e"
127.0.0.1:6379> rpushx mykey2 e #由于mykey2键并不存在,因此rpushx命令不会插入数据,其返回值为0。
(integer) 0
127.0.0.1:6379> lrange mykey 0 -1 #在执行rpoplpush命令前,先看一下 mykey中链表的元素有哪些,注意他们的位置关系。
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
127.0.0.1:6379> rpop mykey #移除并返回mykey键的第一个元素,从右取
"e"
127.0.0.1:6379> lrange mykey 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
127.0.0.1:6379> rpoplpush mykey mykey2 #将mykey的尾部元素e弹出,同时再插入到mykey2的头部(原子性的完成这两步操作)。
"d"
127.0.0.1:6379> lrange mykey 0 -1 #通过lrange命令查看mykey在弹出尾部元素后的结果。
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> lrange mykey2 0 -1 #通过lrange命令查看mykey2在插入元素后的结果。
1) "d"
127.0.0.1:6379> rpoplpush mykey mykey #将source和destination设为同一键,将mykey中的尾部元素移到其头部。
"c"
"c"
127.0.0.1:6379> lrange mykey 0 -1 #查看移动结果。
1) "c"
1) "c"
2) "a"
3) "b"
三、Hash数据类型(散列类型)
Hash用于存储对象,可以采用这样的命名方式(hash格式):对象列别和ID构成键名,使用字段表示对象的属性,而字段值则存储属性值
如:存储ID为2的汽车对象
如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘空间。每一个Hash可以存储4294967295个键值对
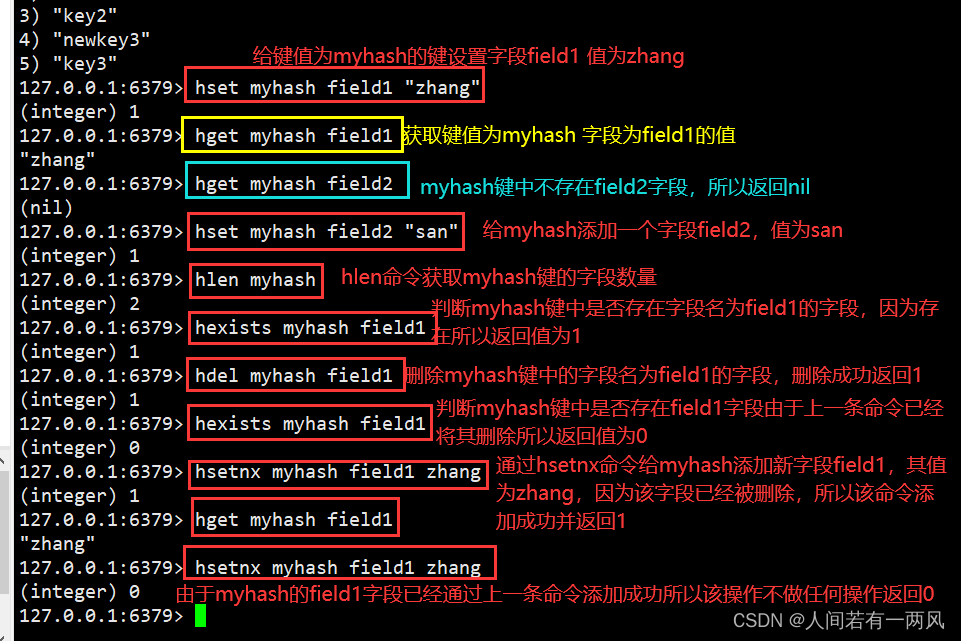
1、hset/hget/hdel/hexists/hlen/hsetnx命令
127.0.0.1:6379> hset myhash field1 "zhang" #给键值为myhash的键设置字段为field1,值为zhang。
(integer) 1
127.0.0.1:6379> hget myhash field1 #获取键值为myhash,字段为field1的值。
"zhang"
127.0.0.1:6379> hget myhash field2 #myhash键中不存在field2字段,因此返回nil.
(nil)
(nil)
127.0.0.1:6379> hset myhash field2 "san" #给myhash添加一个新的字段field2,其值为san。
(integer) 1
127.0.0.1:6379> hlen myhash #hlen命令获取myhash键的字段数量。
(integer) 2
127.0.0.1:6379> hexists myhash field1 #判断myhash键中是否存在字段名为field1的字段,由于存在,返回值为1。
(integer) 1
127.0.0.1:6379> hdel myhash field1 #删除myhash键中字段名为field1的字段,删除成功返回1。
(integer) 1
127.0.0.1:6379> hdel myhash field1 #再次删除myhash键中字段名为field1的字段,由于上一条命令已经将其删除,因为没有删除,返回0
(integer) 0
127.0.0.1:6379> hexists myhash field1 #判断myhash键中是否存在field1字段,由于上一条命令已经将其删除,因为返回0。
(integer) 0
127.0.0.1:6379> hsetnx myhash field1 zhang #通过hsetnx命令给myhash添加新字段field1,其值为zhang,因为该字段已经被删除,所以该命令添加成功并返回1
(integer) 1
127.0.0.1:6379> hget myhash field1
"zhang"
127.0.0.1:6379> hsetnx myhash field1 zhang #由于myhash的field1字段已经通过上一条命令添加成功,因为本条命令不做任何操作后返回0。
(integer) 0
2、hincrby命令
127.0.0.1:6379> del myhash #删除该键,便于后面示例的测试。
(integer) 1
127.0.0.1:6379> hset myhash field 5 #准备测试数据,该myhash的field字段设定值5。
(integer) 1
127.0.0.1:6379> hincrby myhash field 1 #hincrby命令给myhash的field字段的值加1,返回加后的结果。
(integer) 6
127.0.0.1:6379> hincrby myhash field -1 #hincrby命令给myhash的field字段的值加-1,返回加后的结果。
(integer) 5
127.0.0.1:6379> hincrby myhash field -10 #hincrby命令给myhash的field字段的值加-10,返回加后的结果。
(integer) -5

3、hgetall/hkeys/hvals/hmget/hmset命令
127.0.0.1:6379> del myhash #删除该键,便于后面示例测试。
(integer) 1
127.0.0.1:6379> hmset myhash field1 "hello" field2 "world" #hmset命令为该键myhash,一次性设置多个字段,分别是field1="hello",field2="world"。
OK
127.0.0.1:6379> hmget myhash field1 field2 field3 #hmget命令获取myhash键的多个字段,其中field3并不存在,因为在返回结果中与该字段对应的值为nil。
1) "hello"
2) "world"
3) (nil)
127.0.0.1:6379> hgetall myhash #hgetall命令返回myhash键的所有字段及其值,从结果中可以看出,他们是逐对列出的。
1) "field1"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379> hkeys myhash #hkeys命令仅获取myhash键中所有字段的名字。
1) "field1"
2) "field2"
127.0.0.1:6379> hvals myhash hvals命令仅获取myhash键中所有字段的值。
1) "hello"
2) "world"
三、set数据类型(无序集合)
概述:无序集合,元素类型为string类型,元素具有唯一性,不允许存在重复的成员。多个集合类型之间可以进行并集、交集和差集运算
应用范围:
- 可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息。对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中,Set数据类型会自动保证IP地址的唯一性
- 充分利用Set类型的服务端聚合操作方便、高效的特性,可以用于维护数据对象之间的关联关系。比如购买某一电子设备的客户ID被存储在一个指定的Set中,而购买另外一种电子产品的客户ID被存储在另外一个Set中,如果此时我们向获取有哪些客户同时购买了这两种商品时,Set的intersections命令就可以充分发挥它的方便和效率的优势
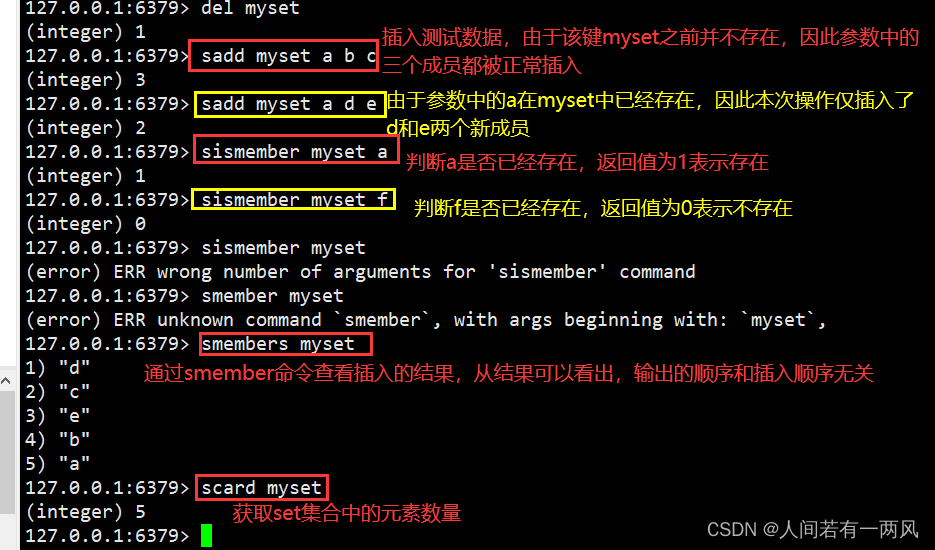
1、sadd/smembers/scard/sismemver命令
127.0.0.1:6379> sadd myset a b c #插入测试数据,由于该键myset之前并不存在,因此参数中的三个成员都被正常插入。
(integer) 3
127.0.0.1:6379> sadd myset a d e #由于参数中的a在myset中已经存在,因此本次操作仅仅插入了d和e两个新成员。
(integer) 2
127.0.0.1:6379> SISMEMBER myset a #判断a是否已经存在,返回值为1表示存在。
(integer) 1
127.0.0.1:6379> SISMEMBER myset f #判断f是否已经存在,返回值为0表示不存在。
(integer) 0
127.0.0.1:6379> SMEMBERS myset #通过smembers命令查看插入的结果,从结果可以看出,输出的顺序和插入顺序无关。
1) "d"
2) "b"
3) "a"
4) "c"
5) "e"
127.0.0.1:6379> SCARD myset #获取Set集合中元素的数量
(integer) 5
2、spop/srem/srandmember/smove命令
127.0.0.1:6379> del myset #删除该键,便于后而的测试。
(integer) 1
127.0.0.1:6379> sadd myset a b c d #为后面的示例准备测试数据。
(integer) 4
127.0.0.1:6379> SMEMBERS myset #查看Set中成员的位置。
1) "b"
2) "c"
3) "a"
4) "d"
127.0.0.1:6379> SRANDMEMBER myset #从结果可以看出,该命令确实是随机的返回了某一成员
"c"
127.0.0.1:6379> SPOP myset #随机的移除并返回Set中的某一成员。
"d"
127.0.0.1:6379> SMEMBERS myset #查看移出后set的成员信息。
1) "b"
2) "c"
3) "a"
127.0.0.1:6379> SREM myset a b f #从myset中移出a、b和f三个成员,其中f并不存在,因此只有a和b两个成员被移出,返回为2。
(integer) 2
127.0.0.1:6379> SMEMBERS myset #查看移出后的输出结果。
1) "c"
127.0.0.1:6379> sadd myset a b #为后面的smove命令准备数据。
(integer) 2
127.0.0.1:6379> sadd myset2 c d
(integer) 2
127.0.0.1:6379> SMOVE myset myset2 a #将a从myset移到myset2,从结果可以看出移动成功。
(integer) 1
127.0.0.1:6379> SMEMBERS myset2 #分别查看myset和myset2的成员,确认移动是否真的成功。
1) "a"
2) "c"
3) "d"
127.0.0.1:6379> SMEMBERS myset
1) "b"
2) "c"
127.0.0.1:6379> 3、hgetall/hkeys/hvals/hmfet/hmset命令
127.0.0.1:6379> del myhash #删除该键,便于后面示例测试。
(integer) 1
127.0.0.1:6379> hmset myhash field1 "hello" field2 "world" #hmset命令为该键myhash,一次性设置多个字段,分别是field1="hello",field2="world"。
OK
127.0.0.1:6379> hmget myhash field1 field2 field3 #hmget命令获取myhash键的多个字段,其中field3并不存在,因为在返回结果中与该字段对应的值为nil。
1) "hello"
2) "world"
3) (nil)
127.0.0.1:6379> hgetall myhash #hgetall命令返回myhash键的所有字段及其值,从结果中可以看出,他们是逐对列出的。
1) "field1"
2) "hello"
3) "field2"
4) "world"
127.0.0.1:6379> hkeys myhash #hkeys命令仅获取myhash键中所有字段的名字。
1) "field1"
2) "field2"
127.0.0.1:6379> hvals myhash hvals命令仅获取myhash键中所有字段的值。
1) "hello"
2) "world"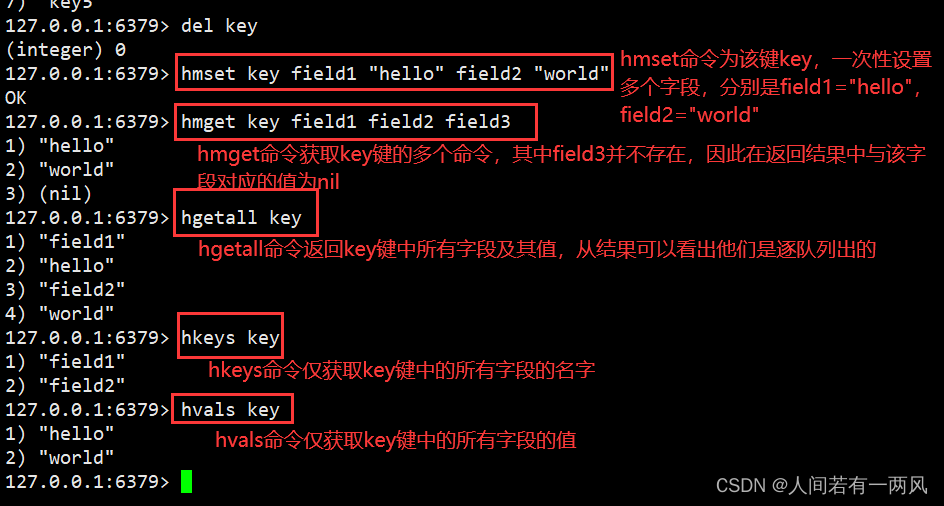
四、set数据类型(无序集合)
概述:无序集合,元素类型为string类型,元素具有唯一性,不允许存在重复的成员。多个集合类型之间可以进行并集、交集和差集运算
应用范围:
- 可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息。对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中,Set数据类型会自动保证IP地址的唯一性
- 充分利用Set类型的服务端聚合操作方便、高效的特性,可以用于维护数据对象之间的关联关系。比如购买某一电子设备的客户ID被存储在一个指定的Set中,而购买另外一种电子产品的客户ID被存储在另外一个Set中,如果此时我们向获取有哪些客户同时购买了这两种商品时,Set的intersections命令就可以充分发挥它的方便和效率的优势
1、sadd/smembers/scard/sismemver命令
127.0.0.1:6379> sadd myset a b c #插入测试数据,由于该键myset之前并不存在,因此参数中的三个成员都被正常插入。
(integer) 3
127.0.0.1:6379> sadd myset a d e #由于参数中的a在myset中已经存在,因此本次操作仅仅插入了d和e两个新成员。
(integer) 2
127.0.0.1:6379> SISMEMBER myset a #判断a是否已经存在,返回值为1表示存在。
(integer) 1
127.0.0.1:6379> SISMEMBER myset f #判断f是否已经存在,返回值为0表示不存在。
(integer) 0
127.0.0.1:6379> SMEMBERS myset #通过smembers命令查看插入的结果,从结果可以看出,输出的顺序和插入顺序无关。
1) "d"
2) "b"
3) "a"
4) "c"
5) "e"
127.0.0.1:6379> SCARD myset #获取Set集合中元素的数量
(integer) 5
2、spop/srem/srandmember/smove命令
127.0.0.1:6379> del myset #删除该键,便于后而的测试。
(integer) 1
127.0.0.1:6379> sadd myset a b c d #为后面的示例准备测试数据。
(integer) 4
127.0.0.1:6379> SMEMBERS myset #查看Set中成员的位置。
1) "b"
2) "c"
3) "a"
4) "d"
127.0.0.1:6379> SRANDMEMBER myset #从结果可以看出,该命令确实是随机的返回了某一成员
"c"
127.0.0.1:6379> SPOP myset #随机的移除并返回Set中的某一成员。
"d"
127.0.0.1:6379> SMEMBERS myset #查看移出后set的成员信息。
1) "b"
2) "c"
3) "a"
127.0.0.1:6379> SREM myset a b f #从myset中移出a、b和f三个成员,其中f并不存在,因此只有a和b两个成员被移出,返回为2。
(integer) 2
127.0.0.1:6379> SMEMBERS myset #查看移出后的输出结果。
1) "c"
127.0.0.1:6379> sadd myset a b #为后面的smove命令准备数据。
(integer) 2
127.0.0.1:6379> sadd myset2 c d
(integer) 2
127.0.0.1:6379> SMOVE myset myset2 a #将a从myset移到myset2,从结果可以看出移动成功。
(integer) 1
127.0.0.1:6379> SMEMBERS myset2 #分别查看myset和myset2的成员,确认移动是否真的成功。
1) "a"
2) "c"
3) "d"
127.0.0.1:6379> SMEMBERS myset
1) "b"
2) "c"
127.0.0.1:6379> 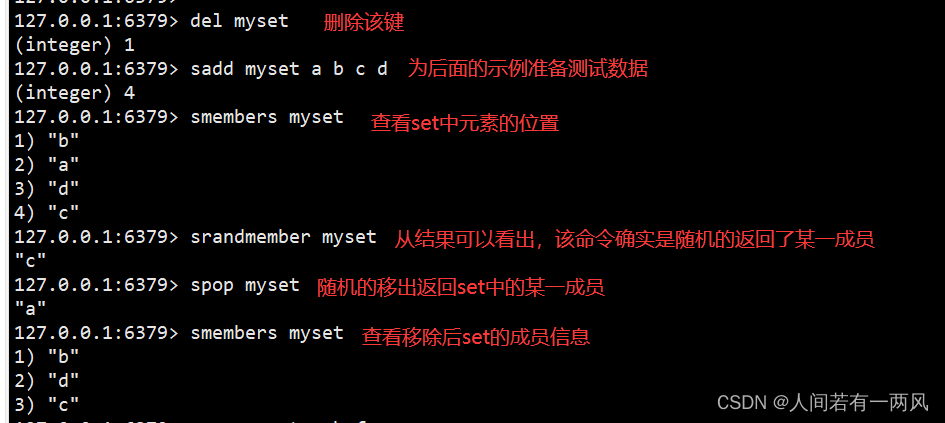

五、sorted set数据类型(zset、有序结合)
概述:a、有序集合、元素类型为string,元素具有唯一性,不能重复。b、每个元素都会关联一个double类型的分数score(表示权重),可以通过权重的大小排序,元素的score可以相同
应用范围:
可以用于一个大型在线游戏的积分沛航胖,每当玩家的分数发生变化时,可以执行ZADD命令更新玩家的分数,此后再通过ZRANGE命令获取积分TOP10的用户信息。当然我们也可以利用ZRANK命令通过usename来获取玩家的排行信息。最后我们将组合使用ZRANGE和ZRANK命令快速的获取和某个玩家积分相近的其他用户的信息。Sorted-Set类型还可用于构建索引数据
1、zadd/zcard/zcount/zrem/zincrby/zscore/zrange/zrankm命令
127.0.0.1:6379> del myzset
(integer) 1
127.0.0.1:6379> zadd myzset 1 "one" #添加一个分数为1的成员。
(integer) 1
127.0.0.1:6379> zadd myzset 2 "two" 3 "three" #添加两个分数分别是2和3的两个成员。
(integer) 2
127.0.0.1:6379> zrange myzset 0 -1 withscores #0表示第一个成员,-1表示最后一个成员。WITHSCORES选 项表示返回的结果中包含每个成员及其分数,否则只返回成员。
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
127.0.0.1:6379> zrank myzset one #获取成员one在Sorted-Set中的位置索引值。0表示第一个位置。
(integer) 0
127.0.0.1:6379> zrank myzset four #成员four并不存在,因此返回nil。
(nil)
127.0.0.1:6379> zcard myzset #获取myzset键中成员的数量。
(integer) 3
127.0.0.1:6379> zcount myzset 1 2 #zcount key min max,分数满足表达式1 <= score <= 2的成员的数量。
(integer) 2
127.0.0.1:6379> zrem myzset one two #删除成员one和two,返回实际删除成员的数量
(integer) 2
127.0.0.1:6379> zcard myzset #查看是否删除成功。
(integer) 1
127.0.0.1:6379> zscore myzset three #获取成员three的分数。返回值是字符串形式。
"3"
127.0.0.1:6379> zscore myzset two #由于成员two已经被删除,所以该命令返回nil。
(nil)
127.0.0.1:6379> zincrby myzset 2 one #成员one不存在,zincrby命令将添加该成员并假设其初始分数为0,将成员one的分数增加2,并返回该成员更新后的分数。
"2"
127.0.0.1:6379> zincrby myzset -1 one #将成员one的分数增加-1,并返回该成员更新后的分数。
"1"
127.0.0.1:6379> zrange myzset 0 -1 withscores #查看在更新了成员的分数后是否正确。
1) "one"
2) "1"
3) "three"
4) "3"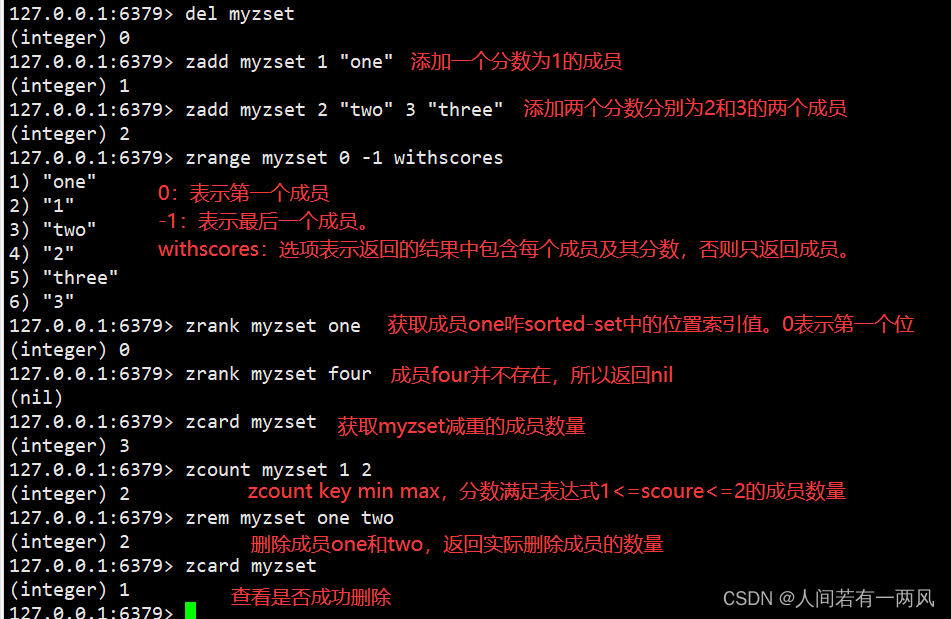

2、zrangebtscore/zremrangebyrank/zremrangebyscore命令
127.0.0.1:6379> del myzset
(integer) 1
127.0.0.1:6379> zadd myzset 1 one 2 two 3 three 4 four
(integer) 4
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 2 #zrangebyscore key min max,获取分数满足表达式1 <= score <= 2的成员。
1) "one"
2) "two"
127.0.0.1:6379> ZRANGEBYSCORE myzset (1 2 #获取分数满足表达式1 < score <= 2的成员。
1) "two"
127.0.0.1:6379> ZRANGEBYSCORE myzset -inf +inf limit 2 3 #-inf表示第一个成员(位置索引值最低的,即0),+inf表示最后一个成员(位置索引值最高的),limit后面的参数用于限制返回成员的值,2表示从位置索引等于2的成员开始,取后而3个成员。
1) "three"
2) "four"
127.0.0.1:6379> ZRANGEBYSCORE myzset 0 4 limit 2 3
1) "three"
2) "four"
127.0.0.1:6379> ZREMRANGEBYSCORE myzset 1 2 #删除分数满足表达式1 <= score <= 2的成员,并返回实际删除的数量。
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 -1 #查看一下.上面的删除是否成功。
1) "three"
2) "four"
127.0.0.1:6379> ZREMRANGEBYRANK myzset 0 1 #删除位置索引满足表达式0 <= rank <= 1的成员。
(integer) 2
127.0.0.1:6379> zcard myzset #查看上--条命令是否删除成功。
(integer) 0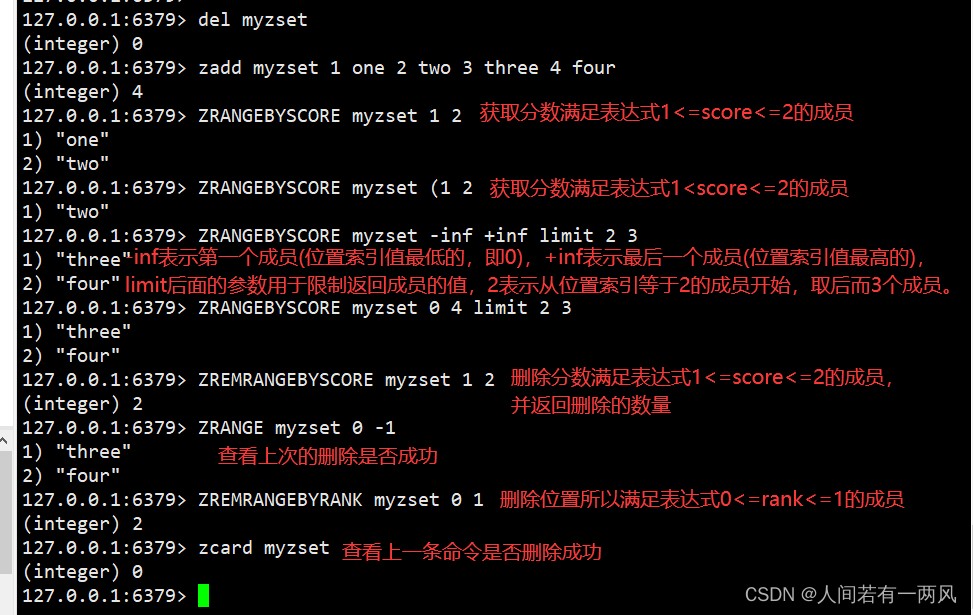
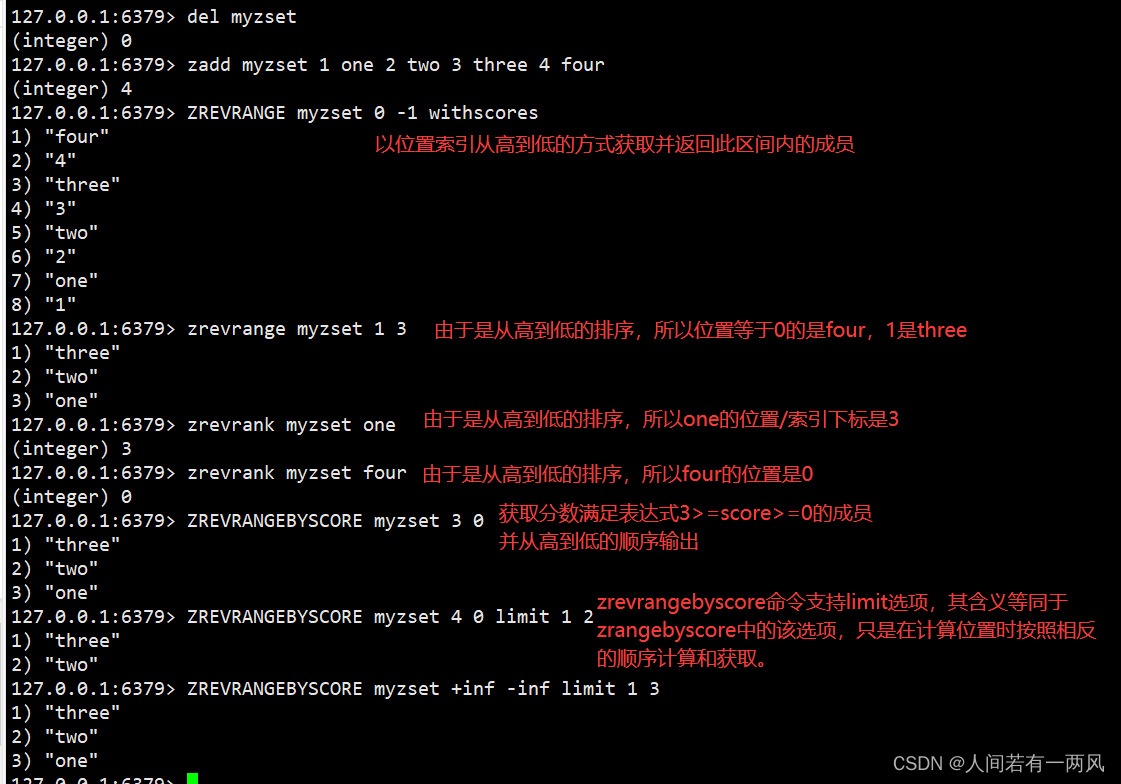
3、zrevrange/zrevrangebyscore/zrevrank命令
127.0.0.1:6379> del myzset
(integer) 0
127.0.0.1:6379> zadd myzset 1 one 2 two 3 three 4 four
(integer) 4
127.0.0.1:6379> ZREVRANGE myzset 0 -1 withscores #以位置索引从高到低的方式获取并返回此区间内的成员。
1) "four"
2) "4"
3) "three"
4) "3"
5) "two"
6) "2"
7) "one"
8) "1"
127.0.0.1:6379> zrevrange myzset 1 3 #由于是从高到低的排序,所以位置等于0的是four,1是three,并以此类推。
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> zrevrank myzset one #由于是从高到低的排序,所以one的位置/索引下标是3。
(integer) 3
127.0.0.1:6379> zrevrank myzset four #由于是从高到低的排序,所以four的位置是0。
(integer) 0
127.0.0.1:6379> ZREVRANGEBYSCORE myzset 3 0 # zrevrangebyscore key max min,获取分数满足表达式3 >= score >= 0的成员,并以从高到底的顺序输出。
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> ZREVRANGEBYSCORE myzset 4 0 limit 1 2 #zrevrangebyscore命令支持limit选项,其含义等同于zrangebyscore中的该选项,只是在计算位置时按照相反的顺序计算和获取。
1) "three"
2) "two"
127.0.0.1:6379> ZREVRANGEBYSCORE myzset +inf -inf limit 1 3
1) "three"
2) "two"
3) "one"















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









