







作者:小树苗渴望变成参天大树
作者宣言:认真写好每一篇博客
作者gitee:gitee
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

二叉树
前言
各位友友们,大家好,之前我们在介绍树的章节二叉树的两种存储方式,一个是数组存储,一个是链式存储,我之前讲过数组存储的时候只适合完全二叉树,因为结点的关系可以计算出来,但完全二叉树是特殊的树,我们大部分都不是特殊的树,所以我们今天将介绍二叉树的另一种存储方式-链式存储,虽然今天将的二叉树在实际应用中没有什么意义,但是可以先带我们入一下小门。
这篇主要对递归要求较高,我开始会给大家画画递归展开图
一、二叉树的创建
我们知道二叉树之所以叫二叉树是因为它最多只有两个孩子,所以使用左孩子右兄弟方法就跟定义一个左孩子和右孩子一样
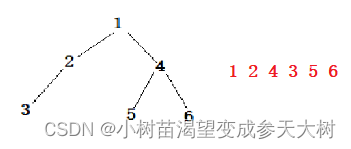
我们先来看一下二叉树的图:
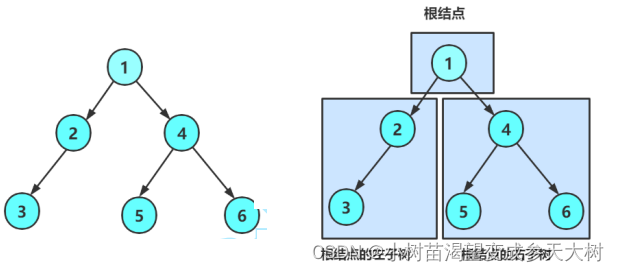
我们来看一下代码:
typedef int BTDateType;
typedef struct BTree
{
BTDateType data;
struct BTree* left;
struct BTree* right;
}BTNode;
通过递归来访问它下面的左孩子和右孩子
因为这异界对于二叉树的插入没有什么意思,因为不知道插在那个结点比较合适,等后期我更新关于平衡二叉树的知识的时候会讲到,那我们就手动创造一棵树
BTNode* BuyNode(BTDateType x)
{
BTNode* new = (BTNode*)malloc(sizeof(BTNode));
if (new == NULL)
{
perror("malloc:");
return;
}
new->data = x;
new->left = NULL;
new->right = NULL;
return new;
}
BTNode* CreateTree()
{
BTNode* node1 = BuyNode(1);
BTNode* node2 = BuyNode(2);
BTNode* node3 = BuyNode(3);
BTNode* node4 = BuyNode(4);
BTNode* node5 = BuyNode(5);
BTNode* node6 = BuyNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;
return node1;
}
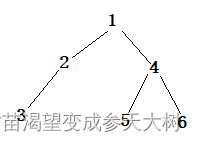
这棵树创建就是这样的
接下来我来讲二叉树的四种遍历,前三种考研大家的递归能力,最后一种需要使用队列来实现。
二、二叉树的遍历
2.1前序遍历
特点是先遍历根结点,在遍历左子树,然后再遍历右子树

递归思想:
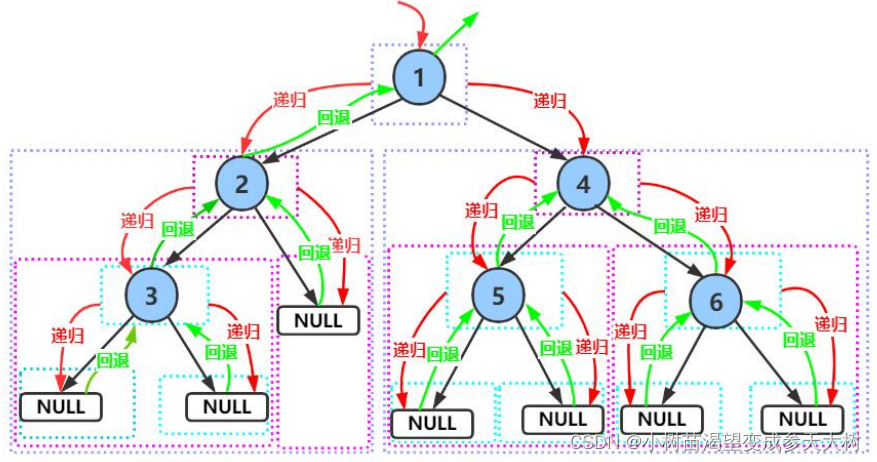
我们来看一下它的代码:
// 二叉树前序遍历
void PreOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return NULL;
}
printf("%d ", root->data);
PreOrder(root->left);
PreOrder(root->right);
}
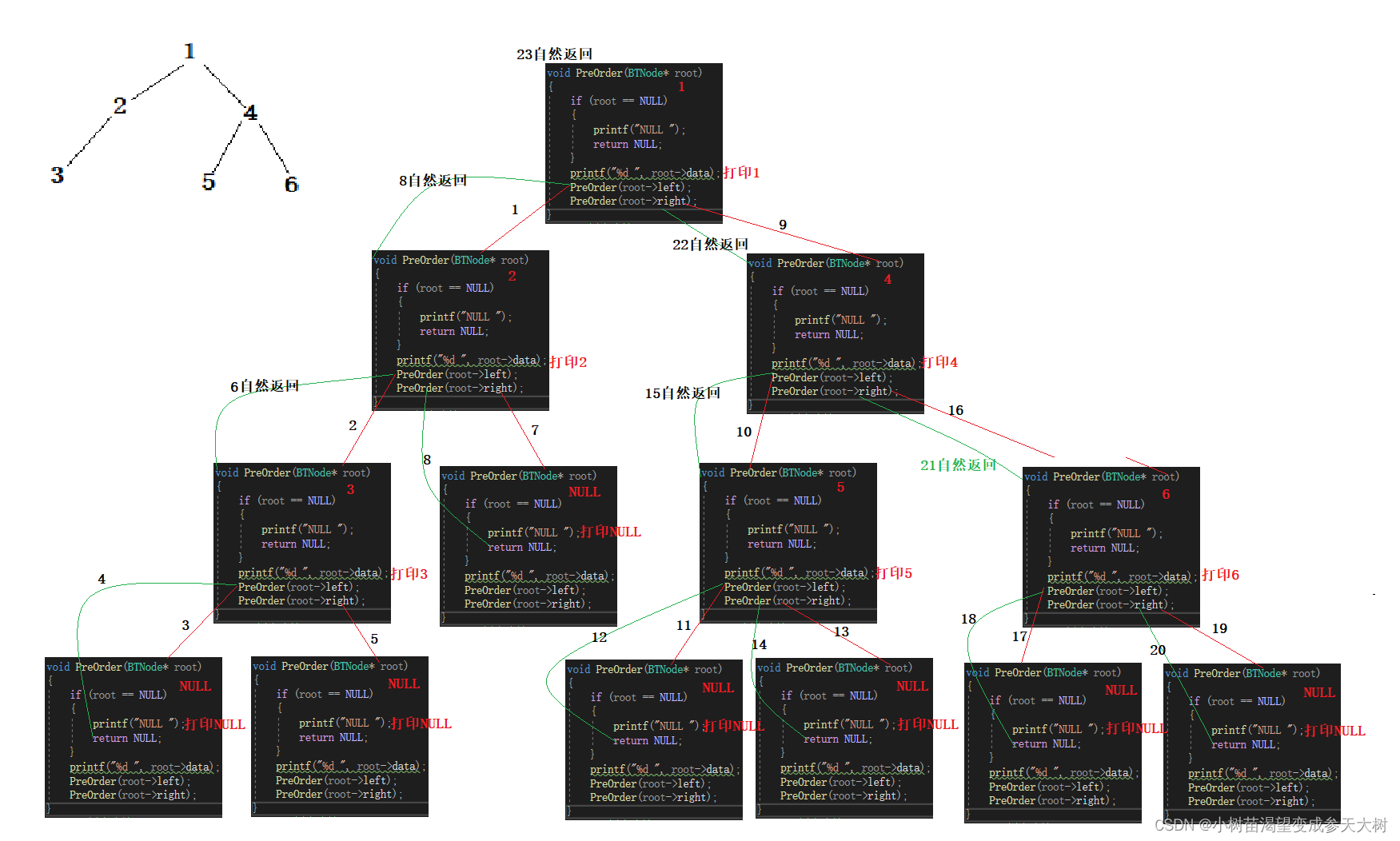
接下来我来话一下递归展开图方大家看看看这个代码是怎么来前序访问结点的:注意跟着我的步骤走
2.2中序遍历
特点是先遍历左子树,在遍历根结点,然后再遍历右子树

void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return NULL;
}
InOrder(root->left);
printf("%d ", root->data);
InOrder(root->right);
}
这个我就不带大家画递归展开图了,大家可以自己下去画画
2.3后序遍历
相信大家看来前两种遍历方法大概知道第三种怎么去写了吧

看代码:
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return NULL;
}
PostOrder(root->left);
PostOrder(root->right);
printf("%d ", root->data);
}
大家一定要去画递归展开图,这一块看起来就几行代码,但是理解了就好了,不太理解的就很难受
接下来我讲解层序遍历
2.4层序遍历
层序遍历的特点是一层一层的遍历,这里我不在使用递归进行操作,因为比较麻烦,我会使用队列来完成这件事,那让我们来看一下队列是解决树的层序遍历的。
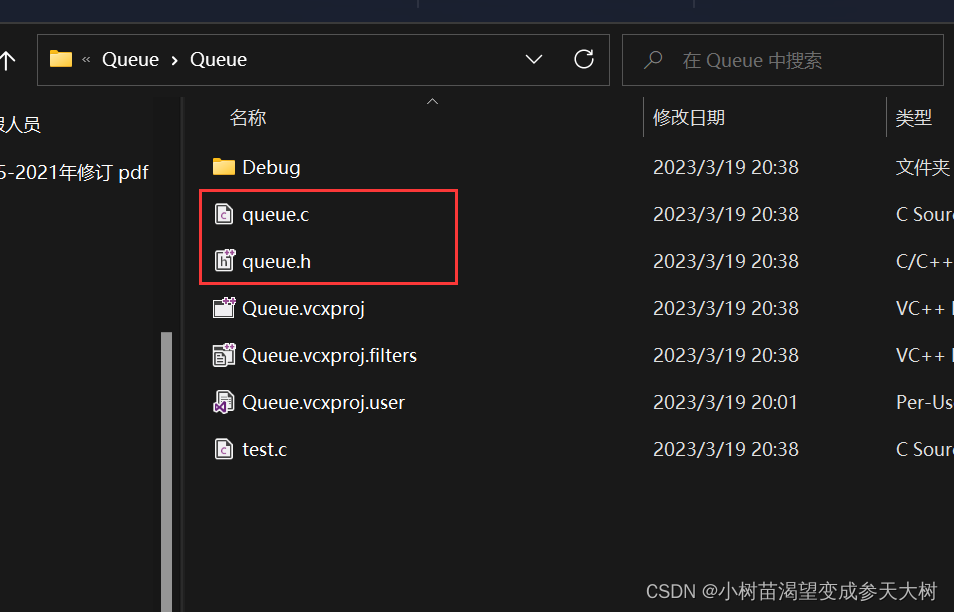
第一步:进入之前写的队列项目文件的目录下,讲两个要用到的队列文件拷贝过来
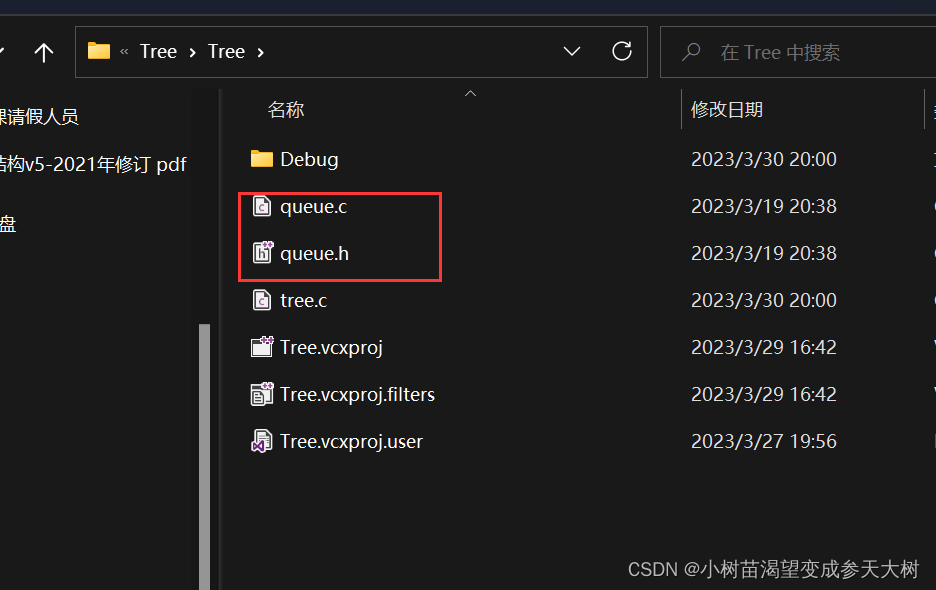
第二步:将这两个文件拷贝到树的文件下
第三步:再vs项目中添加源文件->新建项
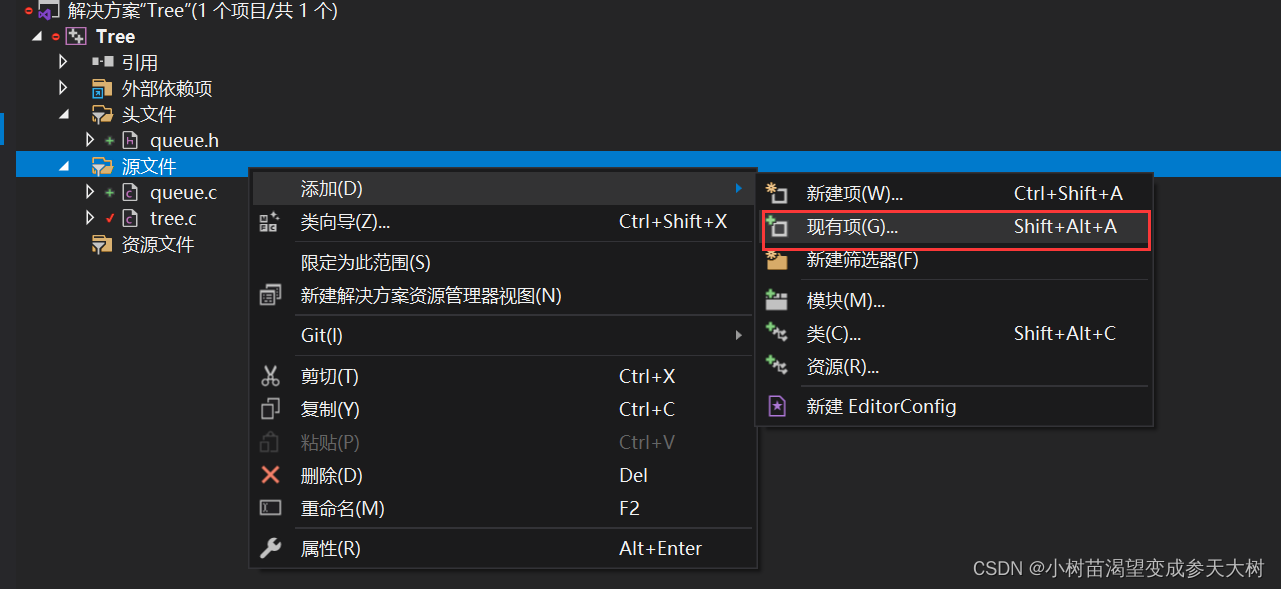
第四步:同时选中刚才那两个文件打开,并且把头文件移到头文件下:
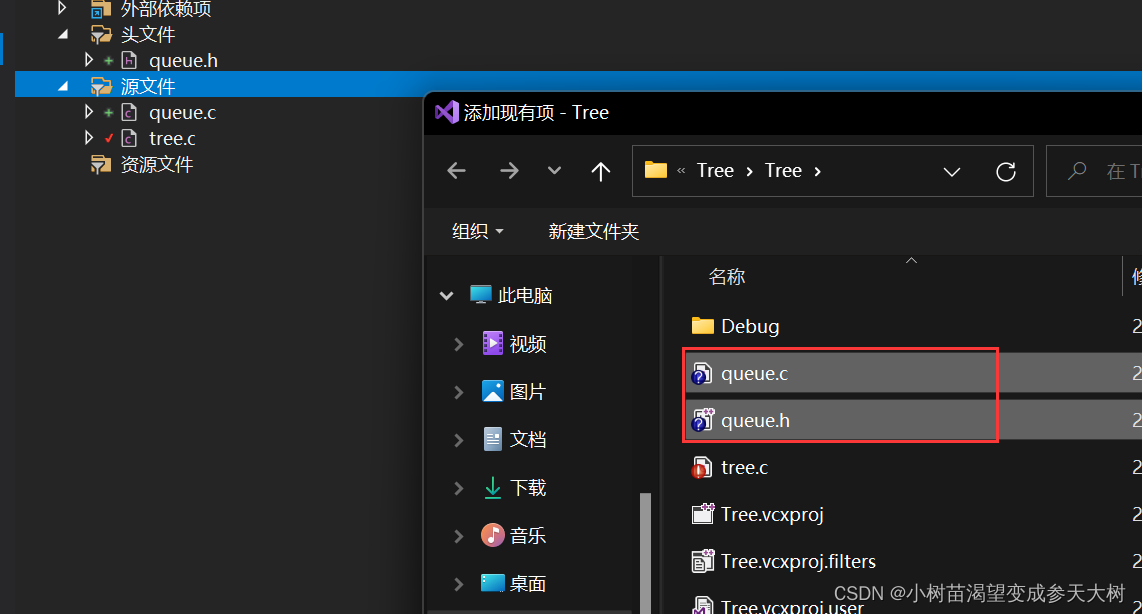
这样我们就导入之前写的队列了,一会就可以直接使用了,要是自己没有写过,可以尝试手撕一下队列,也可以看一下我之前写过的关于队列的博客队列
我们来看层序遍历是怎么使用队列操作的

我们来看代码是怎么实现的:
void LevelOrder(BTNode* root)
{
Queue q;
QueueInit(&q);
if (root != NULL)
{
QueuePush(&q, root);
}
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);//取队头
QueuePop(&q);//出栈
printf("%d ", front->data);
if (front->left != NULL)//不是空入左
{
QueuePush(&q, front->left);
}
if (front->right != NULL)
{
QueuePush(&q, front->right);//不是空入右
}
}
可以跟着走读一遍代码,理解会更深一点,注意一点的是我们再队列存储的不是结点里面的值,而是结点的指针,存值就找不到左右孩子了,这是也体现了我们之前在队列实现typedef的优点了:
typedef struct BTree* QDataType;//存放结点的类型
队列在数的运用后面也会使用的到,在判断完全二叉树的时候会再次使用到
我们来看一下四种遍历的结果是什么:

三、二叉树的结点数和高度
3.1二叉树结点
我们怎么来计算二叉树的结点呢??我们来看一些简单树的结点是怎么计算的:
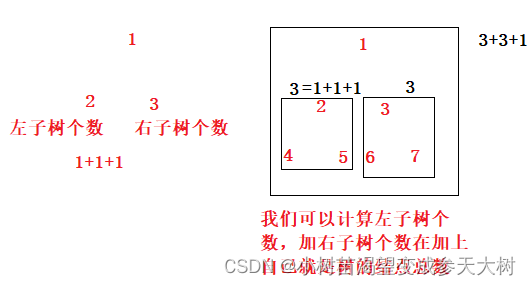
我们来看代码是怎么实现的:
int BinaryTreeSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
int left = BinaryTreeSize(root->left);左子树个数
int right = BinaryTreeSize(root->right);右子树结点个数
return left+right+1;
}
运行结果:
3.2二叉树叶子结点个数
在树的那一篇博客中,我们知道树有很多特点,其中一点就是什么是叶子结点,叶子结点就是没有孩子的结点,根据这个特点我们在刚才求总结点的基础上再加一个条件进行判断不就好了
int BinaryTreeLeafSize(BTNode* root)
{
if(root==NULL)
return 0:
if(root->left==NULL&&root->right==NULL)//控制是否为叶子结点
return 1;
int left=BinaryTreeLeafSize(root->left);左子树叶子结点
int right=BinaryTreeLeafSize(root->right);右子树叶子结点
return left+right;
}

大家如果不太理解,就自己画一下递归展开图
3.3二叉树的高度
我们把树的第一层就看做一层,有几层,树的高度就是多少
我们先来看看简单树的高度怎么求:
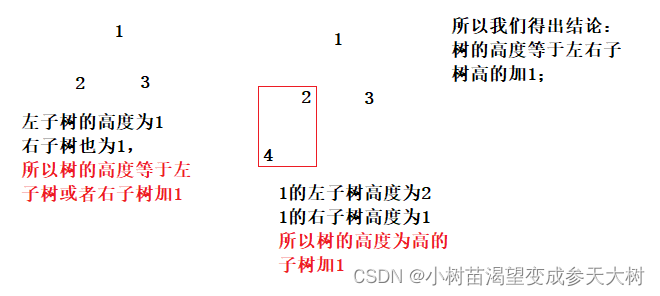
int HeightTree(BTNode* root)
{
if (root == NULL)
return 0;
int m = HeightTree(root->left);//左子树高度
int n = HeightTree(root->right);。。右子树高度
return m > n ? m + 1 : n + 1;
}
我们可以类比求二叉树结点的那个思路去理解这个题目
我们再来看一下另一种写法:
int HeightTree(BTNode* root)
{
if (root == NULL)
return 0;
return HeightTree(root->left) > HeightTree(root->right) ? HeightTree(root->left) + 1 :HeightTree(root->right) + 1;
}
乍一看这种写法和上面的没啥区别,但是,我们来看看,我们再进行判断的时候就要递归两次,再返回结果的是又要递归一次,总共递归三次,所以这种写法效率并不是很高
3.4二叉树的查找值为x的结点
查找我们采取遍历的方式,对结点一个一个的判断,遇到相等就直接返回不需要重新找了,此节点不对就重新找左子树和右子树一步步的往下面走,不为空就返回此结点
希望大家可以自己去理解一下中间的过程:
我们来看一下代码:
BTNode* BinaryTreeFind(BTNode* root, BTDateType x)
{
if (root == NULL)
return NULL;
if (root->data == x)
{
return root;
}
BTNode* left = BinaryTreeFind(root->left, x);
if (left!=NULL)
{
return left;
}
BTNode* right = BinaryTreeFind(root->right, x);
if (right != NULL)
{
return right;
}
return NULL;
}
为什么我们查找的返回值不是布尔值呢??,原因是我们经常讲查找和修改的操作放在一起,找到这个值并且去修改
BTNode* ret = BinaryTreeFind(node, 8);
if (ret != NULL)
{
printf("找到了!\n");
ret->data = 100;//修改他的值为100
printf("%d", ret->data);
}
else
{
printf("没有找到!");
}
相信大家对查找应该都理解了,其实上面讲的四个操作本质都是一样的,我们都是采取递归的思想,把大事化小,都是从一颗最简单的树开始找规律,然后一棵树一棵树的遍历,就能很好的解决问题,后面我会出一期关于二叉树相关的题目,大家可以来学习学习。采用的思想和上面的大同小异
四、判断是否为完全二叉树
完全二叉树的特点是除最后一层,上面的每一层都是满的,最后一层并且是从左到右是连续的
由于完全二叉树的结点不是固定的,不像满二叉树可以通过结点总个数来判断,使用递归也特别麻烦,结束条件不好控制,再层序遍历的时候,我讲过,队列会继续用到的,那我们怎么通过队列来判断完全二叉树,接下来我将举两个例子:
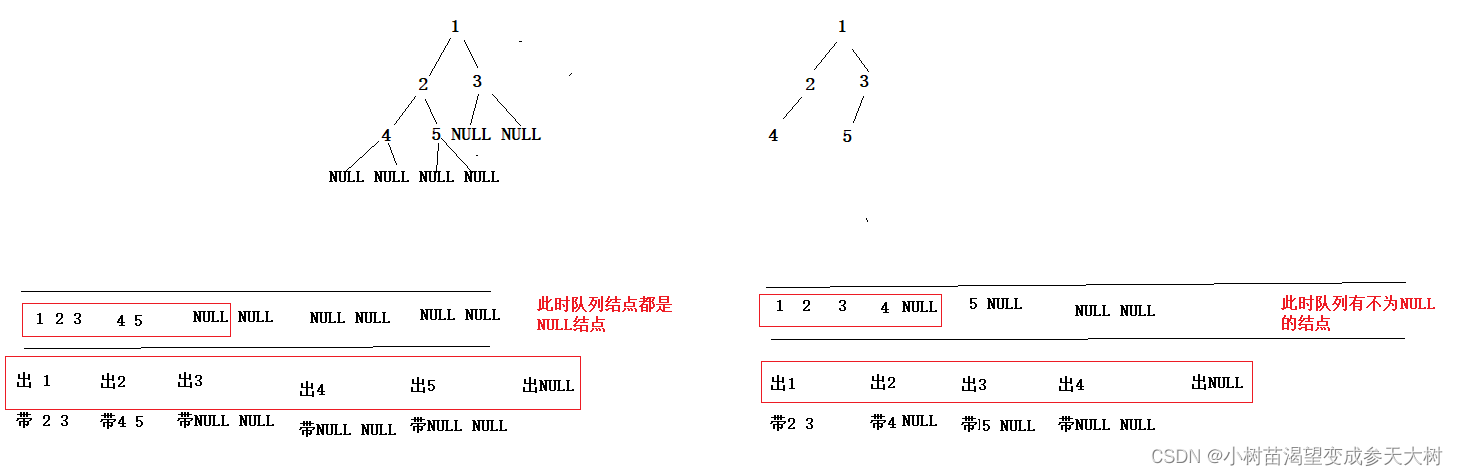
大家看到左边的为完全二叉树,右边不是完全二叉树,所以队列出到第一个NULL结点的时候,就去检查队列其他结点都是NULL结点,就是完全二叉树,否则就不是,不是队列为NULL,是队列里结点为NULL
我们一起来看一下代码更加的直观:
bool BinaryTreeComplete(BTNode* root)//判断是否为完全二叉树
{
Queue q;
QueueInit(&q);
if (root != NULL)
{
QueuePush(&q, root);
}
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front == NULL)//出现第一个NULL结点就退出
{
break;
}
else
{
QueuePush(&q, front->left);
QueuePush(&q, front->right);//不管是啥直接入队列,即使是NULL;
}
}
while (!QueueEmpty(&q))//判断是否为完全二叉树,如果队列全为NULL结点,就是完全二叉树,否则就不是
{
if (QueueFront(&q))
{
return false;
}
QueuePop(&q);
}
return true;
}
这题思路和层序遍历几乎一样的,希望可以把这个弄明白
五、总结
对于二叉树这一篇足够带你先入门了,大家学知识由浅到深,由易到难,接下来会出一片关于二叉树题目的博客,到时候欢迎大家过来学习,这篇的知识一定要自己去理解,后面才能学习的更好,那今天的知识我们就分享到这里了,我们下篇再见。

















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











