






 本文讲述了作者解决京东爬虫问题的过程,包括从数据库和消息队列获取数据,引入jsoup解析网页,重点在于处理Cookie以克服京东的防护机制,以及懒加载图片的抓取。
本文讲述了作者解决京东爬虫问题的过程,包括从数据库和消息队列获取数据,引入jsoup解析网页,重点在于处理Cookie以克服京东的防护机制,以及懒加载图片的抓取。
解决京东爬虫失败问题
(一)、爬虫
1.数据从哪里获取
- 数据库获取。
- 消息队列中获取中。
- 爬虫
2.导入爬虫的依赖
tika包解析电影的.jsoup解析网页
<!-- jsoup解析网页-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
3.编写爬虫工具类
(1).实体类
package com.jsxs.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @Author Jsxs
* @Date 2023/6/30 13:06
* @PackageName:com.jsxs.pojo
* @ClassName: Content
* @Description: TODO
* @Version 1.0
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Content {
private String title;
private String img;
private String price;
}
(2).工具类编写 (2023年09月07日 已废弃⭐)
package com.jsxs.utils;
import com.jsxs.pojo.Content;
import org.elasticsearch.common.recycler.Recycler;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
/**
* @Author Jsxs
* @Date 2023/6/30 12:40
* @PackageName:com.jsxs.utils
* @ClassName: HtmlParseUtil
* @Description: TODO
* @Version 1.0
*/
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keywords) throws Exception {
// 1.获得请求
String url = "https://search.jd.com/Search?keyword="+keywords;
// 2.解析网页 返回的document对象就是浏览器的Document对象
Document document = Jsoup.parse(new URL(url), 3000);
// 3.利用js的Document对象进行操作 ->获取商品整个html页面
Element element = document.getElementById("J_goodsList");
// 4.获取所有的li元素 是一个集合。
Elements elements = element.getElementsByTag("li");
// 创建一个链表,用于存放我们爬取到的信息
ArrayList<Content> contents = new ArrayList<>();
// 5.获取元素中的各个内容
for (Element li : elements) {
// 获取图片 这里面加上attr目的是懒加载。
String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img"); // 爬取懒加载的图片
// 获取价格
String price = li.getElementsByClass("p-price").eq(0).text();
// 获取上坪的价格
String title = li.getElementsByClass("p-name").eq(0).text();
// 存放我们爬取到的信息
contents.add(new Content(title,img,price));
}
return contents;
}
public static void main(String[] args) throws Exception {
for (Content java : new HtmlParseUtil().parseJD("码出高效")) {
System.out.println(java);
}
}
}
结果: 发现运行结果为null
(3).工具类编写 - 解决京东防护
1.先获取 cookie值
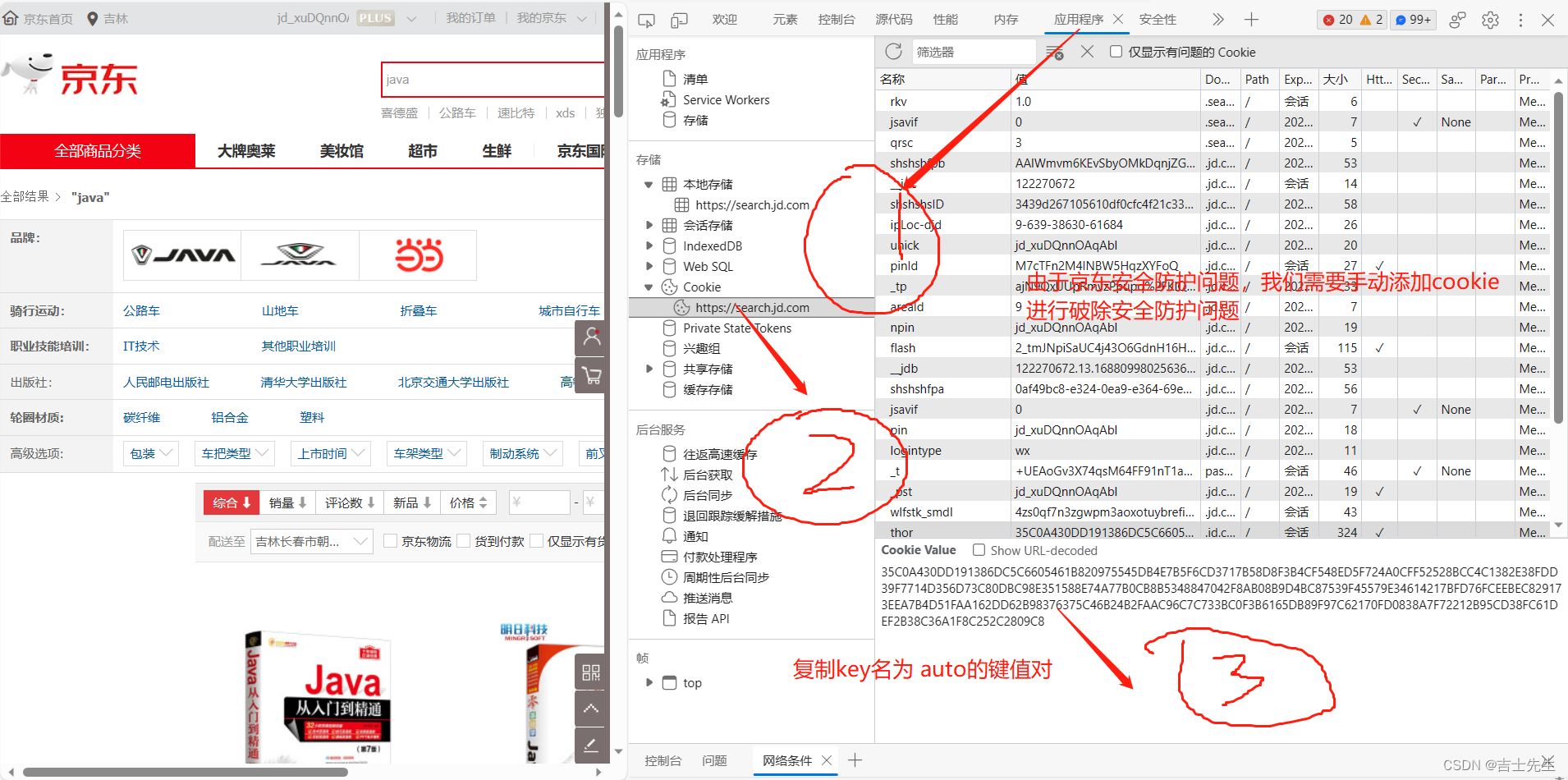
2.在已废弃的工具类上添加
// 设置cookie
Map<String, String> cookies = new HashMap<String, String>();
cookies.put("thor", "35C0A430DD191386DC5C6605461B820975545DB4E7B5F6CD3717B58D8F3B4CF548ED5F724A0CFF52528BCC4C1382E38FDD39F7714D356D73C80DBC98E351588E74A77B0CB8B5348847042F8AB08B9D4BC87539F45579E34614217BFD76FCEEBEC829173EEA7B4D51FAA162DD62B98376375C46B24B2FAAC96C7C733BC0F3B6165DB89F97C62170FD0838A7F72212B95CD38FC61DEF2B38C36A1F8C252C2809C8");
// 2.解析网页 返回的document对象就是浏览器的Document对象
Document document = Jsoup.connect(url).cookies(cookies).get();
4.最终解决完整代码
添加位置为 : 星星标记处。
package com.jsxs.utils;
import com.jsxs.pojo.Content;
import org.elasticsearch.common.recycler.Recycler;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Author Jsxs
* @Date 2023/6/30 12:40
* @PackageName:com.jsxs.utils
* @ClassName: HtmlParseUtil
* @Description: TODO
* @Version 1.0
*/
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keywords) throws Exception {
// 1.获得请求
String url = "https://search.jd.com/Search?keyword="+keywords;
System.out.println(url);
// 设置cookie ⭐
Map<String, String> cookies = new HashMap<String, String>();
cookies.put("thor", "35C0A430DD191386DC5C6605461B820975545DB4E7B5F6CD3717B58D8F3B4CF548ED5F724A0CFF52528BCC4C1382E38FDD39F7714D356D73C80DBC98E351588E74A77B0CB8B5348847042F8AB08B9D4BC87539F45579E34614217BFD76FCEEBEC829173EEA7B4D51FAA162DD62B98376375C46B24B2FAAC96C7C733BC0F3B6165DB89F97C62170FD0838A7F72212B95CD38FC61DEF2B38C36A1F8C252C2809C8");
// 2.解析网页 返回的document对象就是浏览器的Document对象 ⭐⭐
Document document = Jsoup.connect(url).cookies(cookies).get();
// 3.利用js的Document对象进行操作 ->获取商品整个html页面
Element element = document.getElementById("J_goodsList");
System.out.println("***************"+element);
// 4.获取所有的li元素 是一个集合。
Elements elements = element.getElementsByTag("li");
// 创建一个链表,用于存放我们爬取到的信息
ArrayList<Content> contents = new ArrayList<>();
// 5.获取元素中的各个内容
for (Element li : elements) {
// 获取图片 这里面加上attr目的是懒加载。
String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img"); // 爬取懒加载的图片
// 获取价格
String price = li.getElementsByClass("p-price").eq(0).text();
// 获取上坪的价格
String title = li.getElementsByClass("p-name").eq(0).text();
// 存放我们爬取到的信息
contents.add(new Content(title,img,price));
}
return contents;
}
public static void main(String[] args) throws Exception {
for (Content java : new HtmlParseUtil().parseJD("java")) {
System.out.println(java);
}
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











