







目录
本论文涉及的代码仓库链接:
github地址:https://github.com/Anni-Zou/Meta-CoT
gitcode地址:GitCode - 全球开发者的开源社区,开源代码托管平台
概述:
这篇文章《Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models》由上海交通大学的Anni Zou、Zhuosheng Zhang、Hai Zhao以及耶鲁大学的Xiangru Tang共同撰写,探讨了在未知类型输入问题的大型语言模型(LLMs)中,如何通过思维链(Chain-of-Thought,CoT)提示来提高推理能力。文章提出了一种名为GeM-CoT的通用CoT提示机制,用于处理混合任务场景中的问题。
背景与挑战:
大型语言模型(LLMs)通过CoT提示展现出了卓越的推理能力,但现有的CoT方法要么依赖于通用提示,要么依赖于特定任务的示例,这限制了模型的泛化能力。 ◦ 在实际应用中,LLMs常面临混合类型的问题,这些问题未被预先识别归属于哪个任务,因此需要一种新的处理机制。
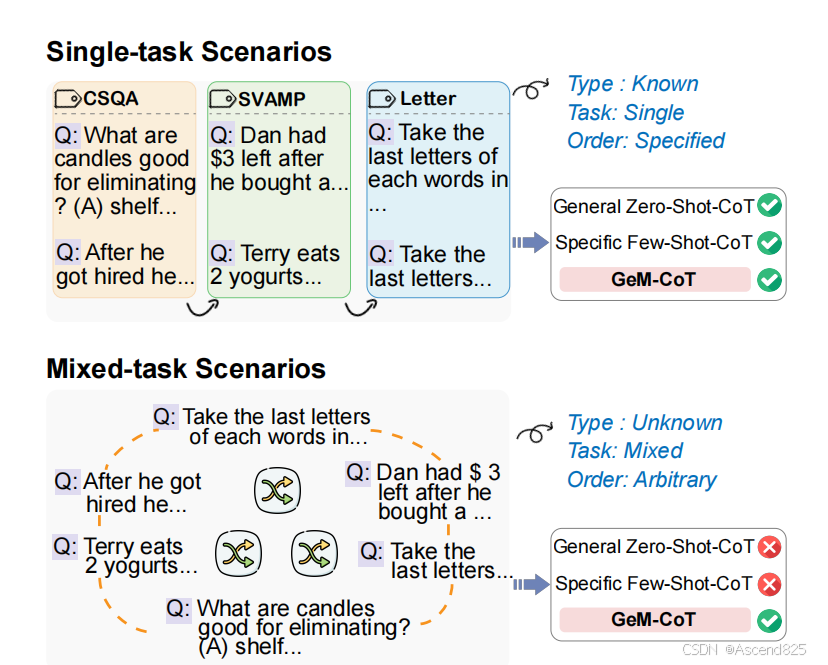
GeM-CoT机制:
GeM-CoT首先对问题进行分类,然后从相应的数据池中自动采样或构建示例。 ◦ 如果输入问题与数据池中的某个类型成功匹配,GeM-CoT会从数据池中获取匹配类型的示例,并进行最终推理以获得答案。 ◦ 如果匹配失败,则通过零样本推理得出答案,并通过基于密度的聚类更新数据缓存,并自动为满足要求的聚类中的数据构建多样化的示例。
模型框架图:
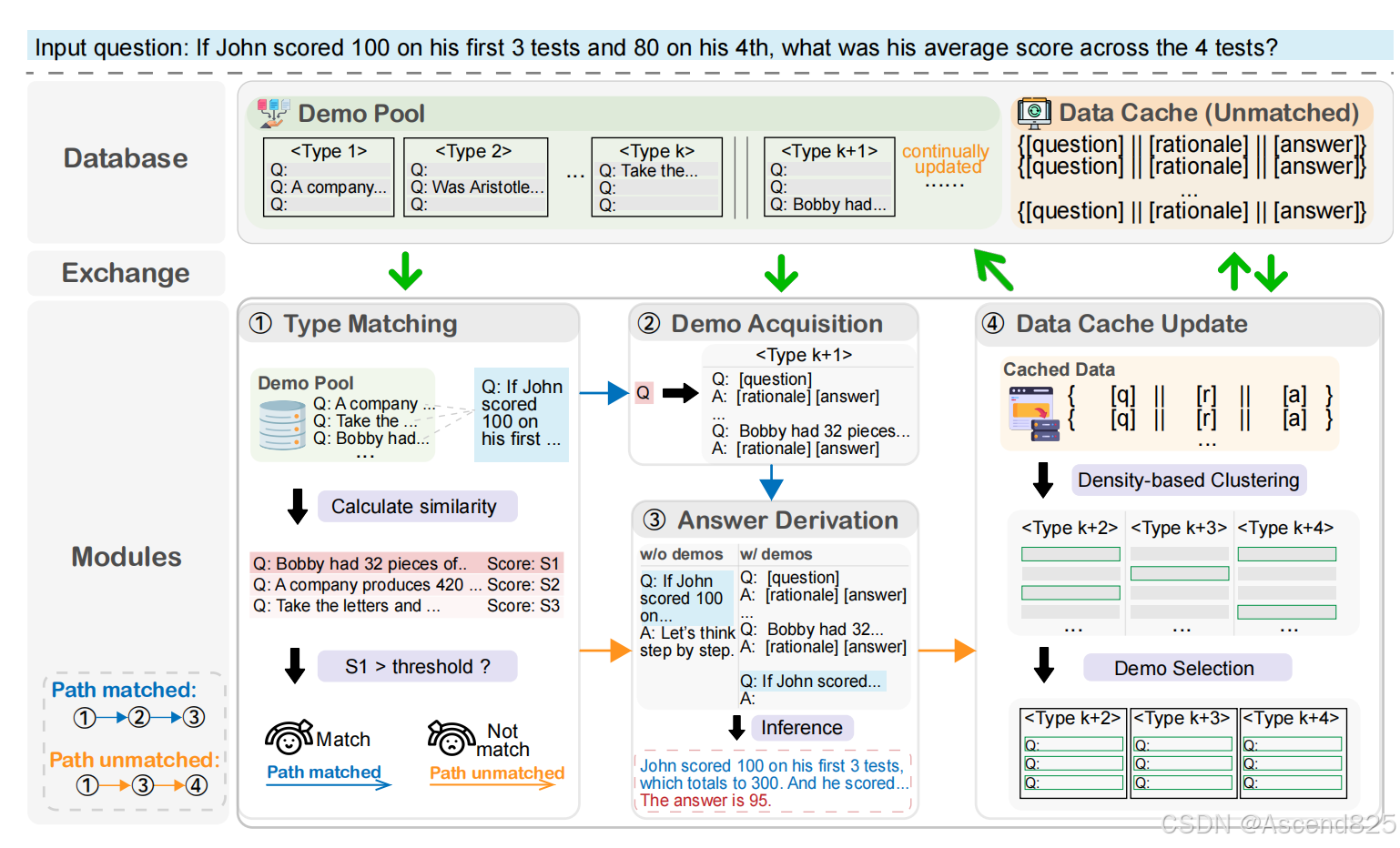
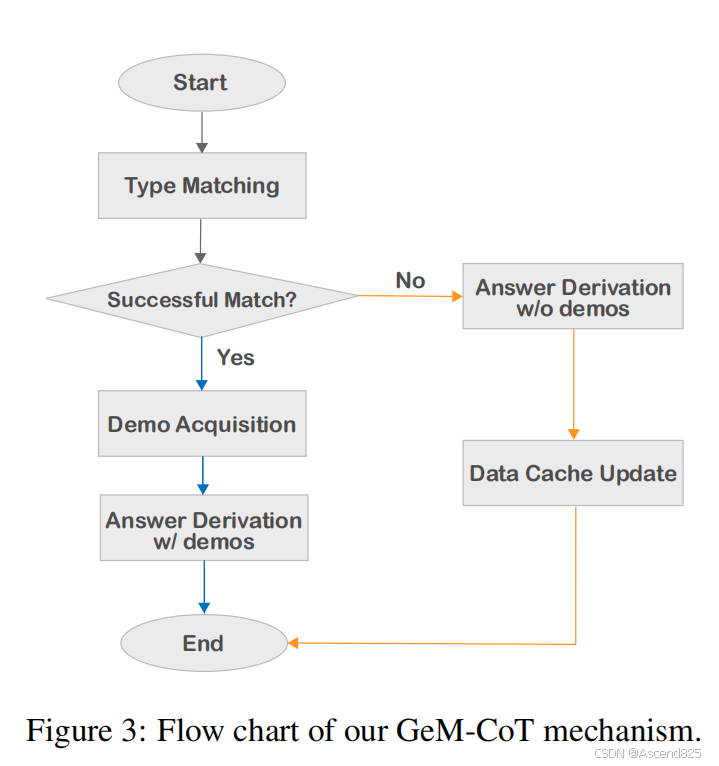
实验设置:
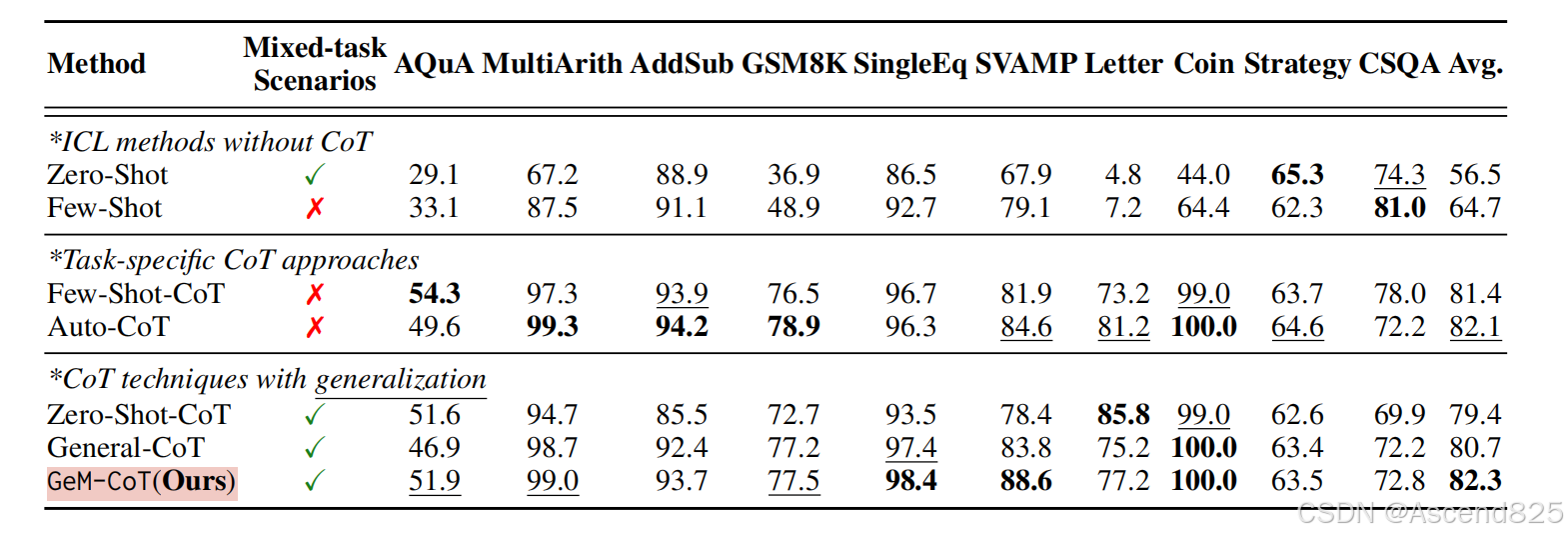
在10个推理数据集和23个BBH任务上评估GeM-CoT,使用GPT-3.5-Turbo和GPT-4模型进行实验。
实验结果:
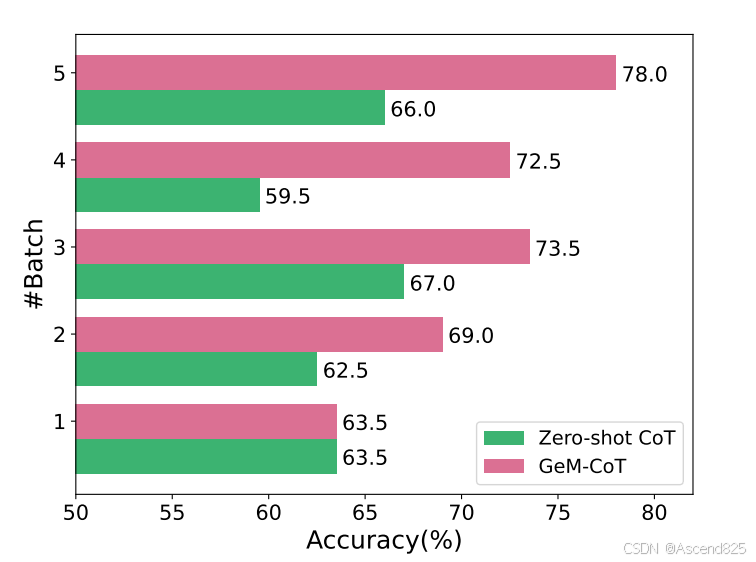
GeM-CoT在10个公共推理任务和23个BBH任务上表现出色,不仅提高了泛化能力,还提升了性能。
相关工作:
讨论了CoT提示和跨任务泛化的相关研究,指出现有研究的局限性,并强调了在混合任务场景中实现泛化的重要性。
实验设置:
在10个推理数据集和23个BBH任务上评估GeM-CoT,使用GPT-3.5-Turbo和GPT-4模型进行实验
结论与局限:
GeM-CoT在混合任务场景中展现了卓越的性能和泛化能力,但也存在局限性,如对推理过程的改进不足,以及在混合任务场景中选择高质量示例的方法可能还有待提高。


















 8187
8187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









