







一、前言
Megrez-3B-Omni是由无问芯穹(Infinigence AI)研发的端侧全模态理解模型,基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力,在三个方面均取得最优精度:
- 在图像理解方面,基于SigLip-400M构建图像Token,在OpenCompass榜单上(综合8个主流多模态评测基准)平均得分66.2,超越LLaVA-NeXT-Yi-34B等更大参数规模的模型。Megrez-3B-Omni也是在MME、MMMU、OCRBench等测试集上目前精度最高的图像理解模型之一,在场景理解、OCR等方面具有良好表现。
- 在语言理解方面,Megrez-3B-Omni并未牺牲模型的文本处理能力,综合能力较单模态版本(Megrez-3B-Instruct)精度变化小于2%,保持在C-EVAL、MMLU/MMLU Pro、AlignBench等多个测试集上的最优精度优势,依然取得超越上一代14B模型的能力表现。
- 在语音理解方面,采用Qwen2-Audio/whisper-large-v3的Encoder作为语音输入,支持中英文语音输入及多轮对话,支持对输入图片的语音提问,根据语音指令直接响应文本,在多项基准任务上取得了领先的结果。
因此作者想将其部署到本地作为辅助工具,在实际部署中也遇到了一些问题,所以便记录下来。
二、部署教程
最开始作者是想在LM Studio上部署的,但是将模型下载下来后发现LM Studio并不支持上传文件的操作,后来经过查询得知只有一小部分模型能够得到LM Studio的视觉支持,这些模型在下载时会有明显的标识的,因此作者智能按照官方的方法去部署了。
首先我们需要去github将模型部署需要的文件下载下来,链接在这:link
下载下来的文件如下图所示:

然后我们还需要在Hugging Face上将模型文件下载下来,这个模型文件在LM Studio中是找不到的,只能手动在网站上下载,搜索Infinigence/Megrez-3B-Omni即可,也可以直接复制下面的命令使用Git下载:
//首先确定已经安装git lfs
git lfs install
//然后直接克隆存储库即可
git clone https://huggingface.co/Infinigence/Megrez-3B-Omni
//如果你想克隆一个包含大文件的 Git 仓库,但只下载这些大文件的指针信息,而不下载实际的大文件内容的话可以用下面的命令
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Infinigence/Megrez-3B-Omni
这里扩展一下Git LFS:Git LFS(Large File Storage,大型文件存储)是Git的一个扩展工具,旨在优化Git在处理大型文件时的表现。它通过将大文件的实际内容存储在远程服务器上,并在本地Git仓库中仅保留指向这些文件的指针来实现这一点。这种方式不仅提高了版本控制系统的效率,还减少了本地仓库的大小,使得克隆、拉取和推送操作更加迅速。
但是这里下载有些问题,当clone到lfs文件时是无法实时下载进度条的,此时你并不知道是否是出现了问题,因此下面是一个可以显示进度条的方法:
//首先将环境变量GIT_LFS_SKIP_SMUDGE设置为1
//然后快速克隆完成后cd进入克隆完成后的目录
//最后git lfs pull就能显示进度条了
将模型文件夹Megrez-3B-Omni放入我们一开始从github中下载下来的Infini-Megrez-Omni-main文件夹中,如下图:
然后我们需要创建环境,我个人建议python版本为3.10.8,环境创建好后pip install -r requirements.txt导入包,还有一点是音频支持是需要下载ffmpeg的,然后这里还需要下载pytorch的GPU版本,否则会报AssertionError: Torch not compiled with CUDA enabled的错误。
下载pytorch可能会遇到点坑,这里总结一下:
首先就是nvidia-smi :

此时出现的cuda版本是只你的显卡最高所能支持的cuda版本,并非是你的cuda版本,要想显示你的cuda版本需要用nvcc -V这个命令:

这个release后面的12.6才是你的cuda版本,因此你需要根据这个cuda版本去下载pytorch,上面的那个cuda版本是依赖于显卡驱动的版本的,也就是Driver Version。
根据这个从pytorch官网的版本下载好pytorch后就可以直接从命令行中输入下面的命令运行模型了,注意要指明模型文件夹的路径:
python gradio_app.py --model_path your/path
这时你可能会报端口冲突的问题,所以我们需要在gradio_app.py这个文件中改几行代码:
//将default修改成你不冲突的端口即可
parser.add_argument("--port", type=int, default=7980)
如果你挂着代理还会遇到连接不上本地的问题,此时有三个选择,一是修改代理配置,二是取消代理,三是如下方法创建共享连接,这个连接是挂到远程网站的:
//修改gradio_app.py这个文件的代码
demo.launch(server_port=port)
//改成
demo.launch(server_port=port,share=True)
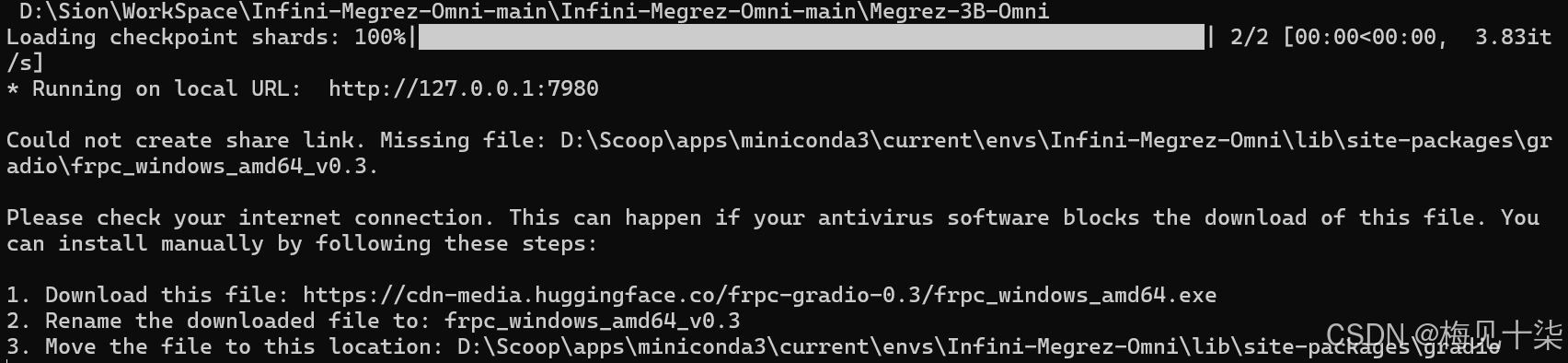
如果你遇到下图中的问题只要按照它的步骤解决即可,这是因为创建远程连接需要下载个文件,而这个文件是需要魔法才能下载的。
最后成功的话就是像下图这样,点击远程的的公共链接即可访问,同时也可以点击本地的这个链接。

三、总结
最后经过测试后发现本地部署大模型的性能并不是很好,还不如直接访问那些免费的大模型,让这个模型处理一张图片运行了这么久都没有运行出来换成在线模型早都出来了,果然AI的发展还是需要算力的提升啊。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











