







1. 简要介绍
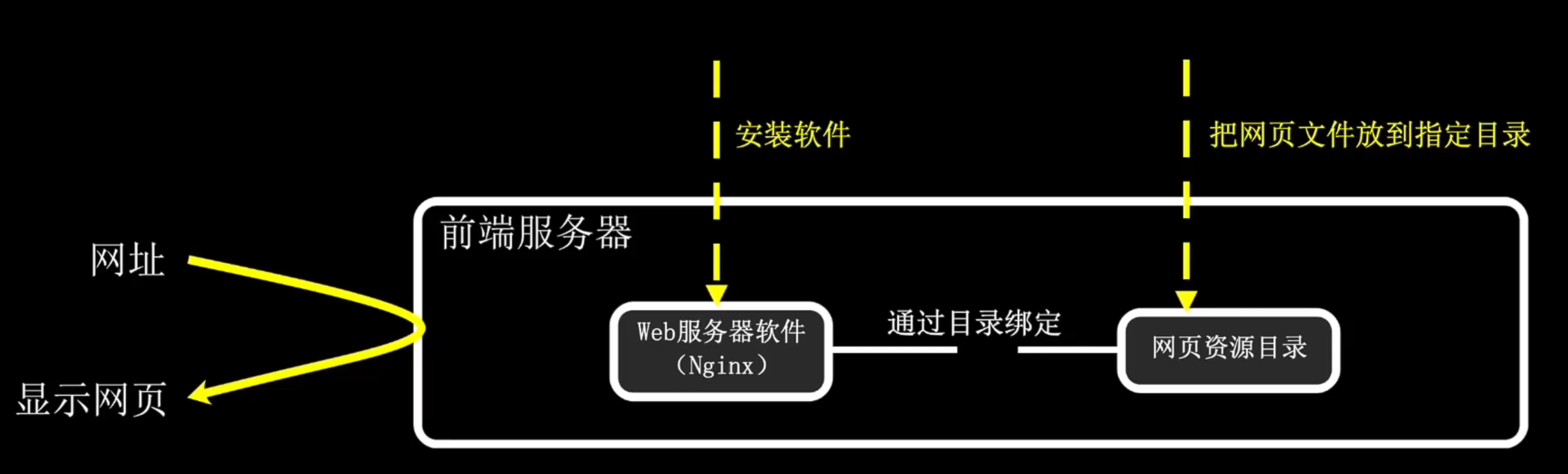
先安装好Ngnix或者Apache,接着把写好的网页文件放到指定目录,然后在浏览器中输入网址就可以打开网页了。
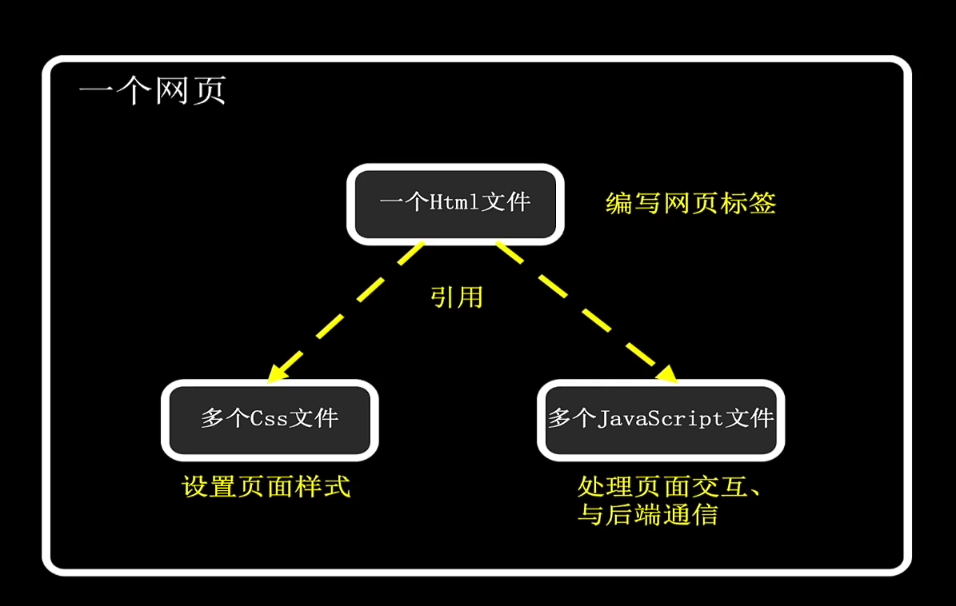
至于网页文件一般只有三种:html(骨架)、css(设置样式,大小、颜色、位置等)、javascript文件一般是处理交互或者与后端通信的。但是只知道前端网页的这些基础知识是不够的,特别是想成为前端架构师的程序员。
下面分两个部分讲解前端网页的工作原理。
2. 前端网页的工作原理
2.1. 浏览器加载网页
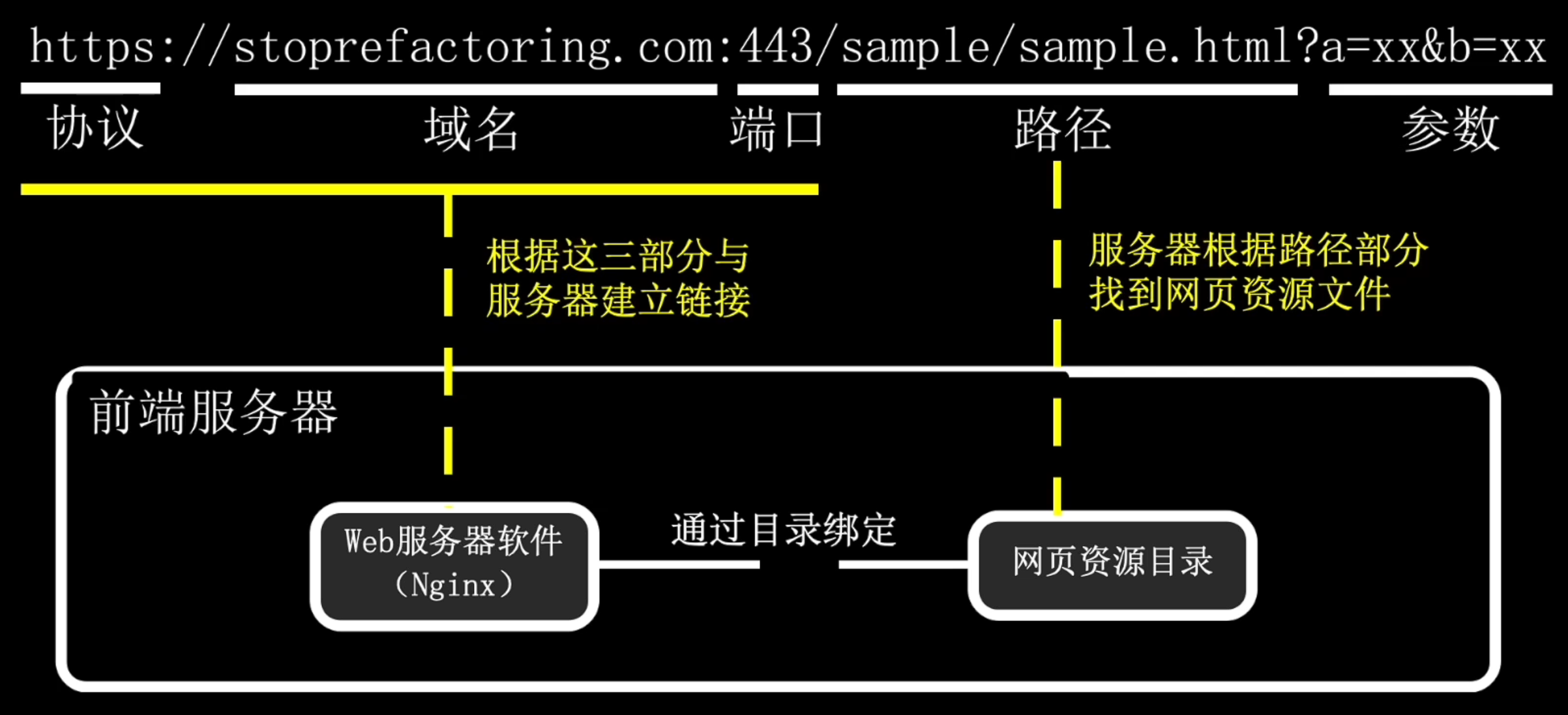
先安装好Ngnix或者Apache,接着把写好的网页文件放到指定目录,然后在浏览器中输入网址就可以打开网页了。
至于网页文件一般只有三种:html(骨架)、css(设置样式,大小、颜色、位置等)、javascript文件一般是处理交互或者与后端通信的。但是只知道前端网页的这些基础知识是不够的,特别是想成为前端架构师的程序员。
下面分两个部分讲解前端网页的工作原理。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























