







一、什么是SparkSQL
1-1 介绍
Spark SQL是 Apache Spark 用于处理结构化数据(DataFrame和Datasets)的模块。
1-1-1 数据结构分类
- 结构数据
- 就是表结构数据,有行列组成,并且描述了数据的属性(字段)和类型 ,表信息
- string int
- 半结构化数据 spark中可以通过方法将半结构化数据转化为结构化数据
- xml 和json
- 描述数据的存储结构,但是无法描述数据的类型
<name>zhansan</name>
<age>18</age>
{
name:zhangsan
}
- 非结构化数据 rdd可以处理
- 文本 ,图片,视频
1-2 特点
- 易整合
- 使用sql配合spark一起使用,封装了不同语言的dsl方法
- 统一数据访问
- 使用read方法可以读取hdfs数据,mysql数据,不同类型的文件数据(json,csv,orc)
- 使用write方法可以写入hdfs,mysql不同类型的文件
- 兼容hive
- 使用hivesql方法
- 标准的数据连接
- 使用jdbc和odbc连接方式连接sparkSQL
1-3 SparkSQL与hiveSQL关系
- shark
- 运行的模式是hive on spark
- 会将hivesqsl转换为spark的rdd
- shark是基于hive开的,维护麻烦,2015年停止维护
- sparkSQL
- 是spark团建独立开发的工具,2014年发布1.0版本
- sparkSQL工具对spark的兼容性更好,优化性能得到提升
- sparkSQL本质也是将sql语句转化为rdd执行,catalyst引擎负责将sql转化为rdd
- sparkSQL可以连接使用hive的metastore服务,管理表的元数据
1-4 数据模型
spark封装一个基础数据模型(数据类型)rdd
然后根据rdd进行再次封装,得到新的数据类型 dataframe
然后根据dataframe再次封装得到了dataset类型
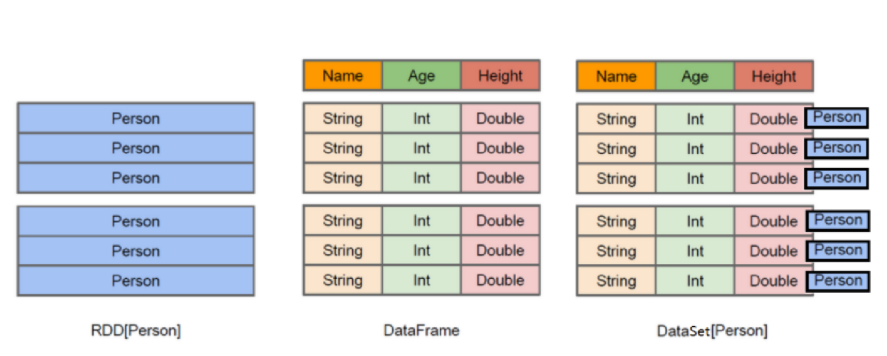
- rdd 弹性分布式集合 使用Python ,java,scala,c,R
[1,张三,20,2,李四,30]
- dataframe类型 结构化数据 行列,表信息(数据的属性(字段)和类型) 使用Python ,java,scala,c,R
- Row类 行数据 rdd中一个列表元素
- Schema类 表信息
[
[1,张三,20], Row1()
[2,李四,30], Row2()
]
Schema
1:id int
2:name string
3:age int
- datasets类型 机构化数据 java,scala
- Row类 一行数据 一个dataframe
- Schema类 表信息
- 从dataset中取出一行数据可以当做datafram类型操作
[
第一行 datafrema[row,scheme]
第二行 datafrema[row,scheme]
]
Schema
1:id int
2:name string
3:age int
二、DataFrame的详解(
- Row 类型 表示一行数据
- datafram就算是多行构成
[
row1,
row2
]
from pyspark.sql import Row
# 不指定字段名
# 定义每行数据
r1 = Row(1,'张三',20)
r2 = Row(2,'李四',22)
# 取行中的数据,没有字段名通过下标取值
print(r1[0])
print(r1[1])
# 定义每行数据 指定字段名
r3 = Row(id=1,name='张三',age=20)
r4 = Row(id=2,name='李四',age=22)
# 通过字段名取值
print(r4['name'])
print(r4['age'])
- schema表信息
- 定义dataframe中的表的字段名和字段类型
from pyspark.sql.types import *
# 定义表信息
# add方法添加指定表信息
# 第一个参数 字段名
# 第二个参数 字段类型
# 第二个参数 是否允许为空值 默认允许 。 nullable=False 不允许
schema_type = StructType().\
add('id',IntegerType()).\
add('name',StringType()).\
add('age',IntegerType(),nullable=False)
三、DataFrame创建
- 基本创建
# 定义行数据导入row,创建dataframe需要导入SparkSession
from pyspark.sql import SparkSession,Row
# 定义表信息需要导入类型
from pyspark.sql.types import *
# 定义行数据
# 定义每行数据
r1 = Row(1,'张三',20)
r2 = Row(2,'李四',22)
# 定义每行数据 指定字段名
r3 = Row(id=1,name='张三',age=20)
r4 = Row(id=2,name='李四',age=22)
# 定义表信息
schema_type = StructType().\
add('user_id',IntegerType()).\
add('username',StringType()).\
add('age',IntegerType(),nullable=False)
# 创建dataframe 需要用到SparkSession类的对象,该对象有创建方法
# 固定的创建格式
ss = SparkSession.builder.getOrCreate()
# createDataFrame 创建dataframe数据 返回一个dataframe的类对象
#第一参数传递row行数据
# 第二参数 传递表信息
df = ss.createDataFrame([r1,r2],schema_type)
# 查看df数据信息 内部会自动print
df.show()
# 查看表结构信息
df.printSchema()
# 注意点
# 1、定义行数据时指定字段名,定义schema也指定不一样的字段名,以schema中定义的字段为主
# 2、定义的schema的字段个数和row的字段个数不一致,会报错,需要保持数量一致
# 3、定义的schema的字段类型和row的字段类型不一致,讲义定义类型时和实际数据类型保持一致
# 创建新的df
df2 = ss.createDataFrame([r3,r4],schema_type)
# 查看
df2.show()
- rdd的二维数据转化为dataframe
- rdd.toDF()
# 使用sparksql都要SparkSession
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 创建SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 在SparkSession对象下有一个sparkcontext对象属性
# 获取sparkcontext对象 不需要加括号
sc = ss.sparkContext
# 转化rdd 需要一个二维嵌套列表
rdd = sc.parallelize([
[1,'张三',20],
[2,'李四',22]
])
#rdd转为df
# 接收schema信息
schema_type = StructType().\
add('id',IntegerType()).\
add('name',StringType()).\
add('age',IntegerType(),nullable=False)
df = rdd.toDF(schema_type)
df.show()
- 案例 读取学生数据转化为DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 1、生成SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 2、获取sparkcontext对象
sc = ss.sparkContext
# 3、 读取文件数据转为rdd
rdd = sc.textFile('/student')
# 4、查看rdd数据
print(rdd.collect())
# 5、对每行数据进行切割
rdd_map = rdd.map(lambda x:[int(x.split(',')[0]),x.split(',')[1],x.split(',')[2],int(x.split(',')[3]),x.split(',')[4]])
print(rdd_map.collect())
# 6、rdd转df
# 7、定义 表信息
schema_type= StructType().\
add('id',IntegerType()).\
add('name',StringType()).\
add('gender',StringType()).\
add('age',IntegerType()).\
add('cls',StringType())
df = rdd_map.toDF(schema_type)
df.show()
- df转为rdd
# df数据重新转为rdd
print(df.rdd.collect())
rdd_map1 = df.rdd.map(lambda x:x[0])
print(rdd_map1.collect())
rdd_map2 = df.rdd.map(lambda x:x['name'])
print(rdd_map2.collect())
四、DataFrame基本使用(
4-1 DSL方法
spark提供DSL方法和sql的关键词一样,使用方式和sql基本类似,在进行数据处理时,要按照sql的执行顺序去思考如何处理数据
from join 知道数据在哪 df本身就是要处理的数据 df.join(df2)
where 过滤需要处理的数据 df.join(df2).where()
group by 聚合 数据的计算 df.join(df2).where().groupby().sum()
having 计算后的数据进行过滤 df.join(df2).where().groupby().sum().where()
select 展示数据的字段 df.join(df2).where().groupby().sum().where().select()
order by 展示数据的排序 df.join(df2).where().groupby().sum().where().select().orderBy()
limit 展示数据的数量 df.join(df2).where().groupby().sum().where().select().orderBy().limit()
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 1、生成SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 2、获取sparkcontext对象
sc = ss.sparkContext
# 3、 读取文件数据转为rdd
rdd = sc.textFile('/student')
# 4、查看rdd数据
# 5、对每行数据进行切割
rdd_map = rdd.map(lambda x:[int(x.split(',')[0]),x.split(',')[1],x.split(',')[2],int(x.split(',')[3]),x.split(',')[4]])
# 6、rdd转df
# 7、定义 表信息
schema_type= StructType().\
add('id',IntegerType()).\
add('name',StringType()).\
add('gender',StringType()).\
add('age',IntegerType()).\
add('cls',StringType())
df = rdd_map.toDF(schema_type)
# 显示所有内容
df.show()
# df数据操作
# 第一种方式,使用dsl方法
# select() 指定显示的字段 返回结果是一个新的df
df_select = df.select(df['id'],df['name'])
df_select2 = df.select(['id','name'])
# 显示df数据
df_select.show()
df_select2.show()
# 数据的过滤方法 where 过滤后的数据会放入一个新的df中
# 一个条件的过滤
df_where = df.where('age > 20')
# 多个条件的与或非 and or 和sql中的条件书写方式一样
df_where1 = df.where('age > 20 and cls = "CS" ')
df_where.show()
df_where1.show()
# groupby 分组操作
# 直接分组计算 计算后的数据存储在新的df
df_groupby = df.groupby('cls').sum('age')
df_groupby.show()
# 配合where进行分组计算
df_new = df.where('age >= 20').groupBy(['cls','gender']).sum('age')
df_new.show()
# 分组聚合后的数据进行过滤
df_new1 = df.where('age >= 20').groupBy(['cls','gender']).sum('age').where('sum(age) > 22')
df_new1.show()
# orderBy 数据排序
df_new2 = df.where('age >= 20').groupBy(['cls','gender']).sum('age').orderBy('sum(age)',ascending=False)
df_new2.show()
# limit指定展示数量
df_new3 = df.where('age >= 20').groupBy(['cls','gender']).sum('age').orderBy('sum(age)',ascending=False).limit(2)
df_new3.show()
多个dsl方法配合使用要注意执行顺序
4-2 sql语句
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 1、生成SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 2、获取sparkcontext对象
sc = ss.sparkContext
# 3、 读取文件数据转为rdd
rdd = sc.textFile('/student')
# 4、查看rdd数据
# 5、对每行数据进行切割
rdd_map = rdd.map(lambda x:[int(x.split(',')[0]),x.split(',')[1],x.split(',')[2],int(x.split(',')[3]),x.split(',')[4]])
# 6、rdd转df
# 7、定义 表信息
schema_type= StructType().\
add('id',IntegerType()).\
add('name',StringType()).\
add('gender',StringType()).\
add('age',IntegerType()).\
add('cls',StringType())
df = rdd_map.toDF(schema_type)
# 显示所有内容
df.show()
# df数据操作
# 第二种方式,SQL方式
# 先创建一个表
# 参数 指定一个表名
df.createTempView('stu') # 本质是创建了一个视图
# 使用sql方法编写sql字符串,返回一个新的df
# sql的语法和hivesql一样
df2 = ss.sql('select id,name from stu')
df2.show()
五、DataFrame的高级DSL方法
- join关联
- 内关联
- 左关联
- 右关联
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 创建SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 通过rdd创建df
sc = ss.sparkContext
schema_type = StructType(). \
add('id', IntegerType()). \
add('name', StringType()). \
add('age', IntegerType(), nullable=False). \
add('gender', StringType())
schema_type1 = StructType(). \
add('user_id', IntegerType()). \
add('name', StringType()). \
add('age', IntegerType(), nullable=False). \
add('gender', StringType())
df1 = sc.parallelize([
[1, '张三', 20, '男'],
[2, '李四', 21, '男'],
[3, '王五', 22, '男'],
[4, '赵六', 23, '男'],
[6, '韩信', 26, '男'],
]).toDF(schema_type)
df2 = sc.parallelize([
[1, '小红', 20, '女'],
[2, '韩梅梅', 21, '女'],
[3, '妲己', 22, '女'],
[4, '小乔', 23, '女'],
[5, '貂蝉', 25, '女'],
]).toDF(schema_type)
df3 = sc.parallelize([
[1, '小红', 20, '女'],
[2, '韩梅梅', 21, '女'],
[3, '妲己', 22, '女'],
[4, '小乔', 23, '女'],
[5, '貂蝉', 25, '女'],
]).toDF(schema_type1)
# 两个df数据关联
# join
# 参数一 指定关联的df
# 参数二 指定关联的字段
# 参数三 指定关联方式 不写是内关联
# 返回一个新的df
df_new = df1.join(df2, 'id')
df_new.show()
# 左
df_new2 = df1.join(df2, 'id', 'left')
df_new2.show()
# 右
df_new3 = df1.join(df2, 'id', 'right')
df_new3.show()
# 字段不一样
df_new4 = df1.join(df3, df1['id'] == df3['user_id'])
df_new4.show()
# join 是按列拼接表数据
# union 按行拼接
df_new5 = df1.union(df2)
df_new5.show()
- 缓存和checkpoint
- 相同和不同点和rdd中的一样
# 使用sparksql都要SparkSession
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 创建SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 在SparkSession对象下有一个sparkcontext对象属性
# 获取sparkcontext对象 不需要加括号
sc = ss.sparkContext
# 指定保存路径
sc.setCheckpointDir('/spark_sql_check')
# 转化rdd 需要一个二维嵌套列表
rdd = sc.parallelize([
[1,'张三',20],
[2,'李四',22]
])
df = rdd.toDF()
# df 进行缓存
# df.persist() # 不需要触发就可以自动缓存
# checkpoint
df.checkpoint()
res = df.count()
print(res)
- 内置函数
- 字符串
# 导入内置函数functions as F命名别称
from pyspark.sql import SparkSession,functions as F
from pyspark.sql.types import *
# 1、生成SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 2、获取sparkcontext对象
sc = ss.sparkContext
# 3、 读取文件数据转为rdd
rdd = sc.textFile('/student')
# 5、对每行数据进行切割
rdd_map = rdd.map(lambda x:[int(x.split(',')[0]),x.split(',')[1],x.split(',')[2],int(x.split(',')[3]),x.split(',')[4]])
# 6、rdd转df
# 7、定义 表信息
schema_type= StructType().\
add('id',IntegerType()).\
add('name',StringType()).\
add('gender',StringType()).\
add('age',IntegerType()).\
add('cls',StringType())
df = rdd_map.toDF(schema_type)
df.show()
# 内置函数 select where
# 字符串操作
# 拼接 内置函数的后面可以跟上alias 命名计算的后字段名
df_new = df.select(['name','gender',F.concat('name','gender').alias('concat')])
df_new.show()
# 指定拼接字符
df_new1 = df.select(['name','gender',F.concat_ws(':','name','gender').alias('concat')])
df_new1.show()
# 字符串切割
df_new2= df_new1.select(F.split('concat',':').alias('split_data'))
df_new2.show()
# 数组数据的下标取值
df_new3 = df_new2.select(df_new2['split_data'][0],df_new2['split_data'][1])
df_new3.show()
#字符串截取
df_new4 = df_new1.select(F.substring('concat',1,2))
df_new4.show()
- 时间
# 导入内置函数functions as F命名别称
from pyspark.sql import SparkSession, functions as F
from pyspark.sql.types import *
# 1、生成SparkSession对象
ss = SparkSession.builder.getOrCreate()
# 2、获取sparkcontext对象
sc = ss.sparkContext
# 3、 读取文件数据转为rdd
rdd = sc.textFile('/student')
# 5、对每行数据进行切割
rdd_map = rdd.map(
lambda x: [int(x.split(',')[0]), x.split(',')[1], x.split(',')[2], int(x.split(',')[3]), x.split(',')[4]])
# 6、rdd转df
# 7、定义 表信息
schema_type = StructType(). \
add('id', IntegerType()). \
add('name', StringType()). \
add('gender', StringType()). \
add('age', IntegerType()). \
add('cls', StringType())
df = rdd_map.toDF(schema_type)
df.show()
# 内置函数 select where
# 字符串操作
# 拼接 内置函数的后面可以跟上alias 命名计算的后字段名
df_new = df.select(['name', 'gender', F.concat('name', 'gender').alias('concat')])
df_new.show()
# 指定拼接字符
df_new1 = df.select(['name', 'gender', F.concat_ws(':', 'name', 'gender').alias('concat')])
df_new1.show()
# 字符串切割
df_new2 = df_new1.select(F.split('concat', ':').alias('split_data'))
df_new2.show()
# 数组数据的下标取值
df_new3 = df_new2.select(df_new2['split_data'][0], df_new2['split_data'][1])
df_new3.show()
# 字符串截取
df_new4 = df_new1.select(F.substring('concat', 1, 2))
df_new4.show()
# 获取当前时间
df_new5 = df.select(['id', 'name', 'gender', F.current_date().alias('date'), F.current_timestamp().alias('timestamp'),
F.unix_timestamp().alias('uninx_timestamp')])
df_new5.show(truncate=False)
# 将unix转化为timestamp
df_new6 = df_new5.select(F.from_unixtime('uninx_timestamp', "yyyy/MM/dd HH:mm:ss"))
df_new6.show(truncate=False)
# 将timestamp转化为unix
df_new7 = df_new5.select(F.unix_timestamp('timestamp'))
df_new7.show(truncate=False)
# 时间加减
df_new8 = df_new5.select(['date',F.date_add('date',-1)])
df_new8.show(truncate=False)
# 年月日的取值
df_new9 = df_new5.select(['date',F.year('date'),F.month('date'),F.dayofweek('date')])
df_new9.show()
- 聚合
# 聚合
df_new10 = df.groupby('cls').sum('age')
df_new10.show()
# agg()聚合方法配合内置函数使用
df_new11=df.groupby('cls').agg(F.sum('age').alias('sum_data'),F.avg('age').alias('avg_data'),F.max('age'))
df_new11.show()
- 其他操作
- sparksession的操作
# 使用sparksql都要SparkSession
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# 创建SparkSession对象
# master 指定资源调度方式
# appName 指定任务名称
ss = SparkSession.builder.master('yarn').appName('yarn_saprksql').getOrCreate()














 1161
1161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









