






@4.15日嵌入式自学内容回顾与整理
一、Linux终端常用命令:
(1)目录和文件操作
ls:列出当前目录下的内容(白色是文件,蓝色是文件夹);
ls -a:列出当前目录所有文件,包括隐藏文件(带.的就是隐藏文件,..是上级目录,.是当前目录);
ls -l:列出当前目录文件,同时显示文件详细信息(权限、创建时间、大小等);
pwd:打印当前目录;
cd ..:返回上级目录;
cd :返回家目录;
cd 路径:到达指定目录;
touch 文件名:在当前目录创建文件;
touch 路径 文件名:在指定目录下创建文件;
mkdir 文件夹名:在当前目录创建文件夹;
mkdir 路径 文件夹名:在指定目录创建文件夹;
rm 文件名:删除当前目录下的文件;
rm 文件名 -r:删除当前目录下的文件夹;
cp 源文件 目录:复制文件到指定目录;
cp 源文件夹 目录 -r:复制文件夹到指定目录;
mv 文件/文件夹 目录:移动文件或文件夹到指定目录;(为什么文件夹操作在这里不像删除/拷贝,要在命令后加-r,这就要从文件夹跟文件的不同点讨论了,文件夹就像一个链表,这里形象的比喻成火车,删除跟拷贝就是砍断或者再造一个火车头,前者后面的车厢没了车头怎么运行呢,后者只有车头没有车险也就是空的,这就存在问题,而移动就像是拉着车头走,而后面的车厢连着车头也会跟着走,就不存在问题。)
(2)编辑文件内容
vi 文件名:打开文件,默认是命令模式,无法编辑文件(复制粘贴等命令除外),只有在编辑模式才可以编辑文件;(这里的文件如果不存在,则会直接在当前目录生成文件,并进入):
在命令模式下:
i:进入文本编辑模式;
nyy:复制光标所在行以及其下的行,n是几就复制几行;
ndd:剪切光标所在行以及其下的行,n是几就剪切几行;
p:在光标的下一行粘贴所复制或剪切的内容;
:q:退出文件,回到终端命令行,若文本内容有改动,会提示是否保存,反之直接退出。
:w:保存文本,仍在文本内。
:wq:保存退出;
:q!:强制退出,若有内容改动,不会保存;
在编辑模式下:
基本跟windows下的文本文档编辑一样,但鼠标只能移动光标位置,没有什么右键跳出设置进行复制粘贴什么的,同样也没法Ctrl C/V什么的。
按ESC退出编辑模式,进入命令模式。
(3)C语言编译运行
gcc 文件名:编译.c文件,生产a.out可执行程序,修改源程序后,再编译生产的a.out会覆盖原来的。
gcc 文件名 -o 名字:生产指定名字的可执行程序,并且不会覆盖之前编译输出的可执行程序;
./可执行程序:运行可执行程序;
二、相关补充
*终端命令行前面的linux@ubantu就是用户名@计算机名,这个ubantu就是GNU制作的Linux发行版,GNU你就当他是个公益组织,专门为了提供免费开源的东西。那么什么是Linux发行版呢,这就的谈谈Linux操作系统的发展历史了,在很久很久以前,有人发明了Unix内核,前期开源(就是在教室给人展示查看),后面以版权售卖形式卖给别人,这个内核使用起来很难,韩国奸商就给这个Unix加上外套,可以较为简单使用Unix,众人开始效仿,各种收费版本就出现了,这就是Linux发行版,而GNU组织也制作了一个Linux发行版ubantu,供大家免罚使用,到这大家应该对ubantu有些了解了,当然不用对这些东西钻牛角尖,会使用Linux操作系统就行了。
*嵌入式就是满足用户需求的、以计算机为核心的、软硬件可剪裁的系统。Linux+arm就可以实现很好的软硬件结合,在Linux操作系统中,C程序的编辑、编译和运行被拆分开了,可以实现多用户编辑、运行,并在硬件系统上直接运行可执行程序,实现软硬件完美结合,而windows操作系统的keil等集成编译环境把这些步骤结合起来,虽然方便程序员编译运行C语言程序,但却没有很好的可移植性,而且一些嵌入式开发通常直接在嵌入式产品上移植Linux操作系统,在上面操作,如果不了解Linux,就很难入手,所以我们要想学习嵌入式一定要学好Linux的C语言编程和一些硬件知识(比如什么是arm)。
*路径分为绝对路径(包含根目录/home/linux/...)和相对路径(不包含根目录,路径是相对于当前路径来说的。比如当前目录下有文件a.c,直接cd a.c,就把目录切换到a.c的位置了,这就是采用相对路径的方式)。
*家目录就是/home/linux/,也可以表示为~,其中第一个斜杠是根目录,后面的斜杠是分隔符。只有家目录下的内容可以操作,而根目录的内容无法操作,权限不够,如果硬要操作,可以采用sudo 命令的方式,执行该命令要先输入用户名密码,就是开机密码,但是大家最好不要随意对根目录进行操作,因为里面都是系统配置文件,不小心删除或者更改了什么文件,严重情况就得重装系统了。
*Linux打开终端除了点击图标还可以采取快捷键的方式(Ctrl+Alt+T);终端字体放大快捷键(Crtl+Shift+加号),缩小快捷键(Ctrl+减号)
*在输入路径时,只需要输入目录前几个字母,按一下Tab就可以补全目录名。
*可执行程序就是二进制文件,硬件只能识别二进制,所以只有二进制文件(可执行程序)才能在电脑或者其他硬件电路上运行,而编辑的.c程序就是写给人看的,计算机没法识别,所以需要编译源程序,这就是编译程序的作用所在。
*之前说过,路径包括相对路径和绝对路径:而前面列出的程序编辑编译运行命令需要程序文件在当前目录(相对路径)下,否则没法执行的,如果当前目录下没有程序,就可以把上面命令中的文件名前加上路径,如gcc /home/linux/c_language/main.c就可以编译其他目录下的程序了)
/*若有遗漏会评论区补充*/
@4.16+4.17日嵌入式自学内容回顾与整理
一、C语言知识
(1)C语言数据类型汇总
基础类型:整型、字符型、浮点型(单精度、双精度)、枚举类型;
构造类型:数组类型、结构体类型、共用体类型;
指针类型
空类型
(2)变量与常量
变量:程序运行过程中其值可以发生变化的量(比如定义int a = 10;这个a就是变量);
常量:程序运行过程中其值不发生变化的量(上面的10就是常量);
(3)整型常量(C语言只有以下三种整型常量表示方法)
十进制整数:12、-123、0;
八进制整数:011、077、021;
十六进制整数:0x123、0xaf、0XAF;
(4)整型变量
有符号短整型short、无符号短整型unsigned short:大小都是2字节。范围分别是-2的15次方到2的15次方减1、0到2的16次方减1;
有符号整型int、无符号整型unsigned int:大小都是4字节。范围分别是-2的31次方到2的31次方减1、0到2的32次方减1;
有符号长整型long、无符号长整型unsigned long:大小都是8字节。范围分别是-2的63次方到2的63次方减1、0到2的64次方减1;
有符号双长整型long long、无符号双长整型unsigned long long:大小跟范围同上。
(5)浮点型常量(C语言只有以下两种表示方法)
十进制法:1.2、12.;
指数法:12.0e2、12.34e-2、1.0E2(e几就是10的几次方的意思,e前后必须有数字(前面整数小数都可以,后面必须是整数);
(6)浮点型变量(不分有无符号,都是有符号的)
单精度浮点型float:大小为4字节;
双精度浮点型double:大小为8字节;
(7)字符常量
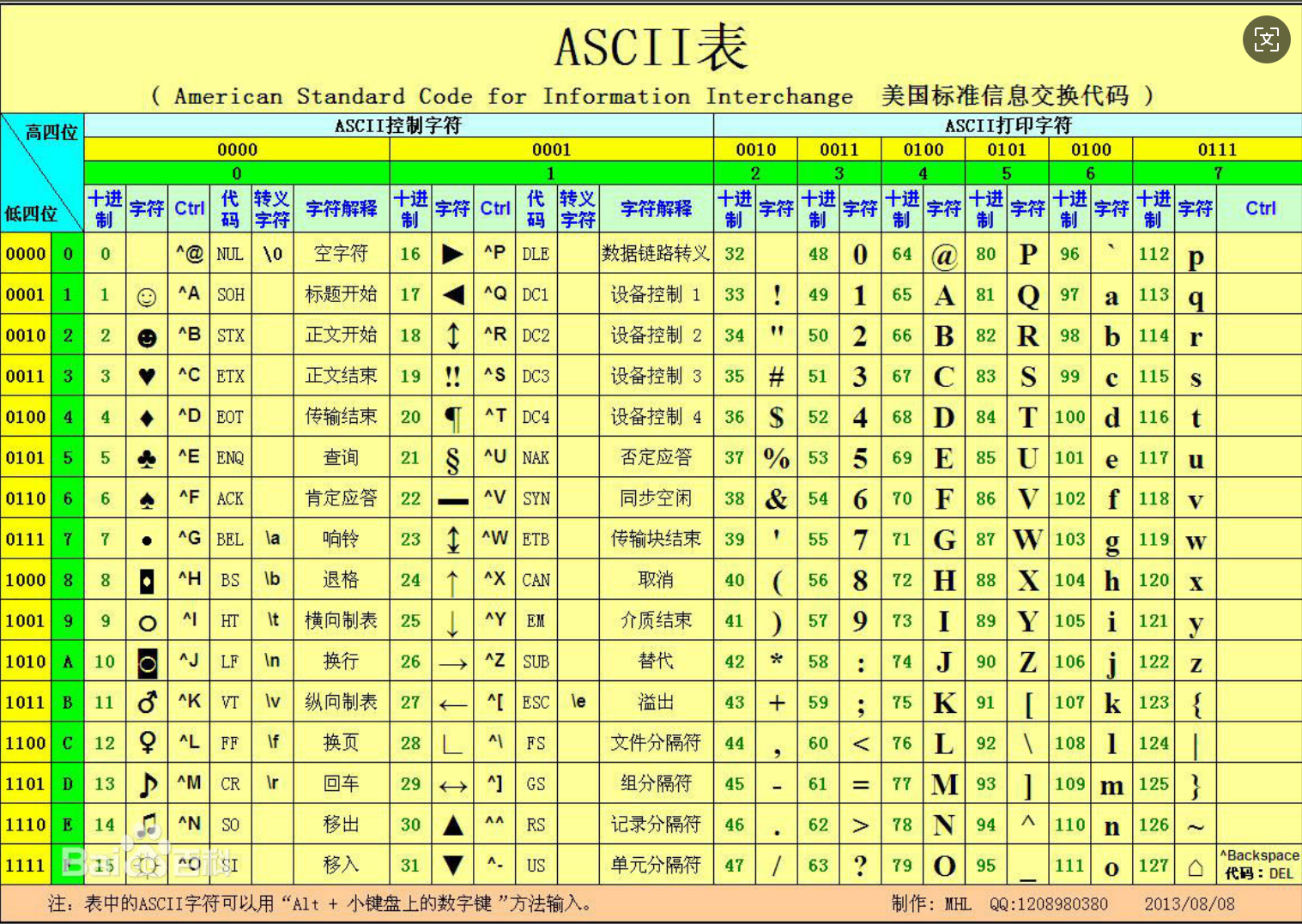
字符常量只有128个;
字符常量用单引号括起来,一些不可见字符用转义字符表示。
每个字符常量对应一个编码,十进制表示对应从0到127,具体见文章末尾附录ASCLL码表;
(8)字符变量
char:大小为1字节,范围是-128到127;
unsigned char;大小为1字节,范围是0到255;
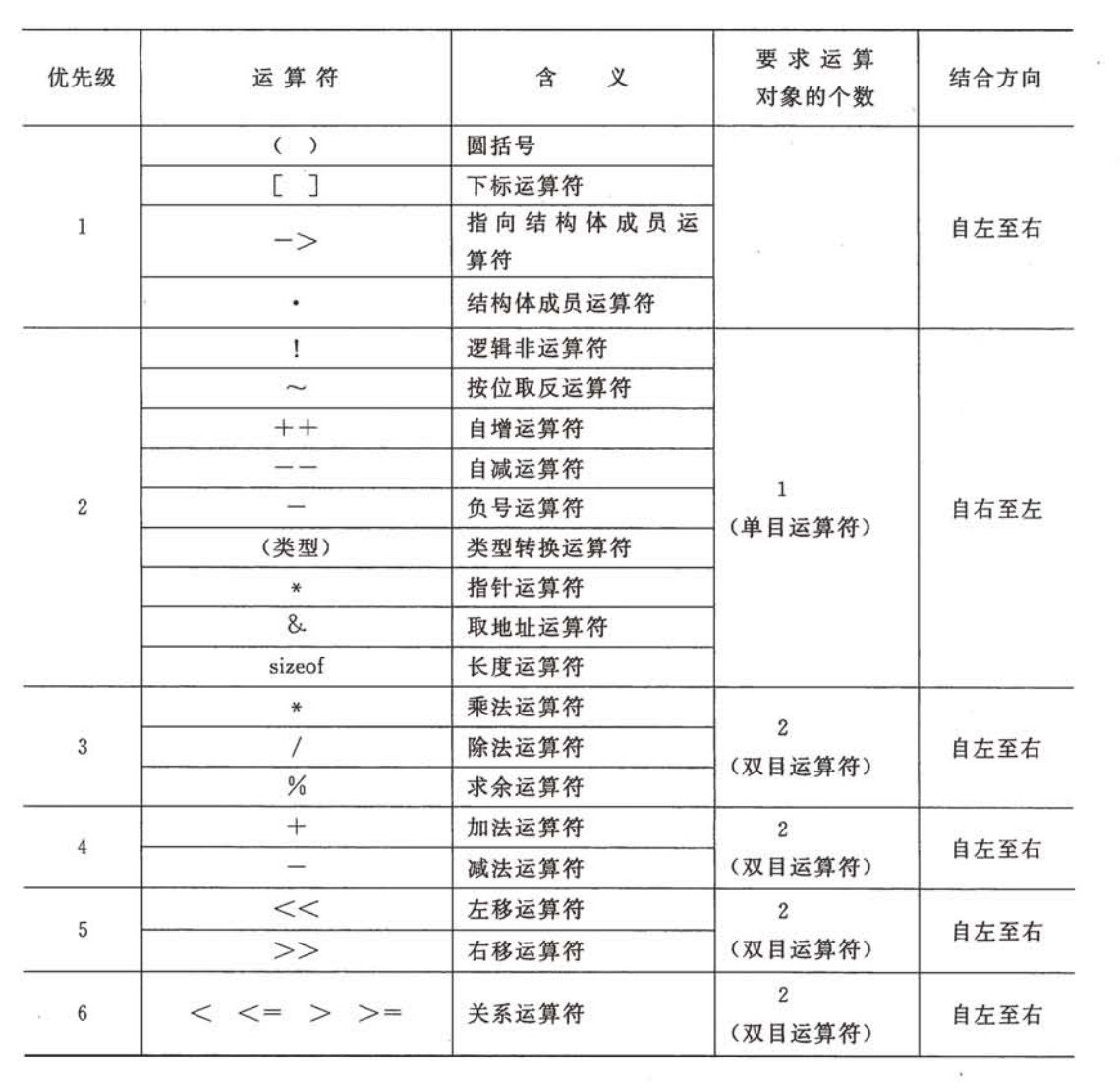
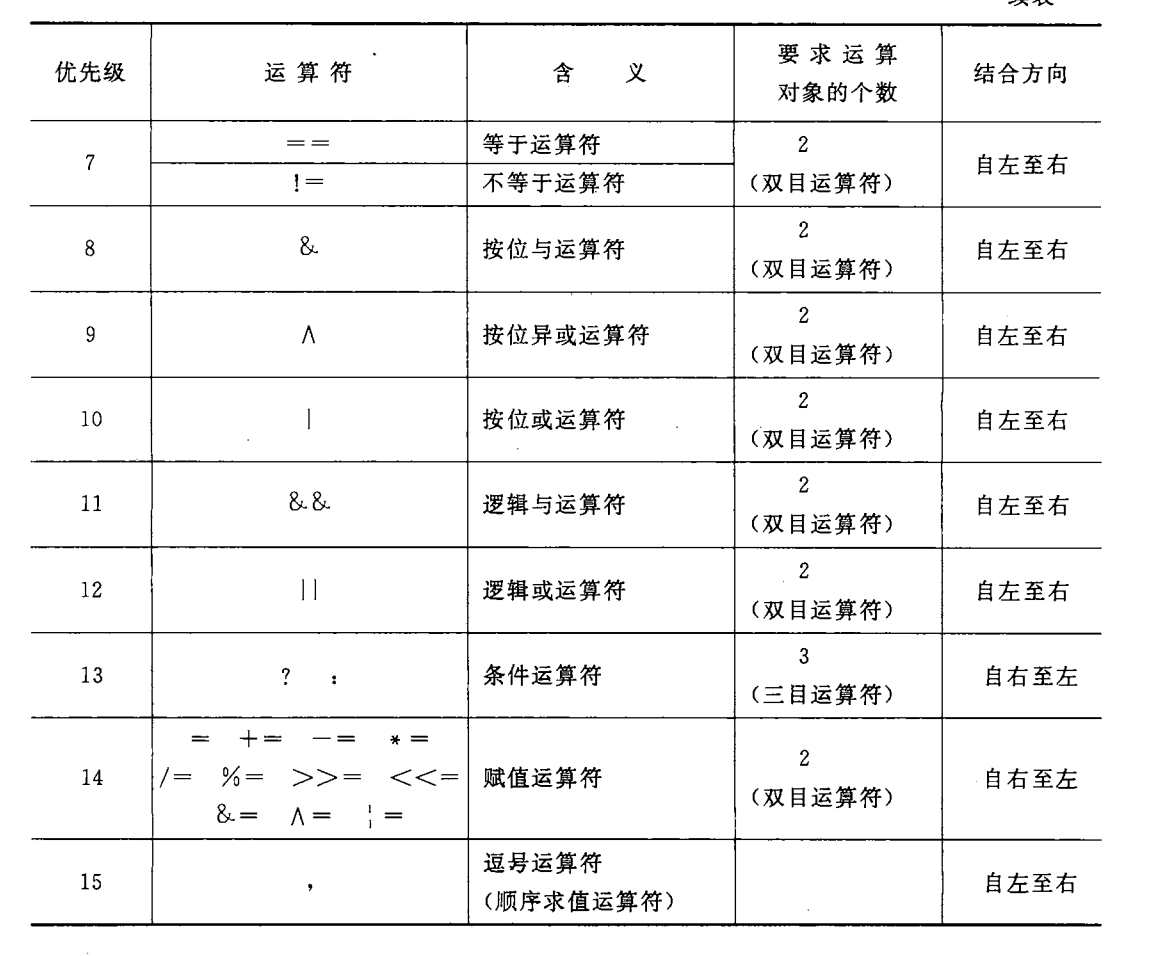
(9)常用运算符(重点记住对应符号、优先级和结合方向,见文章末尾附录)
算术运算符:加(+)、减(-)、乘(*)、除(/)、取余(%)、自增++、自减--;
赋值运算符:=、+=、-=、*=、/=、%=;
逗号运算符:,例子a = (a+b,a*b,a-b),从左到右依次执行,结果a的值为最后一个表达式a-b;
强制类型转换符:(数据类型)。
二、相关补充
*CPU和RAM是计算机不可或缺的部分,一个嵌入式产品也必须有这两部分。RAM(随机存储器)关机数据消失,跟ROM(只读存储器)相反。这里着重介绍RAM,为什么说它是随机存储器,因为变量定义后,就会随机给它分配一段RAM中的内存空间,每次运行程序,给变量分配的都是不同的内存,随机不可预测的,这就是随机存储器为什么叫随机存储器的原因,(这里就可以看出,变量只在程序运行时有存储空间,运行结束就自动销毁了,至于常量,压根没有存储空间)。
*RAM的存储空间可以看成一列表格,从上到下每一格对应一个地址,大小为一个字节,随着格子下移,地址每次加一个字节(所以存储空间衡量大小的最小单位是字节)。
*字节是byte,每1字节(byte)=8位(bit)
*上面的变量a就是一个变量名,也就是给程序运行时分配的存储空间命名为a,在C语言中还有很多需要命名的时候,这个名字当然不能随便取,要遵守以下规则:
1)只能由字母、数字、下划线(_)组成,且首字符只能是字母跟下划线;
2)大小写字母是不同的;
3)不能是C语言关键字(见文章末尾附录),可以是函数名,但你定义之后它就失去了相应的函数功能(比如你定义了变量printf,后面就用不了输出函数printf()了,它只是一个变量名了,如果继续把它当函数使用就会报错);
*进制转换:虽然计算机没有整数二进制表示方法,但为了方便三种进制间的转化,我们需要学习二进制:
十进制转二进制:短除法(辗转相除法);(我们可以记一些常见的2的倍数1、2、4、8、16、32、64、128对应2的(0、1、2、3、4、5、6、7)次方,当十进制数比较小,可以拆分成这些数相加的形式,然后根据这些数是2的几次方,直接把对应二进制位置1,其他位补0);
二进制转十进制:找到二进制数中的1,把它们对应的2的几次方加起来。
八进制转二进制:每一位八进制数转换为三位二进制(转换表见文章最后附录)。
二进制转八进制:从右往左,每三位二进制转换为一位八进制,最后如果不够三位,在左边补零。
十六进制转二进制:每一位十六进制数转换为四位二进制(转换表见文章最后附录)。
二进制转十六进制:从右往左,每四位二进制转换为一位十六进制,最后如果不够四位,在左边补零。
*ARM架构的RAM中存储数据都是小端存储,就是低字节存低位数据,之后依次存储,比如int a=0x12345678,在RAM中从低字节到高字节依次是78、56、34、12;
*整型变量在计算机中是按照补码方式存储的,正数的补码是它本身,负数的补码是原码取反加一。将整数转化为对应字节长度的二进制数后,最高位0为正、1为负。
*当赋给整型变量的整型常量值超出变量定义类型的范围时,就会发生整型溢出,输出的值跟你赋的值就会不同,这时候怎么知道RAM中存的数是多少呢,通过自学,我总结出两种方法:1)第一种:你先把赋值的整数转化为二进制,然后给它减一再按位取反,就可以得到原码,也就是溢出时你输出这个变量的值大小。2)第二种:我自己想出来的笨办法,通过一个例子说明,比如定义了一个有符号整型short a = 31768;从短整型范围-32768到32767来看,这是溢出了,我们运行一下输出函数,最后是输出-32768,或许大家已经发现了什么,没错,这个范围就像是一个周期,每当输出到最后一个数32767后,又回到-32768,往上走,当你输入32769,肯定输出-32767,输入32770,输出-32766,这就是规律,做题是可以试试这个快速方法哦。
*浮点数在ram中是按照符号位+阶码+尾数三部分组成的,具体计算方法见下(以二进制方法计算):符号位0为正、1位负;尾数就是把浮点数表示成二进制后,小数点前只有一位有效数字1,小数点后面的数就是尾数(也就是这个形式:(1.M) × 2^(E-偏移值),M就是尾数,E就是阶码,就相当于二进制版科学计数法,单精度偏移值为127,双精度为1023);阶码就比较复杂一些,就用上面那个公式计算,E就等于偏移值加上几次方。
*字符常量单引号表示形式下,单引号内写多个字符,编译时只把最后一个字符作为常量值(gcc编译时不会报错)。
*浮点型常量在gcc编译器下默认double型,比如你定义一个float a = 0.2;那么a == 0.2的值为0,因为他们数据类型不同。
*小写字母比大写字母ascll码值大32。
*转义字符介绍:
\n:换行,光标移到下一行;
\t:水平制表符,占八格,例:abc\tcd,输出为abc cd,c前共有八格(abc加上5个空格);
\b:退格,把光标前移一格,例:Hello\b123输出hell123,Hello\b\b123输出Hel123;
\r:回车,光标移到开头,例:hello\r123输出123lo;
\\:输出一个\;
\':输出单引号
\":输出双引号
\ooo:每一个o代表一个八进制数,输出对应ASCLL码字符;
\0xhh:每一个h代表一个十六进制数,输出对应ASCLL码字符;
*运算符需要几个操作数就是几目运算符
运算符加操作数就构成表达式,在表达式后加分号就构成表达式语句;
*双目运算符如算术运算符在写程序时两边加上空格,增加可读性;
*求余运算符两边必须都是整数,结果正负由左操作数决定,结果一定小于右操作数;
*定义变量后,其值是未经过初始化或赋初值,其值是随机的。初始化(int a = 12)和赋初值(int a;a = 12)二者效率相较之下,前者高一些。
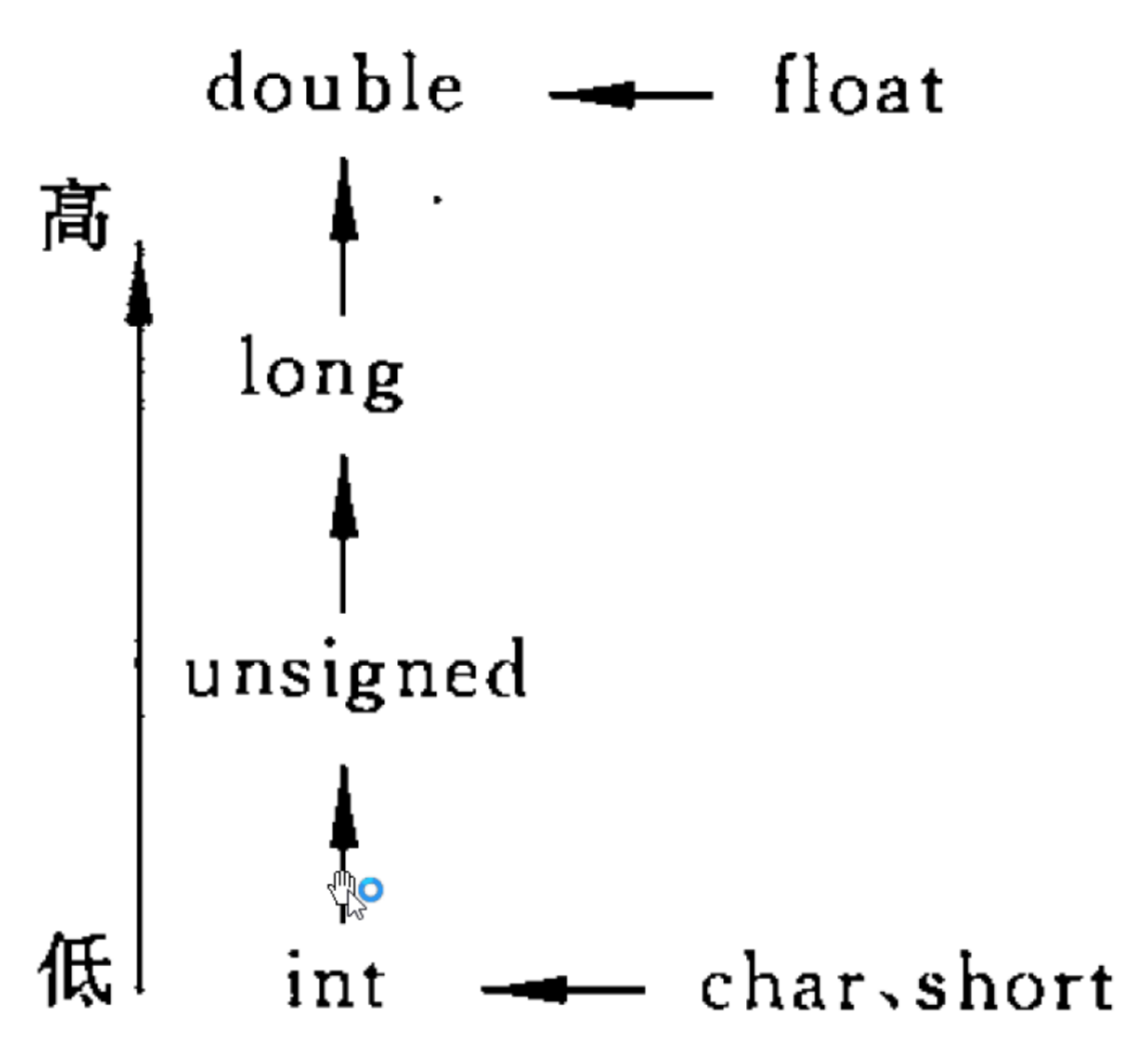
*隐式转换:运算符操作数类型不一致时,需要按照一定规则转为统一类型(编译器自动进行),具体规则见文章结尾附录。
*由于CPU只有双精度运算器,所以浮点型默认双精度类型。
*显式转换:由程序员进行的类型转化,运用强制类型转换符。
*临时(匿名)变量对应临时存储空间,如表达式的结果就是放在临时变量。
*在定义变量时,前面加const,表示定义常变量,其值在程序运行过程不变,但占用存储空间。
*后置加加在RAM中会另开辟一个临时空间存放表达式的值(仍原值),变量对应存储空间的值加一。前置加加则没有临时空间,表达式的值就是变量的值(原值加一)。因此前置加加由于不需要额外开辟存储空间而高效一些。
*在赋值表达式中分为左值(可定位的,能被取地址的,如变量),右值(只读的,不可取地址的,如常量)。常变量虽然是只读变量,但是可作为左值,临时变量只能是右值。
*在赋值时,把浮点数存到int型变量中会造成小数截断,反之没影响;把短整型数据存到整型中会根据符号位扩充空洞,反之会造成高字节截断把有符号数存到无符号数中,RAM中的数据没变,因为字节数相同,可以看出赋值运算就是简单的数据拷贝。
@4.18日嵌入式自学内容回顾与整理
一、C语言知识
(1)单字符输入输出函数
char putchar(int ):输出一个字符。从函数首部组成可以看出函数返回值是字符,函数参数是整型,由于字符变量也是整型变量一种,所以参数也可以是字符类型。
int getchar():键盘输入一个字符。函数首部看出返回值是一个整型(也就是输入字符ASCLL码值),参数任意,但肯定不能随便输,因为字符只有128种,你也只能输入那些,输入其他乱七八糟的函数肯定没法正常工作。
(2)格式化输入输出函数
int printf(const char*,...):输出字符串。函数打印出来的都是整型,因为字符串就是字符组成,字符都是正数,所以打印出来的都是无符号整型。函数参数中第一个是字符串,后面的参数可省略,当字符串中有占位符(格式化字符%等),就会用后面的参数替换掉占位符。
int scanf(const char*,...):输入多个字符。同样是用后面的参数替换占位符,由于函数值传递原因,这里后面的参数需要是地址数据。输入时要把字符串内数据样输出,占位符替换后输出。
(二)相关补充
*输入输出是相对计算机说的。
*C语言本身没有输入输出语句,这是为了提高效率。
*.h表示头文件,里面有各种函数定义。
*格式化字符(占位符)
%d:整型数据占位符
%010d:替换时宽度为10,前面补零,只能补零或者空格。
%o:八进制数据占位符
%#o,会输出0ooo,o表示八进制数
%x:十六进制数据占位符
%#x,会输出0xhhh,h表示十六进制数
%e、%E:占位符用科学计数法浮点数代替,(如1230.0,占位符替换为1.230000e3)
%f:占位符用浮点数十进制表示法代替,默认保留6位小数。
%m.nf:m是宽度,n是小数位数,表示占位符替换为宽度m,n位小数的浮点数据。
%g,%G:两种浮点数表示方法(十进制、科学计数法)哪个短用哪个表示。
%c:占位符用字符代替。
%s:占位符用字符串代替。
%p :占位符用地址代替,十六进制
%%:占位符用%代替。
%lld :用long long整型代替
%lu:用无符号长整型代替。
*printf函数返回值是打印的实际字符个数。
*scanf函数使用时,键盘输入多个数据,要用空格、TAB或换行符。
*scanf函数返回值是正确打印字符的个数。
附录:
1、隐式转换规则
2、C语言关键字

3、Ascll码表
4、运算符


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









